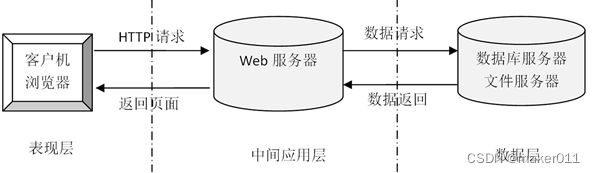
使用阿里云通义千问14B(Qianwen-14B)模型自建问答系统时,调度服务器资源的详情将取决于以下关键因素:
-
模型部署:
- GPU资源:由于Qianwen-14B是一个大规模语言模型,推理时需要高性能的GPU支持。模型参数量大,推理过程中对显存(GPU内存)的要求高,可能需要多块高端GPU,并且考虑是否支持模型并行或数据并行以充分利用硬件资源。
- 单卡显存需求:根据之前的信息,Qianwen-14B微调时至少需要39GB的显存,因此在选择GPU时,至少应配备能够提供类似或更高显存容量的设备,如NVIDIA A100、V100或者RTX 3090等。
-
CPU资源:
- CPU用于处理输入输出和模型运行之外的其他计算任务,要求较高性能,尤其是对于并发请求处理。
-
内存和存储:
- 内存:除了GPU显存外,还需要足够的系统内存来缓存数据、加载模型以及进行其他操作。
- 存储:存放模型权重文件和其他相关数据,需保证充足的硬盘空间。
-
网络带宽:
- 高带宽网络连接确保快速响应客户端请求和高效的数据传输。
-
并发处理能力:
- 根据预期的并发用户数量和每秒查询次数(QPS),可能需要多台服务器进行集群部署,并采用负载均衡器分配请求。
-
容器化与虚拟化技术:
- 可能需要利用Docker或Kubernetes等工具进行资源管理和服务编排。
-
高可用性与灾备:
- 考虑到系统的稳定性和容错性,可能需要部署冗余服务器,并设置自动故障转移机制。
-
资源调度与优化:
- 确保资源的合理分配和动态调整,可以根据实时负载情况灵活调度服务器资源。
在实际搭建过程中,请结合最新的官方文档和技术指南,根据你的业务需求、预算以及技术方案的具体情况进行资源规划。同时,务必关注模型版本更新和最新发布的最佳实践,因为随着时间推移,模型优化和部署策略可能会有所变化。