MySQL核心SQL
结构化查询语句SQL
SQL是结构化查询语言(Structure Query Language),它是关系型数据库的通用语言。
SQL主要可以划分为以下 3 个类别:
-
DDL(Data Definition Languages)语句数据定义语言,这些语句定义了不同的数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。
-
DML(Data Manipulation Language)语句数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括 insert、delete、update 和select 等。
-
DCL(Data Control Language)语句数据控制语句,用于控制不同的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 grant、revoke 等。
库操作
查询数据库
show databases;
创建数据库
create database ChatDB;
删除数据库
drop database ChatDB;
选择数据库
use ChatDB;
表操作
查看表
show tables;
创建表
create table user(id int unsigned primary key not null auto_increment,name varchar(50) unique not null,age tinyint not null,sex enum('M','W') not null)engine=INNODB default charset=utf8;create table t_user(id int(11) unsigned primary key not null auto_increment,email varchar(255) default null,password varchar(255) default null);
查看表结构
desc user;
查看建表
show create table user\G
删除表
drop table user;
CRUD操作
insert增加
//自增键的id是有限的
insert into user(name,age,sex) value('zhangsan',20,'W');insert into user(name,age,sex) value('guojiahui',20,'M');insert into user(name,age,sex) value('wuchanjin',23,'W');insert into user(name,age,sex) value('wo',21,'M');insert into user(name,age,sex) value('ta',22,'W');insert into user(nickname, name, age, sex) values('666', 'li si', 21, 'W'),('888', 'gao yang', 20, 'M');//这种插入最终表里的数据都是一样的 //
这两种插入有啥区别呢:
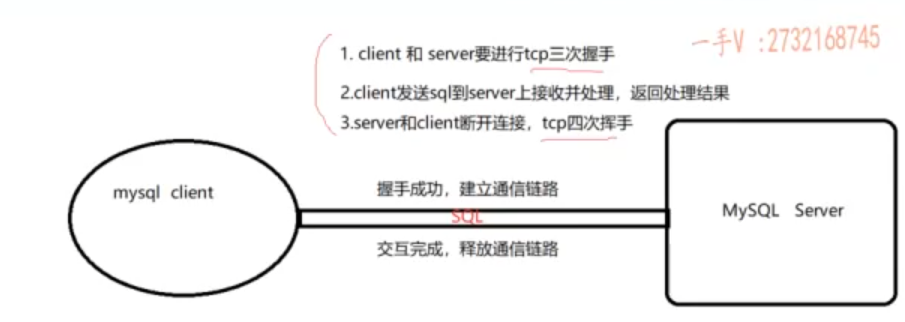
一条就加入的就是少了三次握手的次数 而单独加入就是多次使用三次握手建立连接
update增加
update user set age=age+1;
delete删除
delete from user where age=23;
select查询
select * from user;//全部显示select name,age,sex from user;select name from user;//选中的列的所有数据select name,age,sex from user where age>21;//有条件的
去重distinct
select distint age from user;
空值查询
select * from user where name is null;
union**合并查询**
SELECT country FROM Websites UNION ALL SELECT country FROM apps ORDER BYcountry;
带in查询
select * from user where id in(10, 20, 30, 40, 50)select * from user where id not in(10, 20, 30, 40, 50)select * from user where id in(select stu_id from grade where average>=60.0)
分页查询
select * from user limit N;//看前几个select * from user limit 1,3;//偏移一个 然后取三个
explain:查看SQL语句的执行计划,统计大概的性能指标
select * from user where name = 'zhangsan';//这个怎么扫描的 不是一行一行扫的 直接扫一行 这个是键索引的情况下explain select * from user where age = 21;//这个就是扫了五次 做的事整表搜索

explain显示不出来我limit的优化
limit对于我们得SQL查询的效率有提升了吗?
