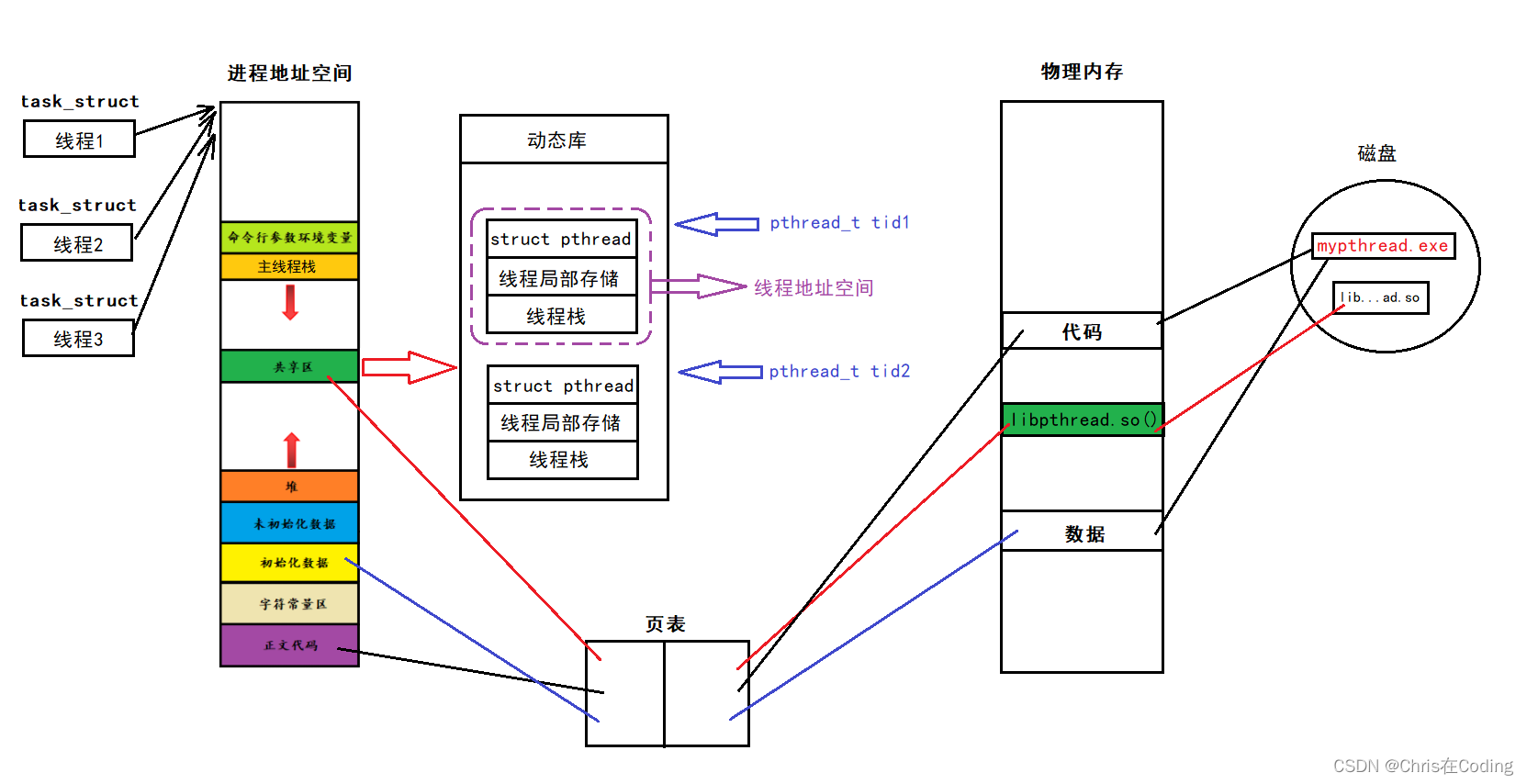
通过简单的回归实例,可以说明数据分割为训练集和测试集的必要性。以下先建立示例数据:
set.seed(123) #设置随机种子
x <- rnorm(100, 2, 1) # 生成100个正态分布的随机数,均值为2,标准差为1
y = exp(x) + rnorm(5, 0, 2)
# 生成一个新的变量y,它是x的指数函数值加上5个正态分布的随机数
# 均值为0,标准差为2
plot(x, y)
linear <- lm(y ~ x)
abline(a = coef(linear)[1], b = coef(linear)[2], lty = 2) 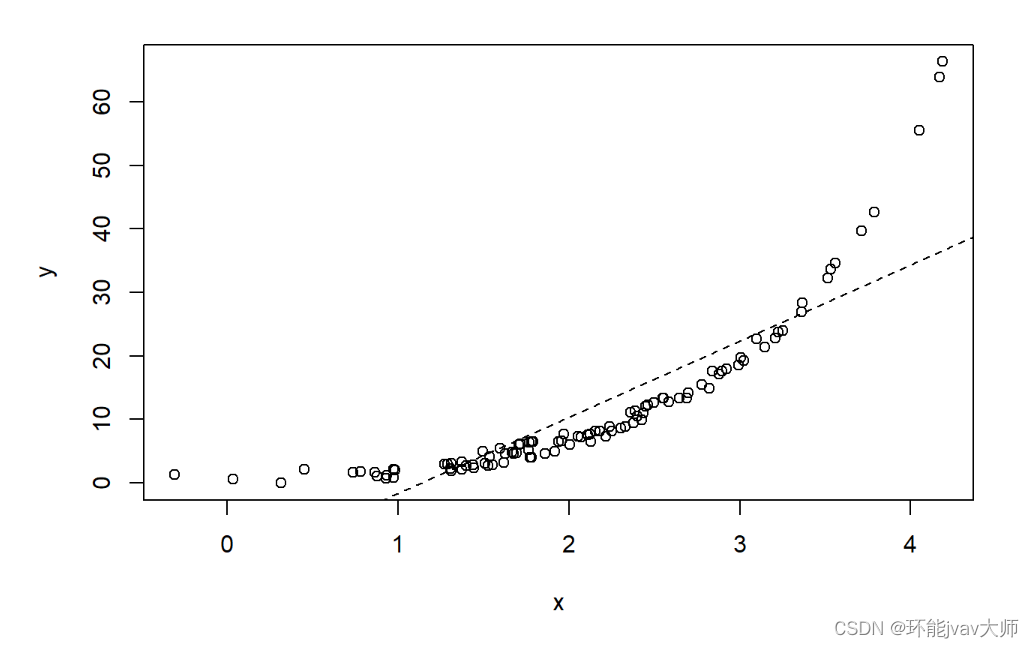
查看建立的数据信息:
summary(linear)
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.6481 -3.7122 -1.9390 0.9698 29.8283
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -13.6323 1.6335 -8.345 4.63e-13 ***
## x 11.9801 0.7167 16.715 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.51 on 98 degrees of freedom
## Multiple R-squared: 0.7403, Adjusted R-squared: 0.7377
## F-statistic: 279.4 on 1 and 98 DF, p-value: < 2.2e-16接受一些x和y的模拟数据,然后绘制一个最贴切的线性模型。根据以上的出结果,多重R方值为0.738,越接近1越好。再试一下通过标准三七开的随机采样分割数据:
data <- data.frame(x, y)
data.samples <- sample(1:nrow(data), nrow(data) * 0.7, replace = FALSE)
training.data <- data[data.samples, ]
test.data <- data[-data.samples, ]
train.linear <- lm(y ~ x, training.data)
train.output <- predict(train.linear, test.data)计算均方根误差 ,根据输入x,比较y与测试集中的实际值,在评估时使用特定的因变量。可采用均方根误差作为测试指标:

RMSE.df = data.frame(predicted = train.output, actual = test.data$y,SE = ((train.output - test.data$y)^2/length(train.output)))
head(RMSE.df)
