文章目录
- 系列文章索引
- 一、快速上手
- 1、导包
- 2、求词频demo
- (1)要读取的数据
- (2)demo1:批处理(离线处理)
- (3)demo2 - lambda优化:批处理(离线处理)
- (4)demo3:流处理(实时处理)
- (5)总结:实时vs离线
- (6)demo4:批流一体
- (7)对接Socket
- 二、Flink部署
- 1、Flink架构
- 2、Standalone部署
- 3、自运行flink-web
- 4、通过参数传递
- 5、通过webui提交job
- 6、停止作业
- 7、常用命令
- 8、集群
- 参考资料
系列文章索引
Flink从入门到实践(一):Flink入门、Flink部署
Flink从入门到实践(二):Flink DataStream API
Flink从入门到实践(三):数据实时采集 - Flink MySQL CDC
一、快速上手
1、导包
<!-- fink 相关依赖 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.18.0</version>
</dependency>
2、求词频demo
注意!自Flink 1.18以来,所有Flink DataSet api都已弃用,并将在未来的Flink主版本中删除。您仍然可以在DataSet中构建应用程序,但是您应该转向DataStream和/或Table API。
(1)要读取的数据
定义data内容:
pk,pk,pk
ruoze,ruoze
hello
(2)demo1:批处理(离线处理)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** 使用Flink进行批处理,并统计wc*** 结果:* (bye,2)* (hello,3)* (hi,1)*/
public class BatchWordCountApp {public static void main(String[] args) throws Exception {// step0: Spark中有上下文,Flink中也有上下文,MR中也有ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// step1: 读取文件内容 ==> 一行一行的字符串而已DataSource<String> source = env.readTextFile("data/wc.data");// step2: 每一行的内容按照指定的分隔符进行拆分 1:Nsource.flatMap(new FlatMapFunction<String, String>() {/**** @param value 读取到的每一行数据* @param out 输出的集合*/@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {// 使用,进行分割String[] splits = value.split(",");for(String split : splits) {out.collect(split.toLowerCase().trim());}}}).map(new MapFunction<String, Tuple2<String,Integer>>() {/**** @param value 每一个元素 (hello, 1)(hello, 1)(hello, 1)*/@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}}).groupBy(0) // step4: 按照单词进行分组 groupBy是离线的api,传下标.sum(1) // ==> 求词频 sum,传下标.print(); // 打印}
}(3)demo2 - lambda优化:批处理(离线处理)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** lambda表达式优化*/
public class BatchWordCountAppV2 {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSource<String> source = env.readTextFile("data/wc.data");/*** lambda语法: (参数1,参数2,参数3...) -> {函数体}*/
