1. 介绍
Intel®以太网800系列网络适配器提供卓越的性能,以满足各种工作负载的要求。800系列提供了数据包分类和排序优化、硬件增强的定时能力以及完全可编程的流水线。Intel的以太网产品组合始终提供可靠的体验和经过验证的互操作性。
在DPDK中,ICE轮询模式驱动程序(PMD)管理着800系列适配器,包括了10Gb/25Gb/50Gb/100Gb Intel以太网网络适配器E810。ICE PMD的数据平面具有不同的、分离的代码路径,包括标量和向量数据路径,可在运行时选择以获得最佳性能。向量数据路径通过使用Intel SIMD指令和其他技术进行加速。基于可用的特定SIMD指令集,向量数据路径选择涵盖了Intel®流式SIMD扩展(Intel® SSE)、Intel®高级矢量扩展2(Intel® AVX2)和Intel®高级矢量扩展512(Intel® AVX-512)数据路径。由于这些向量数据路径的性能显著优于标量路径,我们也将向量路径称为“快速路径”,将标量路径称为“慢速路径”。
本技术指南重点介绍了ICE PMD的数据平面性能,包括用于提高CPU核心上数据包转发性能的方法。还说明了在驱动程序数据路径上使用Intel SSE/Intel AVX2/Intel AVX-512所实现的性能提升。这些内容可以帮助您更好地了解性能提升背后的细节。
这份文档是Network & Edge Platform Experience Kits的一部分。
作者:Leyi Rong Bruce Richardson Georgii Tkachuk
2. 概述
Intel以太网800系列网络适配器提供了从1到100Gbps以太网速率的高效工作负载优化性能。800系列旨在通过创新和多方面的能力来优化NFV、存储、HPC-AI和混合云工作负载,从而改善网络性能。
DPDK是数据平面开发工具包,包含了用于加速运行在各种CPU架构上的数据包处理工作负载的库。DPDK最初在DPDK 19.02版本中添加了800系列以太网网络适配器的ICE轮询模式驱动程序(PMD),为10/25/50/100Gbps的800系列网络适配器提供支持,并且该驱动程序在DPDK的后续版本中得到了进一步改进。虽然ICE PMD支持许多功能,但与DPDK中的其他网络适配器驱动程序一样,数据包处理性能仍然是DPDK PMD的关键指标。
一般来说,当讨论数据包处理性能时,我们应该考虑不同的数据路径,包括标量和向量。向量数据路径利用了Intel的SIMD指令集,对于ICE PMD,可用的向量数据路径包括使用Intel SSE、Intel AVX2和Intel AVX-512进行优化的路径。因此,本文重点讨论以下主题:
不同数据路径(标量/Intel SSE/Intel AVX2/Intel AVX-512)的单核性能比较
在加速的向量数据路径上使用的优化方法,特别是在Intel AVX-512数据路径上
