canal本实验使用的是1.1.5,自行决定版本:[https://github.com/alibaba/canal/releases]
canal 涉及的几个角色
- canal-admin:canal 后台管理系统,管理 canal 服务
- canal-deployer:即canal-server(客户端)
- canal-instance: canal-server 中的一个处理实例(本质上不是一个实体jar服务)
- mysql
Mysql 开启 binlog
- 查看开启状态
#修改 mysql启动配置
vim /etc/my.cnf#添加binlog配置
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1000 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复#重启mysql
restart mysqld
安装 canal-admin
-
下载canal-admin,解压
-
修改配置文件 canal-admin/conf/application.yml
server:port: 8090 #canal-admin控制台访问端口 spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8# admin控制台数据库 spring.datasource:address: 127.0.0.1:3306database: canal_managerusername: rootpassword: 123456driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=falsehikari:maximum-pool-size: 30minimum-idle: 1# canal-deployer连接admin的访问账号,这里密码为明问。canal-deployer中为密文 canal:adminUser: adminadminPasswd: 123456 -
canal-admin 所需canal_manager数据库初始化
sql文件位置: canal-admin/conf/canal_manager.sql
-
启动
sh bin/startup.sh
访问控制台
http://127.0.0.1:8090
输入初始化默认账号密码 admin / 123456 进入系统,登录后可以在账号管理中修改密码。
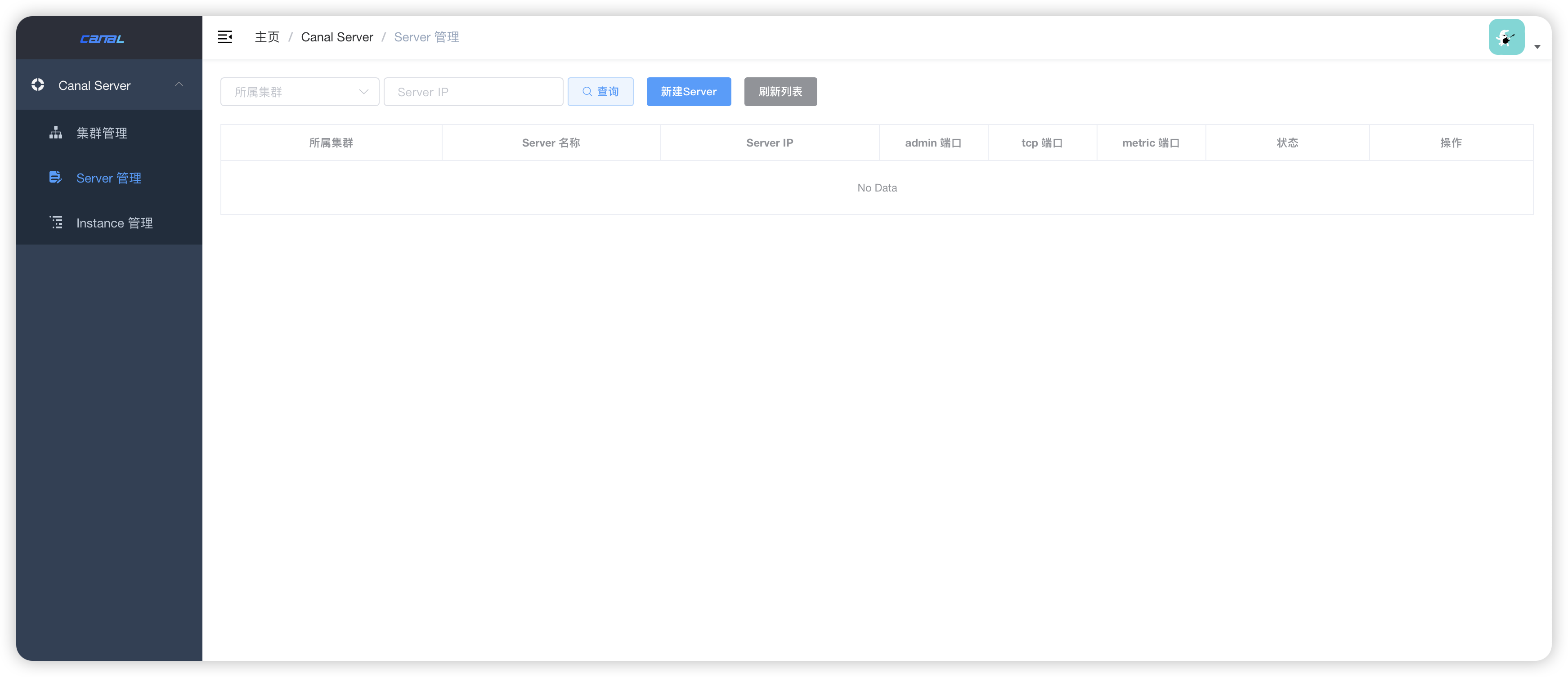
安装 canal-deployer
-
下载解压canal-deployer
-
修改配置文件
删除canal.properties,重命名canal_local.properties为canal.properties
# register ip 本服务在admin中的显示ip,名称也是用这个 canal.register.ip = 127.0.0.1# canal admin config #canal-admin的访问地址 canal.admin.manager = 127.0.0.1:8090 # canal-deployer的控制端口 canal.admin.port = 11110 # canal-admin的访问账号 canal.admin.user = admin # canal-admin的访问密码,与adminPasswd对应,这里是密文 canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 # admin auto register 集群配置 # 启动后自动注册到admin中 canal.admin.register.auto = true # 集群名称 ,这里是单点可空着即可 canal.admin.register.cluster = # 节点名称名称,里是单点可空着即可 canal.admin.register.name = -
启动 canal-deployer
# 启动服务
bin/startup.sh # 查看启动日志
tailf logs/canal/canal.log
- 刷新 admin 列表
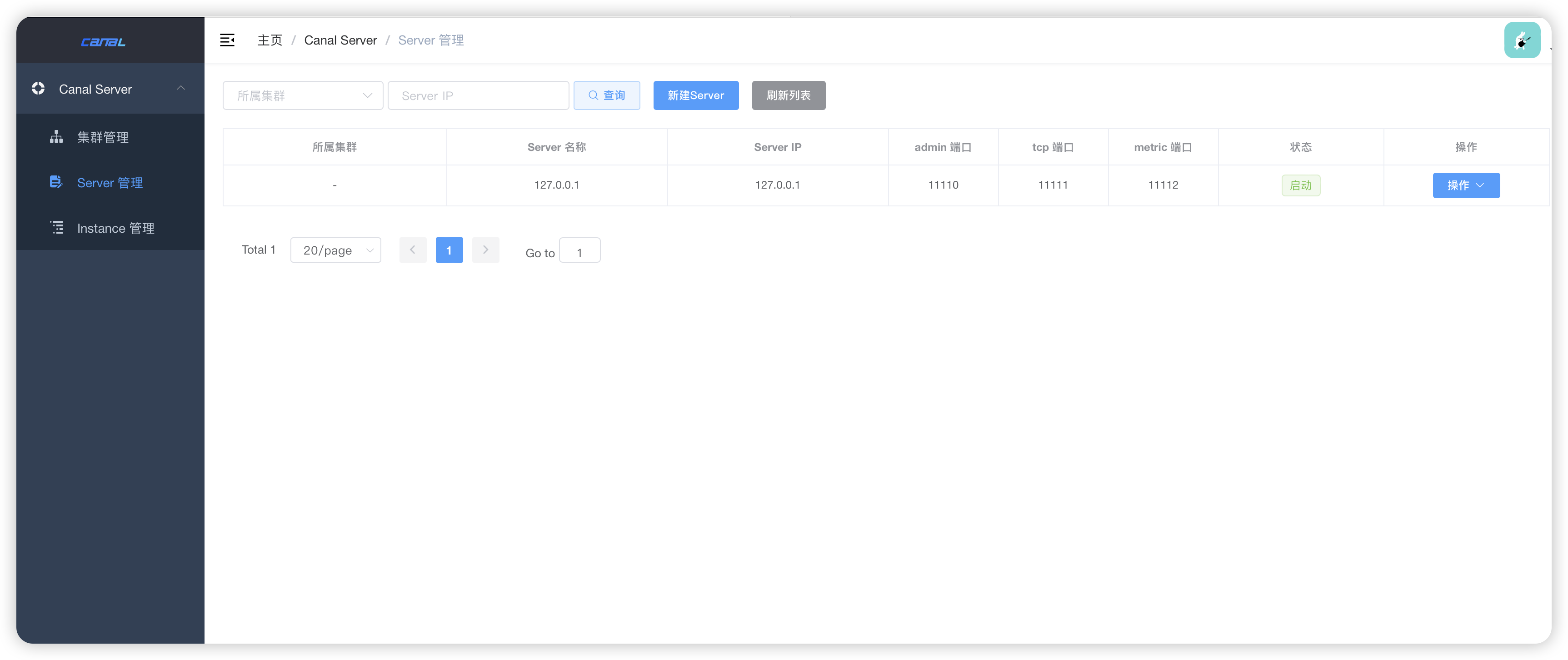
- server 配置,这里默认使用 tcp 方式【不修改,端口就用默认11111】,后续改为mq模式
#################################################
######### common argument #############
#################################################
# 使用tcp方式绑定的本地ip,mq方式不用填下
canal.ip =
# 注册到zk的本地ip,集群方式不用填写
canal.register.ip =
# tcp端口
canal.port = 11111
# 监控信息拉取端口
canal.metrics.pull.port = 11112
# canal instance user/passwd,实例的访问账号密码
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458# canal-admin连接配置,
# adminserver启动时使用本地配置,连上admin后,会统一使用admin的统一配置。
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
canal.admin.register.name =# zk 集群zk的配置
canal.zkServers =
# 数据刷新到zk的频率,ms
canal.zookeeper.flush.period = 1000
# 是否关闭netty
canal.withoutNetty = false
# 数据推送模式 tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
# 文件数据目录
canal.file.data.dir = ${canal.conf.dir}
# 文件数据刷新时间,ms
canal.file.flush.period = 1000
## 缓存的数据最大条数,必须为2的倍数
canal.instance.memory.buffer.size = 16384
## 每条数据的大小,byte。
canal.instance.memory.buffer.memunit = 1024
## 缓存模式
# MEMSIZE :按内存大小,限制为size*memunit
# ITEMSIZE:按条数,没有大小限制,可能出现内存溢出。
canal.instance.memory.batch.mode = MEMSIZE
