文章目录
- 摘要
- Abstract
- 文献阅读
- 题目
- 引言
- 创新点
- Decoder-Encoder模型
- 实验过程
- 实验结果
- 深度学习
- LSTM变体
- Bidirectional LSTM(双向LSTM)
- GRU
- GRU代码实现
- 总结
摘要
本周阅读了一篇关于统计机器翻译的RNN编码器-解码器学习短语表示的文章。
文中提出了一种新的神经网络模型称为RNN编码器-解码器,由两个递归神经网络(RNN)构成。一个RNN将符号序列编码为固定长度的向量表示,另一个将表示解码为另一个符号序列。通过使用由RNN编码器-解码器计算的短语对的条件概率作为现有对数线性模型中的附加特征,使得统计机器翻译系统的性能得到改善。此外,还对LSTM变体双向LSTM、GRU的等相关内容进行学习。
Abstract
This week, an article about RNN encoder-decoder learning phrase representation in statistical machine translation is readed. In this paper, a new neural network model called RNN encoder-decoder is proposed, which consists of two recurrent neural networks (RNN). One RNN encodes the symbol sequence into a vector representation of fixed length, and the other decodes the representation into another symbol sequence. By using the conditional probability of phrase pairs calculated by RNN encoder-decoder as an additional feature in the existing log-linear model, the performance of statistical machine translation system is improved. In addition, we also learn about the two-way LSTM and GRU of the LSTM variant.
