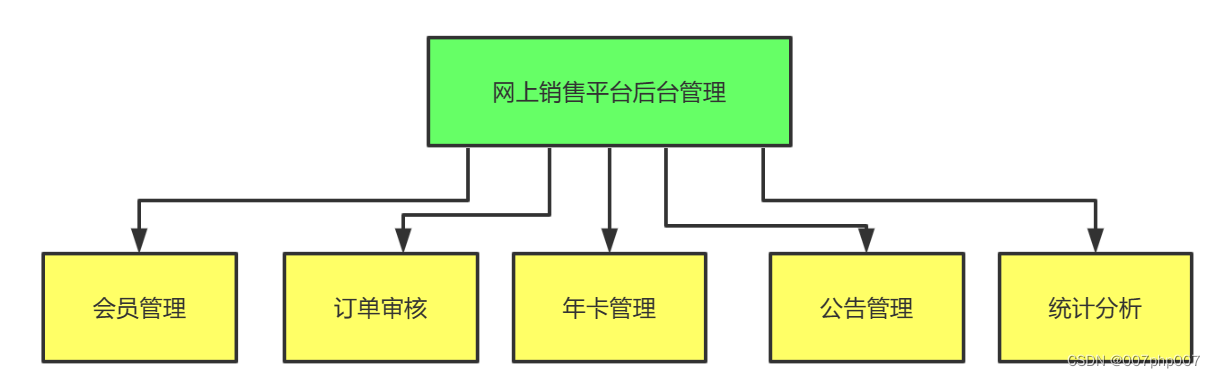
Linux认识与学习BASH
- 认识BASH这个Shell
- shell是什么
- 系统的合法shell与/etc/shells功能
- Bash Shell的功能
- 查询命令是否为Bash shell 的内置命令(type)
- 命令的执行与快速编辑按钮
- shell的变量功能
- 什么是变量?
- 变量的使用与设置:echo、变量设置规则、unset
- 环境变量的功能
- 用env观察环境变量与常见环境变量说明
- 用set观察所有变量(含环境变量与自定义变量)
- 影响显示结果的语系变量(locale)
- 变量的有效范围
- 变量键盘读取、数组与声明:read、array、declare
- 与文件系统及程序的限制关系:ulimit
- 变量内容的删除、取代与替换
- 变量内容的删除与替换
- 变量的测试与内容替换
- Bsah shell的操作环境
- 路径与命令查找顺序
- bash的登录与欢迎信息:/etc/issue、/etc/motd
- bash的环境配置文件如下
- 终端的环境设置:stty、set
- 通配符与特殊符号
- 数据流重定向
- 什么是数据流重定向
- 命令执行的判断根据:;、&&、||
- 管道命令(pipe)
- 选取命令:cut、grep
- 排序命令:sort、wc、uniq
- 双向重定向:tee
- 字符转换命令:tr、col、join、paste、expand
- 划分命令:split
- 参数代码:xargs
- 关于减号【-】的用途
认识BASH这个Shell
管理整个计算机硬件的其实是操作系统的内核(kernel),这个内核是需要保护的。所以我们一般只能通过Shell来跟内核沟通,以让内核完成我们所想要实现的任务。
shell是什么
Shell(即壳)是计算机操作系统中的一个概念,它是用户与操作系统内核之间的接口。用户通过Shell与操作系统进行交互,向系统发送命令并接收系统的输出。Shell解释用户输入的命令,并将其转换为操作系统能理解的形式,然后将执行结果反馈给用户。
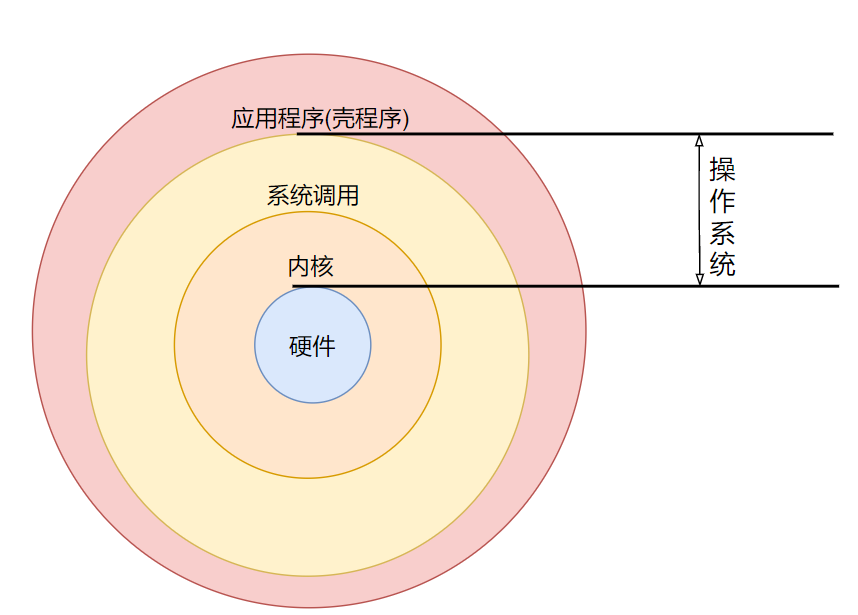
操作系统其实就是一组软件,由于这组软件在控制整个硬件与管理系统的活动检测,如果这组软件能被用户随意使用,若用户应用不当,将会使得整个系统崩溃
但是用户总是需要让用户使用操作系统的,所以就有了在操作系统上面发展的应用程序。用户可以通过应用程序来指挥内核,让内核完成我们所需要的硬件任务。
系统的合法shell与/etc/shells功能
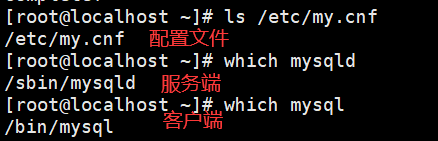
系统上有哪些shell可以用,可以查看/etc/shells这个文件
/etc/shells 文件是一个系统文件,用于存储系统中所有合法的登录shell的路径列表。这个文件的存在可以帮助系统确定哪些shell是可以作为用户的默认登录shell的选择范围。
/etc/shells 文件的功能:
- 限制用户选择范围:当用户想要更改其默认登录shell时,系统会检查用户选择的shell路径是否出现在
/etc/shells文件中。如果用户选择的shell路径未在文件中列出,系统可能会拒绝用户更改为非法shell的请求
[root@chenshiren ~]# cat /etc/shells
/bin/sh (已经被/bin/bash所替换)
/bin/bash (就是Linux默认的shell)
/usr/bin/sh (等于/bin/sh)
/usr/bin/bash (等于/bin/bash)
[root@chenshiren ~]# cat /etc/passwd
....
....
zhw:x:1000:1000:zhw:/home/zhw:/bin/bash # 最后面跟着的就是用户登录所使用的shell
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
csq:x:1001:1001::/home/csq:/bin/bash
project:x:1002:1002::/home/project:/bin/bash
Bash Shell的功能
Bash(Bourne Again Shell)是Linux默认的shell,具有许多强大的功能,如:
命令与文件补全(TAB)
在bash环境中使用【TAB】是一个很好的习惯,可以让你少打很多字,还可以保证你输入的都是正确的。
- 【TAB】接在一串命令的第一个字后面,则为命令补全
- 【TAB】接在一串命令的第二个字后面,则为文件补全
所以我想知道【c】开头的命令呢?就按下【c [TAB] [TAB]】就行了。
命令别名设置(alias)
假如我需要知道这个目录下面所有文件(包含隐藏文件)及所有的文件属性,那么我就必须要执行【ls -al】 这样的命令,很麻烦,我们就可以使用命令别名的方式。例如想让输入 ls 替换为输入 ls -al,那么该如何做呢?
[root@localhost ~]# alias ls='ls -al'
[root@localhost ~]# ls
总用量 48
dr-xr-x---. 3 root root 179 4月 21 16:48 .
dr-xr-xr-x. 17 root root 224 4月 5 20:11 ..
-rw-------. 1 root root 4765 4月 21 10:07 .bash_history
-rw-r--r--. 1 root root 18 4月 20 08:44 .bash_logout
-rw-r--r--. 1 root root 193 4月 20 08:44 .bash_profile
-rw-r--r--. 1 root root 231 4月 20 08:44 .bashrc
drwxr-----. 3 root root 19 4月 20 10:39 .pki
-rw-r--r--. 1 root root 16 4月 21 09:53 utf8zw
-rw-------. 1 root root 4881 4月 21 16:48 .viminfo
-rw-r--r--. 1 root root 83 4月 20 20:16 .vimrc
-rw-r--r--. 1 root root 16 4月 21 09:36 zw
-rw-r--r--. 1 root root 11 4月 21 09:41 zwbig5
-rw-r--r--. 1 root root 11 4月 21 09:43 zwbig555
总所周知root可以删除(rm)任何数据,所以当你使用root的身份在工作时,需要特别小心,但是总有失手的时候,那么rm提供一个选项让我们确认是否删除文件就是-i的选项,所以你可以这样做
[root@localhost ~]# alias rm='rm -i'
这样使用rm的时候,就不用太担心会误删的情况,这也是命令别名的优点.。
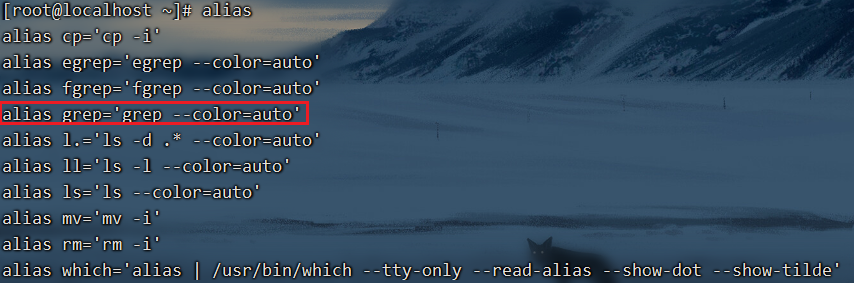
那么如何知道当前我设置了哪些别名呢?如下所示
[root@localhost ~]# alias
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls -al'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
那么怎么取消别名呢?如下所示
[root@localhost ~]# unalias ls
[root@chenshiren ~]# alias
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias xzegrep='xzegrep --color=auto'
alias xzfgrep='xzfgrep --color=auto'
alias xzgrep='xzgrep --color=auto'
alias zegrep='zegrep --color=auto'
alias zfgrep='zfgrep --color=auto'
alias zgrep='zgrep --color=auto'
历史命令(history)
【history】命令它能够记录使用过的命令,我们只需要在命令行里按下【上下键】就可以找到前一个输入的命令。
这么命令在哪里呢?在你的家目录内的【.bash_history】不过,需要留意的是,~/.bash_history记录的是前一次登录以前所执行的命令,而至于这一次登录所执行的命令都被存在内存中,当你成功的注销系统后,该命令才会记录到./bash_history中。
如果我觉得每次输入history字符太多太麻烦,可以使用命令别名来设置
[root@localhost ~]# alias h='history'
这样输入h等于输入了history,那么history 有什么用法呢?
history [n]
history [-c]
history [-raw] histfiles
选项:n:数字,意思是【列出最近的n条命令】的意思
-c:将目前的shell中的所有history内容全部删除
-a:将目前新增的history命令新增histfiles中,若没有加histfiles,则默认写入~/.bash_history。
-r:将history的内容读到目前这个shell的history记录中
-w:将目前history记录的内容写入histfiles中。
# 示例1 列出最近的3条数据
[root@localhost ~]# history 38 echo $bash9 echo $PATH10 history 3
# 示例2 立刻将目前的数据写入histfiles.txt中
[root@localhost ~]# history -w histfiles.txt
那么这个history命令只能让我查询命令而已吗?当然不止,我们还可以利用相关的功能帮我们执行命令
!number
!command
!!# number:执行第几条命令的意思
# command:有最近的命令向前查找【命令串开头为command】的那个命令,并执行
# !!:就是执行上一条命令# 示例1 执行第九条命令
[root@localhost ~]# !9 # 执行第9条命令
echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/.local/bin:/root/bin
任务管理、前台、后台控制(jobs,fg,bg)
任务管理是Shell提供的一个重要功能,通过任务管理可以控制作业的运行方式,前台控制和后台控制是任务管理中的两种常用方式。
jobs命令用于显示当前Shell中正在运行的作业列表,以及作业的状态。通常,作业是指由Shell启动的一个或多个进程组成的任务。jobs命令会列出作业的编号、状态以及相关信息,方便用户查看和管理作业。fg命令用于将一个作业调至前台运行。当用户在Shell中有多个作业时,可以通过fg %作业编号命令将指定作业调至前台运行。作业编号可以通过jobs命令查看。bg命令用于将一个作业切换至后台运行,即让作业在后台继续运行,不阻塞当前Shell的输入。用户可以使用bg %作业编号命令将指定作业切换至后台。
通配符
除了完整的字符串之外,bash还支持许多的通配符来帮助用户查询与命令执行。举例来说我想要知道/usr/bin 下面有多少以X开头的文件,可以使用【ls -l /usr/bin/*X】,此外还有其他可利用的通配符,这些都能够加快用户操作的速度。
程序化脚本
什么是程序化脚本,就是将你平时管理需要执行的连续命令写成一个文件,该文件并且可以通过交互式的方式来进行主机的检测工作,也可以借由shell提供的环境变量及相关的命令来进行设计。
查询命令是否为Bash shell 的内置命令(type)
那我怎么知道这这个命令到底是来自外部命令(指的是非bash所提供的命令)或是内置在bash中呢?可以用type这个命令来观察
type [-tpa] name
选项::不加任何参数时,type显示出name是外部命令还是bash内置命令。
-t:当加入 -t参数时,type将name以下面这些资源显示出它的意义。file :表示外部命令alias:表示该命令为命令别名所设置的名称builtin:表示该命令为bash的内置命令功能
-p:如果后面接的name为外部命令时,才会显示完整的文件名
-a:会由PATH变量定义的路径中,将所有含name的命令都列出来,包括alias# 示例1 查询下rm这个命令是否为bash内置?
[root@localhost ~]# type rm
rm 是 `rm -i' 的别名 # 什么参数都没加,列出rm的最主要使用情况
[root@localhost ~]# type -t rm
alias
[root@localhost ~]# type -a rm
rm 是 `rm -i' 的别名 # 最先展示的是rm的最主要使用情况
rm 是 /usr/bin/rm # 外部命令在所在的路径
# 那么cd是bash的内置命令吗?
[root@localhost ~]# type cd
cd 是 shell 内嵌 # cd是shell的内置命令
命令的执行与快速编辑按钮
如果命令太长的话,如何用两行来输入?