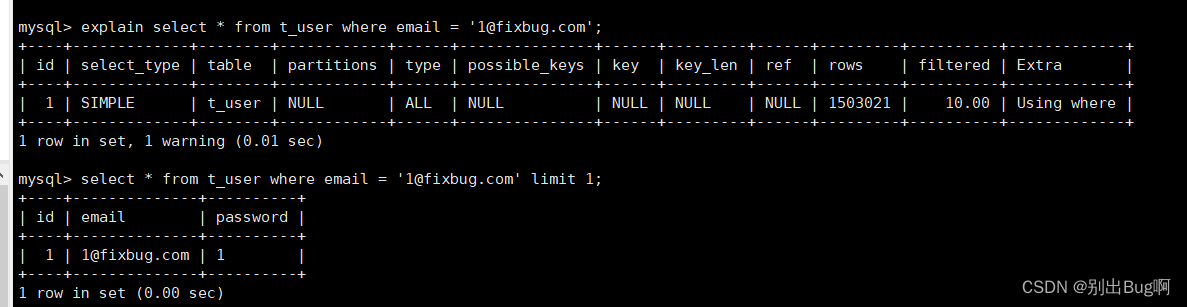
可以看时间 效率明显提升
//limit在什么时候会带来效率上的提升?
delimiter $//把SQL的结束语句改成$Create Procedure add_t_user (IN n INT)//这就是一个存储过程in 表示输入参数 n就是变量BEGINDECLARE i INT;SET i=0;WHILE i<n DOINSERT INTO t_user VALUES(NULL,CONCAT(i+1,'@fixbug.com'),i+1);SET i=i+1;END WHILE;END$delimiter ;call add_t_user(2000000);
分页操作
pagenum = 20 行进记录select * from user limit (pageno-1)*pagenum,pagenum;//这个就是显示0 - 20 当pageno是1的时候就是0 是第一页//这样操作之后功能没问题 但是效率不搞 因为到后面就得都遍历一遍 M的便宜花费的性能我们只需向每一页需要展示的行数 就可以了 优化select * from t_user where id>上一页最后的数据id limit 20;
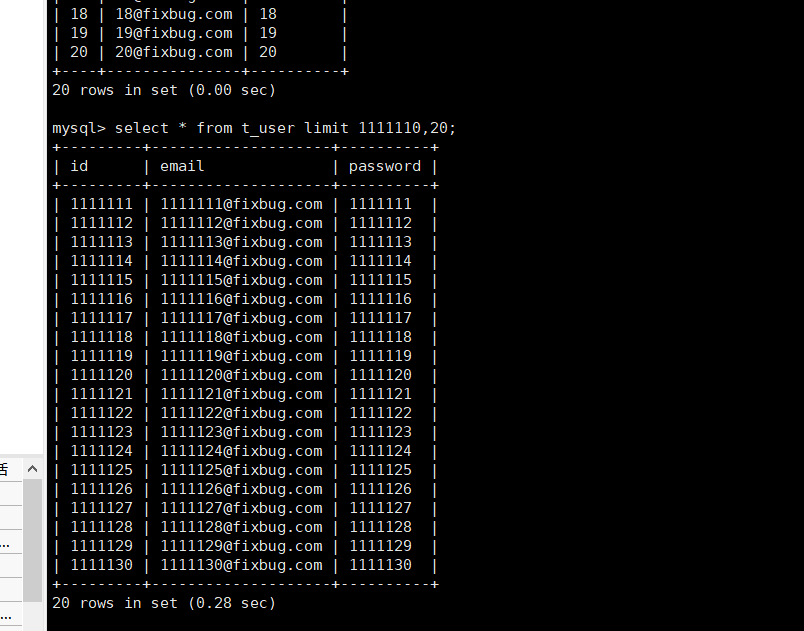