文献阅读
题目
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
引言
在研究神经网络在SMT中的应用的基础上,提出了一种新的神经网络体系结构,可以作为传统基于短语的SMT系统的一部分。提出的神经网络结构,将其称为一个RNN Encoder–Decode,由两个递归神经网络(RNN)作为编码器和解码器对。实验结果表明,采用RNN Encoder–Decode对短语进行译码,提高了译码性能。定性分析表明,RNN Encoder–Decode能较好地捕捉短语表中的语言规律,间接解释了整体翻译性能的量化提升。
创新点
本文提出了GRU的结构:
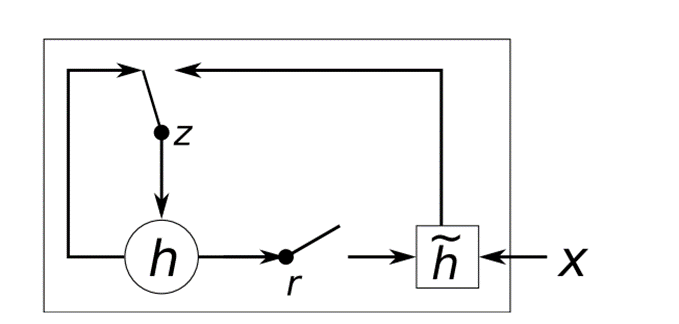
先来看一下GRU各个状态是如何更新的:
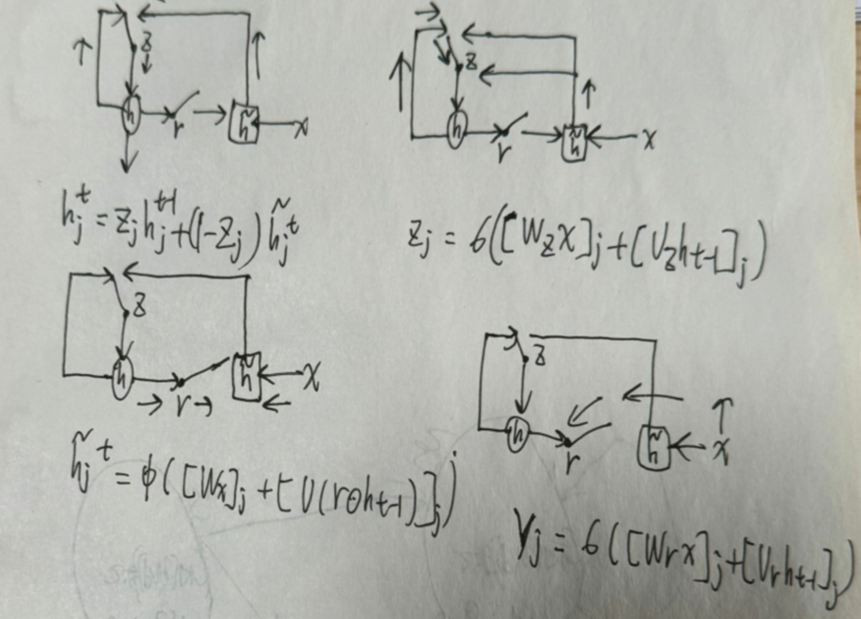
其中,[.]j代表向量的第j个元素,也就是图中的公式都是以单个元素为例进行计算的。⨀表示将两个形状相同的矩阵对应元素相乘。[.]+[.]代表将两个向量进行拼接,不是对应元素相加。x和ht−1分别代表输入和上一层的隐藏状态。W∗和U∗代表权重矩阵,*代表r、z或空。σ代表sigmoid函数,图中z和r分别代表更新门和重置门。
如果重置门被设置为0,那么先前的隐藏层状态就会被强制遗忘,然后用当前的输入进行重置。这使得隐藏层状态可以有效的丢 弃跟未来没有任何关系的信息,从而使信息表达更为紧凑。而更新门则是用来控制先前的隐藏层状态会携带多少信息到当前状态。
Decoder-Encoder模型
编码器是一个RNN,它根据输入序列在每一时间步更新隐状态,最后输出编码向量c来表示整个输入序列。
解码器是一个条件RNN,它根据编码向量c以及前面生成的符号,通过计算隐状态和条件概率分布,生成输出序列。

编码器:
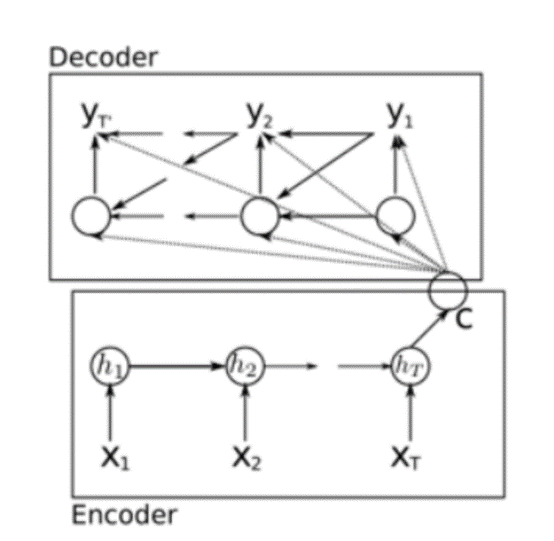
