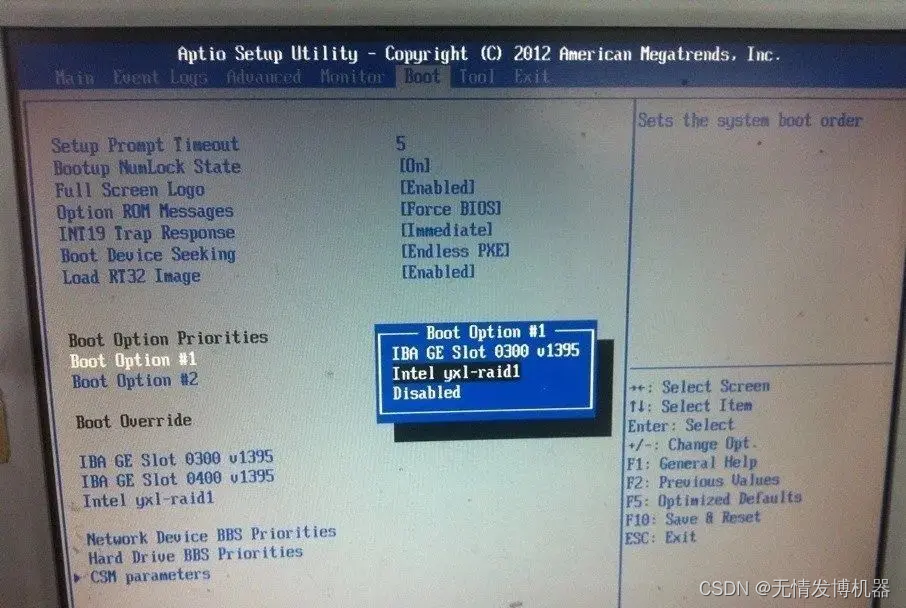
Ajax关于readyState(状态值)和status(状态码)的研究
var getXmlHttpRequest = function () {
try{
//主流浏览器提供了XMLHttpRequest对象
return new XMLHttpRequest();
}catch(e){
//低版本的IE浏览器没有提供XMLHttpRequest对象,IE6以下
//所以必须使用IE浏览器的特定实现ActiveXObject
return new ActiveXObject("Microsoft.XMLHTTP");
}
};
var xhr = getXmlHttpRequest();
// readyState 0=>初始化 1=>载入 2=>载入完成 3=>解析 4=>完成
// console.log(xhr.readyState); 0
xhr.open("TYPE", "URL", true);
// console.log(xhr.readyState); 1
xhr.send();
// console.log(xhr.readyState); 1
xhr.onreadystatechange = function () {
// console.log(xhr.status); //HTTP状态吗
// console.log(xhr.readyState); 2 3 4
if(xhr.readyState === 4 && xhr.status === 200){
alert(xhr.responseText);
}
};
1.Ajax:readyState(状态值)和status(状态码)的区别
readyState,是指运行AJAX所经历过的几种状态,无论访问是否成功都将响应的步骤,可以理解成为AJAX运行步骤,使用“ajax.readyState”获得
status,是指无论AJAX访问是否成功,由HTTP协议根据所提交的信息,服务器所返回的HTTP头信息代码,使用“ajax.status”获得
总体理解:可以简单的理解为state代表一个整体的状态。而status是这个大的state下面具体的小的状态。
2.什么是readyState
readyState是XMLHttpRequest对象的一个属性,用来标识当前XMLHttpRequest对象处于什么状态。
readyState总共有5个状态值,分别为0~4,每个值代表了不同的含义
| 1 2 3 4 5 | 0:初始化,XMLHttpRequest对象还没有完成初始化 1:载入,XMLHttpRequest对象开始发送请求 2:载入完成,XMLHttpRequest对象的请求发送完成 3:解析,XMLHttpRequest对象开始读取服务器的响应 4:完成,XMLHttpRequest对象读取服务器响应结束 |
3.什么是status
status是XMLHttpRequest对象的一个属性,表示响应的HTTP状态码
在HTTP1.1协议下,HTTP状态码总共可分为5大类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | 1xx:信息响应类,表示接收到请求并且继续处理 2xx:处理成功响应类,表示动作被成功接收、理解和接受 3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理 4xx:客户端错误,客户请求包含语法错误或者是不能正确执行 5xx:服务端错误,服务器不能正确执行一个正确的请求
100——客户必须继续发出请求 101——客户要求服务器根据请求转换HTTP协议版本 200——交易成功 201——提示知道新文件的URL 202——接受和处理、但处理未完成 203——返回信息不确定或不完整 204——请求收到,但返回信息为空 205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件 206——服务器已经完成了部分用户的GET请求 300——请求的资源可在多处得到 301——删除请求数据 302——在其他地址发现了请求数据 303——建议客户访问其他URL或访问方式 304——客户端已经执行了GET,但文件未变化 305——请求的资源必须从服务器指定的地址得到 306——前一版本HTTP中使用的代码,现行版本中不再使用 307——申明请求的资源临时性删除 400——错误请求,如语法错误 401——请求授权失败 402——保留有效ChargeTo头响应 403——请求不允许 404——没有发现文件、查询或URl 405——用户在Request-Line字段定义的方法不允许 406——根据用户发送的Accept拖,请求资源不可访问 407——类似401,用户必须首先在代理服务器上得到授权 408——客户端没有在用户指定的饿时间内完成请求 409——对当前资源状态,请求不能完成 410——服务器上不再有此资源且无进一步的参考地址 411——服务器拒绝用户定义的Content-Length属性请求 412——一个或多个请求头字段在当前请求中错误 413——请求的资源大于服务器允许的大小 414——请求的资源URL长于服务器允许的长度 415——请求资源不支持请求项目格式 416——请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段 417——服务器不满足请求Expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求 500——服务器产生内部错误 501——服务器不支持请求的函数 502——服务器暂时不可用,有时是为了防止发生系统过载 503——服务器过载或暂停维修 504——关口过载,服务器使用另一个关口或服务来响应用户,等待时间设定值较长 505——服务器不支持或拒绝支请求头中指定的HTTP版本 |
4.思考问题:为什么onreadystatechange的函数实现要同时判断readyState和status呢?