可以看到偏移以后 时间久增多了 效率不高了
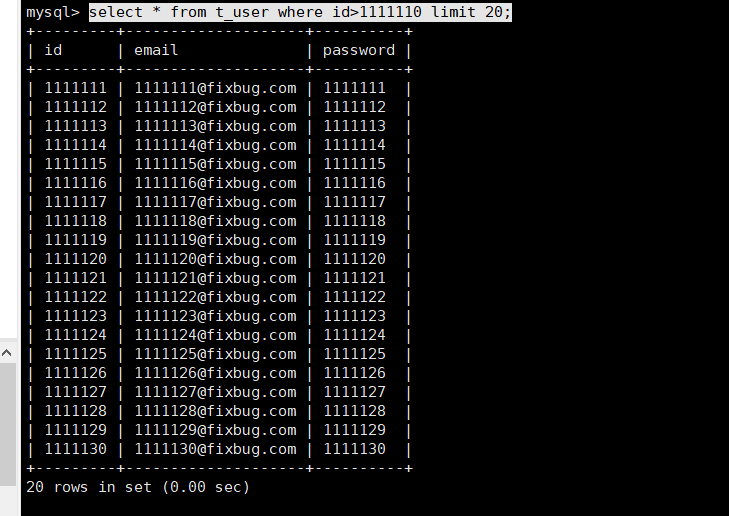
select * from t_user where id>1111110 limit 20;//这样就可以解决上面的问题了 优化偏移量 通过主键
排序order by
select *from user order by name;//默认升序select *from user order by name ,age;//当名字相同时候 按照年龄排序

当出现 using filesort的时候就代表要优化了
分组group by
按照指定的字段分成一组
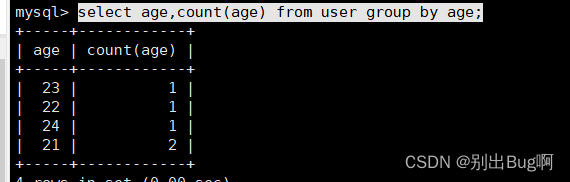
select age from user group by age;select age,count(age) from user group by age;//这个是分组之后看有几个select count(id),age from user group by age having age>20;
笔试实践问题
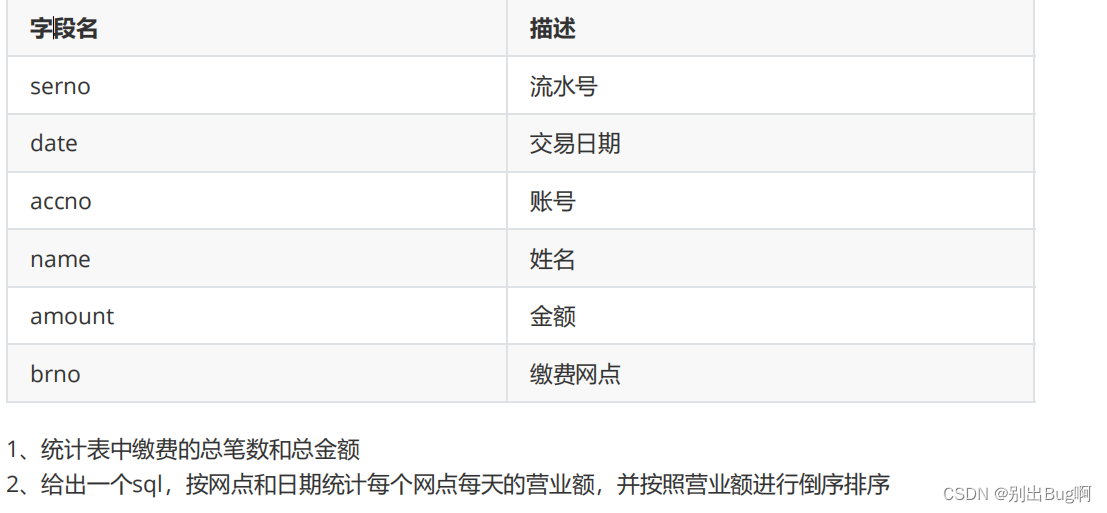
1.
select count(serno),sum(amount) from bank_bill;
2.