# 是否开启raw数据传输模式,即json格式,关闭则使用byte模式
canal.instance.memory.rawEntry = true## 心跳检查
# 是否开启心跳检查
canal.instance.detecting.enable = false
# 心跳sql
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
# 心跳频率
canal.instance.detecting.interval.time = 3
# 失败重试次数
canal.instance.detecting.retry.threshold = 3
# 是否开启失败切换mysql,需要配置standby数据库
canal.instance.detecting.heartbeatHaEnable = false# 并发处理事务数,超过数量将分为多个事物提交
canal.instance.transaction.size = 1024
# mysql主备切换时,binlog监控需要回退的时间,防止切换导致的数据不同步
canal.instance.fallbackIntervalInSeconds = 60## 网络配置
# 数据发送缓冲区,byte
canal.instance.network.receiveBufferSize = 16384
# 数据接受缓冲区,byte
canal.instance.network.sendBufferSize = 16384
# 获取数据的超时时间,秒
canal.instance.network.soTimeout = 10# binlog 过滤配置
# 是否使用druid解析ddl
canal.instance.filter.druid.ddl = true
# 是否忽略dcl语句,权限相关
canal.instance.filter.query.dcl = true
# 是否忽略dml语句,数据操作
canal.instance.filter.query.dml = false
# 是否忽略ddl语句,表操作
canal.instance.filter.query.ddl = true
# 是否忽略table异常,用于排查table异常情况
canal.instance.filter.table.error = false
# 是否忽略dml的数据变动,如update/insert/update操作
canal.instance.filter.rows = false
# 忽略数据库事务的相关事件,如在写入kafka时,忽略TransactionBegin/Transactionend事件,
canal.instance.filter.transaction.entry = false
# 是否忽略dml的insert操作
canal.instance.filter.dml.insert = false
# 是否忽略dml的update操作
canal.instance.filter.dml.update = false
# 是否忽略dml的delete操作
canal.instance.filter.dml.delete = false# 支持的binlog文件格式