[root@chenshiren ~]# cp -rf /etc/NetworkManager/system-connections/ens160.nmconnection \
> /home/csq/
上面这个命令是将网卡文件复制到 csq这个普通用户下,不过因为命令太长,就利用【\Enter】来将这个按键转义,让【Enter】不在具有执行的功能,好让命令可以继续下一行输入。需要注意的是[Enter]是紧挨着( \ )的,两者中间没有其他字符,因为( \ )仅转义紧接着的下一个字符而已。
如果成功转义[Enter]后,下一行最前面会出现 > 的符号,可以继续输入命令,也就是说,那个 > 是系统自动出现的,不需要你输入。
另外,当你需要执行的命令特别长,或是你输入了一串错误的信息时,你想要快速的将这串命令整个删除,一般来说,我们都是使用删除键。其实还有组合键可以使用。
| 组合键 | 功能示范 |
|---|---|
| [ctrl] + u/[ctrl] + k | 分别是从光标处向前删除命令串(ctrl + u)及向后删除命令串(ctrl + k) |
| [ctrl] + a/[ctrl] + e | 分别是让光标移动到整个命令串的最前面(ctrl + a) 或最后面(ctlr + e) |
shell的变量功能
变量是bash环境中非常重要的一个东西,我们知道Linux是多人多任务的环境,每个人登录系统都能取得一个bash shell,每个人都能够使用bash执行mail这个命令来接受自己的邮件等。bash如何得知你的邮箱是哪个文件的?这就需要变量的帮助。
什么是变量?
什么是变量呢?简单来说,就是让某一个特定字符串代表不固定的内容。
举例来说就像【y=ax+b】这东西,在等号左边的(y)是变量,在等号右边(ax + b)是变量内容,需要注意的是左边是未知数,右边是已知数。
变量的可变性与方便性
举例来说,我们每个账号的邮箱默认是以MAIL这个变量来进行存取的,当csq这个用户登录的时候,它便会取得MAIL这个变量,而这个变量的内容其实就是/var/spool/mail/csq,如果zhw登录呢?它取得的MAIL这个变量的内容其实就是/var/spool/mail/zhw。而我们使用邮件读取命令mail,来读取自己的邮箱时,这个程序可以直接读取MAIL这个变量的内容,这样就能够自动地分辨处属于自己的邮箱。

由于系统已经帮我们规划好MAIL这个变量,所以用户只要知道mail这个命令如何使用即可,mail会主动使用MAIL这个变量,如上图。
影响bash环境操作的变量
某些特定变量会影响到bash的环境。举例来说,你可以使用【echo ${PATH}】打印一下PATH变量
会出现一堆目录里面放的可执行文件。你能不能在任何目录下执行命令,与PATH这个变量有很大的关系。例如你执行【ls】这个命令时,系统就是通过PATH这个变量里面的内容所记录的路径顺序来查找命令。如果说PATH变量内的路径没找到【ls】这个命令,那么就会在屏幕上显示【command not found】的错误信息,就是未找到命令的意思。
那么系统默认的变量除了PATH还有哪些呢?
-
HOME:用户的主目录,通常是 /home/username。
-
SHELL:默认的Shell程序。
-
USER:当前登录的用户名。
-
PWD:当前所在的工作目录。
-
LANG:系统默认语言。
-
TERM:终端类型。
-
PS1:Shell提示符。
-
PS2:Shell多行输入时的提示符。
-
DISPLAY:X Window的显示器名称。
-
EDITOR:默认的文本编辑器。
-
HISTSIZE:历史记录的大小。
-
HOSTNAME:当前主机的名称。
-
MAIL:邮件的存储路径。
-
SHLVL:表示Shell的嵌套深度,每次启动Shell时增加1。
脚本程序设计(shell script)的好帮手
这些还都只是系统默认的变量的目的,如果是个人的设置方面的应用:例如你要写一个大型脚本时,有些数据因为可能由于用户习惯的不同而有差异,比如说路径,由于该路径在脚本被使用在相当多的地方,如果下次换一台主机,都要修改脚本里面所有路径,那么一定很麻烦。这个时候如果使用变量,而将该变量的定义写在最前面,后面相关的路径名称都以变量来替换,那么你只要修改一行就等于修改了整篇脚本,非常方便。

简单来说变量就是一组文件或符号等,来替换一些设置或一串保留的数据,例如:我设置了【myname】就是【csq】,所以当你读取了【myname】这个变量时,系统自然就会知道,那就是【csq】,那么如何显示变量呢?这就需要用到【echo】这个命令
变量的使用与设置:echo、变量设置规则、unset
你可以利用echo这个命令来使用变量,但是,变量在被使用时,前面必须要加上【$】符号才行,假如你想要知道PATH内容
变量的使用(echo)
[root@localhost ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/.local/bin:/root/bin
利用echo就能够读出,只需要在变量名称前面加上 ,或是以【 ,或是以【 ,或是以【{变量名}】的方式使用都可以
如何设置或是修改某个变量的内容,用等号(=)连接变量与它的内容,举例来说:我要将myname这个变量名称的内容设置为CSQ该如何设置呢?:
[root@localhost ~]# echo ${myname}<== 这里没有显示任何数据,因为这个变量尚未被设置,是空的。
[root@localhost ~]# myname=CSQ
[root@localhost ~]# echo ${myname}
CSQ <== 出现了,因为这个变量已经被设置了
在bash当中,当一个变量名称尚未被设置时,默认的内容是【空】,另外,变量在设置时,还是需要符合某些规定的,否则会设置失败。
变量设置的规定
- 变量与变量内容以一个等号【=】来连接
例如:myname=CSQ
- 等号两边不能直接接空格
例如:myname = CSQ
- 变量名称只能是英文字母与数字,但是开头字符不能是数字
例如:2myname=CSQ
- 变量内容若有空格可以使用双引号【"】或单引号【'】将变量内容结合起来,
但双引号内的特殊字符如【$】等可以保有原本的特性
例如:yuyan=“lang is $LANG” 则echo ${yuyan}可得lang is zh_CN.UTF-8
单引号内的特殊字符则仅为一般字符(纯文本)
例如:yuyan=‘lang is $LANG’ 则 echo ${yuyan}可得lang is $LANG
-
可用转义符【\】将特殊符号如([Enter]、$、\、空格、’ 等)变成一般字符
如:myname=zhw\ Tsai 就可以打印出空格 -
在一串命令的执行中,还需要借由其他额外的命令所提供的信息时,可以使用反单引号【`命令`】或【$(命令)】。特别注意,那个 ` 是键盘上方数字键 1 左边的那个按键,而不是单引号。
例如你想取得内核版本的信息:version=$(uname -r) 再输入 echo ${version} 可得内核版本
- 若该变量为扩增变量内容时,则可用"$变量名称"或${变量}累加内容
例如:PATH=“$PATH”:/home/bin 或 PATH=${PATH}:/home/bin
- 若该变量需要在其他子程序执行,则需要以export来使变量变成环境变量
例如:export PATH
-
通常大写字符为系统默认变量,自行设置变量可以使用小写字符,方便判断
-
取消变量的的方法使用unset:【unset 变量名称】
例如:取消myname的设置 unset myname
上数内容中我们谈到子进程,那什么是子进程呢?就是说,在目前这个shell的情况下,去启用另一个新的shell,新的那个shell就是子进程。在一般的状态下,父进程的自定义变量是无法在子进程内使用的,但是通过export将变量变成环境变量后,就能够在子进程下面使用。
# 示例1 设置变量name,且内容为csq
[root@localhost kernel]# 12name=csq
-bash: 12name=csq: 未找到命令 # 不能以数字开头
[root@localhost kernel]# name = csq
-bash: name: 未找到命令 # 还是错的,等号两边不能有空格
[root@localhost kernel]# name=csq
[root@localhost kernel]# echo ${name}
csq # 这样才是成功的# 示例2 若name的变量内容为CSQ's name 就是变量内容含有特殊符号时
[root@localhost kernel]# name=CSQ's name
# 单引号与双引号必须要成对 ,在上面的设置中只要一个单引号,因此你按下回车后
# 你还可以继续输入变量内容,但是设置失败了按ctrl + c 结束进程
[root@localhost kernel]# name="CSQ's name"
# 在引号里面的单引号成为了一般字符,为什么不用单引号呢,因为单引号与内容中的单引号凑成了一对就不是原本的内容了
[root@localhost kernel]# echo $name
CSQ's name
[root@localhost kernel]# name=CSQ\'s\ name # 利用转义字符把单引号和空格转义也是可以的
[root@localhost kernel]# echo $name
CSQ's name# 示例3 我要在PATH这个变量中【累加】:/home/csq这个目录
[root@localhost kernel]# PATH=${PATH}:/home/csq # 有很多种方法这里只举例一种# 示例4 如果我要将name变量里面加一个yes呢?
[root@localhost kernel]# name=${name}yes
[root@localhost kernel]# echo $name
CSQ's nameyes# 示例5 如何让我刚刚设置的name=csq可以用在下一个shell程序?
[root@localhost kernel]# name=csq # 设置变量
[root@localhost kernel]# bash # 进入子进程
[root@localhost kernel]# echo $name # 进入后echo一下# 你会发现变量没有被设置
[root@localhost kernel]# exit # 退出子进程
[root@localhost kernel]# export name # 设置环境变量
[root@localhost kernel]# bash # 进入子进程
[root@localhost kernel]# echo $name # echo一下
csq # 出现设置值了
[root@localhost kernel]# exit # 退出子进程 # 示例6 如何进入到内核模块目录?
[root@localhost kernel]# cd /lib/modules/$(uname -r)/kernel
[root@localhost kernel]# cd /lib/modules/`uname -r`/kernel
# 两种方法都是可行的,一般采用第一种# 示例7 取消我们刚刚设置的name的变量
[root@localhost kernel]# unset name
环境变量的功能
目前我的shell环境种,有多少默认的环境变量,可以利用两个命令查看,【env】与【export】
用env观察环境变量与常见环境变量说明
列出目前shell环境下的所有环境变量
[root@localhost ~]# env
SHELL=/bin/bash # 使用的shell
HISTCONTROL=ignoredups
HISTSIZE=1000 # 记录命令的条数
HOSTNAME=chenshiren # 主机名称
PWD=/root
LOGNAME=root
XDG_SESSION_TYPE=tty
MOTD_SHOWN=pam
HOME=/root # 使用者家目录
LANG=zh_CN.UTF-8 # 语系
LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=01;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:e.... # 一些颜色显示
SSH_CONNECTION=192.168.200.1 51385 192.168.200.20 22
XDG_SESSION_CLASS=user
SELINUX_ROLE_REQUESTED=
TERM=linux # 终端使用的环境
LESSOPEN=||/usr/bin/lesspipe.sh %s
USER=root # 使用者的名称
SELINUX_USE_CURRENT_RANGE=
SHLVL=1
XDG_SESSION_ID=2
XDG_RUNTIME_DIR=/run/user/0
SSH_CLIENT=192.168.200.1 51385 22
which_declare=declare -f
XDG_DATA_DIRS=/root/.local/share/flatpak/exports/share:/var/lib/flatpak/exports/share:/usr/local/share:/usr/share
PATH=/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
SELINUX_LEVEL_REQUESTED=
DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/0/bus
MAIL=/var/spool/mail/root # 使用者邮箱所在
SSH_TTY=/dev/pts/0
OLDPWD=/root # 上一个工作目录的所在
BASH_FUNC_which%%=() { ( alias;eval ${which_declare} ) | /usr/bin/which --tty-only --read-alias --read-functions --show-tilde --show-dot $@
}
_=/usr/bin/env # 上一次使用命令的最后一个参数
那么上面的变量有什么功能呢?我们来介绍一下(这个内容在影响bash环境操作的变量种谈到过)
- HOME
代表用户的根目录
- SHELL
告诉我们,目前这个环境是的SHELL是哪个程序
- HISTSIZE
这个与历史命令有关,就是我们曾经执行过的命令会被系统记录下来,在之前的博客history中讲过
当我们使用mail这个命令在收信时,系统会去读取的邮箱文件(mailbox)
- PATH
就是执行文件查找的路径,目录与目录中间以冒号【:】分割,由于文件的查找是依序由PATH的变量内的目录查询的,所以目录的顺序也很重要
- LANG
LANG变量是一个环境变量,用于指定当前系统所使用的默认语言和字符集。
在Linux和Unix系统中,LANG变量通常是在/etc/profile这个文件中定义的,它的值通常是一个类似于“en_US.UTF-8”的字符串,其中“en_US”表示语言,而“UTF-8”表示字符集
- RANDOM
RANDOM是一个内置的环境变量,用于在Shell脚本中生成随机数。它生成的随机数是一个0到32767之间的整数。在每次调用时,它都会生成一个新的随机数。
使用RANDOM变量非常简单。只需要在脚本中使用$RANDOM即可。以下是一个生成随机数的例子:
[root@localhost 16:22:16 ~]# declare -i number=$RANDOM*10/32768+1 ;echo ${number}
在上面的例子中,declare -i number=$RANDOM*10/32768+1 会生成一个介于1到10之间的随机整数。可以使用这个随机数来进行各种操作,比如生成密码、随机选择列表中的选项等。
需要注意的是,RANDOM变量只能生成整数,如果需要生成小数,则需要进行一些额外的处理。
用set观察所有变量(含环境变量与自定义变量)
bash可不止有环境变量,还有一些与bash操作界面有关的变量,以及用户自己定义的变量存在。那么这些变量如何观察?这时候可以用set命令。set除了环境变量除外,还会将其他在bash内的变量通通显示出来,下面列举一部分内容。
[root@localhost ~]# set
BASH=/bin/bash # bash的主程序路径
BASH_VERSINFO=([0]="4" [1]="2" [2]="46" [3]="2" [4]="release" [5]="x86_64-redhat-linux-gnu")
BASH_VERSION='4.2.46(2)-release' # 这两行是bash的版本
COLUMNS=109 # 在目前的终端环境下,使用的栏位有几个字符长度
HISTFILE=/root/.bash_history # 历史命令记录的放置文件,隐藏文件
HISTFILESIZE=1000 # 历史命令文件最大记录数1000(存在上面这个变量文件里)
HISTSIZE=1000 # 内存中记录历史命令条数最大1000条
IFS=$' \t\n' # 默认的分隔符号
LINES=24 # 目前终端下的最大行数
MACHTYPE=x86_64-redhat-linux-gnu # 安装的机器类型
OSTYPE=linux-gnu # 操作系统类型
PS1='[\u@\h \W]\$ ' # 命令提示符
PS2='> ' # 如果你使用转义字符(\),这是第二行以后的提示字符
$ # 目前中shell所使用的PID
? # 刚刚执行完命令的返回值
.......
....
...