第一种思考方式:只使用readyState
var getXmlHttpRequest = function () {
if (window.XMLHttpRequest) {
return new XMLHttpRequest();
}
else if (window.ActiveXObject) {
return new ActiveXObject("Microsoft.XMLHTTP");
}
};
var xhr = getXmlHttpRequest();
xhr.open("get", "1.txt", true);
xhr.send();
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
alert(xhr.responseText);
}
};
服务响应出错了,但还是返回了信息,这并不是我们想要的结果
如果返回不是200,而是404或者500,由于只使用readystate做判断,它不理会放回的结果是200、404还是500,只要响应成功返回了,就执行接下来的javascript代码,结果将造成各种不可预料的错误。所以只使用readyState判断是行不通的。
第二种思考方式:只使用status判断
var getXmlHttpRequest = function () {
try{
return new XMLHttpRequest();
}catch(e){
return new ActiveXObject("Microsoft.XMLHTTP");
}
};
var xhr = getXmlHttpRequest();
xhr.open("get", "1.txt", true);
xhr.send();
xhr.onreadystatechange = function () {
if (xhr.status === 200) {
alert("readyState=" + xhr.readyState + xhr.responseText);
}
};
事实上,结果却不像预期那样。响应码确实是返回了200,但是总共弹出了3次窗口!第一次是“readyState=2”的窗口,第二次是“readyState=3”的窗口,第三次是“readyState=4”的窗口。由此,可见onreadystatechange函数的执行不是只在readyState变为4的时候触发的,而是readyState(2、3、4)的每次变化都会触发,所以就出现了前面说的那种情况。可见,单独使用status判断也是行不通的。
5.由上面的试验,我们可以知道判断的时候readyState和status缺一不可。那么readyState和status的先后判断顺序会不会有影响呢?我们可以将status调到前面先判断,代码如 xhr.status === 200 && xhr.readyState === 4
事实上,这对于最终的结果是没有影响的,但是中间的性能就不同了。由试验我们知道,readyState的每次变化都会触发onreadystatechange函数,假如先判断status,那么每次都会多判断一次status的状态。虽然性能上影响甚微,不过还是应该抱着追求极致代码的想法,把readyState的判断放在前面。
xhr.readyState === 4 && xhr.status === 200
CSS3的 transform属性,怎么才能让他同时执行多个不同动画(属性)效果
div{width: 100px; height: 100px; transition: all 1s; background: red;}
div:hover{transform: rotate(360deg) scale(2,2) skew(10deg,5deg);} 中间用空格隔开 旋转 缩放 扭曲 等同时执行多个效果!