canal.instance.binlog.format = ROW,STATEMENT,MIXED
# 支持的binlog记录格式
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB# ddl语句是否单独处理,防止语句内有无序并发处理导致数据不一致。
canal.instance.get.ddl.isolation = false# 并行处理配置
# 是否开启并行处理binlog
canal.instance.parser.parallel = true
# 并发线程数,理论上不要超过可用处理器数
# 默认Runtime.getRuntime().availableProcessors()。
#canal.instance.parser.parallelThreadSize = 16
## 并行处理的缓冲区大小,kb 必须2的幂次方
canal.instance.parser.parallelBufferSize = 256# 是否开启table mate 的tsdb功能,时序数据库
canal.instance.tsdb.enable = true
# 存储修改table mate的记录文件,默认使用h2数据库
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# 快照存储间隔,小时
canal.instance.tsdb.snapshot.interval = 24
# 快照过期时间,小时
canal.instance.tsdb.snapshot.expire = 360#################################################
######### destinations #############
#################################################
# 当前server中的实例列表
canal.destinations =
# canal 配置文件目录
canal.conf.dir = ../conf
# 是否开启自动扫描,添加启动和删除停止实例
canal.auto.scan = true
# 自动扫描间隔时间,秒
canal.auto.scan.interval = 5# 当没有在binlog中找到位点,是否自动跳到最新的
# 警告:不确定逻辑时,还是不要开启。
canal.auto.reset.latest.pos.mode = false# tsdb配置路径,在canal.conf.dir路径下
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml# 全局配置加载方式
# manager: canal-admin控制台配置
# spring: 本地文件加载
canal.instance.global.mode = manager
# 是否开启lazy懒加载
canal.instance.global.lazy = false
# 管理配置的加载地址
canal.instance.global.manager.address = ${canal.admin.manager}
# 全局配置文件,当mode为Spring时使用,file单机模式,default集群模式,memory内存模式
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml# mq相关配置参考每个mq的处理模式,这里不单独说明
