Python面试笔记
- Python
- Q. Python中可变数据类型与不可变数据类型,浅拷贝与深拷贝详解
- Q. 解释什么是lambda函数?它有什么好处?
- Q. 什么是装饰器?
- Q. 什么是Python的垃圾回收机制?
- Q. Python内置函数dir的用法?
- Q. Python中两边都有下划线的方法有什么含义?
- Q. Python中单下划线和双下划线的区别
- Q. __new__和__init__区别
- Q. 什么是迭代器和⽣成器?
- Q. 什么是异常处理?
- Q. Python断言(assert)
- Q. Python中`*` 和 `**`用法?
Python
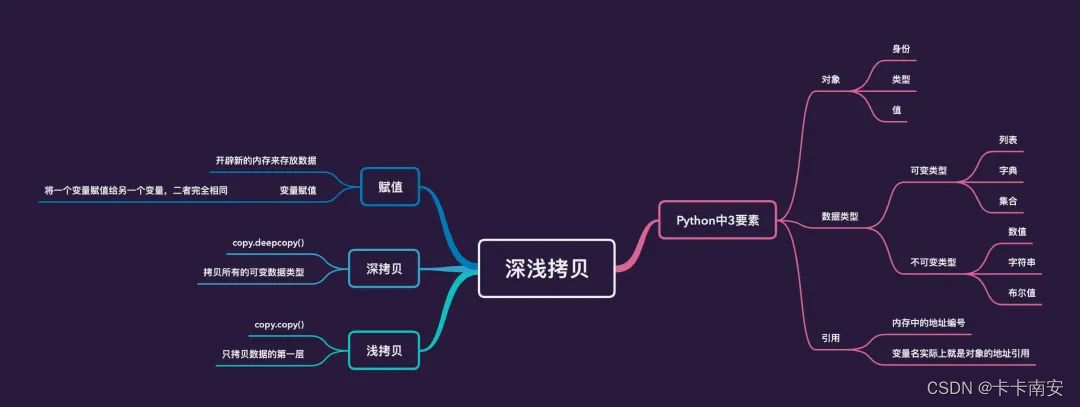
Q. Python中可变数据类型与不可变数据类型,浅拷贝与深拷贝详解
【Python基础】Python的深浅拷贝讲解
Q. 解释什么是lambda函数?它有什么好处?
Lambda函数是Python中的匿名函数。
Lambda函数在Python中被广泛使用,主要是因为它们提供了一种快速定义单行最小函数的方式,而无需使用常规的def关键字。这种函数通常用于需要一个简单操作的地方,例如在列表推导式、map()、filter()等高阶函数中作为参数传递。Lambda函数的基本语法结构是:lambda parameters_list: expression,其中parameters_list是函数的参数列表,而expression则是基于这些参数的表达式,该表达式的结果将被返回。
Lambda函数的优点主要包括代码简洁、无需增加额外变量、即时定义与使用。具体内容如下:
- 代码简洁:由于lambda函数通常只包含一个表达式,因此代码非常简洁,可以提高代码的可读性。
- 无需增加额外变量:因为lambda函数是匿名的,所以不需要为其分配一个名字,这有助于减少程序中的变量数量,避免命名冲突。
- 即时定义与使用:可以在需要时立刻定义并使用,不必像常规函数那样先定义再调用。
# case 1
add = lambda x, y: x + y
result = add(3, 5)
print(result) # 输出:8
# case 2
students = [("Alice", 25), ("Bob", 20), ("Charlie", 30)]
students.sort(key=lambda student: student[1])
print(students) # 输出:[('Bob', 20), ('Alice', 25), ('Charlie', 30)]
# case 3
numbers = [1, 2, 3, 4, 5, 6]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 输出:[2, 4, 6]
Lambda表达式通常⽤于需要传递函数作为参数的函数(例如 map 、 filter 、 sorted 等),或
者在需要定义⾮常简单的匿名函数时。
总之,尽管lambda函数有许多优点,但它们也受到一些限制,如只能包含一个表达式,不能包含复杂的逻辑或语句,且没有文档字符串和名称。因此,在决定是否使用lambda函数时,应当根据实际需求和上下文进行权衡。
Q. 什么是装饰器?
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
def my_decorator(func): def wrapper(): print("Something is happening before the function is called.") func() print("Something is happening after the function is called.") return wrapper @my_decorator
def say_hello(): print("Hello!") # 当调用 say_hello 时,实际上是调用了装饰器返回的 wrapper 函数
say_hello()输出:
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
Q. 什么是Python的垃圾回收机制?
Python的垃圾回收机制主要负责自动管理内存,释放不再使用的对象所占用的内存空间。
Python的垃圾回收机制主要包括以下几种:
- 引用计数(Reference Counting)。这是Python中最基本的垃圾回收方法。每个对象都有一个引用计数,记录有多少个变量指向该对象。当引用计数为0时,表示该对象不再被使用,可以被回收。
- 标记-清除(Mark and Sweep)。这种方法用于处理循环引用的情况。当内存空间即将被占满时,Python会暂停程序,从头到尾扫描所有对象,并标记所有可达的对象。然后,清除所有未被标记的对象,回收它们占用的内存空间。
- 分代回收(Generational Collection)。为了提高垃圾回收的效率,Python引入了分代回收机制。对象被分为不同的代,如第0代和第1代等。新创建的对象通常放在第0代,而经过多次垃圾回收仍然存活的对象会被提升到更高的代。垃圾回收器会更多地检查低代中的对象,而对高代中的对象进行较少的检查,从而提高垃圾回收的效率。
需要注意的是,Python的垃圾回收机制是自动进行的,开发者不需要手动管理内存。垃圾回收器会根据需要定期启动,并在合适的时机回收不再使用的对象。
Q. Python内置函数dir的用法?
在 Python 中,dir() 是一个内置函数,用于查找对象的所有属性和方法。它返回一个字符串列表,包含了对象的所有属性和方法的名称。
class MyClass:def __init__(self):self.name = "John"def say_hello(self):print("Hello, world!")obj = MyClass()print("对象 obj 的属性和方法:", dir(obj))输出:
对象 obj 的属性和方法: ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'say_hello']
Q. Python中两边都有下划线的方法有什么含义?
在Python中,两边都有双下划线的方法名被称为魔法方法(magic methods)。这些方法是Python语言的基础,它们为Python提供了强大的内置功能。例如,__init__ 方法是类的构造函数,__str__ 方法定义了对象被转换为字符串时的行为。
以下是一个简单的类示例,它定义了一个带有两边都有双下划线的方法:
class MyClass:def __init__(self, value):self.value = valuedef __str__(self):return f"MyClass with value: {self.value}"# 使用类
obj = MyClass(10)
print(obj) # 输出: MyClass with value: 10
Python中还有很多其他的魔法方法,以下是一些常用的魔法方法:
__init__:构造函数,当一个对象被创建时会自动调用。
__del__:析构函数,当一个对象被销毁时会自动调用。
__str__:返回一个对象的字符串表示,通常用于print函数。
__repr__:返回一个对象的官方字符串表示,通常用于调试。
__call__:允许一个对象像函数那样被调用。
__getitem__、__setitem__、__delitem__:用于自定义索引操作,如obj[key]。
__len__:返回对象的长度,常用于len()函数。
__iter__:返回一个迭代器,用于遍历对象。
__enter__ 和 __exit__:用于实现上下文管理协议,如with语句。
__add__、__sub__、__mul__ 等:用于自定义算术运算符的行为。
这些魔法方法允许你自定义Python对象的行为,使其更符合你的需求。你可以根据需要实现这些方法来扩展Python类的功能。
Q. Python中单下划线和双下划线的区别
- “单下划线” 开始的成员变量叫做保护变量,意思是只有类对象和子类对象自己能访问到这些变量,需通过类提供的接口进行访问,不能用“from xxx import *”而导入;
- “双下划线” 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。仍然可以通过_{classname}__name来访问__name变量。但是强烈建议你不要这么干,因为不同版本的Python解释器可能会把__name改成不同的变量名。
Q. __new__和__init__区别
__new__与__init__区别总共有四个方面:
- 功能上的区别: 前者生成类实例对象空间的,后者是初始化对象空间并给对象赋值的;
- 执行顺序: 先执行__new__方法生成类对象空间才能执行后者
- 返回值: 前者有返回值,后者没有返回值
- 前者是静态方法, 后者是构造方法。

Q. 什么是迭代器和⽣成器?
迭代器(Iterator)和⽣成器(Generator)都是Python中⽤于处理迭代的重要概念,允许逐个访问数据项,⽽⽆需将所有数据加载到内存中,这在处理⼤型数据集合时⾮常有⽤。尽管有⼀些相似之处,但在实现和⽤法上有⼀些关键的区别。
1.迭代器(Iterator)
迭代器是⼀个对象,它可以通过调⽤ __next__() ⽅法逐个返回集合中的元素。迭代器通常⽤于遍
历集合,如列表、元组、字典等,以及⾃定义的可迭代对象。的核⼼特点是惰性计算,即只在需要时才计算下⼀个元素。
Python的内置函数 iter() 可以⽤于将可迭代对象转换为迭代器,⽽ next() 函数⽤于获取迭代
器的下⼀个元素。当没有更多元素可供迭代时,迭代器会引发 StopIteration 异常。
numbers = [1, 2, 3, 4, 5]
iter_numbers = iter(numbers)
print(next(iter_numbers)) # 输出:1
print(next(iter_numbers)) # 输出:2
2.生成器(Generator)
生成器是⼀种特殊的迭代器,它可以通过函数来创建。⽣成器函数使⽤ yield 关键字来产⽣值,并且会保持函数的状态,以便在下⼀次调⽤时继续执⾏。⽣成器允许按需⽣成数据,⽽不必将所有数据存储在内存中。
⽣成器有两种创建⽅式:
- 使⽤⽣成器函数:定义⼀个函数,其中包含 yield 语句来⽣成值。
def countdown(n):while n > 0:yield nn -= 1
gen = countdown(5)
for num in gen:print(num)
- 使⽤⽣成器表达式:类似于列表推导式,但是使⽤圆括号⽽不是⽅括号,并且按需⽣成数据。
gen = (x for x in range(5))
for num in gen:print(num)