定义和用法
transform 属性向元素应用 2D 或 3D 转换。该属性允许我们对元素进行旋转、缩放、移动或倾斜。
为了更好地理解 transform 属性,请查看这个演示。
| 默认值: | none |
| 继承性: | no |
| 版本: | CSS3 |
| JavaScript 语法: | object.style.transform="rotate(7deg)" |
语法
transform: none|transform-functions;
| 值 | 描述 | 测试 |
| none | 定义不进行转换。 | 测试 |
| matrix(n,n,n,n,n,n) | 定义 2D 转换,使用六个值的矩阵。 | 测试 |
| matrix3d(n,n,n,n,n,n,n,n,n,n,n,n,n,n,n,n) | 定义 3D 转换,使用 16 个值的 4x4 矩阵。 | |
| translate(x,y) | 定义 2D 转换。 | 测试 |
| translate3d(x,y,z) | 定义 3D 转换。 | |
| translateX(x) | 定义转换,只是用 X 轴的值。 | 测试 |
| translateY(y) | 定义转换,只是用 Y 轴的值。 | 测试 |
| translateZ(z) | 定义 3D 转换,只是用 Z 轴的值。 | |
| scale(x,y) | 定义 2D 缩放转换。 | 测试 |
| scale3d(x,y,z) | 定义 3D 缩放转换。 | |
| scaleX(x) | 通过设置 X 轴的值来定义缩放转换。 | 测试 |
| scaleY(y) | 通过设置 Y 轴的值来定义缩放转换。 | 测试 |
| scaleZ(z) | 通过设置 Z 轴的值来定义 3D 缩放转换。 | |
| rotate(angle) | 定义 2D 旋转,在参数中规定角度。 | 测试 |
| rotate3d(x,y,z,angle) | 定义 3D 旋转。 | |
| rotateX(angle) | 定义沿着 X 轴的 3D 旋转。 | 测试 |
| rotateY(angle) | 定义沿着 Y 轴的 3D 旋转。 | 测试 |
| rotateZ(angle) | 定义沿着 Z 轴的 3D 旋转。 | 测试 |
| skew(x-angle,y-angle) | 定义沿着 X 和 Y 轴的 2D 倾斜转换。 | 测试 |
| skewX(angle) | 定义沿着 X 轴的 2D 倾斜转换。 | 测试 |
| skewY(angle) | 定义沿着 Y 轴的 2D 倾斜转换。 | 测试 |
| perspective(n) | 为 3D 转换元素定义透视视图。 | 测试 |
CSS3 @keyframes 规则
如需在 CSS3 中创建动画,您需要学习 @keyframes 规则。
@keyframes 规则用于创建动画。在 @keyframes 中规定某项 CSS 样式,就能创建由当前样式逐渐改为新样式的动画效果。
浏览器支持
| 属性 | 浏览器支持 | ||||
| @keyframes | |||||
| animation | |||||
Internet Explorer 10、Firefox 以及 Opera 支持 @keyframes 规则和 animation 属性。
Chrome 和 Safari 需要前缀 -webkit-。
注释:Internet Explorer 9,以及更早的版本,不支持 @keyframe 规则或 animation 属性。
实例
@keyframes myfirst
{
from {background: red;}
to {background: yellow;}
}
@-moz-keyframes myfirst /* Firefox */
{
from {background: red;}
to {background: yellow;}
}
@-webkit-keyframes myfirst /* Safari 和 Chrome */
{
from {background: red;}
to {background: yellow;}
}
@-o-keyframes myfirst /* Opera */
{
from {background: red;}
to {background: yellow;}
}
CSS3 动画
当您在 @keyframes 中创建动画时,请把它捆绑到某个选择器,否则不会产生动画效果。
通过规定至少以下两项 CSS3 动画属性,即可将动画绑定到选择器:
- 规定动画的名称
- 规定动画的时长
实例
把 "myfirst" 动画捆绑到 div 元素,时长:5 秒:
div
{
animation: myfirst 5s;
-moz-animation: myfirst 5s; /* Firefox */
-webkit-animation: myfirst 5s; /* Safari 和 Chrome */
-o-animation: myfirst 5s; /* Opera */
}
亲自试一试
注释:您必须定义动画的名称和时长。如果忽略时长,则动画不会允许,因为默认值是 0。
什么是 CSS3 中的动画?
动画是使元素从一种样式逐渐变化为另一种样式的效果。
您可以改变任意多的样式任意多的次数。
请用百分比来规定变化发生的时间,或用关键词 "from" 和 "to",等同于 0% 和 100%。
0% 是动画的开始,100% 是动画的完成。
为了得到最佳的浏览器支持,您应该始终定义 0% 和 100% 选择器。
实例
当动画为 25% 及 50% 时改变背景色,然后当动画 100% 完成时再次改变:
@keyframes myfirst
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
@-moz-keyframes myfirst /* Firefox */
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
@-webkit-keyframes myfirst /* Safari 和 Chrome */
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
@-o-keyframes myfirst /* Opera */
{
0% {background: red;}
25% {background: yellow;}
50% {background: blue;}
100% {background: green;}
}
亲自试一试
实例
改变背景色和位置:
@keyframes myfirst
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
@-moz-keyframes myfirst /* Firefox */
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
@-webkit-keyframes myfirst /* Safari 和 Chrome */
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
@-o-keyframes myfirst /* Opera */
{
0% {background: red; left:0px; top:0px;}
25% {background: yellow; left:200px; top:0px;}
50% {background: blue; left:200px; top:200px;}
75% {background: green; left:0px; top:200px;}
100% {background: red; left:0px; top:0px;}
