0 Introduction
谷歌开源的BERT项目在Github上,视频讲解可以参考B站上的一个视频
1 GLUE部分基准数据集介绍
- GLUE数据集官网
- GLUE数据集下载,建议下载运行这个.py脚本文件进行数据集的下载,如果连接无法打开,运行下面代码。运行下面代码后,会自动下载GLUE数据集到本地项目文件夹中,所包含的数据集有
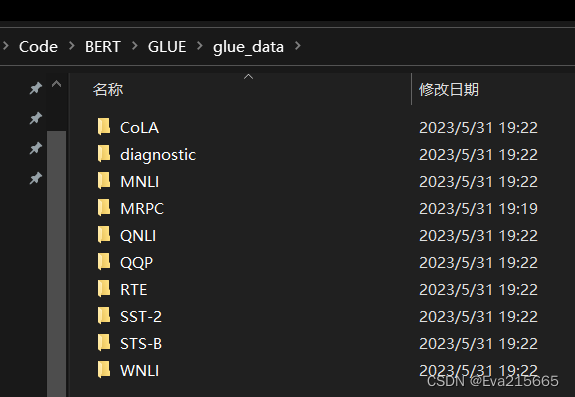
CoLA,diagnostic,MNLI,MRPC,QNLI,QQP,RTE,SST-2,STS-B,WNLI等,关于这些数据集的详细中文介绍,参考这篇博客,本例是在MRPC数据集上构建任务。 - 关于MRPC数据集:本例中是在MRPC数据集上进行构建的,因为MRPC数据集较小,只有3600多条文本数据,但如下面代码中的注释所说,由于版权问题,不再托管MRPC数据集,需要手动下载。下载方式:首先去官网,下载到
MSRParaphraseCorpus.msi文件,双击安装后,会产生一个文件夹,里面即包含了MPRC数据。
数据集搞定后,文件结构如下图
以下是用于下载GLUE数据集的脚本文件download_glue_data.py
''' Script for downloading all GLUE data.Note: for legal reasons, we are unable to host MRPC.
You can either use the version hosted by the SentEval team, which is already tokenized,
or you can download the original data from (https://download.microsoft.com/download/D/4/6/D46FF87A-F6B9-4252-AA8B-3604ED519838/MSRParaphraseCorpus.msi) and extract the data from it manually.
For Windows users, you can run the .msi file. For Mac and Linux users, consider an external library such as 'cabextract' (see below for an example).
You should then rename and place specific files in a folder (see below for an example).mkdir MRPC
cabextract MSRParaphraseCorpus.msi -d MRPC
cat MRPC/_2DEC3DBE877E4DB192D17C0256E90F1D | tr -d $'\r' > MRPC/msr_paraphrase_train.txt
cat MRPC/_D7B391F9EAFF4B1B8BCE8F21B20B1B61 | tr -d $'\r' > MRPC/msr_paraphrase_test.txt
rm MRPC/_*
rm MSRParaphraseCorpus.msi1/30/19: It looks like SentEval is no longer hosting their extracted and tokenized MRPC data, so you'll need to download the data from the original source for now.
2/11/19: It looks like SentEval actually *is* hosting the extracted data. Hooray!
'''import os
import sys
import shutil
import argparse
import tempfile
import urllib.request
import zipfileimport urllib as URLLIB
import urllib.response
import urllib.parse
import io
# from six.moves import urllibTASKS = ["CoLA", "SST", "MRPC", "QQP", "STS", "MNLI", "QNLI", "RTE", "WNLI", "diagnostic"]
TASK2PATH = {"CoLA":'https://dl.fbaipublicfiles.com/glue/data/CoLA.zip',"SST":'https://dl.fbaipublicfiles.com/glue/data/SST-2.zip',"QQP":'https://dl.fbaipublicfiles.com/glue/data/QQP-clean.zip',"STS":'https://dl.fbaipublicfiles.com/glue/data/STS-B.zip',"MNLI":'https://dl.fbaipublicfiles.com/glue/data/MNLI.zip',"QNLI":'https://dl.fbaipublicfiles.com/glue/data/QNLIv2.zip',"RTE":'https://dl.fbaipublicfiles.com/glue/data/RTE.zip',"WNLI":'https://dl.fbaipublicfiles.com/glue/data/WNLI.zip',"diagnostic":'https://dl.fbaipublicfiles.com/glue/data/AX.tsv'}MRPC_TRAIN = 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_train.txt'
MRPC_TEST = 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_test.txt'def download_and_extract(task, data_dir):print("Downloading and extracting %s..." % task)if task == "MNLI":print("\tNote (12/10/20): This script no longer downloads SNLI. You will need to manually download and format the data to use SNLI.")data_file = "%s.zip" % taskurllib.request.urlretrieve(TASK2PATH[task], data_file)with zipfile.ZipFile(data_file) as zip_ref:zip_ref.extractall(data_dir)os.remove(data_file)print("\tCompleted!")def format_mrpc(data_dir, path_to_data):print("Processing MRPC...")mrpc_dir = os.path.join(data_dir, "MRPC")if not os.path.isdir(mrpc_dir):os.mkdir(mrpc_dir)if path_to_data:mrpc_train_file = os.path.join(path_to_data, "msr_paraphrase_train.txt")mrpc_test_file = os.path.join(path_to_data, "msr_paraphrase_test.txt")else:try:mrpc_train_file = os.path.join(mrpc_dir, "msr_paraphrase_train.txt")mrpc_test_file = os.path.join(mrpc_dir, "msr_paraphrase_test.txt")URLLIB.request.urlretrieve(MRPC_TRAIN, mrpc_train_file)URLLIB.request.urlretrieve(MRPC_TEST, mrpc_test_file)except urllib.error.HTTPError:print("Error downloading MRPC")returnassert os.path.isfile(mrpc_train_file), "Train data not found at %s" % mrpc_train_fileassert os.path.isfile(mrpc_test_file), "Test data not found at %s" % mrpc_test_filewith io.open(mrpc_test_file, encoding='utf-8') as data_fh, \io.open(os.path.join(mrpc_dir, "test.tsv"), 'w', encoding='utf-8') as test_fh:header = data_fh.readline()test_fh.write("index\t#1 ID\t#2 ID\t#1 String\t#2 String\n")for idx, row in enumerate(data_fh):label, id1, id2, s1, s2 = row.strip().split('\t')test_fh.write("%d\t%s\t%s\t%s\t%s\n" % (idx, id1, id2, s1, s2))try:URLLIB.request.urlretrieve(TASK2PATH["MRPC"], os.path.join(mrpc_dir, "dev_ids.tsv"))except KeyError or urllib.error.HTTPError:print("\tError downloading standard development IDs for MRPC. You will need to manually split your data.")returndev_ids = []with io.open(os.path.join(mrpc_dir, "dev_ids.tsv"), encoding='utf-8') as ids_fh:for row in ids_fh:dev_ids.append(row.strip().split('\t'))with io.open(mrpc_train_file, encoding='utf-8') as data_fh, \io.open(os.path.join(mrpc_dir, "train.tsv"), 'w', encoding='utf-8') as train_fh, \io.open(os.path.join(mrpc_dir, "dev.tsv"), 'w', encoding='utf-8') as dev_fh:header = data_fh.readline()train_fh.write(header)dev_fh.write(header)for row in data_fh:label, id1, id2, s1, s2 = row.strip().split('\t')if [id1, id2] in dev_ids:dev_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))else:train_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))print("\tCompleted!")def download_diagnostic(data_dir):print("Downloading and extracting diagnostic...")if not os.path.isdir(os.path.join(data_dir, "diagnostic")):os.mkdir(os.path.join(data_dir, "diagnostic"))data_file = os.path.join(data_dir, "diagnostic", "diagnostic.tsv")urllib.request.urlretrieve(TASK2PATH["diagnostic"], data_file)print("\tCompleted!")returndef get_tasks(task_names):task_names = task_names.split(',')if "all" in task_names:tasks = TASKSelse:tasks = []for task_name in task_names:assert task_name in TASKS, "Task %s not found!" % task_nametasks.append(task_name)return tasksdef main(arguments):parser = argparse.ArgumentParser()parser.add_argument('--data_dir', help='directory to save data to', type=str, default='glue_data')parser.add_argument('--tasks', help='tasks to download data for as a comma separated string',type=str, default='all')parser.add_argument('--path_to_mrpc', help='path to directory containing extracted MRPC data, msr_paraphrase_train.txt and msr_paraphrase_text.txt',type=str, default='')args = parser.parse_args(arguments)if not os.path.isdir(args.data_dir):os.mkdir(args.data_dir)tasks = get_tasks(args.tasks)for task in tasks:if task == 'MRPC':format_mrpc(args.data_dir, args.path_to_mrpc)elif task == 'diagnostic':download_diagnostic(args.data_dir)else:download_and_extract(task, args.data_dir)if __name__ == '__main__':sys.exit(main(sys.argv[1:]))
- 关于微软MRPC数据集
2 下载BERT项目
- 用Git工具从BERT开源项目上把项目完整克隆下来,如何使用Git工具从GitHub或者Gitee上克隆项目,参见这里
- 创建一个用于该项目的虚拟环境,参见这里
- 在该虚拟环境下,下载安装该项目所需的依赖,即
requirements.txt,安装方式,在激活当前虚拟环境的情况下,执行pip install -r D:\Code\BERT\bert\requirements.txt,其中D:\Code\BERT\bert\是requirements.txt所在路径