⽣成器通常⽤于处理⼤型数据集或需要逐个⽣成数据的情况,因为不需要⼀次性加载所有数据到内存中,从⽽节省了内存资源。
总之,迭代器和⽣成器都是处理迭代的强⼤⼯具,允许⾼效地处理⼤型数据集和按需⽣成数据。可以根据任务的需求选择使⽤哪种⽅式。
Q. 什么是异常处理?
异常处理是⼀种编程技术,⽤于在程序执⾏期间捕获、处理和处理可能发⽣的异常情况或错误。异常是指在程序执⾏过程中出现的不正常情况,可能导致程序崩溃或产⽣不可预料的结果。异常处理的⽬标是使程序能够优雅地应对异常情况,⽽不是因异常⽽终⽌或崩溃。
在Python中,异常处理通常使⽤ try 和 except 语句来实现。基本的异常处理结构如下:
try:# 可能引发异常的代码块
except ExceptionType:# 处理异常的代码块
- try 语句块包含可能引发异常的代码,它会被监视以检查是否发⽣异常。
- 如果在 try 块中的代码引发了指定类型的异常( ExceptionType ),则程序将跳转到与该异常匹配的 except 块,执⾏异常处理代码。
- 如果在 try 块中没有引发异常,则 except 块将被跳过,程序将继续执⾏ try 块之后的代码。
try:num = int(input("请输⼊⼀个整数:"))result = 10 / num
except ZeroDivisionError:print("除以零错误")
except ValueError:print("输⼊不是有效的整数")
else:print("结果是:", result)
finally:print("结束")
- else语句块中的代码会在try块没有抛出任何异常的情况下运行。
- finally语句块中的代码无论是否发生异常都会被执行。
Q. Python断言(assert)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。
语法格式如下:
assert expression
#等价于:
if not expression:raise AssertionError#assert后面也可以紧跟参数:assert expression [, arguments]
#等价于:
if not expression:raise AssertionError(arguments)
例子:
>>> assert True # 条件为 true 正常执行
>>> assert False # 条件为 false 触发异常
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AssertionError
>>> assert 1==1 # 条件为 true 正常执行
>>> assert 1==2 # 条件为 false 触发异常
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AssertionError>>> assert 1==2, '1 不等于 2'
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AssertionError: 1 不等于 2
>>>
Q. Python中* 和 **用法?
在 Python 中,* 和 ** 具有语法多义性,具体来说是有四类用法。
1.算数运算
>>> 2 * 5 #乘法
//10
>>> 2 ** 5 #乘方
//32
2.函数形参
*args 和 **kwargs 主要用于函数定义。
你可以将不定数量的参数传递给一个函数。不定的意思是:预先并不知道, 函数使用者会传递多少个参数给你, 所以在这个场景下使用这两个关键字。其实并不是必须写成 *args 和 **kwargs。 *(星号) 才是必须的. 你也可以写成 *ar 和 **k 。而写成 *args 和**kwargs 只是一个通俗的命名约定。
python函数传递参数的方式有两种:
- 位置参数(positional argument)
- 关键词参数(keyword argument)
*args 与 **kwargs 的区别,两者都是 python 中的可变参数:
*args表示任何多个无名参数,它本质是一个 tuple**kwargs表示关键字参数,它本质上是一个 dict
如果同时使用 *args 和 **kwargs 时,必须 *args 参数列要在 **kwargs 之前。
>>> def fun(*args, **kwargs):
... print('args=', args)
... print('kwargs=', kwargs)
...
>>> fun(1, 2, 3, 4, A='a', B='b', C='c', D='d')
//args= (1, 2, 3, 4)
//kwargs= {'A': 'a', 'B': 'b', 'C': 'c', 'D': 'd'}
使用*args:
>>> def fun(name, *args):
... print('你好:', name)
... for i in args:
... print("你的宠物有:", i)
...
>>> fun("Geek", "dog", "cat")
//你好: Geek
//你的宠物有: dog
//你的宠物有: cat
使用 **kwargs :
>>> def fun(**kwargs):
... for key, value in kwargs.items():
... print("{0} 喜欢 {1}".format(key, value))
...
>>> fun(Geek="cat", cat="box")
//Geek 喜欢 cat
//cat 喜欢 box
3.函数实参(解引用)
如果函数的形参是定长参数,也可以使用 *args 和 **kwargs 调用函数,类似对元组和字典进行解引用:
>>> def fun(data1, data2, data3):
... print("data1: ", data1)
... print("data2: ", data2)
... print("data3: ", data3)
...
>>> args = ("one", 2, 3)
>>> fun(*args)
data1: one
data2: 2
data3: 3
>>> kwargs = {"data3": "one", "data2": 2, "data1": 3}
>>> fun(**kwargs)
data1: 3
data2: 2
data3: one
4.序列解包
序列解包没有**
>>> a, b, *c = 0, 1, 2, 3
>>> a
0
>>> b
1
>>> c
[2, 3]