PS1(提示字符的设置)
PS1就是我们的命令提示符。当我们每次按下[Enter]按键去执行某个命令后,最后要再次出现提示字符时,就会主动去读取整个变量值。上面PS1内显示的是一些特殊符号,这些特殊符号可以显示不同的信息。下面我们来介绍一下
-
\d:显示出【星期 月 日】 的日期格式,如【Mon Feb 2】
-
\H:完整的主机名。举例来说【localhost.localdomain】
-
\h:仅取主机名在第一个小数点前的名字,如【localhost】
-
\t:显示时间,为24小时格式的【HH:MM:SS】
-
\T:显示时间,为12小时格式的【HH:MM:SS】
-
\A:显示时间,为24小时格式的【HH:MM】
-
@:显示数据,为12小时格式的【am/pm】
-
\u:目前用户的账户名称,如【csq】
-
\v:BASH的版本信息
-
\w:完整的工作目录名称,由根目录写起的目录名称,单根目录会以~替换
-
\W:利用basename函数取得工作目录名称,所以仅会列出最后一个目录名
-
\# :执行的第几个命令
-
\KaTeX parse error: Expected 'EOF', got '#' at position 21: …,如果是root时,提示字符为#̲,否则就是
让我们来看看Centos默认的PS1内容吧【[\u@\h \W]\$】现在你知道那些反斜杠后的参数的意义了吧?要注意,那个反斜杠后的参数为PS1的特殊功能,与bash的变量设置没关系,不要搞混了,那你现在知道了为何你的命令提示字符是【[root@localhost ~]# 】了吧?
那么假设我想要给命令提示字符添加一个显示时间为24小时格式的【HH:MM:SS】该怎么添加呢?
[root@localhost ~]# PS1='[\u@\h \W \t]\$'
[root@localhost ~ 13:49:49]#
# 看到了吗,提示字符变了
$(关于本shell的PID)
美元符本身也是一个变量。整个东西代表的是目前这个shell的进程号,就是所谓的PID。想要知道我们的shell的PID,就可以用【echo $$】,就会出现我们shell的PID
[root@localhost ~ 13:53:42]#
9937
?(关于上一个执行命令的返回值)
问好也是一个特殊的变量,在bash里面这个变量很重要。这个变量是上一个执行的命令所返回的值。当我们执行某个命令的时候,这些命令都会返回一个执行后的代码。一般来说执行成功会返回一个0值,如果执行过程中失败,就会返回错误的代码,一般就是非0的数值来替换
[root@localhost ~ 14:03:47]# echo $SHELL
/bin/bash # 可以顺利执行没有错误
[root@localhost ~ 14:04:02]# echo $?
0 # 没有错误所以返回0
[root@localhost ~ 14:04:06]# 1name=csq
bash: 1name=csq: 未找到命令 # 发生错误了
[root@localhost ~ 14:04:21]# echo $?
127 # 因为发生了错误,返回错误(非0)
OSTYPE,HOSTTYPE,MACHTYPE(主机硬件与内核的等级)
-
OSTYPE(操作系统类型)
OSTYPE是一个环境变量,它指示当前操作系统的类型。这个变量在不同的操作系统中有不同的名称,例如,在Linux中,它被称为$OSTYPE,在MacOS中,它被称为$SYSTEM_TYPE。OSTYPE的值通常是一个字符串,表示操作系统的名称和版本号,例如,linux-gnu、darwin、win32等。 -
HOSTTYPE(主机类型)
HOSTTYPE也是一个环境变量,它指示当前主机的类型。这个变量在不同的操作系统中有不同的名称,例如,在Linux中,它被称为$HOSTTYPE,在MacOS中,它被称为$MACHTYPE。HOSTTYPE的值通常是一个字符串,表示主机的类型和处理器架构,例如,x86_64、i686、armv7等。 -
MACHTYPE(机器类型)
MACHTYPE是一个环境变量,它指示当前机器的类型。这个变量通常是由HOSTTYPE和其他信息组成的,以提供更详细的硬件和内核等级信息。MACHTYPE的值通常是一个字符串,表示主机的类型、处理器架构、操作系统类型和内核类型等信息,例如,x86_64-pc-linux-gnu、armv7l-unknown-linux-gnueabihf等。
export(自定义变量转成环境变量)
env和set两者之间有啥差异?其实这俩者差异在于【该变量是否会被子进程所继续引用】。什么是子进程?什么是父进程呢?
当你登录Linux并取得一个bash后,你的bash就是一个独立的进程,这个进程的识别使用的是进程标识符,也就是PID。接下来你在这个bash下面所执行的任何命令都是由这个bash衍生出来的,那些被执行的命令就被称为子进程。如下图
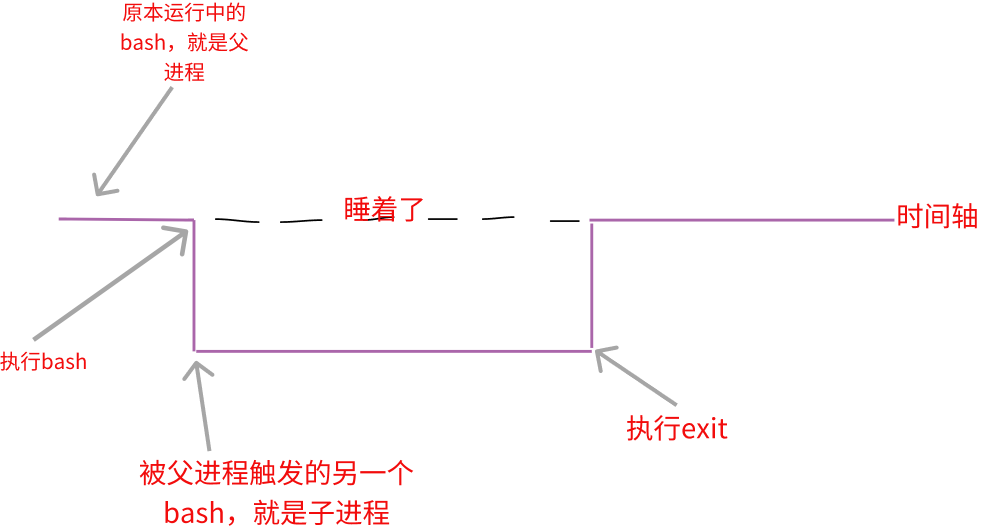
如上图所示,我们在原本的bash下面执行另一个bash,结果操作的环境界面就会跑到第二个bash去(就是子进程),那原本的bash就会暂停情况(睡着了sleep),整个目录运行的环境是实践的部分。若要回到原本的bash中去,就只有将第二个bash结束掉(执行 exit 或 logout)才行。
这个进程概念与变量由啥关系?子进程会继承父进程的环境变量,子进程不会继承父进程的自定义变量。所以你在原本bash的自定义变量进入子进程后就会消失不见,一直到你离开子进程并回到原本的父进程后,这个变量才会出现。
那我们就可以使用export命令,可以让变量内容继续在子进程中使用
export 变量名称
用于共享自己的变量设置给后来调用的文件或其他进程
如果仅执行export而没有接变量时,那么此时就会把所以的环境变量显示出来
[root@localhost ~ 14:10:33]# export
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/root"
declare -x HOSTNAME="localhost.localdomain"
...........
......
..
影响显示结果的语系变量(locale)
Linux到底支持多少语系呢?可以由locale来查询
[root@localhost ~ 14:45:43]# locale -a
......
zh_CN.utf8 # 简体中文编码
....
那么我们如何自定义这些编码呢?其实可以通过下面这些变量
[root@localhost ~ 14:46:03]# locale
LANG=zh_CN.UTF-8 # 主语言的环境
LC_CTYPE="zh_CN.UTF-8" # 字符(文字)辨识编码
LC_NUMERIC="zh_CN.UTF-8" # 数字系统的显示信息
LC_TIME="zh_CN.UTF-8" # 时间系统的显示数据
LC_COLLATE="zh_CN.UTF-8" # 字符的比较与排序
LC_MONETARY="zh_CN.UTF-8" # 币值格式的显示等
LC_MESSAGES="zh_CN.UTF-8" # 信息显示的内容,如功能表,错误信息等。
....
...
....
LC_ALL= # 整体语系的环境
- 如果设置了
LANG或LC_ALL变量,它们会影响整个系统的语言环境。 - 如果其他与语言环境相关的变量(比如
LC_CTYPE、LC_COLLATE等)没有被设置,那么LANG或LC_ALL变量会代替它们的作用。 - 因此,一般而言,在设置语言环境时,只需要设置
LANG或LC_ALL这两个变量即可,因为它们是最主要、最全局的语言环境设置变量。
当然每个用户可以去调整自己喜欢的语系,系统默认的语系定义在哪里呢?其实就在/etc/locale.conf里面
[root@localhost 15:08:52 ~]# vim /etc/locale.confLANG="zh_CN.UTF-8"
系统原本是中文语系,所有显示的数据通通是中文。但为了网页显示的关系,需要将输出转成英文语系才行,但是又不想写入配置文件,毕竟暂时显示使用,应该怎么做
[root@localhost 15:13:00 ~]# LANG=en_US.UTF-8
[root@localhost 15:13:45 ~]# export LC_ALL=en_US.UTF-8
[root@localhost 15:14:00 ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=en_US.UTF-8
变量的有效范围
- 环境变量
- 作用范围:环境变量是在操作系统环境中全局可见的变量,可以被所有的子进程继承和访问。它们对整个系统环境都具有影响。
- 存储位置:环境变量存储在操作系统分配给shell使用的内存区域中,可以通过
export命令设置为环境变量。 - 示例:
PATH环境变量用于指定系统在哪些目录中查找可执行文件
- 自定义变量
- 作用范围:自定义变量只在定义它的特定范围内有效,通常是在脚本或程序的特定部分。
- 存储位置:自定义变量通常存储在当前shell的内存中,只在当前shell会话中可见,不会被子进程继承
- 设置方法:自定义变量可以通过直接赋值的方式在shell脚本或命令中创建和修改。
- 示例:在shell脚本中定义一个局部变量
count用于计数,该变量只在该脚本中有效。
为什么环境变量的数据可以被子进程所引用呢?这是因为内存配置的关系
- 当启动一个shell,操作系统会分配一内存区域给shell使用,此内存中的变量可以让子进程使用。
- 若在父进程利用export功能,可以让自定义变量的内容写到上述的内存区域当中(环境变量)
- 当你加载另一个shell时(即启动子进程,而离开原本的父进程)子shell可以将父shell的环境变量所在的内存区域导入自己的环境变量区块当中
变量键盘读取、数组与声明:read、array、declare
read
要读取来自键盘输入的变量,就是要使用read这个命令。这个命令最常被用在shell脚本的编写当中,想要跟用户交互?用这个命令就对了
read [-pt] 变量
选项:
-p:后面可以接提示字符
-t:后面可以接等待的【秒数】# 示例1 让使用者由键盘输入一内容,将该内容变成名为atest的变量
[root@localhost 15:46:33 ~]# read atest
This is atest # 光标会等待你输入,输入This is atest
[root@localhost 15:53:59 ~]# echo ${atest}
This is atest # 你刚刚输入的数据已经变成一个变量的内容# 示例2 提示使用者30秒输入自己的名字,将输入字符作为名为named的变量内容
[root@localhost 15:54:09 ~]# read -p "please keyin your name: " -t 30 named
please keyin your name: csq # 这里是提示字符,输入csq
[root@localhost 15:57:05 ~]# echo ${named}
csq # 发现输入的数据又变成了一个变量的内容
declare,typeset
declare或typeset是一样的功能,就是声明变量的类型。如果使用declare后面没有接任何参数,那么bash就会主动的将所有的变量名称与内容通通显示出来,就好像set一样。
declare [-aixr] 变量
选项:
-a: 将后面名为xxxx的变量定义成为数据(array)类型
-i:将后面名为xxxx的变量定义成为整数(integer)类型
-x:用法与export一样,就是将后面的变量变成环境变量
-r:将变量设置成为readonly类型,该变量不可被更改内容,也不能unset
让变量sum进行100+300+50的求和结果
[root@localhost 16:15:28 ~]# sum=100+300+50
[root@localhost 16:15:38 ~]# echo ${sum}
100+300+50 # 为什么没有 帮我们求和,因为这个是文字形式的变量属性
[root@localhost 16:15:41 ~]# declare -i sum=100+50+300
[root@localhost 16:16:11 ~]# echo ${sum}
450
由于默认情况下,bash对于变量有几个基本定义:
- 变量类型默认为字符串,所以若不指定变量类型,则1+2为一个字符串而不是计算式。所以上述第一个执行的结果才会是那种情况
- bash环境中的数值运算,默认最多仅能到达整数形态,所以1/3结果为0
现在你晓得为什么你要进行变量声明了吧?如果需要非字符串类型的变量,那就得要进行变量的声明才行。
让sum变成环境变量
[root@localhost 16:28:45 ~]# export |grep sum
declare -ix sum="450" # 出现了,包括由i与x的定义
让sum变成只读属性,不可修改
[root@localhost 16:28:54 ~]# declare -r sum
[root@localhost 16:30:03 ~]# sum=111
-bash: sum: readonly variable # 不能改这个变量了!
让sum变成非环境变量的自定义变量吧
[root@localhost 16:30:16 ~]# declare +x sum # 将-变成+可以进行【取消】操作
[root@localhost 16:31:38 ~]# declare -p sum # -p可以单独列出变量的类型
declare -ir sum="450" # 只剩下,i,r的类型,不具有x
declare也是个很有用的功能,尤其是当我们需要使用到下面的数组功能时,它也可以帮我们声明数组的属性。数组在shell脚本中也是很常用的。如果你不小心将变量设置为【只读】,通常要注销在登录能恢复该变量的类型。
数组(array)变量类型
那么如何设置数组的变量与内容呢?
var[index]=content
意思说我有一个数组名为var,这个数组的内容为var[1]=小明,var[2]=小弔,var[3]=老明,那个index就是一些数字,重点是用中括号[]来设置。
[root@localhost 16:45:56 ~]# var[1]="small ming"
[root@localhost 17:09:46 ~]# var[2]="bro ming"
[root@localhost 17:10:12 ~]# var[3]="old ming"
[root@localhost 17:10:24 ~]# echo "${var[1]},${var[2]},${var[3]}"
small ming,bro ming,old ming
与文件系统及程序的限制关系:ulimit
想象一个状况,文档Linux主机里面同时登录了10个人,这10个人不知道怎么高的,同时开启了100个文件,每个文件大小约为10MB,请问一下,Linux内存要多大才够他们使用?