// source.map(String::toUpperCase).print();// 使用了Java泛型,由于泛型擦除的原因,需要显示的声明类型信息source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).groupBy(0).sum(1).print();}
}
(4)demo3:流处理(实时处理)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** 流式处理* 结果:* 8> (hi,1)* 6> (hello,1)* 5> (bye,1)* 6> (hello,2)* 6> (hello,3)* 5> (bye,2)*/
public class StreamWCApp {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.readTextFile("data/wc.data");source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(x -> x.f0) // 这种写法一定要掌握!流式的并没有groupBy,而是keyBy!根据第一个值进行sum.sum(1).print();// 需要手动开启env.execute("作业名字");}
}(5)总结:实时vs离线
离线:结果是一次性出来的。
实时:来一个数据处理一次,数据是带状态的。
(6)demo4:批流一体
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** 采用批流一体的方式进行处理*/
public class FlinkWordCountApp {public static void main(String[] args) throws Exception {// 统一使用StreamExecutionEnvironment这个执行上下文环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); // 选择处理方式 批/流/自动DataStreamSource<String> source = env.readTextFile("data/wc.data");source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(x -> x.f0) // 这种写法一定要掌握.sum(1).print();// 执行env.execute("作业名字");}
}(7)对接Socket
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** 使用Flink对接Socket的数据并进行词频统计** 大数据处理的三段论: 输入 处理 输出**/
public class FlinkSocket {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/*** 数据源:可以通过多种不同的数据源接入数据:socket kafka text** 官网上描述的是 env.addSource(...)** socket的方式对应的并行度是1,因为它来自于SourceFunction的实现*/DataStreamSource<String> source = env.socketTextStream("localhost", 9527);System.out.println(source.getParallelism());// 处理source.flatMap((String value, Collector<Tuple2<String,Integer>> out) -> {String[] splits = value.split(",");for(String split : splits) {out.collect(Tuple2.of(split.trim(), 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(x -> x.f0) // 这种写法一定要掌握.sum(1)// 数据输出.print(); // 输出到外部系统中去env.execute("作业名字");}
}二、Flink部署
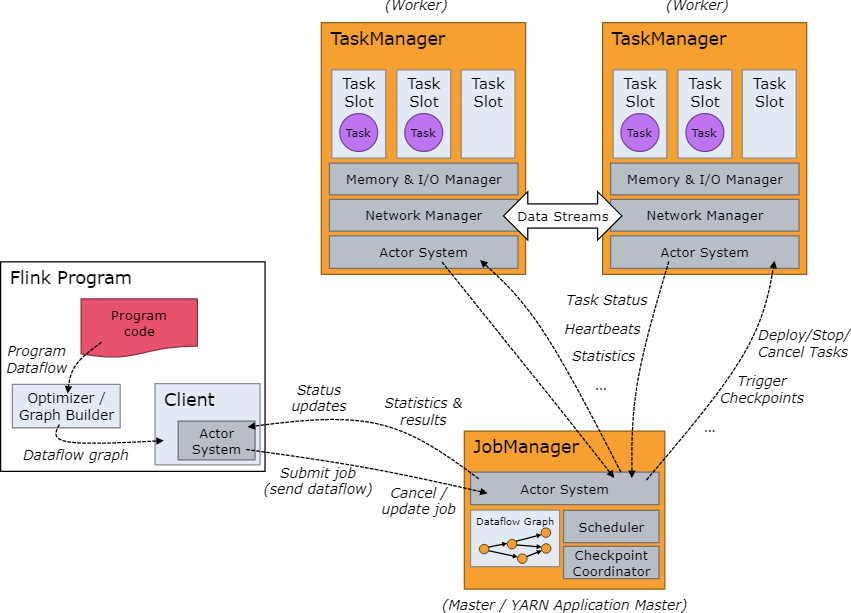
1、Flink架构
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/concepts/flink-architecture/