}
亲自试一试
CSS3 动画属性
下面的表格列出了 @keyframes 规则和所有动画属性:
| 属性 | 描述 | CSS |
| @keyframes | 规定动画。 | 3 |
| animation | 所有动画属性的简写属性,除了 animation-play-state 属性。 | 3 |
| animation-name | 规定 @keyframes 动画的名称。 | 3 |
| animation-duration | 规定动画完成一个周期所花费的秒或毫秒。默认是 0。 | 3 |
| animation-timing-function | 规定动画的速度曲线。默认是 "ease"。 | 3 |
| animation-delay | 规定动画何时开始。默认是 0。 | 3 |
| animation-iteration-count | 规定动画被播放的次数。默认是 1。 | 3 |
| animation-direction | 规定动画是否在下一周期逆向地播放。默认是 "normal"。 | 3 |
| animation-play-state | 规定动画是否正在运行或暂停。默认是 "running"。 | 3 |
| animation-fill-mode | 规定对象动画时间之外的状态。 | 3 |
下面的两个例子设置了所有动画属性:
实例
运行名为 myfirst 的动画,其中设置了所有动画属性:
div
{
animation-name: myfirst;
animation-duration: 5s;
animation-timing-function: linear;
animation-delay: 2s;
animation-iteration-count: infinite;
animation-direction: alternate;
animation-play-state: running;
/* Firefox: */
-moz-animation-name: myfirst;
-moz-animation-duration: 5s;
-moz-animation-timing-function: linear;
-moz-animation-delay: 2s;
-moz-animation-iteration-count: infinite;
-moz-animation-direction: alternate;
-moz-animation-play-state: running;
/* Safari 和 Chrome: */
-webkit-animation-name: myfirst;
-webkit-animation-duration: 5s;
-webkit-animation-timing-function: linear;
-webkit-animation-delay: 2s;
-webkit-animation-iteration-count: infinite;
-webkit-animation-direction: alternate;
-webkit-animation-play-state: running;
/* Opera: */
-o-animation-name: myfirst;
-o-animation-duration: 5s;
-o-animation-timing-function: linear;
-o-animation-delay: 2s;
-o-animation-iteration-count: infinite;
-o-animation-direction: alternate;
-o-animation-play-state: running;
}
亲自试一试
实例
与上面的动画相同,但是使用了简写的动画 animation 属性:
div
{
animation: myfirst 5s linear 2s infinite alternate;
/* Firefox: */
-moz-animation: myfirst 5s linear 2s infinite alternate;
/* Safari 和 Chrome: */
-webkit-animation: myfirst 5s linear 2s infinite alternate;
/* Opera: */
-o-animation: myfirst 5s linear 2s infinite alternate;
}
HTML5的canvas绘图和CSS3的绘图哪个更有优越性
如题,最好能从多个方面比较,能说下区别,二者的原理。
 iGO2dU
iGO2dU
2013-09-27
简单解释一下:
- CSS更像是把多个“矩形”(div)裁剪后,然后拼接成一个图案,然后给图案上色。
- Canvas由点开始,延长无数个点,得到线,延长线之后得到一个面(三角形,圆形,矩形等等的图案面),然后给线或者面描边,上色。
- CSS目前更像是小朋友的手工课,Canvas更像是用一支笔画图,不过画出来的图更加像能够控制大小的矢量图片。
下图简单说明

在面对曲线和更复杂图形的时候,Canvas比CSS更有办法。另外Canvas确定坐标位置的时候更加贴近我们常用到的数学思维方法。
只能显浅说说。
为什么canvas绘制的线条会模糊、有锯齿?
2017年05月30日 22:24:51
阅读数:5385
有如下的代码:
<style type="text/css">
canvas {
position:absolute;
height : 100%;
width : 100%;
}
</style>
<canvas id="canvas" width="100%" height="100%">
</canvas>
<script type="text/javascript">
var canvas = document.getElementById('canvas'),
context = canvas.getContext('2d')
context.translate(70, 70);
context.moveTo(0, 0)
context.lineTo(70, -70)
context.stroke();
</script>
结果实际的效果虚化非常严重,清晰度非常差,锯齿非常严重,如下所示:
为什么会出现这样的情况呢?原因是canvas的宽度与高度必须作为属性明确指定(也不能通过CSS设置),并且只能是数字,不支持百分比。基于以上的规则,所以很容易找到症结,canvas绘制的图片本来较小,但经过CSS强行放大拉伸,所以就会出现模糊、锯齿严重的效果。
解决的办法很简单,在绘制之前,首先设置canvas的宽度,代码如下:
varcanvas = document.getElementById('canvas'),
// 计算画布的宽度 width = canvas.offsetWidth, // 计算画布的高度 height = canvas.offsetHeight,context = canvas.getContext('2d')
// 设置宽高 canvas.width = width; canvas.height = height;再次刷新浏览器,终于一切正常了。
结论
HTML中很多元素的宽高必须通过属性设定,而不是CSS,比如canvas,比如SVG
html5 canvas 画图移动端出现锯齿毛边的解决方法
Posted on 2017-05-19 11:01 人生梦想起飞 阅读(2748) 评论(0) 编辑 收藏
使用HTML5的canvas元素画出来的.在移动端手机上测试都发现画图有一点锯齿问题
出现这个问题的原因应该是手机的宽是720像素的, 而这个canvas是按照小于720像素画出来的, 所以在720像素的手机上显示时, 这个canvas的内容其实是经过拉伸的, 所以会出现模糊和锯齿.