[root@localhost ~]# declare -i sum=10*100*10 ; echo $sum
10000
10000MB=10GB,这样,内存完全不够他们用。为了预防这个情况的发生,所以我们的bash是可以限制用户的某些系统资源的,包括可以开启的文件数量,可以使用CPU时间,可以使用内存的总量
ulimit [-SHacdfltu] [配额]
选项:
-H:hard limit 严格的设置,必定不能超过这个设置的数值
-S:soft limit 警告的设置,可以超过这个设置值,超过则有警告信息在设置上面,通常soft 会比hard小
-a:后面不接任何选项与参数,可列出所有的限制与额度。
-c:当某些程序发生错误时,系统可能会将该程序在内存中的信息写成文件(除错用)这种文件就被称为内核文件。为此限制每个内核文件的最大容量
-f:此shell可以建立的最大文件容量(一般可能设置为2GB)单位为Kbytes
-d:程序可使用的最大段内存容量
-l:可用于锁定的内存量
-t:可使用的最大CPU时间(单位为秒)
-u:单一使用者可以使用的最大进程数量# 示例1 列出你目前身份(假设为一般账号)的所有限制数据数值
[csq@localhost ~]$ ulimit -a
core file size (blocks, -c) 0 # 只要是0就代表没限制
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited # 可建立单一文件大小
pending signals (-i) 31116
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024 #同时可开启的文件数量
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited# 限制使用者仅能建立10MBytes以下的容量文件
[csq@localhost ~]$ ulimit -f 10240
[csq@localhost ~]$ ulimit -a |grep 'file size'
core file size (blocks, -c) 0
file size (blocks, -f) 10240
[csq@localhost ~]$ dd if=/dev/zero of=10mb bs=1M count=15
文件大小超出限制
变量内容的删除、取代与替换
变量除了可以直接设置来修改原本的内容之外,有没有办法通过简单的操作来将变量的内容进行微调呢?
变量内容的删除与替换
| 变量设置方式 | 说明 |
|---|---|
| ①${变量#关键词} ②${变量##关键词} | ①若变量内容从头开始的数据符合【关键词】,则将符合的最短数据删除 ②若变量内容从头开始的数据符合【关键词】,则将符合最长数据删除 |
| ①${变量%关键词} ②${变量%%关键词} | ①若变量内容从尾向前的数据符合【关键词】,则将符合的最短数据删除 ②若变量内容从尾向前的数据符合【关键词】,则将符合的最长数据删除 |
| ①${变量/旧字符串/新字符串} ②${变量//旧字符串/新字符串} | ①若变量内容符合【旧字符串】则【第一个旧字符串会被新字符串替换】 ②若变量内容符合【旧字符串】则【全部的旧字符串会被新字符串替换】 |
先让小写的path自定义变量设置的与PATH内容相同
[csq@localhost ~]# path="$PATH"
[root@localhost ~]# echo ${path}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/.local/bin:/root/bin
假设我不喜欢local/bin 这个目录,所以要将一个目录删掉,如何显示?
[root@localhost ~]# echo ${path#/*local/bin:}
/usr/sbin:/usr/bin:/root/.local/bin:/root/bin
删除前面所有的目录,仅保留最后一个目录
[root@localhost ~]# echo ${path##/*:}
/root/bin
因为在PATH这个变量内容中,每个目录都是以冒号【:】隔开的,所以要从头删掉目录就是介于斜线(/)到冒号(:)之间的数据。但是PATH中不止一个冒号(😃
上面谈到的是从前面开始删除变量内容,那么如果想要从后面向前删除变量内容?这个时候就得使用百分比(%)符号了
我想要删除最后面那个目录,就是从:到bin为止的字符
[root@localhost ~]# echo ${path%:*bin}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/.local/bin
# 注意最后面一个目录不见了
# 这个%符号代表由最后面开始向前删除
那如果我只想要保留第一个目录?
[root@localhost ~]# echo ${path%%:*bin}
/usr/local/sbin
假设你是csq,那你的MAIL变量应该是/var/spool/mail/csq,假设你只想保留最后面那个文件名,前面的目录名称都不要了,如何利用$MAIL变量来完成?(最长符合)
[root@localhost ~]# echo ${MAIL##/*/}
root
相反如果你只想拿掉文件名,保留目录名称,即【/var/spool/mail/】最短符合。
[root@localhost ~]# echo ${MAIL%/*}
/var/spool/mail
将path的变量内容内的sbin替换成大写的SBIN
[root@localhost ~]# echo ${path/sbin/SBIN}
/usr/local/SBIN:/usr/local/bin:/usr/sbin:/usr/bin:/root/.local/bin:/root/bin
# 这个部分就容易理解了。关键字在于那两个斜线,量斜线的中间的是旧字符
# 后面的是新字符,所以结果就会出现如上述的特殊字体不放
[root@localhost ~]# echo ${path//sbin/SBIN}
/usr/local/SBIN:/usr/local/bin:/usr/SBIN:/usr/bin:/root/.local/bin:/root/bin
# 如果是两条斜线,那么就变成所有符合的内容都会被替换。
变量的测试与内容替换
测试以下是否存在username这个变量,若不存在则给予username内容为root
[root@localhost ~]# echo ${username}# 出现空白,所以username不存在,也可能是空字符
[root@localhost ~]# username=${username-root}
[root@localhost ~]# echo ${username}
root # 因为username没有设置,所以主动给予名为root的内容
[root@localhost ~]# username="This is csqcsqcsq" # 主动设置username的内容
[root@localhost ~]# echo ${username}
This is csqcsqcsq # 因为username已经设置了
不过这还是有点问题。因为username可能已经被设置为【空字符串】了。果真如此的话,那你还可以使用下面的案例来给予username的内容为root
若username未设置或未空字符,则将username内容设置为root
[root@localhost ~]# username=""
[root@localhost ~]# username=${username-root}
[root@localhost ~]# echo ${username}# 因为username被设置为空字符了,所以当然还是保留为空字符。
[root@localhost ~]# username=${username:-root}
[root@localhost ~]# echo ${username}
root # 加上【:】后若变量内容为空或是未设置,都能够以被后面的内容替换
大括号内有没有冒号【:】的差别还是很大的。加上冒号,被测试的变量未被设置或是已被设置未空字符串时,都能够用后面的内容来替换与设置。
下面例子中,那个var与str为变量,我们想要针对str是否有设置来决定var的值,一般来说,str:代表【str没设置或为空的字符串时】,至于str则仅为【没有该变量】
| 变量设置方式 | str没有设置 | str为空字符串 | str已设置非为空字符串 |
|---|---|---|---|
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr var=expr | str不变 var= | str不变 var=$str |
| var=${str:=expr} | str=expr var=expr | str=expr var=expr | str不变 var=$str |
| var=${str?expr} | expr输出至stderr | var= | var=$str |
| var=${str:?expr} | expr输出至stderr | expr输出至stderr | var=$str |
根据上面这张表,我们来进行几个案例练习,首先来测试以下,如果旧变量(str)不存在时,我们要给予新变量一个内容,若旧变量存在则新变量内容以旧变量来替换,结果如下:
测试:假设str不存在(用unset)然后测试以下减号(-)的用法
[root@localhost ~]# unset str;var=${str-newvar}
[root@localhost ~]# echo "var=${var},str=${str}"
var=newvar,str= # 因为str不存在,所以var为newvar
测试若str已存在,测试一下var会变怎样?
[root@localhost ~]# str="oldvar";var=${str-newvar}
[root@localhost ~]# echo "var=${var},str=${str}"
var=oldvar,str=oldvar # 因为str存在,所以var等于str的内容
如果你想要将旧变量内容也一起替换掉的话,那么就使用等号(=)
[root@localhost ~]# unset str;var=${str=newvar}
[root@localhost ~]# echo "var=${var},str=${str}"
var=newvar,str=newvar # 因为str不存在,所以var str 均为newvar
测试如果str已经存在了,测试一下var会变怎样?
[root@localhost ~]# str="oldvar";var=${str=newvar}
[root@localhost ~]# echo "var=${var},str=${str}"
var=oldvar,str=oldvar # 因为str存在,所以var等于str的内容
那如果我只是向指定,如果旧变量不存在时,整个测试就告知我【有错误】,此时就能够使用问号【?】的帮忙
测试:若str不存在时,则var的测试结果直接显示“无此变量”
[root@localhost ~]# unset str;var=${str?}
-bash: str: 参数为空或未设置
测试:若str存在时,则var的内容会与str相同
[root@localhost ~]# str="oldvar";var=${str?novar}
[root@localhost ~]# echo "var=${var},str=${str}"
var=oldvar,str=oldvar # 因为str存在,所以var等于str的内容
Bsah shell的操作环境
登录Linux的时候,屏幕上面会出现一些说明文字,告知我们的Linux版本什么的,还有,登录的时候我们还可以给予用户写信息或欢迎文字
路径与命令查找顺序
现在我们知道系统里面其实有不少的ls命令,或是包括内置的echo命令,那么来想一想,如果一个命令(例如ls)被执行时,到底是哪一个ls被拿来运行呢?基本上,命令运行的顺序可以这样看
-
以相对/绝对路径执行命令,例如【/bin/ls】或【ls】
-
有alias找到该命令来执行、
-
由bash内置的(builtin)命令来执行
-
通过$PATH这个变量的顺序查找到第一个命令来执行
举例来说,你可以执行【/bin/ls】及单纯的执行【ls】看看,会发现使用ls有颜色但是/bin/ls则没颜色。因为/bin/ls是直接使用该命令来执行,而ls会因为【alias ls=‘ls --color=auto’】这个命令别名而先使用,
如果想了解命令查找的顺序,其实通过【type -a ls】也可以查询的到。
# 示例1 设置echo的命令别名为echo -n,然后再观察echo执行的顺序
[root@localhost 3339 09:34:02~]# alias echo='echo -n'
[root@localhost 8003 09:36:23~]# type -a echo
echo 是 `echo -n' 的别名
echo 是 shell 内嵌
echo 是 /usr/bin/echo
顺序是:先alias 再内嵌再由$PATH找到/bin/echo
bash的登录与欢迎信息:/etc/issue、/etc/motd
bash的登录和欢迎信息就在【/etc/issue】里面
[root@localhost 5358 09:43:23~]# cat /etc/issue
\S
Kernel \r on an \m
| issue内的各代码意义 |
|---|
| \d 本地端时间的日期 |
| \l 显示第几个终端界面 |
| \m 显示硬件的等级 |
| \n 显示主机的网络名称 |
| \O 显示domain name |
| \r 显示操作系统的版本(相当于 uname -r) |
| \t 显示本地端的时间 |
| \S 操作系统的名称 |
| \v 操作系统的版本 |
如果你在tty3的登录画面看到如下显示,该如何设置呢?
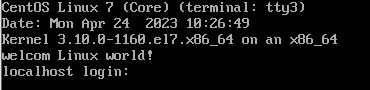
用root的身份,并参考上述反斜杠功能去修改【/etc/issue】成为如下模样即可
\S (terminal: \l)
Date: \d \t
Kernel \r on an \m
welcom Linux world!
除了/etc/isue之外还有个/etc/issue.net,这是啥?这个是提供给telnet这个远程登录程序用的。当我们使用telnet连接主机时,主机的登录画面就会显示/etc/issue.net而不是/etc/issue。
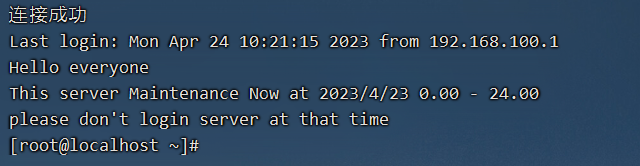
至于纳入你你想要让用户登录后取得一些信息,例如你想要让大家都知道的信息,那么可以将信息加入 /etc/motd里面。例如:在登录后,告诉登录者,系统将会在某个固定时间进行维护工作,可以这样做
Hello everyone
This server Maintenance Now at 2023/4/23 0.00 - 24.00
please don't login server at that time
bash的环境配置文件如下
为什么我什么也没有操作,但是一进bash就取得了一堆可用的变量了呢?这是因为系统有一些环境配置文件的存在,让bash在启动时直接读取这些配置文件
login shell与non-login shell
Shell会根据启动方式的不同分为两种模式:login shell(登录Shell)和non-login shell(非登录Shell)。这两种模式之间在启动时加载的配置文件和环境变量等方面有所不同。
login shell:取得bash时需要完整的登录流程,就称为login shell。举例来说,你要由tty1 - tty6登录,需要输入用户的账号密码,此时取得的bash就称为【login shell】non-login shell:取得bash的方法不需要重复登录的操作,举例来说,你在原本的bash环境下再次执行bash这个命令,同样的也没有输入账号密码,那第二个bash(子进程)也是non-login shell。
为什么要介绍login,non-login shell?这是因为这两个取得bash的情况中,读取的配置文件并不一样所致。由于我们需要登录系统,一般来说,login shell其实只会读取两个配置文件
login shell(登录Shell)
/etc/profile:这是系统整体的设置,最好不要修改这个文件~/bash_profile或~/.bash_login或~/.profie:属于用户个人设置。你要添加自己的数据,就写入这里
/etc/profile(login shell 才会读)
你可以使用vim去阅读一下这个文件内容。这个配置文件可以利用用户标识符(UID)来决定很多重要的变量数据,这也是每个用户登录取得bash时一定会读取的配置文件。所以如果你想要帮所有用户设置整体环境,那就是这里。
- PATH:会根据UID决定PATH变量要不要含有sbin的系统命令目录
- MAIL:根据账号设置好用户的【mailbox】到【/var/spoll/mail/账户名】
- USER:根据用户的账号设置此变量内容
- HOSTNAME:根据主机的hostname命令决定此变量内容
- HISTSIZE:历史命令记录条数,默认1000
- umask:包括root默认为022而一般用户为002等
/etc/profile可不止会做这些事而已,它还会去调用外部的配置文件
/etc/profile.d/*.sh
其实这是个目录内的众多文件。只要在【/etc/profile.d/ 】这个目录内且扩展名为 .sh,另外,用户能够具有r的权限,那么该文件就会被 【/etc/profile】调用。在这个目录下面的文件规范了bash操作界面的颜色,语系,ll与ls命令的命令别名、vi的命令别名、which的命令别名等。如果需要帮所有用户设置一些共享的命令别名时,可以在这个目录下面自行建立扩展名.sh文件,并将所需要的数据写入即可。
/etc/locale.conf
这个文件由【/etc/profile.d/lang.sh】调用,这也是我们决定bash默认使用何种语系的重要配置文件。文件里最重要的就是LANG/LC_ALL 这些变量的设置
/usr/share/bash-completion/completions/*
包含了用于Bash自动补全功能的脚本文件,除了命令补齐、文件补齐之外,还可以进行命令的选项/参数补齐功能。那就是从这个目录里面找到相应的命令来处理,其实这个目录下面的内容是由【/etc/profile.d/bash_completion.sh】这个文件加载的
~/.bash_profile(login shell 才会读)
bash在读完整体环境设置的【/etc/profile】并借此调用其他配置文件,接下来则是会读取用户的个人配置文件。在login shell 的bash环境中,所读取的个人偏好配置文件其实主要有三个,依序分别是:
- ~/.bash_profile
- ~/.bash_login
- ~/.profile
其实bash的login shell 设置只会读取上面三个文件的其中一个,而读取的顺序则是依照上面的顺序。也就是说,如果~/.bash_profile存在,那么其他两个文件不论存不存在,都不会被读取,如果~/.bash_profile不存在才回去读取~/.bash_login,前两者都不存在才会读取~/.profile。。
让我们看看root的/root/.bash_profile 的内容是怎么样的
[root@localhost ~]# cat ~/.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then # 下面这三行判断并读取~/.bashrc. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin # 这几行处理个人设置
export PATH
这段内容指的是判断家目录下的/.bashrc存在否,若存在则读入/.bashrc的设置。bash文件读入的方式主要是通过一个命令【source】来读取,也就是说/.bash_profile其实会再调用/.bashrc的设置内容。我们来看看login shell的读取流程:
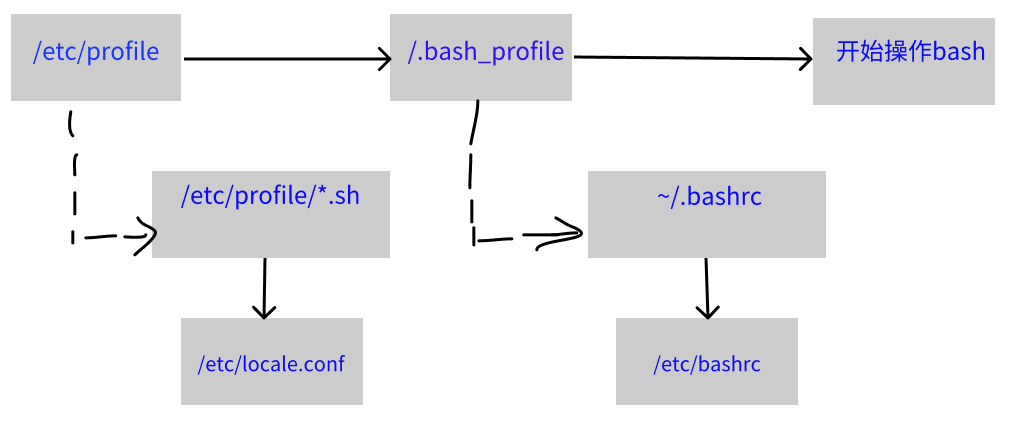
实线的方向是主流线程,虚线的方向则是被调用的配置文件
在login shell 环境下,最终读取的配置文件是【~/.bashrc】这个文件,所以,你当然可以将自己的偏好设置写入该文件即可。
source:读入环境配置文件的命令
source 配置文件文件名
案例如:
将家目录的~/.bashrc的设置读入目前的bash环境中
[root@localhost ~]# source ~/.bashrc # 两个命令是一样的
[root@localhost ~]# . ~/.bashrc
由于/etc/profile与~/.bash_profile 都是在取得login shell的时候才会读取的配置文件,所以,如果你将自己的偏好设置写入上述文件后,通常都是得注销后再登录后,该设置才会生效。那么能不能直接读取配置文件而不注销登录呢?可以的,利用source命令
举例来说,我修改了【~/.bashrc】,那么不需要注销,立即以【source ~/.bashrc 】就可以将刚刚最新设置的内容读入目前的环境中了。
~/.bashrc(non-login shell会读)
non-login shell这种非登录情况取得bash操作界面的环境配置文件又是上面?当你取得non-login shell 时,该bash配置文件仅会读取/.bashrc而已,那么默认的/.bashrc内容如何?