编码器部分标注出了隐藏层状态,用ht表示,其更新公式为:
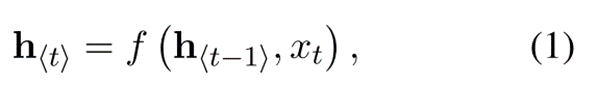
其公式(1)说明当前时刻的隐藏层状态ht是由上一时刻的状态ht−1和当前时刻的输入xt共同决定的。f 是一个函数,可以是一个简单的逻辑函数,比如sigmoid函数,也可以是一个复杂的函数,比如LSTM。这篇论文中f用的是作者提出的一个新的结构,叫做GRU。
C是中间语义表示,可以是各个时刻隐藏输出的汇总:
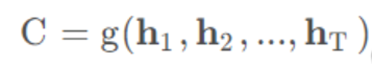
也可以是最后一层隐层的输出:
C=hT
本篇论文中作者是将隐层的最后输出作为语义表示 C 。由于编码器用的是RNN的结构,每一个循环中的信息都会流到下一个循环中,因此中间语义表示 C 理论上包含了输入序列的所有信息。

解码器:
图中标注出了解码器的隐藏层状态,用st表示,从图中可以看出,隐藏层的状态更新,不仅跟上一时刻的输出st−1和当前时刻的输入c有关系,还跟上一时刻的输出yt−1有关:

实验过程
一、数据集
使用WMT2014数据集,其包含大量英法平行数据。双语语料库包括Europarl(6100万单词)、news commentary(550万单词)、UN(421万单词)和两个爬行语料库(9000万单词)。最后两个语料库比较吵。为了训练法语语言模型,除了bitext的目标侧外,还有大约7.12亿的爬行报纸材料。所有的单词计数都是经过标记的法语单词。
二、评估指标
提出使用RNN编码器-解码器模型来对短语进行分值,与传统的基于语言模型的方法进行对比BLEU分数。
三、超参数的设定
实验中使用的RNN Encoder–Decoder有1000个隐藏单元,标准差固定为0.01,h=10^-6,ρ=0.95。
实验结果

当我们同时使用CSLM和RNN Encoder–Decoder的短语评分时,可以获得最佳的性能。这说明CSLM和RNN Encoder–Decoder的贡献不太相关,单独改进这两种方法可以得到更好的结果。此外,我们尝试惩罚神经网络未知的单词数量(即不在候选列表中的单词)。我们通过简单地将未知单词的数量作为一个附加特性添加到式(9)中的对数线性模型中来实现这一点。然而,在这种情况下我们无法在测试集上获得更好的性能,而只能在开发集上获得更好的性能。