解决方案一:就是在canvas标签中设置了width="200",height="200"之外, 还在外部的CSS样式表中设置了该canvas的宽度为100%,然后在画图时把canvas的的宽度设为手机端的最大像素值, 因为现在的手机端宽度的最大的只有1080像素宽, 所以就把canvas的宽度和高度设为200的6倍也就是1200像素, 按照这个像素画完之后, width:100%又会把canvas的宽度和高度缩小至父元素的宽和宽那么大, 因此整个canvas被缩小了, 大尺寸的canvas内容被缩小了之后肯定不会产生锯齿现象,解决的原理其实就是画图时候将canvas的宽和高放大一定的倍数,按照放大后的canvas宽和高画图,然后画完之后再将canvas缩小为目标宽和高,这样解决的方法存在的问题是,在PC端反而锯齿会更明白,只是移动端的效果很好,所以在pc端不需要放大倍数,实例如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
解决方案二:使用window.devicePixelRatio设备上物理像素和设备独立像素(device-independent pixels (dips))的比例来设置canvas实际需要放大的倍数,原理与上一种方法一样,区别在于 devicePixelRatio取出的是实际的比例倍数,在pc端显示为1,避免了上种方法PC端不判断同样放大一样倍数画图出现明显锯齿问题,但是devicePixelRatio各个浏览器的兼容性不是很好,这是唯一缺陷,实现方法如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
备注:以上两种方法经初步测试只有在安卓红米Note下的UC浏览器中不支持,原因在于安卓红米Note下的UC浏览器中对于HTML5 canvas画布是最大限制很小,不能超过256px ,超过画布就显示花屏,不能显示绘制的图,属于安卓红米Note下的UC浏览器对于canvas的兼容性不支持超过这个宽度的画图
清除,H5中canvas画的图中的锯齿
2016年08月24日 22:22:06
阅读数:333
手动开启HTML5 Canvas的抗锯齿可以用
canvas.getContext('2d').imageSmoothingEnabled =true;
或者直接把整个画布偏移0.5像素:
canvas.getContext('2d').translate(0.5,0.5);
css3动画与js动画的区别
css与 js动画 优缺点比较
我们经常面临一个抉择:到底使用JavaScript还是CSS动画,下面做一下对比
JS动画
缺点:(1)JavaScript在浏览器的主线程中运行,而主线程中还有其它需要运行的JavaScript脚本、样式计算、布局、绘制任务等,对其干扰导致线程可能出现阻塞,从而造成丢帧的情况。
(2)代码的复杂度高于CSS动画
优点:(1)JavaScript动画控制能力很强, 可以在动画播放过程中对动画进行控制:开始、暂停、回放、终止、取消都是可以做到的。
(2)动画效果比css3动画丰富,有些动画效果,比如曲线运动,冲击闪烁,视差滚动效果,只有JavaScript动画才能完成
(3)CSS3有兼容性问题,而JS大多时候没有兼容性问题
CSS动画
缺点:
(1)运行过程控制较弱,无法附加事件绑定回调函数。CSS动画只能暂停,不能在动画中寻找一个特定的时间点,不能在半路反转动画,不能变换时间尺度,不能在特定的位置添加回调函数或是绑定回放事件,无进度报告
(2)代码冗长。想用 CSS 实现稍微复杂一点动画,最后CSS代码都会变得非常笨重。
优点: (1)浏览器可以对动画进行优化。
- 浏览器使用与 requestAnimationFrame 类似的机制,requestAnimationFrame比起setTimeout,setInterval设置动画的优势主要是:1)requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率,一般来说,这个频率为每秒60帧。2)在隐藏或不可见的元素中requestAnimationFrame不会进行重绘或回流,这当然就意味着更少的的cpu,gpu和内存使用量。
- 强制使用硬件加速 (通过 GPU 来提高动画性能)
CSS动画流畅的原因
渲染线程分为main thread(主线程)和compositor thread(合成器线程)。
如果CSS动画只是改变transform和opacity,这时整个CSS动画得以在compositor thread完成(而JS动画则会在main thread执行,然后触发compositor进行下一步操作)
在JS执行一些昂贵的任务时,main thread繁忙,CSS动画由于使用了compositor thread可以保持流畅,
在主线程中,维护了一棵Layer树(LayerTreeHost),管理了TiledLayer,在compositor thread,维护了同样一颗LayerTreeHostImpl,管理了LayerImpl,这两棵树的内容是拷贝关系。因此可以彼此不干扰,当Javascript在main thread操作LayerTreeHost的同时,compositor thread可以用LayerTreeHostImpl做渲染。当Javascript繁忙导致主线程卡住时,合成到屏幕的过程也是流畅的。
为了实现防假死,鼠标键盘消息会被首先分发到compositor thread,然后再到main thread。这样,当main thread繁忙时,compositor thread还是能够响应一部分消息,例如,鼠标滚动时,加入main thread繁忙,compositor thread也会处理滚动消息,滚动已经被提交的页面部分(未被提交的部分将被刷白)。
CSS动画比JS流畅的前提:
- JS在执行一些昂贵的任务
- 同时CSS动画不触发layout或paint
在CSS动画或JS动画触发了paint或layout时,需要main thread进行Layer树的重计算,这时CSS动画或JS动画都会阻塞后续操作。
只有如下属性的修改才符合“仅触发Composite,不触发layout或paint”:
- backface-visibility
- opacity
- perspective
- perspective-origin
- transfrom