[root@localhost ~]# cat ~/.bashrc
# .bashrc
alias rm='rm -i' # 使用者的个人设置
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then # 整体的环境设置. /etc/bashrc
fi# Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER=# User specific aliases and functions
特别注意一下,由于root的身份与一般用户不同,由上面的数据,如果是一般用户的~/.bashrc会有些许不同,为什么会主动调用/etc/bashrc这个文件呢。因为/etc/bashrc帮我们的bash定义出下面的内容
- 根据不同的UID设置umask值
- 根据不同的UID设置了提示字符(就是 PS1 变量)
- 调用 /etc/profile.d/*.sh 的设置
由于这个~/.bashrc会调用/etc/bashrc及 /etc/profile.d/*.sh,所以,万一你没有~/.bashrc(可能自己不小心将他删除了),那么你就会发现你的bash提示字符可能会变成这个样子
不要担心,这是正常的,因为你并没有调用 /etc/bashrc来规范PS1变量,而且这样的情况也不会影响你的bash使用。如果你想要显示命令提示字符,那么可以复制/etc/skel/.bashrc到你的根目录,再定义一下你所想要的内容,并使用source 去调用~/.bashrc 那你的命令提示符就会回来
-bash-4.2# cp -rf /etc/skel/.bashrc /root/
-bash-4.2# source .bashrc
[root@localhost ~]#
/etc/man_db.conf
这个文件规定了执行man的时候,该去哪里查看数据的路径设置。
~/.bash_history
默认的情况下,我们的历史命令就记录再这里。而这个文件能记录几条数据跟【HISTFILESIZE】这个变量有关。每次登录bash的时候,bash会先读取这个文件,将所有历史命令读入内存,因此,当我们登录bash后就可以查知上次使用过哪些命令。
~/.bash_logout
这个文件则记录了【当我注销bash后,系统在帮我做完什么操作后才离开】的意思。你可以去读取一下这个文件的内容,默认情况下,注销时bash只是帮我们清掉屏幕信息而已。不过你可以将一些备份或是其他你认为重要的任务写在这个文件中(例如清空缓存),那么当你离开Linux的时候,就可以解决一些事情。
终端的环境设置:stty、set
stty
stty是Linux中使用的命令行工具,用于设置终端(terminal)的各种参数。“stty"是"set tty”(设置终端)的缩写。通过使用stty命令,用户可以配置和控制终端的行为,例如控制终端的输入和输出方式、控制光标的移动方式、配置特殊字符的处理方式等。
stty [-a]
选项:
-a:将目前所有的stty参数列出来
使用案例:
[root@localhost ~]# stty
speed 38400 baud; line = 0;
-brkint -imaxbel
[root@localhost ~]# stty -a
speed 38400 baud; rows 24; columns 109; line = 0;
intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>; eol2 = <undef>; swtch = <undef>;
start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R; werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0;
......
.....
...
我们可以利用stty -a来列出目前环境中所有的按键列表,在上面的列表中,需要注意的是特殊字体那几个,此外,如果出现表示【ctrl】那个按键的意思。举例来说,【intr=C】表示利用【ctrl + c】来完成,几个重要关键词的意义是:
- intr:发送一个interrupt(中断)的信号给目前正在run的程序(就是终止)
- quit:发送一个quit的信号给目前正在run的程序
- erase:向后删除字符
- kill:删除在目前命令行上的所有文字
- eof:End of file的意思,代表【结束输入】
- start:在某个程序停止后,重新启动它的output
- stop:停止目前屏幕的输出
- susp:送出一个terminal stop 的信号给正在运行的程序
# 示例1 将ctrl + h 设置为删除字符的按键
[root@localhost ~]# stty erase ^h
[root@localhost ~]# stty erase ^? # 测试完后改回来
当你工作的时候经常在Windows与Linux之间切换,在Windows下面,很多软件默认的储存块键是【ctrl + s】,我不小心在Linux按下了【ctrl + s】,整个VIM就不能动了(界面锁死了),请问该如何处理?
按下【ctrl + q】就可以让整个界面重新恢复正常了
| 组合按键 | 执行结果 |
|---|---|
| Ctrl + C | 终止目前的命令 |
| Ctrl + D | 输入结束(EOF),例如邮件结束的时候 |
| Ctrl + M | 就是回车 |
| Ctrl + S | 暂停屏幕的输出 |
| Ctrl + Q | 恢复屏幕的输出 |
| Ctrl + U | 在提示字符下,将整列命令删除 |
| Ctrl + Z | 暂停目前的命令 |
set
set主要用于设置和显示Shell的环境变量,以及修改Shell的运行时属性。
set [-uvCHhmBx]
选项:
-u:默认不启用,若启用后,当使用未设置变量时,会显示是错误信息
-v:默认不启用,若启用后,在信息被输出前,会先显示信息的原始内容
-x:默认不启用,若启用后,在命令被执行前,会显示命令内容(前面有++符号)
-h:默认启用,与历史命令有关。
-H:默认启用,与历史命令有关。
-m:默认启用,与任务管理有关。
-B:默认启用,与中括号[]的作用有关。
-C:默认不启用,若使用>等,则若文件存在时,该文件不会被覆盖。# 示例1 显示目前所有的set设置值
[root@localhost ~]# echo $-
himBH
# 那个$-变量内容就是set的所有设置,bash默认是himBGH# 示例2 设置“若使用未定义变量时,则显示错误信息”
[root@localhost ~]# set -u
[root@localhost ~]# echo $ldjadjawdl
-bash: ldjadjawdl: 未绑定变量
# 默认情况下,未设置/未声明的变量都会说【空的】,不过,若设置-u参数。
# 若要取消这个参数 set + u 即可# 示例3 执行前,显示该命令内容
[root@localhost ~]# set -x
[root@localhost ~]# echo $PATH
+ echo /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
++ printf '\033]0;%s@%s:%s\007' root localhost '~'
# 看见了?要输出的命令都会先被打印到屏幕上,前面会多出+的符号
通配符与特殊符号
在bash的操作环境中还有一个非常有用的功能,那就是通配符(wildcard)。我们利用bash处理数据就更方便了,下面列出一些常用的通配符。
| 符号 | 意义 |
|---|---|
| * | 代表【0个到无穷多个】 |
| ? | 代表【一定有一个】任意字符 |
| [] | 同样代表【一定有一个在括号内】的字符(非任意字符)。 例如[abcd]代表【一定有一个字符,可能是a、b、c、d这四个任何一个】 |
| [-] | 若有减号在中括号内时,代表【在编码顺序内的所有字符】。 例如[0-9]代表0和9之间的所有数字,因为数字的语系编码都是连续的 |
| [^] | 若中括号内的第一个字符为指数符号(^),那表示【反向选择】, 例如[^abc] 代表一定有一个字符,只要是非a、b、c的其他字符就接受的意思 |
#示例1 找出/etc/ 下面以cron为开头的文件名
[root@localhost ~]# ll -d /etc/cron*
drwxr-xr-x. 2 root root 21 Apr 5 20:08 /etc/cron.d
drwxr-xr-x. 2 root root 42 Apr 5 20:08 /etc/cron.daily
-rw-------. 1 root root 0 Aug 9 2019 /etc/cron.deny
drwxr-xr-x. 2 root root 22 Jun 10 2014 /etc/cron.hourly
drwxr-xr-x. 2 root root 6 Jun 10 2014 /etc/cron.monthly
drwxr-xr-x. 2 root root 6 Jun 10 2014 /etc/cron.weekly
-rw-r--r--. 1 root root 451 Jun 10 2014 /etc/crontab# 示例2 找出/etc/ 下面文件名【刚好是五个字母】的文件名
[root@localhost ~]# ls -d /etc/?????
/etc/audit /etc/groff /etc/issue /etc/pam.d /etc/rc2.d /etc/rc5.d /etc/sasl2
/etc/fstab /etc/group /etc/libnl /etc/rc0.d /etc/rc3.d /etc/rc6.d /etc/tuned
/etc/gnupg /etc/hosts /etc/magic /etc/rc1.d /etc/rc4.d /etc/rwtab /etc/vimrc# 示例3 找出/etc/下面文件名含有数字的文件名
[root@localhost ~]# ls -d /etc/*[1-9]*
/etc/dbus-1 /etc/grub2.cfg /etc/krb5.conf.d /etc/polkit-1 /etc/rc3.d /etc/rc6.d
/etc/DIR_COLORS.256color /etc/iproute2 /etc/mke2fs.conf /etc/rc1.d /etc/rc4.d /etc/sasl2
/etc/e2fsck.conf /etc/krb5.conf /etc/pkcs11 /etc/rc2.d /etc/rc5.d /etc/X11# 示例4 找出/etc/下面文件名开头非为小写字母的文件名
[root@localhost ~]# ls -d /etc/[^a-z]*
/etc/AAA.txt /etc/DIR_COLORS.256color /etc/GREP_COLORS /etc/X11
/etc/DIR_COLORS /etc/DIR_COLORS.lightbgcolor /etc/NetworkManager# 示例5 找出/etc/下面文件名开头非为小写字母的文件名并移动到/tmp/upper中
[root@localhost ~]# mkdir /tmp/upper;cp -rf /etc/[^a-z]* /tmp/upper
[root@localhost ~]# ls /tmp/upper/
AAA.txt DIR_COLORS DIR_COLORS.256color DIR_COLORS.lightbgcolor GREP_COLORS NetworkManager X11
除了通配符之外,bash环境中的特殊符号有哪些?