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = localcanal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8##################################################
######### Kafka #############
##################################################
# MQ地址
kafka.bootstrap.servers = 127.0.0.1:6667
# ack方式
# all:所有kafka节点同步完成返回,最慢
# 1: kafka主节点持久化后返回,一般快,
# 0: 发送后即返回,最快
kafka.acks = all
# 数据是否压缩
kafka.compression.type = none
# 每次发送消息的数据包大小,byte
kafka.batch.size = 16384
# 每次发送消息的间隔时间,ms
kafka.linger.ms = 1
# 最大请求大小,byte
kafka.max.request.size = 1048576
# 消息缓存大小
kafka.buffer.memory = 33554432
# 每个链接最大请求数
kafka.max.in.flight.requests.per.connection = 1
# 消息重试次数
kafka.retries = 0#kafka的kerberos 认证,开启需要配置2个认证文件
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag = ##################################################
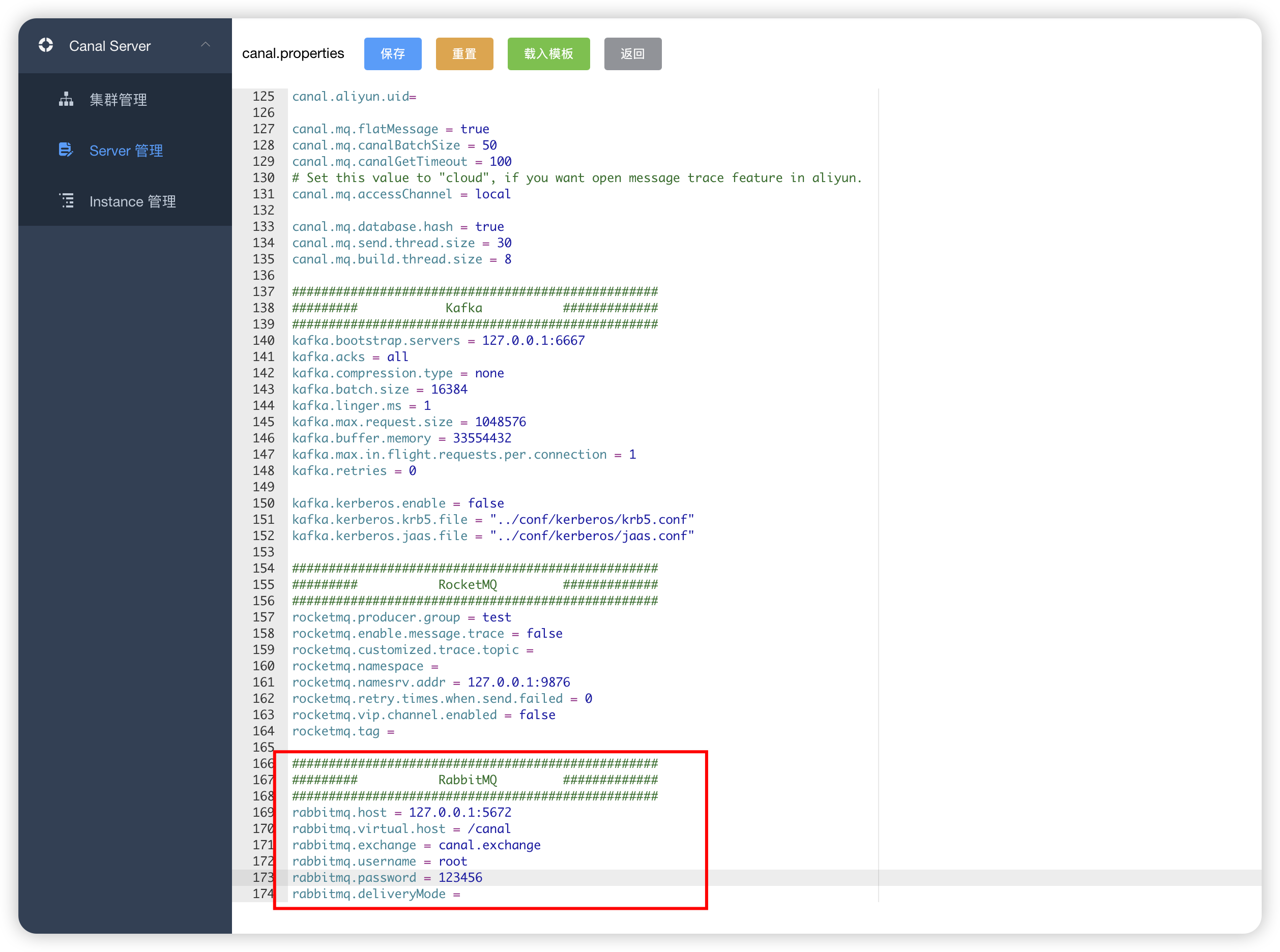
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
创建实例
- admin 控制台中创建
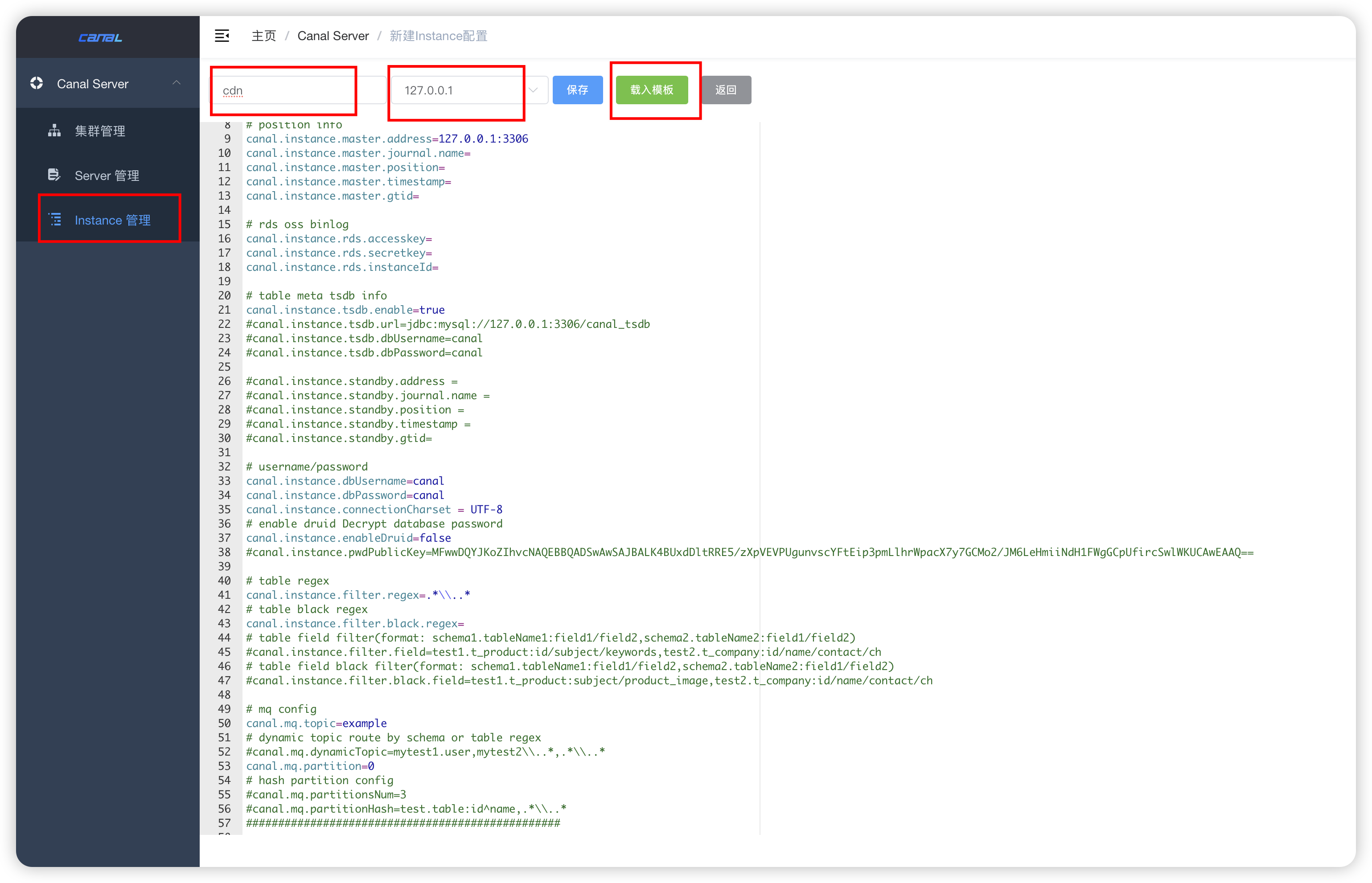
-
载入模版进行配置
如果没有特殊配置,修改数据库相关即可
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=root
canal.instance.dbPassword=123456canal.instance.filter相关的是监听数据库和表配置
#################################################
# 同mysql集群配置中的serverId,mysql的server_id参数
# canal.instance.mysql.slaveId=0# 开启gtid,生成同步数据全局id,防止主从不一致
canal.instance.gtidon=true# binlog的pos位点信息,修改时重建实例,或删除实例配置文件。
canal.instance.master.address=127.0.0.1:3306
#mysql起始的binlog文件,默认最新数据