所以只有用上了3D加速或修改opacity时,css3动画的优势才会体现出来。
(2)代码相对简单,性能调优方向固定
(3)对于帧速表现不好的低版本浏览器,CSS3可以做到自然降级,而JS则需要撰写额外代码
结论
如果动画只是简单的状态切换,不需要中间过程控制,在这种情况下,css动画是优选方案。它可以让你将动画逻辑放在样式文件里面,而不会让你的页面充斥 Javascript 库。然而如果你在设计很复杂的富客户端界面或者在开发一个有着复杂UI状态的 APP。那么你应该使用js动画,这样你的动画可以保持高效,并且你的工作流也更可控。所以,在实现一些小的交互动效的时候,就多考虑考虑CSS动画。对于一些复杂控制的动画,使用javascript比较可靠。
关于Cookie的原理、作用,区别以及使用
2016年10月15日 09:35:10
阅读数:44112
1、cookie的作用:
我们在浏览器中,经常涉及到数据的交换,比如你登录邮箱,登录一个页面。我们经常会在此时设置30天内记住我,或者自动登录选项。那么它们是怎么记录信息的呢,答案就是今天的主角cookie了,Cookie是由HTTP服务器设置的,保存在浏览器中,但HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。就像我们去超市买东西,没有积分卡的情况下,我们买完东西之后,超市没有我们的任何消费信息,但我们办了积分卡之后,超市就有了我们的消费信息。cookie就像是积分卡,可以保存积分,商品就是我们的信息,超市的系统就像服务器后台,http协议就是交易的过程。
2、机制的区别:
session机制采用的是在服务器端保持状态的方案,而cookie机制则是在客户端保持状态的方案,cookie又叫会话跟踪机制。打开一次浏览器到关闭浏览器算是一次会话。说到这里,讲下HTTP协议,前面提到,HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。此时,服务器无法从链接上跟踪会话。cookie可以跟踪会话,弥补HTTP无状态协议的不足。
3、cookie的分类:
cookie分为会话cookie和持久cookie,会话cookie是指在不设定它的生命周期expires时的状态,前面说了,浏览器的开启到关闭就是一次会话,当关闭浏览器时,会话cookie就会跟随浏览器而销毁。当关闭一个页面时,不影响会话cookie的销毁。会话cookie就像我们没有办理积分卡时,单一的买卖过程,离开之后,信息则销毁。
持久cookie则是设定了它的生命周期expires,此时,cookie像商品一样,有个保质期,关闭浏览器之后,它不会销毁,直到设定的过期时间。对于持久cookie,可以在同一个浏览器中传递数据,比如,你在打开一个淘宝页面登陆后,你在点开一个商品页面,依然是登录状态,即便你关闭了浏览器,再次开启浏览器,依然会是登录状态。这就是因为cookie自动将数据传送到服务器端,在反馈回来的结果。持久cookie就像是我们办理了一张积分卡,即便离开,信息一直保留,直到时间到期,信息销毁。
4、简单的使用cookie的代码
cookie的几种常见属性:document.cookie="key=value;expires=失效时间;path=路径;domain=域名;secure;(secure表安全级别),
cookie以字符串的形式保存在浏览器中。下面贴段代码出来,是一个类似购物网站的将商品添加到购物车,再从购物车还原商品信息的过程,是自己用原生JS封装的函数。
封装的cookie的存入,读取以及删除的函数:(这里是将信息以对象的形式存放到cookie中的,会用到JSON的知识)
- // key : cookie 名
- // value : cookie 值
- // options : 可选配置参数
- // options = {
- // expires : 7|new Date(), // 失效时间
- // path : "/", // 路径
- // domain : "", // 域名
- // secure : true // 安全连接
- // }
- function cookie(key, value, options) {
- /* read 读取 */
- // 如果没有传递 value ,则表示根据 key 读取 cookie 值
- if (typeof value === "undefined") { // 读取
- // 获取当前域下所有的 cookie,保存到 cookies 数组中
- var cookies = document.cookie.split("; ");
- // 遍历 cookies 数组中的每个元素
- for (var i = 0, len = cookies.length; i < len; i++) {
- // cookies[i] : 当前遍历到的元素,代表的是 "key=value" 意思的字符串,
- // 将字符串以 = 号分割返回的数组中第一个元素表示 key,
- // 第二个元素表示 value
- var cookie = cookies[i].split("=");
- // 判断是否是要查找的 key,对查找的 key 、value 都要做解码操作
- if (decodeURIComponent(cookie[0]) === key) {
- return decodeURIComponent(cookie[1]);
- }
- }
- // 没有查找到指定的 key 对应的 value 值,则返回 null
- return null;
- }
- /* 存入 设置 */
- // 设置 options 默认为空对象
- options = options || {};
- // key = value,对象 key,value 编码
- var cookie = encodeURIComponent(key) + "=" + encodeURIComponent(value);
- // 失效时间
- if ((typeof options.expires) !== "undefined") { // 有配置失效时间
- if (typeof options.expires === "number") { // 失效时间为数字
- var days = options.expires,