| 符号 | 内容 |
|---|---|
| # | 注释符号 常常在脚本中使用,视为说明,#号后面的数据均不执行 |
| \ | 转义符 将【特殊字符或通配符】还原成一般的字符 |
| | | 管道:分隔两个管道命令的符号 |
| ; | 连续命令执行分隔符:连续性命令的界定(注意,与管道符并不相同) |
| ~ | 用户的家目录 |
| $ | 使用变量前导符:就是变量之前需要加的变量替换值 |
| & | 任务管理:将命令变成后台任务 |
| ! | 逻辑运算意义上的【非】not的意思 |
| / | 目录符号:路径分隔的符号 |
| >、>> | 数据流重定向:输出重定向,分别是【替换】与【累加】 |
| <、<< | 数据流重定向:输入定向,< 输入重定向到一个程序 |
| ’ ’ | 单引号,不具有变量替换的功能($ 变为纯文本) |
| " " | 具有变量替换的功能,($ 可保留相关功能) |
| ` ` | 两个 【`】中间为可以先执行的命令,也可以使用$( ) |
| ( ) | 在中间为子 shell的起始于结束 |
| { } | 在中间为命令区块的组合 |
以上为bash环境中常见的特殊符号集合,你的【文件名】尽量不要使用到上述字符。
数据流重定向
数据流重定向由字面意思来看,好像就是将【数据给他定向到其他地方去】的样子?没错数据流重定向就是将某个命令执行后应该要出现在屏幕上的数据,给他传输到其他地方。
什么是数据流重定向
什么是数据流重定向呢?这得由命令的执行说起,一般来说,如果你要执行一个命令,通常它会是这样的:
我们执行一个命令的时候,这个命令可能会由文件读入数据,经过处理之后,再将数据输出到屏幕上。
标准输出(>,>>)与标准错误输出(2>,2>>)
简单来说,标准输出指的是命令执行所返回的正确信息,而标准错误输出可理解为命令执行失败后,所返回的错误信息。举例来说,我们系统默认有 /etc/crontab 但却无 /etc/ajkdadjajdaj,此时若执行【cat /etc/crontab /etc/ajkdadjajdaj】这个命令时,cat会进行:
- 标准输出:读取/etc/crontab后,将该文件内容显示到屏幕上
- 标准错误输出:因为无法找到 /etc/ajkdadjajdaj ,因此在屏幕上显示错误信息
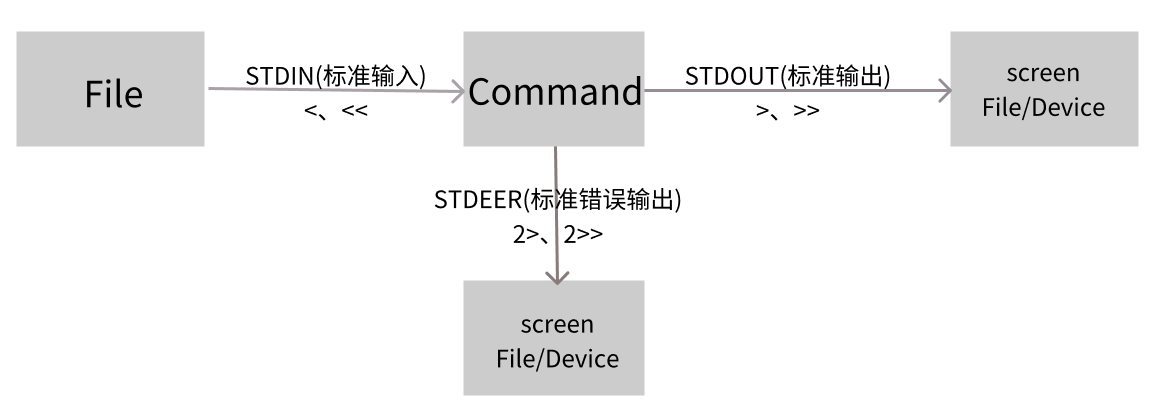
不管正确或错误的数据都是默认输出到屏幕上的,所以屏幕会很乱。那能不能通过某些机制将两股数据分开?那就是数据流重定向的功能,数据流重定向可以将STDOUT(标准输出)与STDEER(标准错误输出)分别传送到其他文件或设备,而分别传送所使用的特殊字符如下:
- 标准输入(STDIN):代码为0,使用<或<<
- 标准输出(STDOUT):代码为1,使用>或>>
- 标准错误输出(STDEER):代码为2,使用2>或2>>
为了理解STDOUT和STDEER,我们可以先来进行一个案例练习:
[root@localhost ~]# ll / # 屏幕会显示出文件名的信息
[root@localhost ~]# ll / > ~/rootfile # 屏幕并无信息
[root@localhost ~]# ll ~/rootfile # 新文件被建立了
-rw-r--r--. 1 root root 1014 4月 25 09:34 /root/rootfile
屏幕为什么不会输出信息呢?这是因为原本【ll /】所显示的数据已经被重定向到 ~/rootfile 文件中了,这个~/rootfile的文件名可以随便取。当你执行【cat ~/rootfile】那就可以看到原本应该在屏幕上面的数据。
[root@localhost ~]# cat ~/rootfile
总用量 20
lrwxrwxrwx. 1 root root 7 4月 5 20:07 bin -> usr/bin
dr-xr-xr-x. 5 root root 4096 4月 20 11:03 boot
drwxr-xr-x. 20 root root 3260 4月 25 09:07 dev
drwxr-xr-x. 76 root root 8192 4月 25 09:07 etc
drwxr-xr-x. 2 root root 6 4月 11 2018 home
lrwxrwxrwx. 1 root root 7 4月 5 20:07 lib -> usr/lib
lrwxrwxrwx. 1 root root 9 4月 5 20:07 lib64 -> usr/lib64
drwxr-xr-x. 2 root root 6 4月 11 2018 media
drwxr-xr-x. 2 root root 6 4月 11 2018 mnt
drwxr-xr-x. 2 root root 6 4月 11 2018 opt
dr-xr-xr-x. 180 root root 0 4月 25 09:07 proc
dr-xr-x---. 4 root root 221 4月 25 09:34 root
drwxr-xr-x. 26 root root 780 4月 25 09:07 run
lrwxrwxrwx. 1 root root 8 4月 5 20:07 sbin -> usr/sbin
drwxr-xr-x. 2 root root 6 4月 11 2018 srv
dr-xr-xr-x. 13 root root 0 4月 25 09:07 sys
drwxrwxrwt. 16 root root 4096 4月 25 09:07 tmp
drwxr-xr-x. 13 root root 155 4月 5 20:07 usr
drwxr-xr-x. 19 root root 267 4月 5 20:14 var
如果我再次执行【ll /home > /rootfile】后,这个/root/file 文件的内容会变成什么样呢?
[root@localhost ~]# ll /home/ > ~/rootfile
[root@localhost ~]# cat ~/rootfile
总用量 0
drwx------. 2 csq csq 62 4月 25 09:52 csq
drwx------. 2 zhw zhw 62 4月 25 09:52 zhw
drwx------. 2 zzh zzh 62 4月 25 09:52 zzh
他变成【仅有 ll /home】的数据了,这是为什么呢?原本的【ll / 】 的数据不见了,这是因为文件的建立方式是:
该文件(~/rootfile)若不存在,系统会自动地将它建立起来当这个文件存在的时候,那么系统就会先将这个文件内容清空,然后再将数据写入也就是若以>输出到一个已存在的文件中,这个文件就会被覆盖掉
那么如果我想要将数据累加而不想要将旧的数据删除,应该怎么做?利用两个大于的符号(>>)就好了。以上吗的案例来说,你应该要改成【ll / >> ~/roofile】 即可。如此一来,当~/rootfile不存在系统会主动建立这个文件,若该文件存在,则数据会在该文件的最下面累加进去。
那如果是标准错误的错误数据呢?那就通过2>及2>>,同样是覆盖(2>)与累加(2>>)的特性。刚刚上面说到stdout代码是1,而stderr代码是2,所以这个2>是很容易理解的,如果仅存在>时,则代表默认代码1,也就是说:
- 1>:以覆盖的方法将【正确的数据】输出到指定文件或设备上
- 1>>:以累加的方法将【正确的数据】输出到指定文件或设备上
- 2>:以覆盖的方法将【错误的数据】输出到指定的文件或设备上
- 2>>:以累加的方法将【错误的数据】输出到指定的文件或设备上
要注意【1>>】以及【2>>】中间是没有空格的
了解完概念再看看怎么使用,当你以一般身份执行find这个命令时,由于权限的问题可能会产生一些错误信息,例如执行【find / -name testing】时,可能会产生类似【find:/root:Permission denied】之类的信息,例如下面这个案例:
[csq@localhost ~]$ find /home -name .bashrc # 我此时的身份是csq这个一般用户
/home/csq/.bashrc <== 可以访问自己的目录下面的.bashrc文件
find: ‘/home/zhw’: Permission denied <== 报错没有权限访问
find: ‘/home/zzh’: Permission denied <== 报错没有权限访问
由于/home下面还有我们建立的其他账号存在,这些账号的根目录你当然不能进入,所以就会有错误及正确数据。
那么假如我想要将数据输出到 list 这个文件中呢?执行【find /home -name .bashrc > list】会有什么结果呢?
[csq@localhost ~]$ find /home -name .bashrc > list
find: ‘/home/zhw’: Permission denied
find: ‘/home/zzh’: Permission denied
[csq@localhost ~]$ cat list
/home/csq/.bashrc
你会发现list里面只存了刚刚的那个【正确】的输出数据。
如果我想要将正确的与错误的数据分别存入不同的文件中需要怎么做呢?
[csq@localhost ~]$ find /home -name .bashrc > list_right 2> list_error
[csq@localhost ~]$ cat list_right
/home/csq/.bashrc
[csq@localhost ~]$ cat list_error
find: ‘/home/zhw’: Permission denied
find: ‘/home/zzh’: Permission denied
你可以看到屏幕上不会出现任何信息,因为刚刚执行的结果中,有Permission denied错误的信息都会跑到【list_error】这个文件中,至于正确的信息则会存在【list_right】文件中。Do you understand?
/dev/null垃圾桶黑洞设备与特殊写法
你可以想象以下,如果我知道会有错误信息的发生,所以要将错误信息忽略掉不显示或存储应该怎么办?这个时候黑洞设备/dev/null 就很重要了,这个/dev/null 可以吃掉任何导向这个设备的信息。用法如下:
[csq@localhost ~]$ find /home -name .bashrc 2> /dev/null
/home/csq/.bashrc
# 将错误的数据丢弃,屏幕上会显示正确的数据
如果我想要将正确的数据与错误的数据通通都写入一个文件中应该怎么做?这个时候就得使用特殊的写法了,如下案例
[csq@localhost ~]$ find /home -name .bashrc > list 2>list # 错误的写法
[csq@localhost ~]$ cat list
find: ‘/home/zhw’: Permission denied
find: ‘/home/zzh’: Permission denied # 只会显示错误的数据,不会显示正确的数据[csq@localhost ~]$ find /home -name .bashrc > list 2>&1 # 正确的写法
[csq@localhost ~]$ cat list
/home/csq/.bashrc
find: ‘/home/zhw’: Permission denied
find: ‘/home/zzh’: Permission denied # 正确的数据和错误的数据都显示了[csq@localhost ~]$ find /home -name .bashrc &>list # 正确的写法
[csq@localhost ~]$ cat list
/home/csq/.bashrc
find: ‘/home/zhw’: Permission denied
find: ‘/home/zzh’: Permission denied # 正确的数据和错误的数据都显示了
上述案例中,第一种写法错误的原因是,有两股数据同时写入一个文件,又没有特殊的语法,此时两股数据可能会交叉写入该文件内,造成次序错乱。上述案例中有两种写法,可以选择第二种写法最为常用
标准输入:<与<<
了解完标准输出和标准错误输出后,那么这个<与<<又是什么呢?以最简单的语法来说,那就是【将原本需要由键盘输入的数据,改由文件内容来替换】的意思。我们先由下面的cat命令操作了解一下什么叫做键盘输入吧
案例:利用cat命令来建立一个文件的简单流程
[csq@localhost ~]$ cat > catfile
I like Linux
but I don't like English
<== 这里按下ctrl + d 来退出
[csq@localhost ~]$ cat catfile
I like Linux
but I don't like Englisht
由于加入> 在cat后,所以这个catfile会被主动地建立,而内容就是刚刚键盘上面输入的那两行数据了。那我能不能用纯文本替换键盘输入,也就是说,用某个文件的内容来替换键盘的输入
案例:用stdin替换键盘的输入以建立新文件的简单流程
[csq@localhost ~]$ cat > catfile < ~/.bashrc
[csq@localhost ~]$ ll catfile ~/.bashrc
-rw-rw-r--. 1 csq csq 231 Apr 25 15:13 catfile
-rw-r--r--. 1 csq csq 231 Apr 1 2020 /home/csq/.bashrc
# 可以看到两个文件大小一模一样,可以自行查看一下内容也是一模一样的
了解了<之后,那么<<是什么呢?它代表的是【结束的输入字符】的意思。
举例来说:我要用cat直接将输入的信息输出到catfile种,且当由键盘输入eof时,该次输入就结束
[csq@localhost ~]$ cat > catfile << "eof"
> I like Linux
> I dont like 银阁里希
> eof
[csq@localhost ~]$ cat catfile
I like Linux
I dont like 银阁里希 # 只有这两行没有关键词eof的那一行
假设我要将echo "error message"以标准错误的格式来输出,该如何处置?
既然有2>&1来将2>转到1>去,那么应该会有1>&2吧,因此你可以这样做
[csq@localhost ~]$ echo "error message" 1>&2
error message
[csq@localhost ~]$ echo "error message" 2> /dev/null 1>&2
第一行中有信息输入到屏幕上,第二条则没有信息,这表示信息已经通过2> /dev/null丢掉了垃圾桶中了,可以肯定的是错误信息
命令执行的判断根据:;、&&、||
在某些情况下,我想要一次执行很多命令,而不想分次执行时,该怎么办?基本上你有两种选择,一个是通过shell脚本去执行,一种则是通过下面的介绍来输入多个命令。
cmd ; cmd(不考虑命令相关性的连续命令执行)
在某些时候,我们希望可以一次执行多个命令,例如关机的时候我希望可以执行两次 sync同步写入磁盘后才shutdown计算机,那么可以怎么做呢?
[root@localhost ~]# sync ; sync ; shutdown -h now
在命令与命令中间利用分号【;】开隔开,这样一来,分号前的命令执行完后就立刻接着执行后面的命令。
那么我如果想在某个目录下面建一个文件,也就是说,如果该目录存在的话,那我才建立文件,如果不存在,那就不创建文件。也就是说这两个命令彼此之间是由相关性的,前一个命令是否成功执行与后一个命令要是否执行有关,那就要用&&或||
$?(命令返回值)与&&或||
如同上面谈到的,两个命令之间有依赖性,而这个依赖性主要判断的地方就在于前面一个命令的执行结果是否正确。判断原理就是【若前面一个命令执行结果正确,在Linux下面就会返回一个$?=0的值】
| 命令执行情况 | 说明 |
|---|---|
| cmd1 && cmd2 | 1. 若cmd1 执行完毕且正确执行($?=0),则开始执行cmd2 2. 若cmd1 执行完毕且为错误($?≠0),则cmd2不执行 |
| cmd1 || cmd2 | 1. 若cmd1 执行完毕且正确执行($?=0),则cmd2 不执行 2. 若cmd1 执行完毕且为错误($?≠0),则开始执行cmd2 |
上述cmd1 及 cmd2 都是命令。
# 示例1 使用ls 查看目录/tmp/abc是否存在,若存在则用touch 建立/tmp/abc/heh
[root@localhost ~]# ls /tmp/abc/ && touch /tmp/abc/hehe
ls: cannot access /tmp/abc/: No such file or directory
# ls说无法访问/tmp/abc/: 没有那个文件或目录,并没有touch的错误,表示touch并没有执行。
[root@localhost ~]# mkdir /tmp/abc
[root@localhost ~]# ls /tmp/abc/ && touch /tmp/abc/hehe
[root@localhost ~]# ll /tmp/abc/hehe
-rw-r--r--. 1 root root 0 Apr 25 16:20 /tmp/abc/hehe# 示例2 看到了吧,/tmp/abc不存在,touch就不会执行,若/tmp/abc存在的话,
# 那么touch就会开始执行。不过这样非常麻烦!能不能自动判断,如果没有该目录就自己建立一个
[root@localhost ~]# rm -rf /tmp/abc/ # 先删除此目录方便测试
[root@localhost ~]# ls /tmp/abc || mkdir /tmp/abc
ls: cannot access /tmp/abc: No such file or directory # ls报错没有/tmp/abc
[root@localhost ~]# ll -d /tmp/abc
drwxr-xr-x. 2 root root 6 Apr 25 16:23 /tmp/abc # mkdir创建了# 示例3 如果你再重复执行【ls /tmp/abc || mkdir /tmp/abc】也不会出现重复mkdir的错误,