//网点 营业额 日期 select出来select brno,date,sum(amount) as money from bank_bill grouo by brno,date order by money desc;//按照网点和日期来分组 用金钱排序
连接查询
内连接查询
内连接就是查询两个表的交集,左连接就是查表一特有的数据;右连接就是查表二特有的数据

create table student(uid int unsigned primary key not null auto_increment,name varchar(50) not null,age tinyint unsigned not null,sex enum('M','W') not null);create table course(cid int unsigned primary key not null auto_increment,cname varchar(50) not null,credit tinyint unsigned not null);create table exame(uid int unsigned not null,cid int unsigned not null,time date not null,socre float not null,primary key(uid,cid));insert into student(name,age,sex) values('zhangsan',18,'M'),('ggg',19,'M'),('chchc',23,'W'),('liuliu',22,'M'),('linlin',21,'W');insert into student(name,age,sex) values('liuxiaokai',23,'W');insert into course(cname,credit) values('c++基础课程',5),('c++高级课程',10),('c++算法课程',15),('c++项目课程',22);insert into exame(uid,cid,time,socre) values(1,1,'2024-03-23',99.0),(1,2,'2024-03-24',89.0),(2,2,'2024-03-26',91.0),(2,3,'2024-03-24',92.0),(3,1,'2024-03-27',55.0),(3,2,'2024-03-22',100.0),(3,3,'2024-03-27',37.0),(3,4,'2024-03-23',49.0),(4,4,'2024-03-27',59.0),(5,2,'2024-03-23',79.0),(5,3,'2024-03-23',92.0),(5,4,'2024-03-26',82.0);//多表查询 学生的详细信息和课程的详细信息
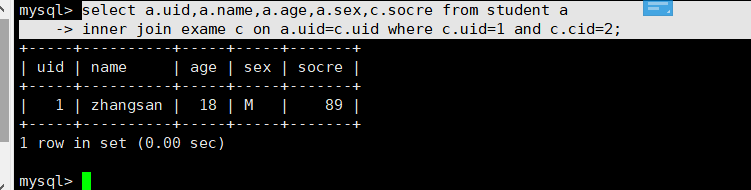
//预知的条件select socre from exame where uid=1 and cid=2;select a.uid,a.name,a.age,a.sex from student a where a.uid=1;//起别名select c.score from exame c where c.uid=1 and c.cid=2;// on a.uid=c.uid 区分大表 和小表 按照数据量来区分 小表永远是整表扫描 然后取大表搜索//从student小表中取出所有的a.uid 然后拿着这些uid去exame大表中搜索select a.uid,a.name,a.age,a.sex,c.socre from student ainner join exame c on a.uid=c.uid where c.uid=1 and c.cid=2;