- t = options.expires = new Date();
- t.setDate(t.getDate() + days);
- }
- cookie += ";expires=" + options.expires.toUTCString();
- }
- // 路径
- if (typeof options.path !== "undefined")
- cookie += ";path=" + options.path;
- // 域名
- if (typeof options.domain !== "undefined")
- cookie += ";domain=" + options.domain;
- // 安全连接
- if (options.secure)
- cookie += ";secure";
- // 保存
- document.cookie = cookie;
- }
- // 从所有的 cookie 中删除指定的 cookie
- function removeCookie(key, options) {
- options = options || {};
- options.expires = -1; // 将失效时间设置为 1 天前
- cookie(key, "", options);
- }
下面是商品详情页的JS代码
- // 找到所有的 “添加到购物车” 超级链接
- var links = $("a", $("#tab"));
- // 循环,为每个 “添加到购物车” 的超级链接添加点击事件
- for (var i = 0, len = links.length; i < len; i++) {
- links[i].onclick = function(){
- // 获取当前超级链接所在行的所有单元格
- var _cells = this.parentNode.parentNode.cells;
- // 获取到即将添加到购物车中的商品信息
- var _id = _cells[0].innerHTML,
- _name = _cells[1].innerHTML,
- _price = _cells[2].innerHTML;
- // 将商品信息包装到一个对象中
- var product = {
- id : _id,
- name : _name,
- price : _price,
- amount : 1
- };
- /* 将当前选购的商品对象保存到 cookie 中去 */
- // 从 cookie 中读取已有的保存购物车的数组结构
- var _products = cookie("products");
- if (_products === null) // cookie 中不存在 products 名的 cookie
- _products = [];
- else // 存在,则解析 cookie 读取到的字符串为 数组 结构
- _products = JSON.parse(_products);
- // 将当前选购的商品追加到数组中保存
- _products.push(product);
- // 继续将 _products 数组内容存回 cookie
- cookie("products", JSON.stringify(_products), {expires:7});
- }
- }
html代码,css代码大家可以自己写
- <table id="tab">
- <tr>
- <td>序号</td>
- <td>名称</td>
- <td>价格</td>
- <td>操作</td>
- </tr>
- <tr>
- <td>1</td>
- <td>空调</td>
- <td>3999</td>
- <td><a href="javascript:void(0);">添加到购物车</a></td>
- </tr>
- <tr>
- <td>2</td>
- <td>风扇</td>
- <td>288</td>
- <td><a href="javascript:void(0);">添加到购物车</a></td>
- </tr>
- </table>
- <a href="cart_购物车.html" target="_blank">查看购物车</a>
购物车还原商品信息:
- // 从 cookie 中读取购物车已有的商品信息
- var _products = cookie("products");
- // 判断购物车是否有商品
- if (_products === null || (_products = JSON.parse(_products)).length === 0)
- return;
- // 如果有商品,则显示到页面中
- $(".result")[0].innerHTML = "";
- for (var i = 0, len = _products.length; i < len; i++) {
- // 当前遍历到的商品对象
- var prod = _products[i];
- // 克隆 .row 的节点
- var _row = $(".row")[0].cloneNode(true);
- // 将当前商品对象的信息替换节点中对应的部分,用class名获取到的节点返回类型是一个数组所以要在后面加上[0]
- $(".index", _row)[0].innerHTML = prod.id; // 编号
- $(".name", _row)[0].innerHTML = prod.name; // 名称
- $(".price", _row)[0].innerHTML = prod.price; // 价格
- $(".amount", _row)[0].innerHTML = prod.amount; // 数量
- $(".oper", _row)[0].innerHTML = "<a href='javascript:void(0);'>删除</a>"
- // 将克隆的节点副本追加到 .result 的 div 中
- $(".result")[0].appendChild(_row);
- };
- // 为每个 “删除” 的超级链接绑定点击事件
- var links = $("a", $("#container"));
- for (var i = 0, len = links.length; i < len; i++) {