canal.instance.master.journal.name=
#mysql起始的binlog偏移量,只会在配置binlog文件中寻找
canal.instance.master.position=
#mysql起始的binlog时间戳,只会在配置binlog文件中寻找
canal.instance.master.timestamp=
#ysql起始的binlog的gtid,只会在配置binlog文件中寻找
canal.instance.master.gtid=# 阿里云rds的sso配置
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=# 开启tsdb功能,记录table mate变动
canal.instance.tsdb.enable=true
# tsdb数据存储在位置
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal# 备用数据库,当master数据库检查失败后,切换到该节点继续消费
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=# mysql连接用户名和密码
canal.instance.dbUsername=root
canal.instance.dbPassword=123456
canal.instance.connectionCharset = UTF-8
# 开启druid数据库密码加密
canal.instance.enableDruid=false
# 加密公钥
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==# 匹配table表达式,需要处理的表
canal.instance.filter.regex=.*\\..*
# 匹配过滤table表达式,不需要处理的表
canal.instance.filter.black.regex=
# 匹配table字段表达式,指定传递字段,不指定全传。
#(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# 匹配过滤table字段表达式,不传递的字段,canal.instance.filter.field为空时生效@(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch# mq消息配置
# mq topic
canal.mq.topic=example
# 动态topic配置,topic为表名
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
# mq分区
canal.mq.partition=0
# hash分区数量 ,为空默认为1个分区
#canal.mq.partitionsNum=3
# hash分区主键,没有冒号就使用表名进行分区。有冒号使用字段进行分区。
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
- 启动 instance
tcp 模式测试
package com.cdn.demo.mainTcpCanal;import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;import java.net.InetSocketAddress;