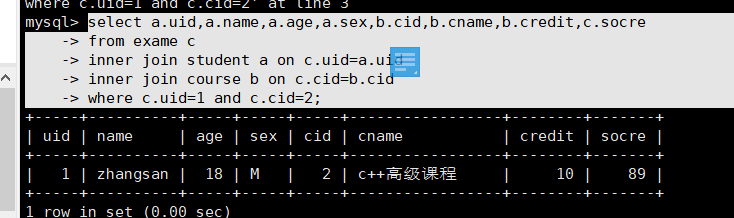
//三表联合查询select a.uid,a.name,a.age,a.sex,b.cid,b.cname,b.credit,c.socrefrom exame cinner join student a on c.uid=a.uidinner join course b on c.cid=b.cidwhere c.uid=1 and c.cid=2;
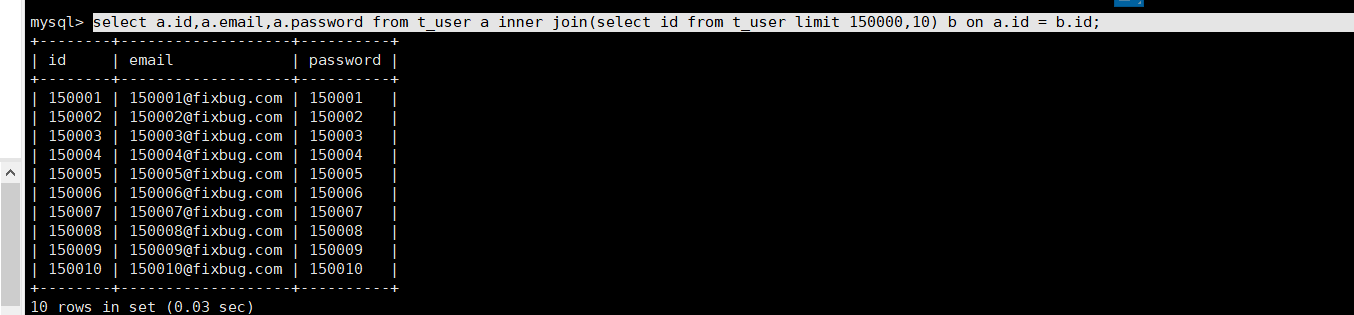
我们limit 便宜的时候select的数据也是影响我们偏移的小效率的,可能是我的数据太小了 看不出来
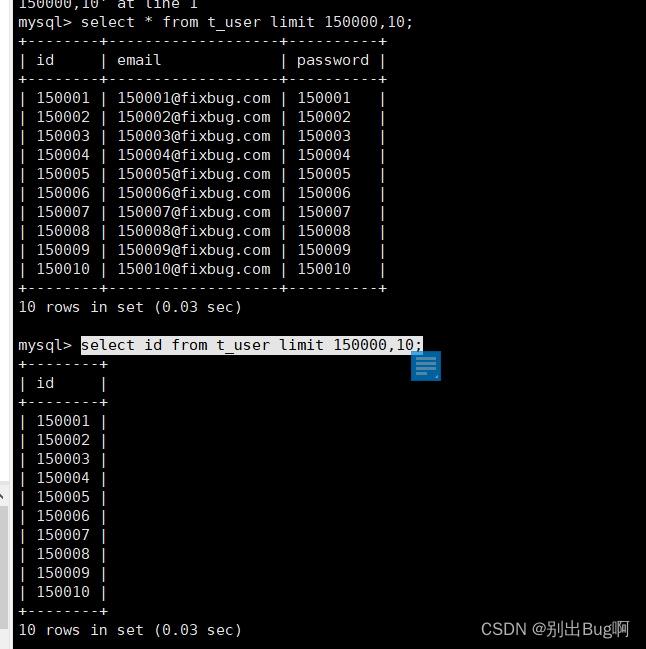
但是我们有的时候不知道偏移量的时候怎么提升呢
select a.id,a.email,a.password from t_user a inner join(select id from t_user limit 150000,10) b on a.id = b.id;//生成临时得表然后 联合查询
外连接查询
各存储引擎区别
MyISAM 不支持事务、也不支持外键,索引采用非聚集索引,其优势是访问的速度快,对事务完整性没 有要求,以 SELECT、INSERT 为主的应用基本上都可以使用这个存储引擎来创建表。MyISAM的表在磁 盘上存储成 3 个文件,其文件名都和表名相同,扩展名分别是: .frm(存储表定义) .MYD(MYData,存储数据) .MYI (MYIndex,存储索引) InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全,支持自动增长列,外键等功能, 索引采用聚集索引,索引和数据存储在同一个文件,所以InnoDB的表在磁盘上有两个文件,其文件名 都和表名相同,扩展名分别是: .frm(存储表的定义) .ibd(存储数据和索引) MEMORY 存储引擎使用存在内存中的内容来创建表。每个MEMORY 表实际只对应一个磁盘文件,格式 是.frm(表结构定义)。MEMORY 类型的表访问非常快,因为它的数据是放在内存中的,并且默认使 用 HASH 索引(不适合做范围查询),但是一旦服务关闭,表中的数据就会丢失掉。
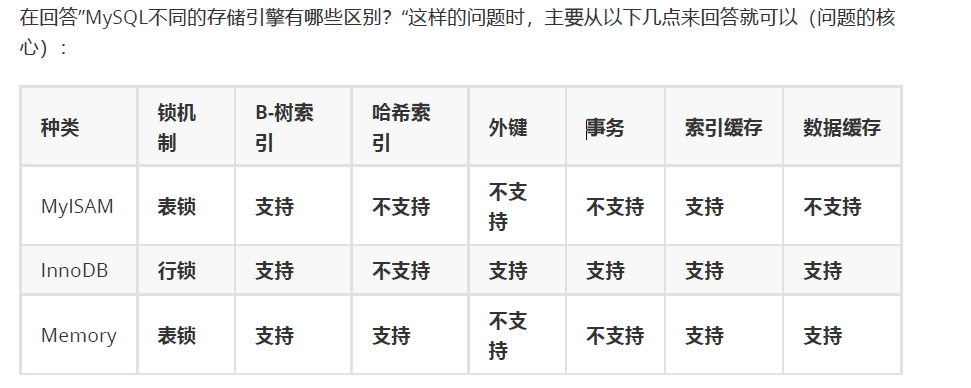
锁机制:表示数据库在并发请求访问的时候,多个事务在操作时,并发操作的粒度。
B-树索引和哈希索引:主要是加速SQL的查询速度。 外键:子表的字段依赖父表的主键,设置两张表的依赖关系。 事务:多个SQL语句,保证它们共同执行的原子操作,要么成功,要么失败,不能只成功一部分,失败需要回滚事务。 索引缓存和数据缓存:和MySQL Server的查询缓存相关,在没有对数据和索引做修改之前,重复查询可以不用进行磁盘I/O(数据库的性能提升,目的是为了减少磁盘I/O操作来提升数据库访问效率),读取上一次内存中查询的缓存就可以了。