3. 性能比较
Intel于1997年推出了第一代带有MMX扩展的SIMD处理器,用于x86架构。随后,Intel开发了Intel® Streaming SIMD Extensions (Intel® SSE)和Intel® Advanced Vector Extensions (Intel® AVX)以进一步提高SIMD操作的性能。Intel AVX-512是Intel于2013年提出,由一组512位指令组成,用于对之前256位Intel AVX指令的扩展。Intel AVX-512首先在Intel的Xeon Phi x200(Knights Landing)中实现,然后在新的Intel Xeon可扩展处理器系列中实现。
3.1 基准测试平台
由于Intel AVX-512每个指令消耗更宽的数据并使用更多的功率,在某些Intel处理器中,当执行Intel AVX-512指令时,CPU频率可能会随之降低。随着在较新的Intel Xeon可扩展处理器系列中使用Intel AVX-512时潜在的频率降低情况的缓解,我们使用第四代Intel Xeon可扩展处理器作为性能基准测试平台。表1描述了性能基准测试平台的详细信息。
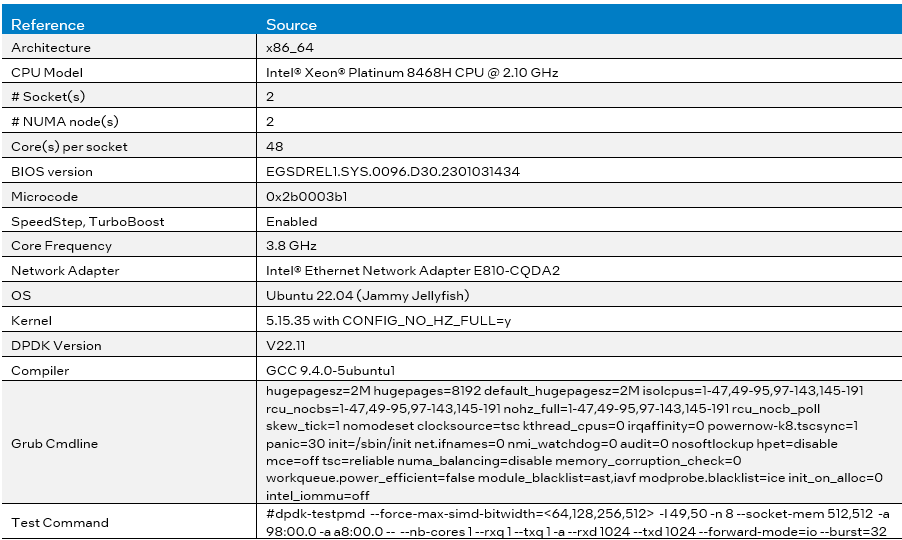
表1.Performance Benchmark Platform Configuration
性能基准测试平台拓扑结构使用两个双口100Gb以太网网络适配器E810的单个端口(每个网络适配器一个端口)连接到Ixia® Traffic Generator,因为网络适配器E810-CQDA2每个适配器最多仅支持100Gb。这意味着如果数据包大小为64字节,则核心应处理总共297.6 Mpps的聚合流量。DPDK的“Testpmd”参考应用程序负责从Ixia转发数据包,如图1所示。需要注意的是,在测试用例中使用了RFC2544零丢包测试,设置可接受的数据包丢失率为0。
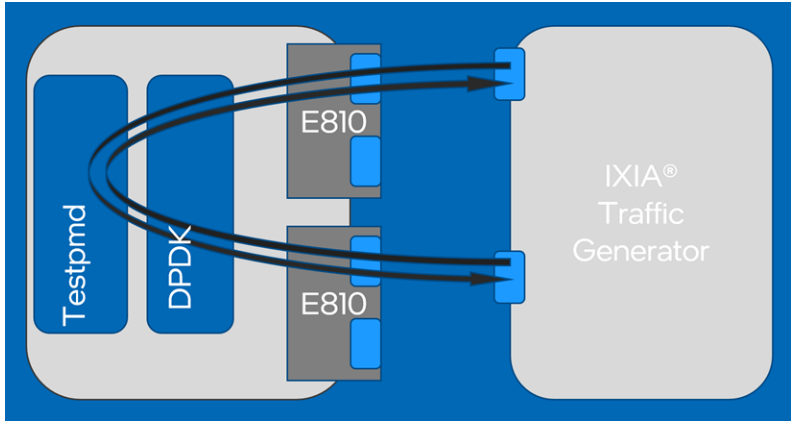
图1.Performance Benchmark Test Topology
3.2 数据路径选择
如前面所述,在DPDK ICE PMD中,数据平面有几种SIMD加速实现。这不仅适用于特定的PMD,对于DPDK中的其他Intel高速以太网适配器,例如“ixgbe”和“i40e” PMD,也存在多个加速实现。尽管这些快速数据路径不支持所有网络适配器的网络卸载功能,特别是在传输(Tx)侧,但在不需要这些高级卸载功能的场景中,选择专用的快速数据路径是值得的,因为这样的路径可以通过使用先进的SIMD扩展指令集和相关优化在最先进的现代处理器上提供更好的性能。以ICE PMD为例,添加了三种SIMD扩展实现,再加上原始的标量数据路径,因此可以根据平台和应用要求选择四种不同的数据路径之一。这四条路径及其驱动程序中源代码的位置如下:
标量数据路径 – ice_rxtx.c
Intel SSE 数据路径 – ice_rxtx_vec_sse.c
Intel AVX2 数据路径 – ice_rxtx_vec_avx2.c
Intel AVX-512 数据路径 – ice_rxtx_vec_avx512.c
DPDK testpmd应用程序用于测试ICE PMD数据包转发性能。通常来说,驱动程序本身在运行时选择其认为最佳的代码路径 ,如果硬件支持的话, 通常是Intel AVX2路径。但我们可以通过在运行时向应用程序传递DPDK EAL参数“--force-max-simd-bitwidth = <val>”来手动调整数据路径选择。例如,要选择Intel AVX-512数据路径(在支持的硬件上),将--force-max-simd-bitwidth = 512追加到testpmd命令中。类似地,将<val>更改为64、128和256,可以分别将数据路径选择更改为标量、Intel SSE和Intel AVX2数据路径。
3.3 不同数据路径的性能基准测试
为了展示使用ICE PMD可以实现的数据包转发性能,图2显示了我们从标量数据路径开始,通过选择各种向量化数据路径,一直到Intel AVX-512路径时测得的数据包吞吐量。测试配置如表1所示。驱动程序使用32字节的灵活接收描述符格式,接收/发送描述符环形队列大小为1024。
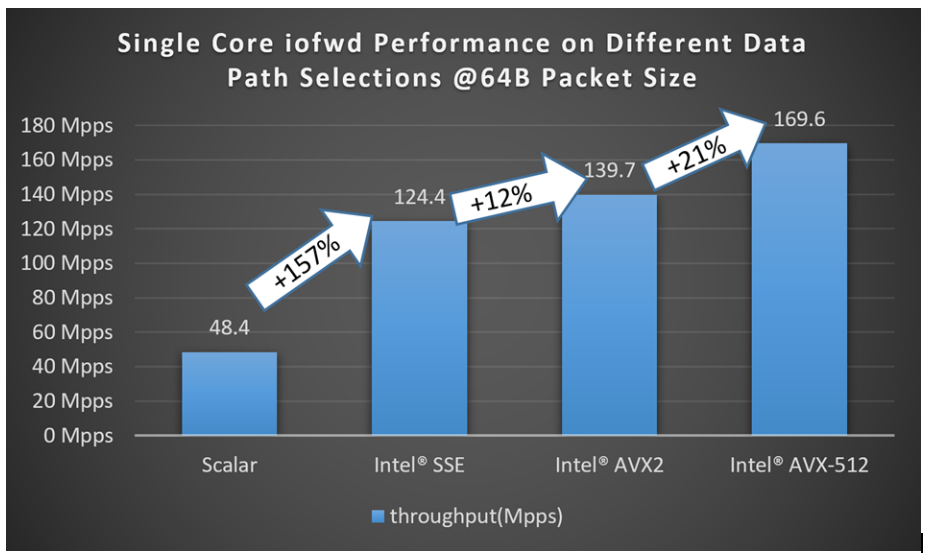
图2.Single Core iofwd Performance on Different Data Path Selections @ 64B Packet Size
性能测试结果表明,运行在单个核心上的testpmd iofwd(转发模式,在不修改接收到的每个数据包的情况下进行转发)从使用标量数据路径到使用Intel SSE数据路径,再到Intel AVX2数据路径,最终到Intel AVX-512数据路径时,都可以实现显著的性能提升。总体而言,在使用Intel AVX-512数据路径和最初的标量数据路径之间,单个核心的性能提高了约3.5倍。需要注意的是,这些路径支持的功能并不完全相等,因为标量数据路径支持更高级的网络卸载功能。然而,即使仅在三种不同的向量化代码路径之间进行比较(它们在功能上是等效的),数据也表明可以通过使用更高级的SIMD指令来实现性能提升。
4. ICE PMD 性能优化
第3.3节展示了当将数据路径从标量更改为Intel AVX-512实现时,驱动程序性能会大大提高。在本节中,我们将深入探讨在最新的Intel Xeon可扩展处理器上使用最新的Intel AVX-512数据路径如何优化性能。
4.1 ICE PMD 报文流水线
本小节概述了ICE PMD中如何处理网络数据包。
4.1.1 接收路径流水线
图3展示了接收网络数据包所涉及的步骤。如图所示,步骤如下:
CPU/驱动程序将接收描述符写入内存/缓存中的网络端口接收描述符环形队列。该描述符包括对空缓冲区的引用,网络适配器可以将新接收的数据包放入其中。
网络适配器读取接收描述符以获取缓冲区地址以存放数据包。
网络适配器使用DMA将接收到的数据包写入提供的缓冲区。
网络适配器向描述符环形队列回写接收描述符,以通知软件已接收并将数据包放入提供的缓冲区中。
CPU从新的接收描述符中读取接收到的数据包的详细信息,例如数据包长度或者数据包的卸载元数据。
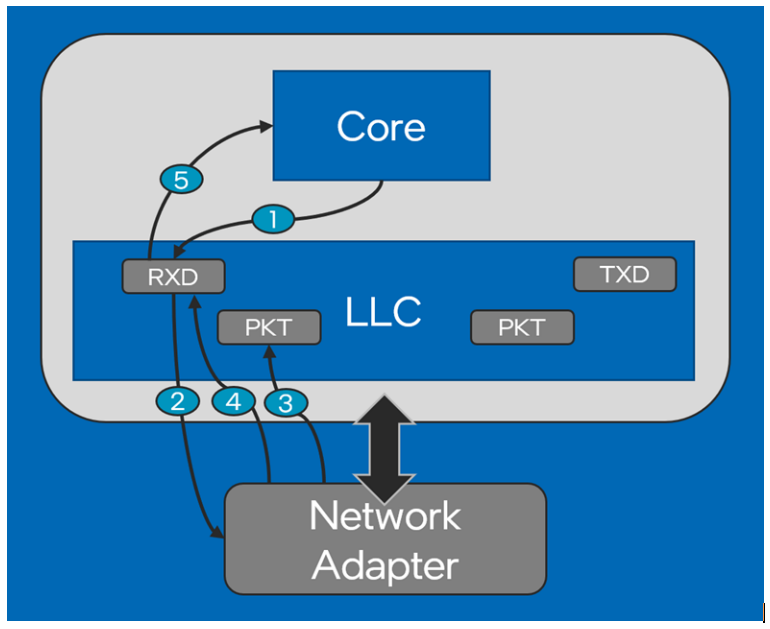
图3.Rx Path Pipeline
4.1.2 送发路径流水线
同样,图4展示了发送路径数据包处理流水线。发送数据包的步骤如下:
CPU将新的数据写入数据包缓冲区。对于新创建的数据包,这将是包括协议头在内的完整数据包。在将先前接收到的数据包重新发出系统前,CPU可能只写入少量数据,例如更新数据包头,然后进行传输。
CPU读取下一个发送描述符以检查网络适配器是否已使用该发送描述符完成了之前的发送。如果是的话,则可以重新使用该发送描述符进行发送流程。如果之前的发送未完成,则没有可用的发送描述符,这次数据包传输失败。
CPU将发送描述符写入描述符环形队列。该描述符包括指向要传输的数据包所在的缓冲区的指针,以及其他必要的元数据,例如数据包长度。对于标量数据路径,此描述符可能包括网络适配器在真正开始传输数据包前需要执行的一些转换的详细信息(即发送侧网络卸载数据)。
网络适配器读取发送描述符以获取数据包缓冲区地址和数据包长度。
网络适配器从缓冲区读取发送数据包并进行传输。
网络适配器回写新的发送描述符以更新传输状态。对于标量数据路径,网络适配器在每个数据包传输后都会回写完成状态。然而,对于向量数据路径,仅会在N个数据包(默认为32个)后才执行回写,以节省PCI传输带宽来提升性能。这种优化仅在向量数据路径实现,因为向量路径不支持所有的发送侧网络卸载功能,每个数据包仅使用一个描述符。然而这种优化并不适用标量路径,因为网络适配器仅在数据包的最后一个描述符上执行回写,并且无法保证每一次的第N个描述符都是数据包的最后一个描述符。

图4.Tx Path Pipeline
4.2 Intel AVX-512 数据路径的优化
Intel AVX-512是x86平台上最新的Intel SIMD扩展技术。与其前身Intel AVX2相比,它将可用的SIMD寄存器数量翻倍,并将每个寄存器的宽度从256位扩展到512位。除了更多和更宽的SIMD寄存器外,Intel AVX-512还扩展了指令集,提供了更高级的功能,包括掩码操作,嵌入式广播,指令前缀嵌入舍入控制以及压缩地址偏移量功能。
如图2所示,Intel AVX-512数据路径无疑是ICE PMD内性能表现最佳的数据路径。与早期驱动程序路径相比,显著的性能提升不仅来自于使用Intel AVX-512指令,还来自于其他一些代码优化。下面的章节将更详细地介绍其中的一些优化方法。