import java.util.List;import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;public class TcpCanalClient {public static void main(String args[]) {// 创建链接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",11111), "cdn", "", "");int batchSize = 1000;int emptyCount = 0;try {connector.connect();connector.subscribe(".*\\..*");connector.rollback();int totalEmptyCount = 120;while (emptyCount < totalEmptyCount) {Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {emptyCount++;System.out.println("empty count : " + emptyCount);try {Thread.sleep(1000);} catch (InterruptedException e) {}} else {emptyCount = 0;// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);printEntry(message.getEntries());}connector.ack(batchId); // 提交确认// connector.rollback(batchId); // 处理失败, 回滚数据}System.out.println("empty too many times, exit");} finally {connector.disconnect();}}private static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue;}RowChange rowChage = null;try {rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),e);}EventType eventType = rowChage.getEventType();System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));for (RowData rowData : rowChage.getRowDatasList()) {if (eventType == EventType.DELETE) {printColumn(rowData.getBeforeColumnsList());} else if (eventType == EventType.INSERT) {printColumn(rowData.getAfterColumnsList());} else {System.out.println("-------> before");printColumn(rowData.getBeforeColumnsList());System.out.println("-------> after");printColumn(rowData.getAfterColumnsList());}}}}private static void printColumn(List<Column> columns) {for (Column column : columns) {System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());}}
}
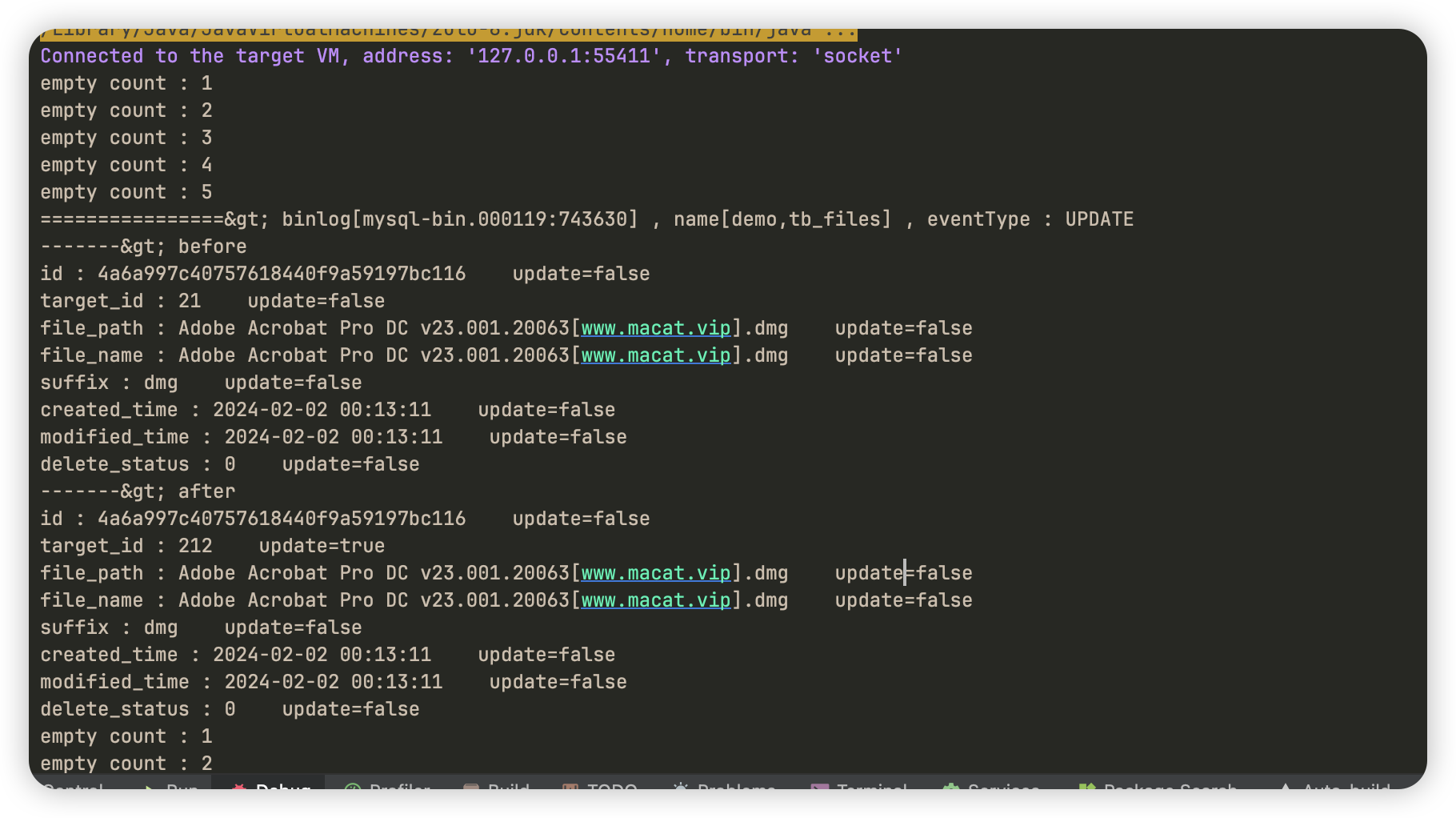
- 运行 main 启动后,修改 mysql 中数据,即可获取到修改内容。
---------------------------- 修改为MQ模式-----------------------
在canal-admin修改canal-deployer中的配置文件
只需要修改两项即可
-
数据推送模式

-
MQ相关配置
监听代码
package com.cdn.demo.rabbit;/*** @author 蔡定努* @date 2024/04/01 13:38*/import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.AcknowledgeMode;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;/*** Canal + RabbitMQ 监听数据库数据变化* @date 2021/11/4 23:14*/
@Component
@Slf4j
@RequiredArgsConstructor
public class CanalRabbitMqListener {@RabbitListener(bindings = {@QueueBinding(value = @Queue(value = "canal.queue", durable = "true"),exchange = @Exchange(value = "canal.exchange"),key = "canal.routing.key")},ackMode = "AUTO")public void handleDataChange(String message) {JSONObject jsonObject = JSON.parseObject(message);JSONArray data = jsonObject.getJSONArray("data");String database = jsonObject.getString("database");String id=jsonObject.getString("id");JSONArray oldData = jsonObject.getJSONArray("old");String tableName = jsonObject.getString("table");String type = jsonObject.getString("type");Boolean isDdl = jsonObject.getBoolean("isDdl");log.info("Canal 监听 {} ", message);}
}