## predicted actual SE
## 2 7.874300 6.383579 0.07407499
## 3 28.504227 34.624423 1.24855995
## 4 11.341893 7.233768 0.56255641
## 5 12.019753 6.505638 1.01351529
## 12 14.678243 11.102747 0.42613909
## 15 4.118657 2.335049 0.10604193sqrt(sum(RMSE.df$SE))
## [1] 6.946493train.quadratic <- lm(y ~ x^2 + x, training.data)
quadratic.output <- predict(train.quadratic, test.data)
RMSE.quad.df = data.frame(predicted = quadratic.output, actual = test.data$y, SE = ((quadratic.output - test.data$y)^2/length(train.output)))
head(RMSE.quad.df)
## predicted actual SE
## 2 7.874300 6.383579 0.07407499
## 3 28.504227 34.624423 1.24855995
## 4 11.341893 7.233768 0.56255641
## 5 12.019753 6.505638 1.01351529
## 12 14.678243 11.102747 0.42613909
## 15 4.118657 2.335049 0.10604193
sqrt(sum(RMSE.quad.df$SE))
## [1] 6.946493根据上述输出表明,将多项式从一次调整为二次有助于减少模型预测值与实际值之间的误差,接着再提高多项式的次数并查看对均方根误差的影响
train.polyn <- lm(y ~ poly(x, 4), training.data)
polyn.output <- predict(train.polyn, test.data)
RMSE.quad.df = data.frame(predicted = polyn.output, actual = test.data$y,SE = ((polyn.output - test.data$y)^2/length(train.output)))
head(RMSE.quad.df)
## predicted actual SE
## 2 5.228193 6.383579 0.0444972216
## 3 34.410640 34.624423 0.0015234381
## 4 7.312166 7.233768 0.0002048764
## 5 7.789798 6.505638 0.0549688692
## 12 9.946884 11.102747 0.0445339986
## 15 3.482548 2.335049 0.0438918352
sqrt(sum(RMSE.quad.df$SE))
## [1] 0.8836878与二次方程的拟合情况相比,可以看到均方根误差有所上升,符合用高次方程过度拟合数据的结果。

![[office] Excel2019函数MAXIFS怎么使用?Excel2019函数MAXIFS使用教程 #知识分享#微信#经验分享](https://img-blog.csdnimg.cn/img_convert/358b3daf7ce7e4ef6c937fed9fb7529b.jpeg)