海底这类特殊数据场景下的检测模型开发相对来说比较少,在前面的博文中也有一些涉及,感兴趣的话可以自行移步阅读即可:
《尝试探索水下目标检测,基于yolov5轻量级系列模型n/s/m开发构建海底生物检测系统》
《基于YOLOv5+C3CBAM+CBAM注意力的海底生物[海参、海胆、扇贝、海星]检测识别分析系统》
《基于自建数据集【海底生物检测】使用YOLOv5-v6.1/2版本构建目标检测模型超详细教程》
《探索水下低光照图像检测性能,基于轻量级YOLOv8模型开发构建海底生物检测识别分析系统》
《探索水下低光照图像检测性能,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建海底生物检测识别分析系统》
《探索水下低光照图像检测性能,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建海底生物检测识别分析系统》
《探索水下低光照图像检测性能,基于DETR(DEtection TRansformer)模型开发构建海底生物检测识别分析系统》
在前文我们已经实践开发了YOLO系列的模型,本文的主要想法是想要基于早期的YOLOv3来开发构建海底生物检测识别系统。
首先看下实例效果:
简单看下实例数据情况:


本文是选择的比较经典的也是比较古老的YOLOv3来进行模型的开发,YOLOv3(You Only Look Once v3)是一种目标检测算法模型,它是YOLO系列算法的第三个版本。该算法通过将目标检测任务转化为单个神经网络的回归问题,实现了实时目标检测的能力。
YOLOv3的主要优点如下:
实时性能:YOLOv3采用了一种单阶段的检测方法,将目标检测任务转化为一个端到端的回归问题,因此具有较快的检测速度。相比于传统的两阶段方法(如Faster R-CNN),YOLOv3能够在保持较高准确率的情况下实现实时检测。