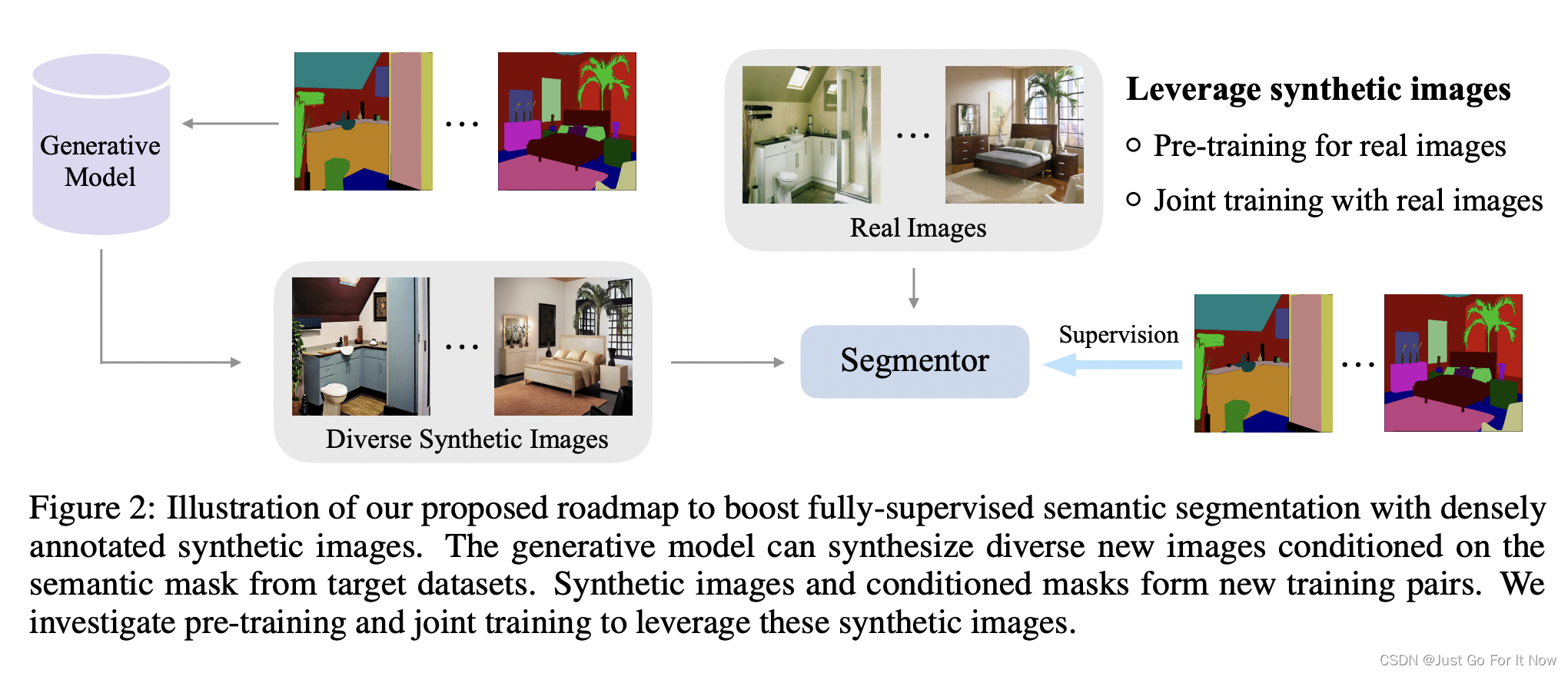
图4左边的图显示了使用RNN Encoder–Decoder学习的单词嵌入矩阵对单词进行二维嵌入。该预测是由最近提出的BarnesHut-SNE (van der Maaten, 2013)完成的。我们可以清楚地看到,语义上相似的单词彼此聚集在一起(参见图4中的放大图)。这种情况下的表示(图1中的c)是一个1000维的向量。与单词表示类似,我们使用图5中的bar - hut - sne可视化由四个或更多单词组成的短语的表示。
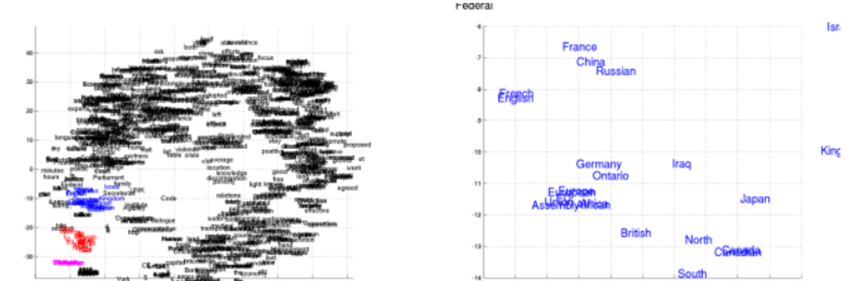
从可视化结果可以看出,RNN Encoder–Decoder同时捕获了短语的语义结构和句法结构。例如,在左下角的图中,大多数短语是关于持续时间的,而那些在语法上相似的短语则聚集在一起。右下角的图表显示了语义相似(国家或地区)的短语集群。另一方面,右上角的图表显示了语法上相似的短语。

深度学习
LSTM变体
Bidirectional LSTM(双向LSTM)
LSTM只能实现单向的传递,无法编码从后到前的信息。当我们语句是承前启后的情况时,自然能完成。但是当语句顺序倒过来,关键次在后面了,LSTM就无能为力了。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
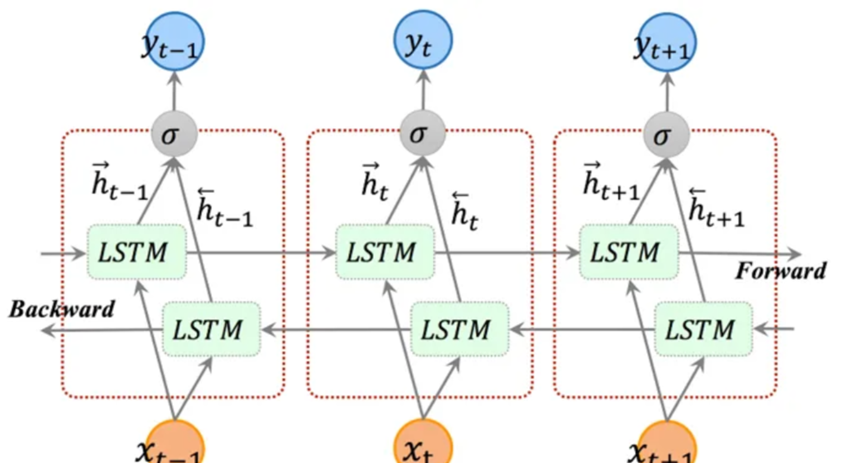
双向LSTM结构中有两个 LSTM 层,一个从前向后处理序列,另一个从后向前处理序列。这样,模型可以同时利用前面和后面的上下文信息。在处理序列时,每个时间步的输入会被分别传递给两个 LSTM 层,然后它们的输出会被合并。通过双向 LSTM,我们可以获得更全面的序列信息,有助于提高模型在序列任务中的性能。
双向神经网络的单元计算与单向的是相通的。但是双向神经网络隐藏层要保存两个值,一个参与正向计算,另一个值参与反向计算,处理完成后将两个LSTM的输出拼接起来。
Q:为什么LSTM中经常使用的是双向LSTM?