# 这是因为/tmp/abc已经存在了,后续的mkdir 就不会执行。
# 如果我想要建立/tmp/abc/hehe这个文件,但我不知道/tmp/abc是否存在,那该如何是好?
[root@localhost ~]# ls /tmp/abc || mkdir /tmp/abc && touch /tmp/abc/hehe
上述案例种尝试建立/tmp/abc/hehe,不管/tmp/abc 是否存在。那么案例三应该如何解释?由于Linux下面的命令都是由左向右执行,所以说上述案例有几种情况来分析一下:
-
(1) 若/tmp/abc 不存在故返回 $?≠0,则 (2) 因为 || 遇到非为 0 的$?故开始 mkdir /tmp/abc ,由于mkdir /tmp/abc 会成功执行,所以返回 $?=0 (3) 遇到$?=0 故会执行 touch /tmp/abc/hehe 最终hehe被建立
-
(2) 若/tmp/abc存在故返回 $?=0 则(2) 因为|| 遇到0的$?不会执行,此时 $?=0继续向后传,故(3)因为遇到$?=0 开始建立 /tmp/abc/hehe 了,最终 /tmp/abc/hehe 被建立
整个流程图如下:
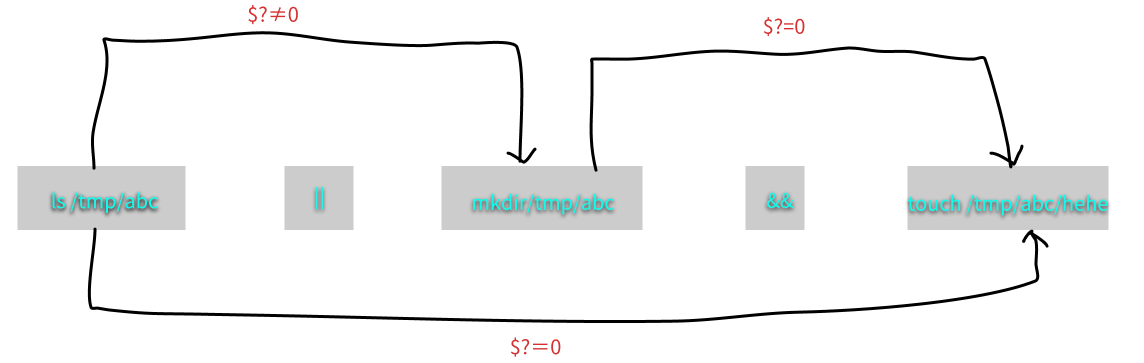
上面这张图的两股数据种,上方的线程为不存在 /tmp/abc 时所进行的命令操作,下方的线段则是存在 /tmp/abc 的命令操作。
# 以ls 测试/tmp/csq 是否存在,若存在则显示 "yes" 不存在则显示 "no"
[root@chenshiren ~]# ls /tmp/csq >/dev/null 2>&1 && echo "yes" || echo "no"
no
练习到这里你应该知道了,命令是一个接着一个去执行的,因此,如果真的使用判断,那么整个 && 与 || 的顺序不能搞错。一般来说,假设判断式有三个,也就是:
command1 && command2 || command3
一般来说 command2 和command3 会使用肯定可以执行的成功的命令。
管道命令(pipe)
有时候我在bash命令执行输出数据的时候,有时候数据必须要经过好几个命令处理后才能得到我们想要的结果。这时候我们就可以时候管道命令,管道命令使用的是【|】这个符号shift + \即可输出。我们来利用管道命令简单的举个例子
假设我们想要知道/etc/下面有多少文件,那么可以利用【 ls /etc】 来查看,不过,因为/etc 下面文件太多了,导致输出以后屏幕很多内容,此时我们可以通过 less命令的协助
[root@localhost ~]# ls /etc/ | less
如此一来,使用ls命令输出后的内容,就能够被less读取,并且利用less功能,我们就可以前后翻动或者/file 查找文件,非常方便。其实这个管道命令【|】仅能处理前一个命令传来的正确信息,也就是标准输出信息,对于标准错误信息并没有直接处理能力。
管道命令处理流程图如下所示
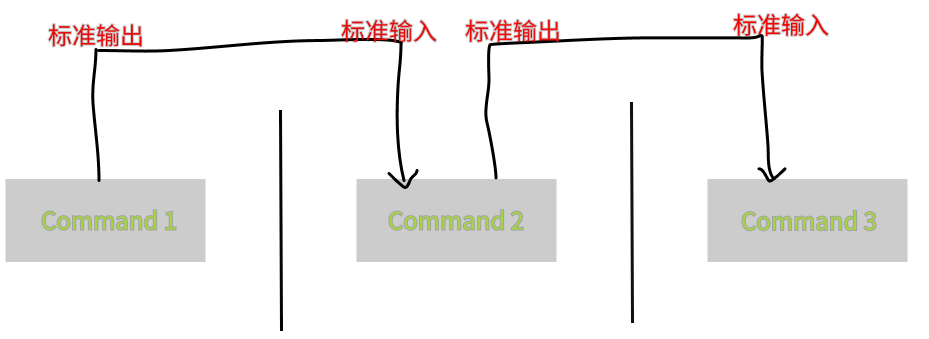
如上图所示,每个管道后面接的第一个数据必定是【命令】,而且这个命令必须能够接受标准输入的数据才行,这样的命令才可为管道命令,如less、more、head、tail 等都是可以接受标准输入的管道命令至于例如 ls、cp、mv等就不是管道命令。因为ls、cp、mv并不会接受来自stdin的数据,也就是说,管道命令主要有两个比较特殊的地方:
管道命令仅会处理标准输出,对于标准错误输出会给予忽略管道命令必须要能够接受来自前一个命令的数据成为标准输入继续处理才行。
如果你硬是要让标准错误可以被管道命令所使用的话,可以这么做。可以使用数据流重定向,让2>&1加入命令中,就可以让2> 变成1>。
选取命令:cut、grep
什么是选取命令?就是将一段数据经过分析后,取出我们所想要的,或是经由分析关键词,取得我们所想要的那一行。不过,要注意的是,一般来说,选取信息通常是针对【一行一行】来分析的,并不是整篇信息分析,下面介绍两个很常用的信息选取命令
cut
cut翻译成英格利希的意思就是【切】,这个命令可以将一段信息的某一段给他【切】出来,处理的信息就是以【行】为单位
cut -d '分隔字符' -f 字段
cut -c 字符区间
选项:
-d:后面接分隔字符,与-f一起使用
-f:根据-d分隔字符将一段信息划分成为数段,用-f取出第几段的意思
-c:以字符的单位取出固定字符的区间# 示例1 将PATH变量取出,我要找出第五个路径
[root@localhost ~]# echo ${PATH}
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin1 2 3 4 5
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 5
/root/bin
# 如同上面数字显示,我们是以【:】作为分隔,因此会出现/root/bin# 示例2 如果想要列出第3和第5,可以这样
[root@localhost ~]# echo ${PATH} | cut -d ':' -f 3,5
/usr/sbin:/root/bin# 示例3 将export输出的信息,取得第12字符以后的所有字符
[root@localhost ~]# export
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/root"
declare -x HOSTNAME="localhost.localdomain"
declare -x LANG="zh_CN.UTF-8"
declare -x LESSOPEN="||/usr/bin/lesspipe.sh %s"
declare -x LOGNAME="root"
.....
.......
...
# 注意看,每个数据都是整齐的输出,如果我们不想要【declare -x 】时,就得这样做
[root@localhost ~]# export | cut -c 12-
HISTCONTROL="ignoredups"
HISTSIZE="1000"
HOME="/root"
HOSTNAME="localhost.localdomain"
LANG="zh_CN.UTF-8"
LESSOPEN="||/usr/bin/lesspipe.sh %s"
LOGNAME="root"
...........
......
...# 示例4 用last将显示的登录者的信息中,仅留下使用者的大名
[root@localhost ~]# last
root pts/1 192.168.100.1 Wed Apr 26 08:42 still logged in
root pts/0 192.168.100.1 Wed Apr 26 08:42 still logged in
root pts/1 192.168.100.1 Tue Apr 25 15:54 - 18:56 (03:01)
root pts/0 192.168.100.1 Tue Apr 25 15:54 - 18:56 (03:01)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 15:51 - 09:37 (17:45)
.....
.......
...
# last 可以输出【账号/终端/来源/日期时间】的数据,并且是排列整齐的。
[root@localhost ~]# last | cut -d ' ' -f 1
root
root
root
root
reboot
root
root
.....
.......
...
# 由输出的结果我们可以发现第一个空白分隔的栏位代表账号,所以使用如上命令
# 但是因为root pts/1 之间空格有好几个,并非仅有一个,所以,如果要找出
# pts1/1 其实不能以 cut -d ' ' -f 1,2 输出结果会不是我们想要的
grep
刚刚的cut是将一行信息当中,取出某部分我们想要的,而grep则是分析一行信息,若当中有我们所需要的信息,则将该行拿出来,简单的语法是这样的。
grep [-acinv] [--color=auto] '查找字符' filename
选项:
-a:将二进制以文本文件的方式查找数据
-c:计算找到'查找字符'的次数
-i:忽略大小写的不同,所以大小写视为相同
-n:顺便输出行号
-v:反向选择,就是显示出没有'查找字符'内容的那一行
--color=auto:可以将找到的关键字的那一行加上颜色显示# 示例1 last当中,又出现root的那一行就显示出来
[root@localhost ~]# last | grep 'root'
root pts/1 192.168.100.1 Wed Apr 26 09:42 still logged in
root pts/0 192.168.100.1 Wed Apr 26 09:42 still logged in
root pts/1 192.168.100.1 Wed Apr 26 09:42 - 09:42 (00:00)
root pts/0 192.168.100.1 Wed Apr 26 09:42 - 09:42 (00:00)
root pts/1 192.168.100.1 Wed Apr 26 08:42 - down (00:59)
....
......# 示例2 与上述案例相反,只要没有root就取出
[root@localhost ~]# last |grep -v 'root'
reboot system boot 3.10.0-1160.el7. Wed Apr 26 09:42 - 14:05 (04:22)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 15:51 - 09:42 (17:50)
reboot system boot 3.10.0-1160.el7. Tue Apr 25 09:07 - 09:42 (1+00:34)
reboot system boot 3.10.0-1160.el7. Mon Apr 24 20:40 - 09:42 (1+13:01)
....
...# 示例3 在last的输出信息中,只要有root就取出,并且仅取第一栏
[root@localhost ~]# last |grep 'root'|cut -d ' ' -f 1
root
root
root
root
root
.......
....
# 在last输出信息中,利用cut命令的处理,就能够仅取第一栏
取出/etc/man_db.conf 内含MANPATH的那几行
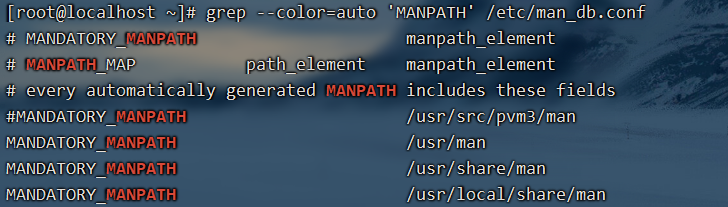
加上–color=auto 的选项,找到的关键字部分会用特殊颜色显示,但是不加也会显示,因为centos7系统中,默认已经将–color=auto 选项加入到了alias中了。
排序命令:sort、wc、uniq
很多时候,我们都会区计算一次数据里面的相同形式的数据总数,举例来说,使用last可以查得系统上面有登录主机者的身份。那么我可以针对每个用户查出它们的总登录次数吗?此时就要排序与计算之类的命令来辅助,下面介绍一下几个好用的排序与统计的命令。
sort
sort它可以帮我们进行排序,而且可以根据不同的数据形式来排序,例如数字与文字的排序就不一样。
sort [-fbMnrtuk] [file 或 stdin]
选项:
-f:忽略大小写的差异,例如A与a视为编码相同
-b:忽略最前面的空格字符部分
-M:以月份的名字来排序,例如JAN、DEC等排序方法
-n:使用【纯数字】进行排序(默认是以文字形式来排序的)
-r:反向排序
-u:就是uniq,相同的数据中,仅出现一行代表。
-t:分隔符号,默认是使用[TAB]键来分隔
-k:以哪个区间来进行排序的意思。# 示例1 个人账号都记录在/etc/passwd下,请将账号进行排序
[root@localhost ~]# cat /etc/passwd | sort
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
csq:x:1000:1000::/home/csq:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....
...
# 直接输入sort 默认是以【文字】形式来排序的,所以由a开始排序到最后# 示例2 /etc/passwd内容是以【:】分隔的,我想以第三栏来排序,该如何?
[root@localhost ~]# cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
csq:x:1000:1000::/home/csq:/bin/bash
zhw:x:1001:1001::/home/zhw:/bin/bash
zzh:x:1002:1002::/home/zzh:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
....
......
..
# 发现了吗sort默认是以文字形式来排序的,如果想要数字排序
# cat /etc/passwd | sort -t ':' -k 3 -n 这样才行 加上-n来告知sort是以数字来排序# 示例3 利用last,将输出的数据仅显示账号,并加以排序
[root@localhost ~]# last | cut -d ' ' -f 1 | sort
uniq
如果我完成了排序,我想要将重复的数据仅列出一个显示,可以怎么做呢?
uniq [-ic]
选项:
-i:忽略大小写字符的不同
-c:进行计数# 示例1 使用last将账号列出,仅取出账号栏,进行排序后,仅取出一位
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq reboot
root
wtmp# 示例2 如果我还想要知道每个人登录的总次数呢?
[root@localhost ~]# last | cut -d ' ' -f 1 | sort | uniq -c1 7 reboot34 root1 wtmp
# 1.先将所有的数据列出来 2.再将人名独立出来 3.经过排序 4.只显示一个
# 从上述案例得知可以发现reboot出现了7次,root登录则有34次,大部分都是root在登录
# wtmp与第一行的空白都是last的默认字符,两个可以忽略
这个命令用来将重复的行删除掉只显示一个,举例来说,你要知道这个月登录你主机的用户有谁,而不在乎它的登录次数,那么就可以使用上面的案例。
wc
如果我想知道/etc/man_db.conf 这个文件里面有多少文字?多少行?多少字符?,可以利用wc这个命令来完成,它可以帮我们计算出信息的整体数据
wc [-lwm]
选项:
-l:仅列出行
-w:仅列出多少字
-m:多少字符# 示例1 man_db.conf里面到底有多少行、字数、字符数呢?