4.2.1 使用SIMD 指令进行向量处理
第4.1节描述了在核心上接收数据包时发生的处理过程。就 CPU 时间周期成本而言,其中相当大一部分的核心周期被用于处理来自网络适配器的接收描述符,并将信息从描述符传输到 DPDK 内部缓冲区元数据“mbuf”结构(第4.1.1节的第5步)。我们可以使用 SIMD 指令来加速此过程,同时处理多个描述符中的信息。
Intel 以太网800 系列网络适配器的默认 32 字节灵活接收描述符格式如图5所示。
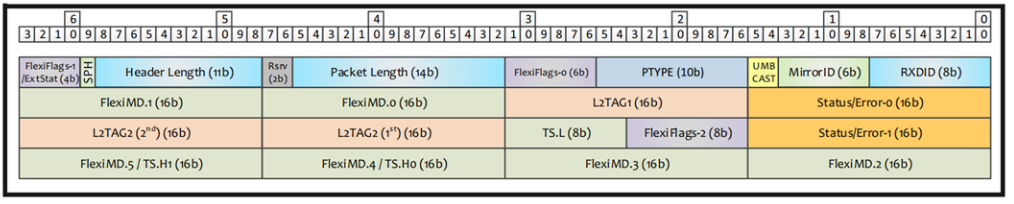
图5.Receive Flex Descriptor
由于大多数所需的数据包信息,如数据包长度、数据包类型、描述符完成指示符和数据包结束指示符,都在 32 字节 接收描述符的前 16 字节中提供,因此来自最多四个接收描述符的数据可以合并到一个(64 字节)Intel AVX-512 ZMM 寄存器中。这四个描述符可以通过利用 Intel AVX-512 指令同时进一步处理。这四个组合的接收描述符在寄存器中的格式如图6所示。
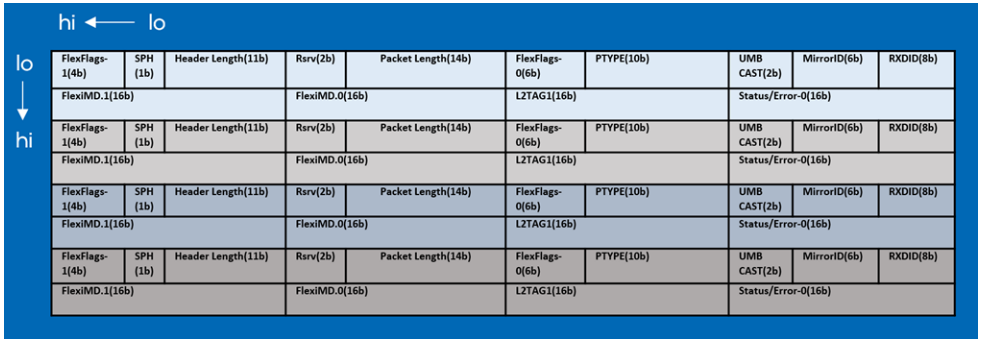
图6.Format of Combined Four Rx Descriptors in One Intel AVX-512 Register
在将四个接收描述符收集到单个 Intel AVX-512 寄存器中后,PMD 开始从接收描述符操作和解释数据包信息到mbuf中。使用一组 512 位和 256 位指令,例如使用_mm512_shuffle_epi8()来按指定的控制掩码重排打包元素,或者使用_mm512_extracti64x4_epi64()以提取 512 位宽度数据的所选 256 位部分,或者使用 _mm512_mask_blend_epi32()将指定的控制掩码混合打包整数,驱动程序解析并重新组织描述符的字段以匹配 DPDK mbuf 结构中字段的内存布局。在这些向量化操作之后,每个数据包的 mbuf 结构可以通过单个 32 字节存储指令适当地填充,如图7所示。有关更多信息,请参见 Intel® 64 and IA-32 Architectures Software Developer's Manual。

图7.Reorganized Descriptor’s Content to Fill Up DPDK “mbuf” Structure
与上述过程类似,向量化指令也在此数据路径的其他位置使用,通过并行处理以帮助实现更好的性能。尽管本指南未包含所有这些向量化处理的细节,但读者仍可以从上述片段的示例中学习。
4.2.2 直接对内存池进行操作