多尺度特征融合:YOLOv3引入了多尺度特征融合的机制,通过在不同层级的特征图上进行检测,能够有效地检测不同尺度的目标。这使得YOLOv3在处理尺度变化较大的场景时表现出较好的性能。
全局上下文信息:YOLOv3在网络结构中引入了全局上下文信息,通过使用较大感受野的卷积核,能够更好地理解整张图像的语义信息,提高了模型对目标的识别能力。
简洁的网络结构:YOLOv3的网络结构相对简洁,只有75个卷积层和5个池化层,使得模型较易于训练和部署,并且具有较小的模型体积。
YOLOv3也存在一些缺点:
较低的小目标检测能力:由于YOLOv3采用了较大的感受野和下采样操作,对于小目标的检测能力相对较弱。当场景中存在大量小目标时,YOLOv3可能会出现漏检或误检的情况。
较高的定位误差:由于YOLOv3将目标检测任务转化为回归问题,较粗糙的特征图和较大的感受野可能导致较高的定位误差。这意味着YOLOv3在需要较高精度的目标定位时可能会受到一定的限制。
YOLOv3是YOLO系列里程碑性质的模型,随着不断地演变和发展,目前虽然已经在性能上难以与YOLOv5之类的模型对比但是不可否认其做出的突出贡献。
训练数据配置文件如下:
# path
train: ./dataset/images/train/
val: ./dataset/images/test/# number of classes
nc: 4# class names
names: ['holothurian', 'echinus', 'scallop', 'starfish']
我们开发构建了yolov3全系列的参数模型,包含:yolov3-tiny、yolov3和yolov3-spp,实验阶段保持完全相同的参数设置,等待训练完成我们来整体对比可视化。