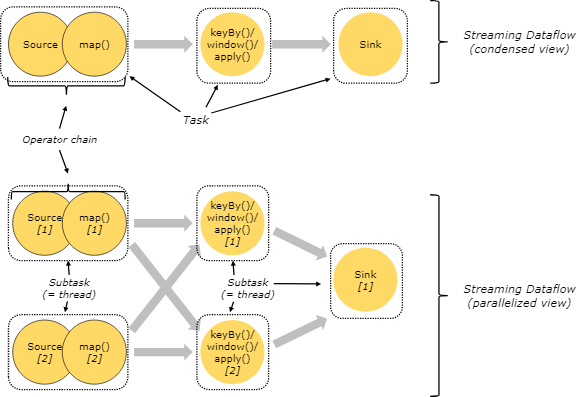
Flink是一个分布式的带有状态管理的计算框架,可以运行在常用/常见的集群资源管理器上(YARN、K8S)。
一个JobManager(协调/分配),一个或多个TaskManager(工作)。
2、Standalone部署
按照官网下载执行即可:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/try-flink/local_installation/
可以根据官网来安装,需要下载、解压、安装。
也可以使用docker安装。
启动之后,localhost:8081就可以访问管控台了。
3、自运行flink-web
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>1.18.0</version>
</dependency>
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8082); // 指定web端口,开启webUI,不写的话默认8081
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
// 新版本可以直接使用getExecutionEnvironment(conf)
以上亲测并不好使……具体原因未知,设置为flink1.16版本或许就好用了。
4、通过参数传递
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 通过参数传递进来Flink引用程序所需要的参数,flink自带的工具类
ParameterTool tool = ParameterTool.fromArgs(args);
String host = tool.get("host");
int port = tool.getInt("port");DataStreamSource<String> source = env.socketTextStream(host, port);
System.out.println(source.getParallelism());
可以通过命令行参数:–host localhost --port 8765
5、通过webui提交job
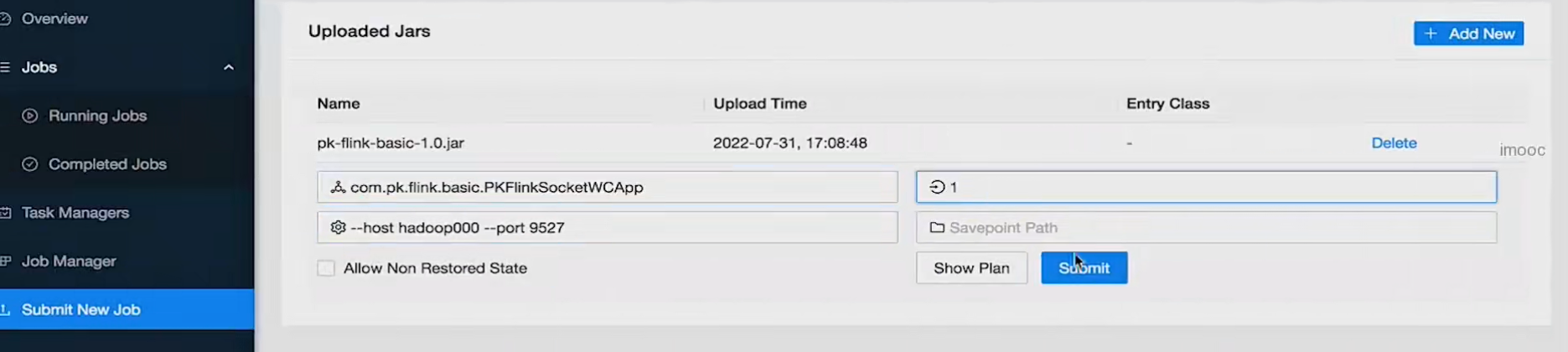
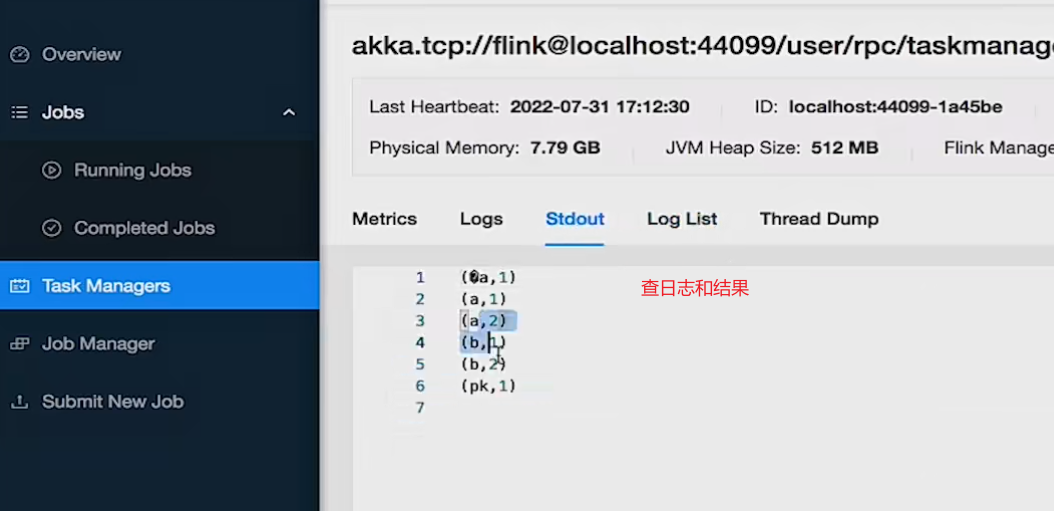
6、停止作业

7、常用命令
# 查看作业列表
flink list -a # 所有
flink list -r # 正在运行的
# 停止作业
flink cancel <jobid># 提交job
# -c,--class <classname> 指定main方法
# -C,--classpath <url> 指定classpath
# -p,--parallelism <paralle> 指定并行度
flink run -c com.demo.FlinkDemo FlinkTest.jar
8、集群
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/concepts/flink-architecture/#flink-application-execution
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/overview/
单机部署Session Mode和Application Mode:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/resource-providers/standalone/overview/
k8s:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/resource-providers/native_kubernetes/
YARN:
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/resource-providers/yarn/
参考资料
https://flink.apache.org/
https://nightlies.apache.org/flink/flink-docs-stable/