在第 4.2.1 节中描述的发送路径中,在 PMD 开始传输数据包之前,会检查可用的发送描述符数量。当空闲发送描述符数量低于 tx_free_thresh 定义的阈值时,PMD 必须尝试释放那些已完成传输的数据包的缓冲区,并使其占用的描述符可供重新使用。
在 PMD 内部,相当大比例的处理时间可能会用于缓冲区分配和释放。特别是,在传输后释放缓冲区可能带来很大的开销,因为每个数据包可能需要单独检查以确定它属于哪个缓冲区“池”,然后将其释放回该池。可以通过多种方式来提高缓冲区释放的性能,所有这些方式都在 Intel AVX-512 传输路径中的 ICE PMD 中实现了。
首先,在网络适配器端口配置时,DPDK 允许应用程序通过 FAST_FREE 标志指定正在传输到端口上的缓冲区都属于同一内存池,并且不会使用大于单个缓冲区的数据包。当提供此标志时,PMD 中的缓冲区释放函数只需要查看要释放的第一个数据包的缓冲区池,然后可以在单个 put 操作中释放所有缓冲区到同一内存池。
其次,PMD 利用了在所有情况下都返回固定数量元素到内存池的事实,使得 PMD 可以避免使用内存池实现的通用代码,而是使用优化的 Intel AVX-512 操作将指针存储在内存池中。虽然内存池代码尝试一次复制一个缓冲区指针,但驱动程序代码可以使用 AVX-512指令一次加载和存储八个指针。这大大减少了所需的加载/存储操作数量,提高了性能。
4.2.3 其他优化手法
本指南的前几节介绍了主要的优化方法。本节会介绍一些小但有用的技巧,来提高性能。
微调 接收/发送阈值常量,以在吞吐量和延迟之间取得平衡。
使用写组合存储(Write Combining Store)而不是常规 MMIO 写入来更新队列尾寄存器。对于传输中的较小突发,这可以在支持的平台上提供可观的优势。通过使较小的突发更加经济,此更改还可帮助应用程序实现更低的延迟。
使用内联 - 例如通过函数属性显式内联 - 可确保代码不会因被拆分为单独的函数而付出代价,通过确保编译器将子函数内联到主代码块中。
通过将多个加载/存储合并为一个向量化操作来最小化加载/存储操作。例如,进行单个 32 字节或 64 字节存储,而不是多个 4 字节或 8 字节存储操作。
5. 总结
本技术指南展示了使用最新的 Intel AVX-512 指令集所能实现的好处。它通过在使用不同指令集(标量和向量)时,DPDK 轮询模式驱动程序对 Intel® 以太网800 系列网络适配器所达到的性能表现来展示。Intel AVX-512 代码路径明显比以前使用 Intel SSE 或 Intel AVX2 的向量化实现更快,同时也比标量代码快得多 - 尽管提供的卸载集比后者少。
此外,本文还探讨了 AVX-512 数据路径采取的一些主要优化方法,解释了这些优化如何有助于提高性能。

转载须知
DPDK与SPDK开源社区
公众号文章转载声明
推荐阅读
深入浅出Hyperscan出版啦!
SPDK Trace Log用法简介


点点“赞”和“在看”,给我充点儿电吧~