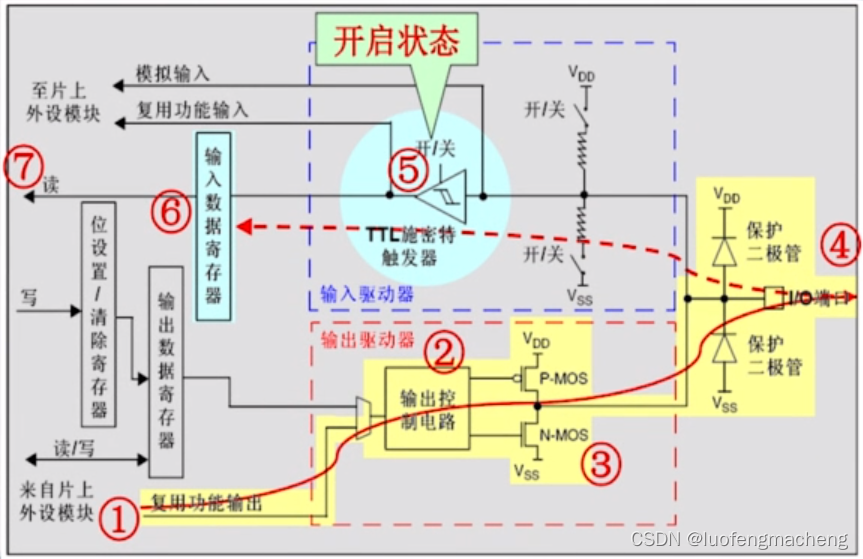
矩阵做 transpose
import torch tensor_Matrix_A = torch.tensor([[1,2],[4,5],[7,8]
], dtype=torch.float32)
print(tensor_Matrix_A.T)# 结果
tensor([[1., 4., 7.],[2., 5., 8.]])torch.nn.Linear() 模块也被称为 “feed-forward layer"或者"fully connected layer”。公式如下:
y = x ⋅ A T + b y = x \cdot A^T + b y=x⋅AT+b
解释上面的公式:
- X: It is the input to the layer (deep learning is a stack of layers like
torch.nn.Linear()and others on top of each other). - A: It is the weights matrix created by the layer, this starts out as random numbers that get adjusted as a neural network learns to better represent patterns in the data (notice the “T”, that’s because the weights matrix gets transposed).
- b: It is the bias term used to slightly offset the weights and inputs
- y: It is the output (a manipulation of the input in the hopes to discover patterns in it).
使用代码来举例
import torchtensor_Matrix_A = torch.tensor([[1,2],[4,5],[7,8]
], dtype=torch.float32)torch.manual_seed(42)
linear = torch.nn.Linear(in_features=2,out_features=6)
print(linear)
x = tensor_Matrix_B
output = linear(x)
print(f"linear weight: {linear.weight}") # 得将获得结果进行 transposed, 再做 linear 预算
print(f"Input shape: {x.shape}\n")
print(f"Out:\n{output}\n\nOutput shape: {output.shape}")# 结果如下:
Linear(in_features=2, out_features=6, bias=True)
linear weight: Parameter containing:
tensor([[ 0.5406, 0.5869],[-0.1657, 0.6496],[-0.1549, 0.1427],[-0.3443, 0.4153],[ 0.6233, -0.5188],[ 0.6146, 0.1323]], requires_grad=True)
Input shape: torch.Size([3, 2])Out:
tensor([[ 1.1093, 0.7453, 0.4836, 0.3154, 0.0263, 0.2369],[ 3.9513, 2.3627, 0.6018, 0.8727, -0.2832, 1.8631],[ 5.6657, 3.4961, 0.7323, 1.3590, -0.6974, 2.7424]],grad_fn=<AddmmBackward0>)Output shape: torch.Size([3, 6])看到这里,点个赞呗~