双向结构的设计可以提高模型的表示能力和性能,特别是好地捕捉序列中的信息、在处理复杂序列数据时。以下是为什么经常使用两层双向LSTM的一些原因:
更丰富的上下文信息: 两层LSTM可以提供更丰富的上下文信息。第一层LSTM将原始输入序列的信息进行初步处理,然后将其作为更丰富的输入提供给第二层LSTM。这有助于模型更好地捕捉输入序列中的特征和模式。
更强的特征表示: 两层LSTM可以逐步提取更抽象、更高级别的特征表示。第一层LSTM将原始数据进行编码,然后第二层LSTM在第一层的基础上进一步提取更有意义的特征。这有助于提高模型的表达能力,从而更好地建模序列数据
双向信息:双向LSTM可以从两个方向(正向和反向)分别获取序列数据的信息。
GRU
虽然LSTM能够抑制梯度消失问题,但需要以增加时间复杂度和空间复杂度作为代价。GRU在LSTM基础上将忘记门和输入门合并成一个新的门即更新门, GRU包含两个门:更新门与重置门
如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。这两个门控向量决定了哪些信息最终能作为门控循环单元的输出,它们能够保存长期序列中的信息,使得重要信息可以跨越长时间步骤传递,且不会随时间而清除或因为与预测不相关而移除。
GRU的优势:
参数更少:从而有效降低过拟合的风险,因此模型泛化能力较好,并且在反向传播的过程中,随着反向传播深度的加深,对应需要反向传播路径相比于LSTM大量减少,从而减小了时间、空间复杂度的负担。
训练速度较快: 由于GRU的参数较少,它通常比LSTM更快地训练。
对短序列有优势:GRU在某种程度上减少了梯度消失的问题,使其更容易捕捉到短序列中的相关信息。
GRU的缺点:
信息保存不如LSTM: GRU的门控机制相对简单,因此它不太适合捕捉长期依赖关系。在某些任务中,尤其是处理需要长期记忆的序列数据时,LSTM可能表现更好。
性能不稳定:GRU在某些任务中可能表现得不如LSTM稳定,因为它在不同数据集和问题上的性能差异较大。在一些情况下,LSTM可能更可靠。
GRU代码实现
d2l是李沐老师自己的一个包,可以从github上自行下载,之后我们就可以通过train_iter以mini-batch方式读取数据;并通过vocab把词转换成数字表示进行模型输入和输出。
import torch
from torch import nn
from d2l import torch as d2l
# 设置每个batch的大小和时间步数
batch_size, num_steps = 32, 35
# 加载时间机器数据集并获取词汇表
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
先设置输入输出参数维度为词汇表大小,然后定义了两个函数normal和three,用于生成服从正态分布的随机权重张量。然后利用three函数初始化了GRU模型中更新门、重置门、候选隐状态等不同组件所需的权重和偏置参数。接着初始化了从隐状态到输出的权重和偏置。最后将所有参数放入列表中,设置requires_grad,并返回参数列表。这样就完成了GRU模型中不同门控机制的参数初始化,为后续建立GRU模型提供了参数准备。
# 初始化模型参数
def get_params(vocab_size, num_hiddens, device):# 设置输入和输出的维度为词汇表大小num_inputs = num_outputs = vocab_size# 定义一个函数,用于生成服从正态分布的随机张量,并乘以0.01进行缩放def normal(shape):return torch.randn(size=shape, device=device) * 0.01# 定义一个函数,生成三组权重和偏置张量,用于不同的门控机制def three():return (normal((num_inputs, num_hiddens)), normal((num_hiddens, num_hiddens)),torch.zeros(num_hiddens, device=device))# 初始化GRU中的权重和偏置# 权重和偏置用于控制更新门W_xz, W_hz, b_z = three() # GRU多了这两行# 权重和偏置用于控制重置门W_xr, W_hr, b_r = three() # GRU多了这两行# 权重和偏置用于计算候选隐藏状态W_xh, W_hh, b_h = three()# 隐藏状态到输出的权重W_hq = normal((num_hiddens, num_outputs))# 输出的偏置b_q = torch.zeros(num_outputs, device=device)# 参数列表中各参数顺序params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]# 遍历参数列表中所有参数for param in params:# 设置参数的`requires_grad`属性为True,以便进行梯度计算param.requires_grad_(True)# 返回参数列表中所有参数return params