[root@localhost ~]# cat /etc/man_db.conf | wc131 723 5171
# 输出的三个数字中,分别代表:【行、字数、字符数】# 示例2 使用last可以输出登录者,但是last最后两行并非账号内容,
# 那么请问,我该如何以一行命令串取得登录系统的总人次呢?
[root@localhost ~]# last |grep [a-zA-z] |grep -v 'wtmp' | grep -v 'reboot' | wc -l
34# 由于last会输出空白行,wtmp、reboot等无关账号登录的信息
# 因此,利用grep 取出非空白行,以及取出上述关键字的那几行,在计算行数,就好了
双向重定向:tee
前面我们了解过数据流重定向知道【>】会将数据流整个传送给文件或设备,因此我们除非去读取该文件或设备,否则就无法继续利用整个数据流。那如果我想要将整个数据流处理过程中将某段信息存下来,应该怎么做呢?利用tee就行
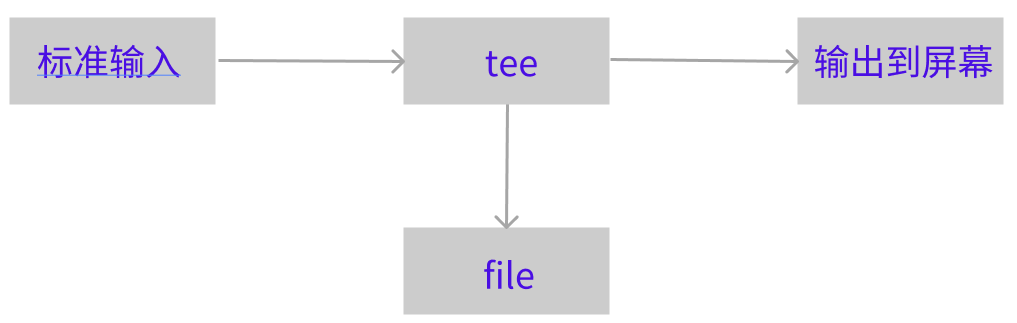
tee会同时将数据流分送到文件与屏幕,而输出到屏幕,其实是stdout,那就可以让下个命令继续处理
tee [-a] file
选项:
-a:以累加的方式,将数据加入file当中# 示例1 将last输出存一份到last.list文件中
[root@localhost ~]# last | tee last.list | cut -d " " -f 1
root
root
root
root
......
...# 示例2 将ls -l /home 的数据存一份到~/homefile,同时屏幕也有输出信息
[root@localhost ~]# ls -l /home | tee ~/homefile
total 0
drwx------. 2 csq csq 162 Apr 25 14:48 csq
drwx------. 2 zhw zhw 62 Apr 25 09:52 zhw
drwx------. 2 zzh zzh 62 Apr 25 09:52 zzh
# 如果信息很多的话在后面可以加一个【 | less】# 示例3 再ls -l /etc的数据累加到~/homefile中,同时屏幕也要输出信息
[root@localhost ~]# ls -l /etc/ | tee -a ~/homefile | less
# 是否累加成功可以自行查看
字符转换命令:tr、col、join、paste、expand
tr
可以用来删除一段信息当中的文件,或是进行文字信息的替换
tr [-ds] SET1 ....
选项:
-d:删除信息当中的SET1字符
-s:替换掉重复的字符# 示例1 将last输出的信息中,所有的小写变成大写字符
[root@localhost ~]# last | tr '[a-z]' '[A-Z]'
ROOT PTS/1 192.168.100.1 WED APR 26 09:42 STILL LOGGED IN
ROOT PTS/0 192.168.100.1 WED APR 26 09:42 STILL LOGGED IN
.....
...# 示例2 将/etc/passwd 输出信息中,将冒号【:】删除
[root@localhost ~]# cat /etc/passwd | tr -d ':'
rootx00root/root/bin/bash
binx11bin/bin/sbin/nologin
daemonx22daemon/sbin/sbin/nologin
admx34adm/var/adm/sbin/nologin
.....
...# 示例3 将/etc/passwd转成dos换行到/root/passwd中,再将^M符号删除
[root@localhost ~]# cp -rf /etc/passwd ~/passwd && unix2dos ~/passwd
unix2dos: converting file /root/passwd to DOS format ...
[root@localhost ~]# file ~/passwd
/root/passwd: ASCII text, with CRLF line terminators # 这就是DOS换行
[root@localhost ~]# cat ~/passwd | tr -d '\r' > ~/passwd.Linux
[root@localhost ~]# ll /etc/passwd ~/passwd*
-rw-r--r--. 1 root root 957 Apr 25 09:52 /etc/passwd
-rw-r--r--. 1 root root 979 Apr 26 15:12 /root/passwd
-rw-r--r--. 1 root root 957 Apr 26 15:12 /root/passwd.Linux
# 处理过后,发现文件大小与原本的/etc/passwd就一致了
上述案例,为什么可以使用\r替换?
回车符(Carriage Return)或者 \r 是一个控制字符,它在DOS/Windows系统中作为换行符的一部分存在,表示将光标移动到行首。在Linux和Unix系统中,换行符只有一个,是一个叫做 Line Feed 的字符,也就是 \n。
因此,当我们在Linux系统中使用cat命令查看一个DOS/Windows系统中的文本文件时,会看到很多 ^M 字符,这是因为 ^M 是 \r 的可见表示。而在Linux系统中,这个字符并不是换行符的一部分,因此需要将它替换掉。
tr命令可以用来替换文本中的字符,其中 -d 选项表示删除指定的字符,因此 tr -d ‘\r’ 表示删除文本中的 \r 字符。所以,使用 tr -d ‘\r’ 命令可以将 DOS/Windows 格式的文本文件转换为 Linux 格式。
col
col [-xb]
选项:
-x:将tab键转换成对的空格键# 示例1 利用cat -A 显示出所有的特殊按键,最后以col 将[TAB]转成空白
[root@localhost ~]# cat -A /etc/man_db.conf
# 执行完这个命令你就看到很多^I的符号,那就是tab
[root@localhost ~]# cat /etc/man_db.conf | col -x | cat -A |less
# 执行完命令就可以看到所有的[TAB]按键会被替换成为空格键
col的用途就是简单的处理[tab]按键替换成空格键。
join
join翻译成英格利希的意思就是(参加/加入),它是在处理两个文件之前的数据,而且,主要是在处理【两个文件当中,有相同数据的那一行,才将它加在一起的意思。
join [-ti12] file1 file2
选项:
-t:join默认以空格字符分隔数据,并且比对【第一个栏位】的数据如果两个文件相同,则将两条数据连成一行,且第一个栏位放在第一个
-i:忽略大小写的差异
-1:这个是数字的1,代表【第一个文件要用哪个栏位来分析】的意思
-2:代表【第二个文件要用哪个栏位来分析】的意思# 示例1 用root身份,将/etc/passwd与/etc/shadow相关数据整合成一栏
[root@localhost ~]# head -n 3 /etc/passwd /etc/shadow
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin==> /etc/shadow <==
root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:*:18353:0:99999:7:::
daemon:*:18353:0:99999:7:::
# 由于输出的数据可以发现在两个文件的最左边栏都是相同账号,且以:分隔
[root@localhost ~]# join -t ':' /etc/passwd /etc/shadow | head -n 3
root:x:0:0:root:/root:/bin/bash:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:*:18353:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:18353:0:99999:7:::
# 通过上面的操作,我们可以将两个文件第一栏位相同者整合成一行
# 第二个文件的相同栏位并不会显示(因为已经在最左边的栏位出现了)# 示例2 我们知道/etc/passwd 第四个栏位是GID
# 这个GID记录在/etc/group 当中的第三个栏位,请问如何将两个文件整合?
[root@localhost ~]# head -n 3 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin==> /etc/group <==
root:x:0:
bin:x:1:
daemon:x:2:
# 从上面可以看出确实有相同的部分
[root@localhost ~]# join -t ':' -1 4 /etc/passwd -2 3 /etc/group | head -n 3
0:root:x:0:root:/root:/bin/bash:root:x:
1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:
2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:# 同样的,相同的栏位部分移动到了最前面,所以第二个文件的内容就每显示
paste
这个paste就要比join简单多了。相对于join必须要比对两个文件的数据相关性,paste就直接将两行贴在一起,且中间以【TAB】键隔开
paste [-d] file1 file2
选项:
-d:后面可以接分隔字符,默认是以【TAB】来分隔
- :如果file部分写错了 -,表示来自标准输入的数据的意思# 示例1 用root的身份,将/etc/passwd与/etc/shadow同行贴在一起,且仅取出前3行
[root@localhost ~]# paste /etc/passwd /etc/shadow - |head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:18353:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:18353:0:99999:7:::
# 注意同一行间是以【TAB】按键隔开的可以仔细看一下# 示例2 先将/etc/group读出(用cat),然后与上述案例的那两个文件忒在一起,且仅取出前3行
[root@localhost ~]# cat /etc/group | paste /etc/passwd /etc/shadow - | head -n 3
root:x:0:0:root:/root:/bin/bash root:$6$0x0W5U0lAIGfNePS$fQegjEeiYdvyV7xK7zyhR9jsXzAwkB6XoA6RxpGo0X/uz8uPhblK9frf36sRtpdyNgJY4jZPQplMR1b/Hqgb9/::0:99999:7::: root:x:0:
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:18353:0:99999:7::: bin:x:1:
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:18353:0:99999:7::: daemon:x:2:
expand
这个命令就是在将【TAB】按键转成空格键
expand [-t] file
选项:
-t:后面可接数字,一般来说一个TAB按键可以用8个空格键来替换我们也可以自定义一个【TAB】按键代表多少个字符
# 示例1 将/etc/man_db.conf 内行首的MANPATH的字样就取出,仅取前三行
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3
MANPATH_MAP /bin /usr/share/man
MANPATH_MAP /usr/bin /usr/share/man
MANPATH_MAP /sbin /usr/share/man
# 行首的 ^ 的意思是找出以MANPATH的行# 示例2 上述案例,如果我想要将所有的符号都列出来来?
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# cat -A 可以将【TAB】键显示为【^I】
承接上述案例,我将【TAB】按键设置成6个字符的话?

如果你字符长度设置为 9 或 10就又不同了,还有个命令unexpand是将空格转成【TAB】命令
我们把上述的案例改一下 在让他转成【TAB】命令
[root@localhost ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | expand -t 8 -| unexpand -t 8 - | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# 就像这样 好像转空格了 又好像没转,左右摇摆
划分命令:split
split命令它可以帮你将一个大文件,依据文件大小或行数来划分,就可以将大文件划分为小文件了
split [-bl] file PREFIX
选项:
-b:后面可接欲划分成的文件大小,可加单位,例如b、k、m等
-l:以行数来进行划分
PREFIX:代表前缀字符的意思,可作为划分文件的前缀文字# 示例1 我的/etc/services 有600多K,若想要分成300K一个文件时
[root@localhost ~]# cd /tmp/;split -b 300K /etc/services services
[root@localhost tmp]# ll -k services*
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesaa
-rw-r--r--. 1 root root 307200 Apr 26 16:10 servicesab
-rw-r--r--. 1 root root 55893 Apr 26 16:10 servicesac
# 这个文件名可随意取,我们只要写上前缀文字,小文件就会以xxxaaa,xxxab,xxxac等方式来建立小文件# 示例2 如何将上面的三个小文件合成一个文件,文件名servicesback
[root@localhost tmp]# cat services* >> servicesback
[root@localhost tmp]# ls -l servicesback /etc/services
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
-rw-r--r--. 1 root root 670293 Apr 26 16:13 servicesback# 示例3 使用ls -al /输出的信息中,每十行记录一个文件
[root@localhost tmp]# ls -al /etc/ | split -l 10 - lsroot
[root@localhost tmp]# wc -l lsroot*0 lsroot10 lsrootaa10 lsrootab10 lsrootac10 lsrootad........
# 重点在这个-号,一般来说如果需要stdout或是stdin时,但偏偏又没有文件
# 有的只是 - 时,那么这个 - 就会被当成 stdin或stdout
参数代码:xargs
xargs是在做什么?以字面的意义来看,x是加减乘除的乘号,args则是参数的意思,所以说这个命令就是在产生某个目录的参数的意思。xargs可以读入stdin的数据,并且以空格符或换行符作为识别符,将stdin的数据分隔为参数。因为是以空格符作为分隔,所以,如果有一些文件名或是其他意义的名词内含有空格符的时候,xargs可能就会误判,用法如下
xargs [-0epn] command
选项:
-0:如果输入stdin含有特殊字符,例如:`、\、空格等特殊字符时,这个-0参数可以将它还原成一般的字符,这个参数可以用于特殊状态
-e:这个是EOF的意思,后面可以接一个字符,当xargs分析到这个1字符时,就会停止工作
-p:在执行每个命令时,都会询问使用者的意思
-n:后面接次数,每次command命令执行时,要使用几个参数的意思
当xargs后面没有接任何命令的时候,默认是以echo 来进行输出# 示例1 将/etc/passwd内的第一栏取出,仅取三行,使用id这个命令将每个账号内容显示出来
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
# 通过-n处理,一次给予一个参数# 示例2 同上,但是执行id时,都要询问使用者是否操作?
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -p -n 1 id
id root ?...y
uid=0(root) gid=0(root) groups=0(root)
id bin ?...y
uid=1(bin) gid=1(bin) groups=1(bin)
id daemon ?...y
uid=2(daemon) gid=2(daemon) groups=2(daemon)# 示例3 将所有的/etc/passwd内的账号都以id查看,但查到sync就结束命令串
[root@localhost ~]# cat /etc/passwd | head -n 7
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd | xargs -e'sync' -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
uid=3(adm) gid=4(adm) groups=4(adm)
uid=4(lp) gid=7(lp) groups=7(lp)
# 注意上述案例中那个-e'sync'是连在一起的,中间没有空格
# 可以看到我们查看 /etc/passwd sync在第6行,当分析到第6行内容时就自动停止了
关于减号【-】的用途
管道命令在bash的连续的处理程序中是相当重要的。另外,在日志文件的分析中也是相当的重要。在管道命令中,常常会使用到一个命令的标准输出(stdout)作为这次的标准输入(stdin),某些命令需要用到文件名(例如 tar)来进行处理时,该stdin与stdout可以利用减号【-】来替代,举例来说
[root@localhost ~]# tar -cvf - /home | tar -xvf - -C /tmp/homeback/
上面的例子是说:【我将/home里面的文件给他打包,但打包的数据不是记录到文件,而是传送到stdout,经过管道后,将tar -cvf - /home 串送给后面的 tar -xvf -】后面的这个【-】则是使用前一个命令的stdout,因此,我们就不需要文件名了。