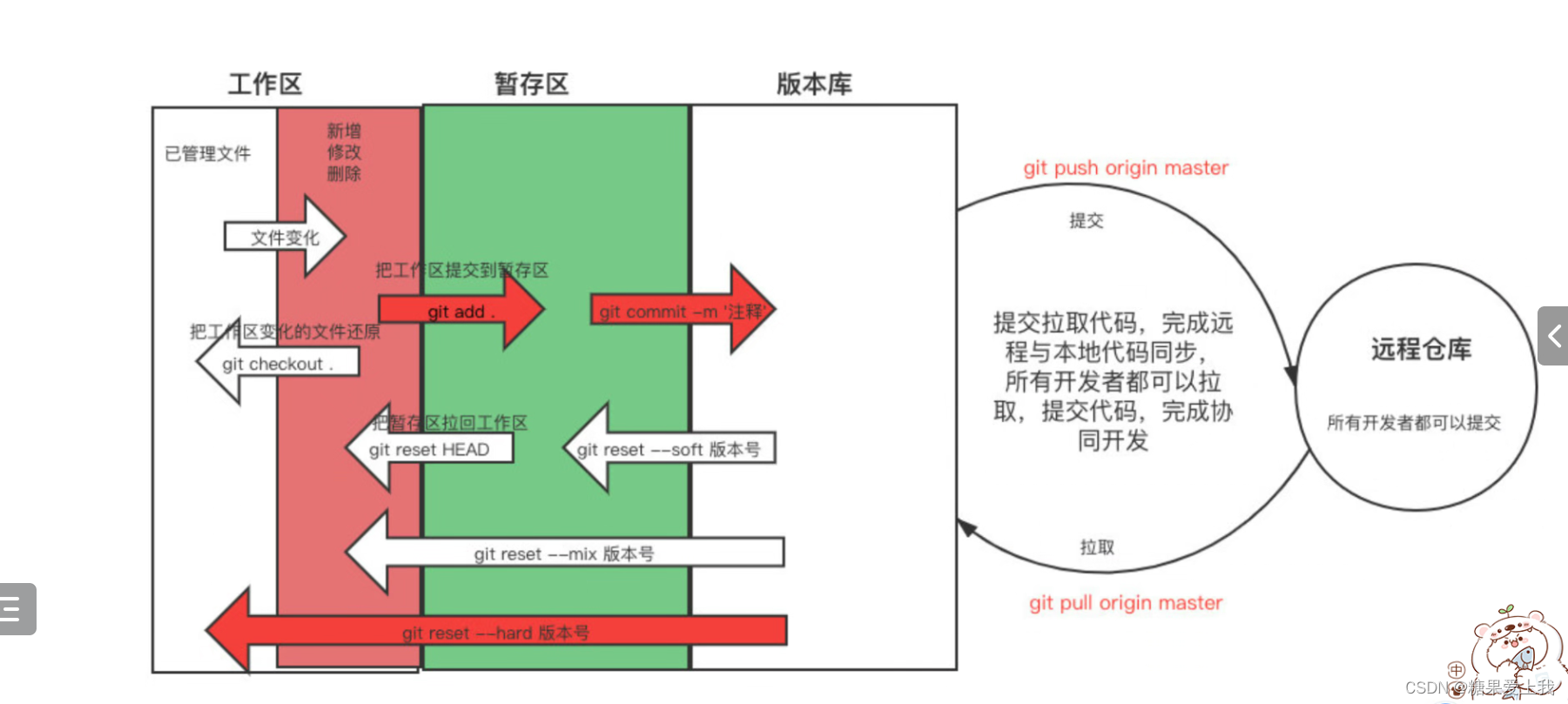
-
批量新增excel文件
import osimport xlwings as xwapp = xw.App(visible=True,add_book=False)#visible设置为ture的时候会自动打开创建的excel文件,设为为false的时候不会看到excel文件打开了,实际进程占用了....dept_list = ['人事部','财务部','研发部','行政部']path = os.path.abspath(os.path.abspath(os.path.dirname(__file__)))dept_path = os.path.join(path,'excel文件')for dept in dept_list:workbook = app.books.add()workbook.save(f'{dept_path}/部门业绩-{dept}.xlsx') -
批量打开excel文件
import os import xlwings as xw app = xw.App(visible=True,add_book=False) for dir,curdir,files in os.walk(dept_path):if files:for file in files:file_path = os.path.join(dir,file)if file.endswith('.xlsx'):app.books.open(file_path) -
批量修改excel文件工作表名
import osimport xlwings as xwapp = xw.App(visible=False,add_book=False)path = os.path.abspath(os.path.abspath(os.path.dirname(__file__)))dept_path = os.path.join(path,'excel文件')#批量修改 【部门业绩-行政部.xlsx 】 这个文件的工作表名workbook =app.books.open(f'{dept_path}\部门业绩-行政部.xlsx')for sheet in workbook.sheets:sheet.name = sheet.name.replace('Sheet','部门')workbook.save()app.quit()
4.合并相似excel文件内容到一个excel(只会合并每个excel第一个sheet页的内容)
import pandas as pddata_list = []for dir,curdir,files in os.walk(dept_path):if files:for file in files:file_path = os.path.join(dir,file)if file.endswith('.xlsx') and file.startswith('部门业绩-'):data_list.append(pd.read_excel(file_path))data_all = pd.concat(data_list)data_all.to_excel('部门业绩.xlsx')
-
合并一个excel文件多个sheet页内容到第一个sheet页中
import pandas as pd import xlwings as xw file = f'{dept_path}\部门业绩-行政部.xlsx' df_list = pd.read_excel(file,sheet_name=None) df_all = pd.concat(df_list.values()) app=xw.App(visible=False,add_book=False) workbook = app.books.open(file) workbook.sheets.add('汇总表',before=workbook.sheets[0]) workbook.sheets['汇总表'].range('A1').options(index=False).value=df_all workbook.save() workbook.close() app.quit() -
拆分excel表(按照某个分类拆分成不同的excel表)
import pandas as pd file = f'{dept_path}\产品表.xlsx' df= pd.read_excel(file) products = df['产品类型'].unique() #去重获取产品类型这一列所有产品for product in products:df_product = df[df['产品类型']==product]df_product.to_excel(f'{dept_path}\产品表-{product}.xlsx') -
拆分excel表(按照某个分类拆分成不同的sheet页)
import pandas as pd file = f'{dept_path}\采购表.xlsx' #读取所有sheet页 df_list= pd.read_excel(file,sheet_name=None,parse_dates=False) #合并成一个大数据表 df_all = pd.concat(df_list.values())file2 = f'{dept_path}\采购表-按产品类分.xlsx' excel_writer = pd.ExcelWriter(file2,date_format='YYYY-MM-DD') for product,df in df_all.groupby('产品类型'):df.to_excel(excel_writer,product,index=False) excel_writer.save() -
比较2个excel文件内容
import os import xlwings as xwapp = xw.App(visible=False,add_book=False) file = f'{dept_path}\产品表.xlsx' file_back = f'{dept_path}\产品表-备份.xlsx' book = app.books.open(file) book_backup = app.books.open(file_back)for row in book.sheets[0].range('A1').expand():for cell in row:backup_cell = book_backup.sheets[0].range(cell.address)if cell.value != backup_cell.value:cell.color = backup_cell.color = (255,0,0) book.save() book.close() book_backup.save() book_backup.close() app.quit()