这个函数接收batch_size, num_hiddens和device作为参数。它返回一个只包含一个元素的元组,个元素是一个形状为(batch_size, num_hiddens)、设备为device、且值全为0的张量。这个全零的隐藏状态张量将作为GRU模型最初的隐藏状态使用。
# 定义隐藏状态的初始化函数
def init_gru_state(batch_size, num_hiddens, device):# 返回隐藏状态初始化为全零的元组return (torch.zeros((batch_size, num_hiddens), device=device),)
以下代码通过输入序列上的逐步计算,实现了GRU的基本前向计算流程,包括不同门控单元的计算以及隐藏状态的更新。
def gru(inputs, state, params):# 参数 params 解包为多个变量,分别表示模型中的权重和偏置W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params # 传入的隐藏状态 state 解包为单个变量 H。H, = state# 创建一个空列表,用于存储每个时间步的输出outputs = []# 遍历输入序列中的每个时间步for X in inputs:# 更新门控机制 ZZ = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)# 重置门控机制 RR = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)# 计算候选隐藏状态 H_tildaH_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)# 更新隐藏状态 HH = Z * H + (1 - Z) * H_tilda# 计算输出 YY = H @ W_hq + b_q# 将输出添加到列表中outputs.append(Y)# 将所有输出拼接在一起,并返回拼接后的结果和最终的隐藏状态return torch.cat(outputs, dim=0), (H,)
训练与预测:
训练和预测的工作方式与RNN中的实现完全相同。训练结束后,我们分别打印输出训练集的困惑度和前缀“time traveler”和“traveler”的预测序列上的困惑度。
# 训练
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
# 设置训练的总轮数和学习率
num_epochs, lr = 500, 1
# 创建 GRU 模型实例
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,init_gru_state, gru)
# 调用 D2L 库中的训练函数,传入模型实例、训练数据迭代器、词汇表、学习率和训练的总轮数
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
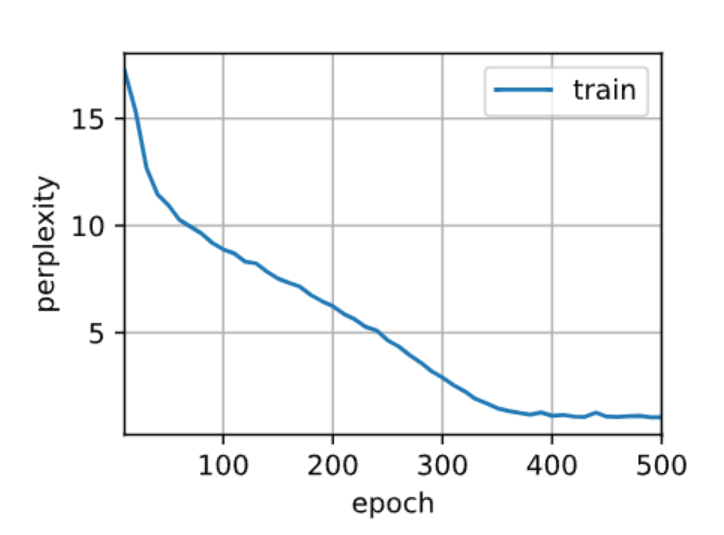
简单实现:高级API包含了前文介绍地全部配置细节,所以可以直接实例化GRU。其使用编译好的运算符来进行计算,而非python处理其中的许多细节。
# 简洁实现
# 设置输入特征的维度为词汇表大小
num_inputs = vocab_size
# 创建一个 GRU 层,指定输入特征的维度和隐藏单元的数量
gru_layer = nn.GRU(num_inputs, num_hiddens)
# 创建一个 RNNModel 实例,传入 GRU 层和词汇表的大小
model = d2l.RNNModel(gru_layer, len(vocab))
# 将模型移动到指定的设备上(可能是 GPU)
model = model.to(device)
# 调用 D2L 库中的 train_ch8 函数进行训练,传入模型实例、训练数据迭代器、词汇表、学习率和训练的总轮数
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
总结
GRU由于门控机制允许选择性信息保留和遗忘,因此比传统RNN更擅长捕获长期依赖。比其他类型的循环神经网络GRU需要更少的训练时间,具有比LSTM更少的参数,使其训练速度更快并且不易过度拟合,可用于各种自然语言处理任务,包括语言建模、情感分析和机器翻译。但在需要对复杂的顺序依赖关系进行建模的任务中,它的表现可能不如LSTM。