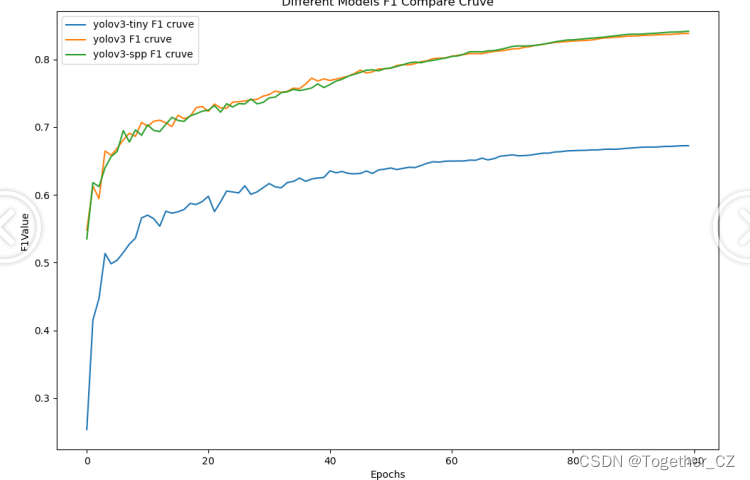
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能.F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
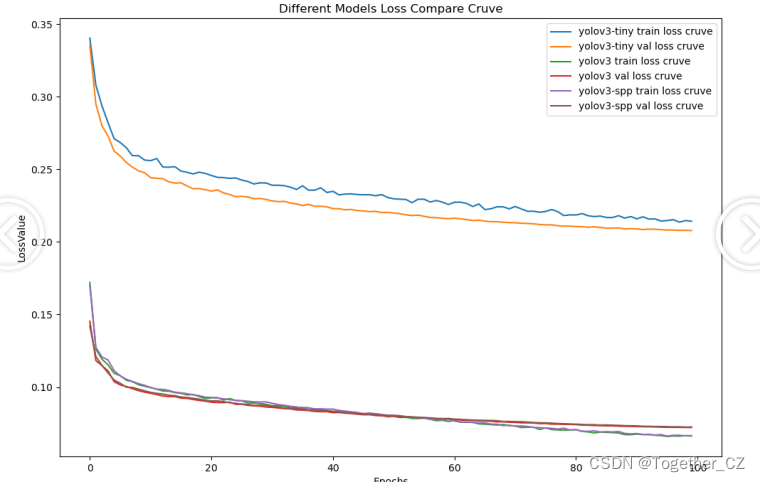
【loss曲线】
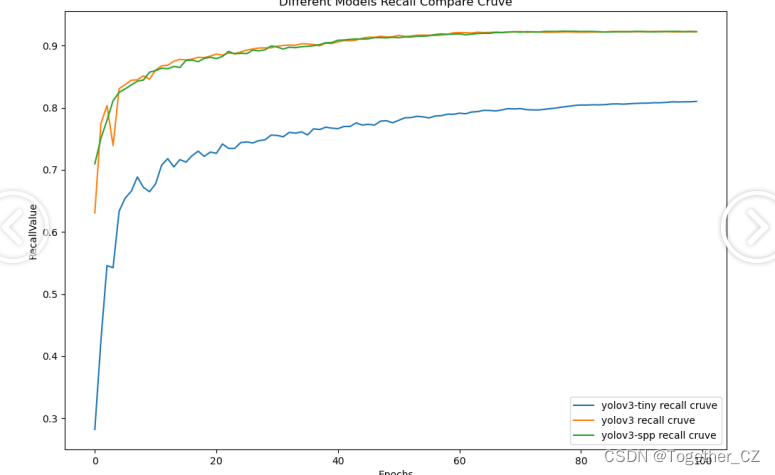
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。

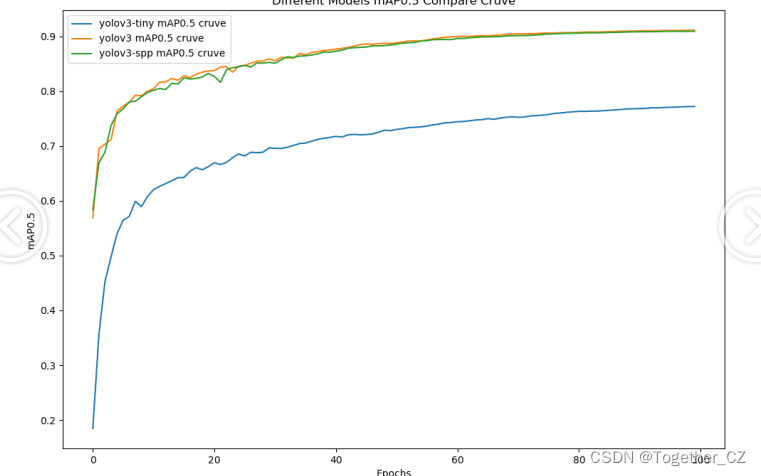
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
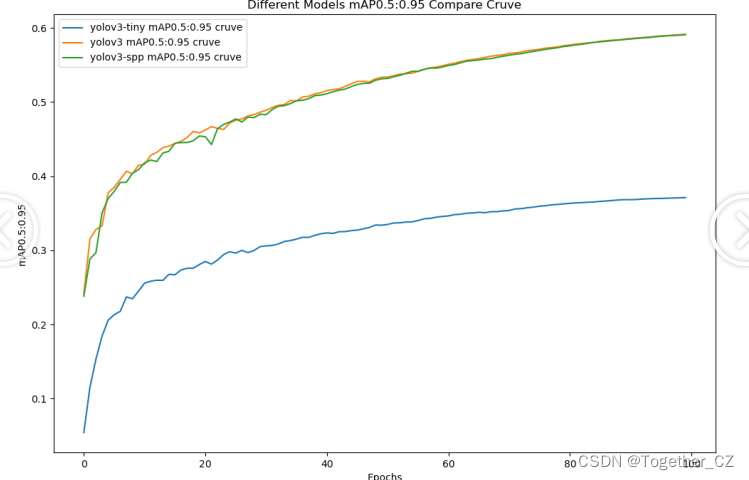
从实验结果综合对比来看不难看出:tiny系列的模型效果最差,被其他系列的模型拉开了明显的差距,yolov3和yolov3-spp两款模型达到了相近的性能,且参数量相近。我们考虑最终选择使用yolov3系列的模型来作为最终的推理模型。
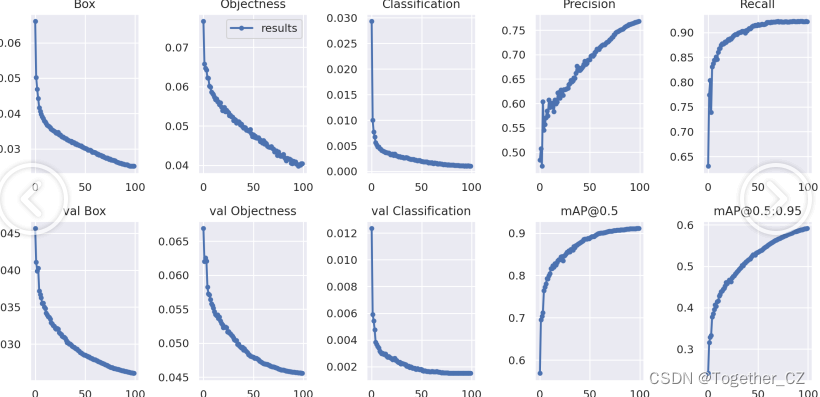
训练可视化如下所示:
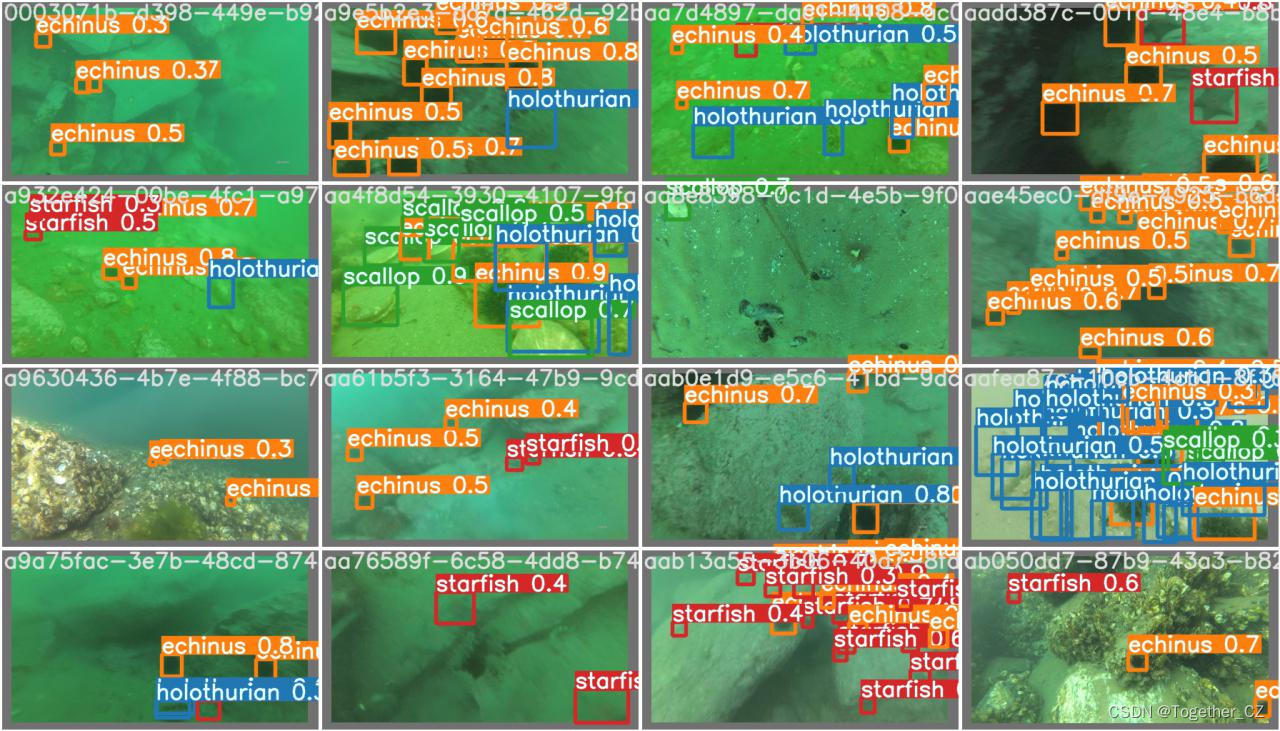
Batch实例如下:

感兴趣的话也都可以自行动手尝试下!
如果自己不具备开发训练的资源条件或者是没有时间自己去训练的话这里我提供出来对应的训练结果可供自行按需索取。
单个模型的训练结果默认YOLOv3-tiny
全系列三个模型的训练结果总集