- // links[i].index = i; // 为当前遍历到的超级链接附加数据
- links[i].product = _products[i]; //
- links[i].onclick = function(){
- // alert("你点击的是第" + (this.index + 1) + "个连接");
- var index = inArray(this.product, _products);
- if (index !== -1) {
- _products.splice(index, 1);
- }
- // 更新 cookie
- cookie("products", JSON.stringify(_products), {expires:7});
- // 找出页面中待删除的行
- var _row = this.parentNode.parentNode;
- _row.parentNode.removeChild(_row);
- };
- }
这里的$(' ')函数是自己封装的函数,用于获取到DOM节点,可以看下我关于getElementsByClassName的兼容那篇文章。
购物车的html代码
- <div id="container">
- <div class="row">
- <div class="index">商品编号</div>
- <div class="name">商品名称</div>
- <div class="price">价格</div>
- <div class="amount">数量</div>
- <div class="oper">操作</div>
- </div>
- <div class="result" style="clear:both;">
- 购物车为空
- </div>
- </div>
浏览器的历史记录是存储在cookie,session,还是物理文件当中或者其他方式存储? 50
在网络上,临时cookie为用户浏览器关闭时消失的含有用户有关信息的小文件,有时也称通话cookie。跟永久cookie不一样,临时cookie不保存在硬盘驱动器而是存在临时存储器中,当浏览器关闭时,将被删除。
当应用程序创建cookie时,在设置Cookie选择项中不设置日期就可以创建临时cookie。(对于永久cookie,设置了截止日期,cookie保存在用户硬盘驱动器,直到截止日期或者用户的删除)。
临时cookie常常用于允许返回用户已经访问过的网站,从而可在一定程度用户化信息。有些网站使用加密套接字协议层(SSL)来加密cookie携带的信息。
两者区别:
1、cookie数据存放在客户的浏览器上,
session数据放在服务器上
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE
4、单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能大于3K。
COOKIE安全与防护
2017年05月28日 21:08:18
阅读数:3015
目 录
摘要
关键词
一、 引言
二、 COOKIE概述
三、 COOKIE安全分析
四、 COOKIE惯性思维
五、 COOKIE防护
六、 总结
七、 参考文献: 15
摘要:Cookie是一小段文本信息,只能保存字符串,伴随着用户请求和页面在Web服务器和浏览器间传递,用来保持Web中的回话状态和缓存信息,记录用户的状态。Cookie的使用方便了人们的网上生活,但同时对用户的许多隐私信息构成了威胁。本文介绍了Cookie技术的相关概念、应用领域及基本特征,说明了Cookie的工作原理和Cookie结构;其次讲述了常见的Cookie技术的漏洞,最后介绍了针对Cookie技术的安全防护措。
关键词:Cookie,HTTP无状态,保持secure,httponly,跨站攻击
一、引言
Cookie技术产生于HTTP协议在互联网的急速发展。由于因特网的发展,人们对于web服务的便利性和友好性有了更大的需求。在复杂的互联网交互活动中,希望服务器能够记录活动的状态,识别不同用户的活动记录。使得用户在本次访问服务器中,服务器能有上次用户访问时的种种记录和资源。
但是,HTTP协议是无状态的,即协议对于事物处理没有记忆能力。这种情况下,如果后续事物处理需要之前的信息,就必须要重传。举个例子,你再淘宝里面精挑细选了50件产品放在了购物车中,但是不小心关闭了淘宝界面。这时再登录时,我们肯定希望购物车中还是有这50件产品。
http协议是不能记住我们上次把50件产品加入购物车的。在客户端和服务器进行这种动态交互的web 应用的大量出现后,http的无状态特性就极大的阻碍了这些交互应用的发展。因此,在这种需求下就推出了各种能够保存web服务器状态的技术手段,两种用于保持HTTP连接状态的技术就应运产生了。一种是session技术,另一种就是cookie技术。
Cookie在英文中意为“小饼干,小甜品”,顾名思义就是形容cookie容量小,cookie是一小段文本文件,只含有字符。
Cookie就是服务器给用户颁布的一个状态值,并且保存在客户端或浏览器。只要在cookie的有效期内,用户再次访问该服务器时,浏览器会检查本地的cookies,并且会自动将cookie加在请求头部中一起发送给服务器,服务器通过识别该cookie来辨别用户身份,并且将用户在服务器中的资源提供给用户。
过度泛化的“隐私问 题”,正在影响互联网发展的大方向。 央视3·15晚会出人意料地没有谈食物、水和空气,而选择曝光公众缺乏意识的cookie问题,这一下子让还处在马斯洛需求层面较低层级的中国人民在对自身安全的追求上开始更加忧虑。Cookie 安全就不止为安全领域的人员所熟知,而成为一个热门的全民话题。
二、COOKIE概述
1. Cookie属性
1)Cookie名称,Cookie名称必须使用只能用在URL中的字符,一般用字母及数字,不能包含特殊字符,如有特殊字符想要转码。如js操作cookie的时候可以使用escape()对名称转码。
2)Cookie值,Cookie值同理Cookie的名称,可以进行转码和加密。
3)Expires,过期日期,一个GMT格式的时间,当过了这个日期之后,浏览器就会将这个Cookie删除掉,当不设置这个的时候,Cookie在浏览器关闭后消失。
4)Path,一个路径,在这个路径下面的页面才可以访问该Cookie,一般设为“/”,以表示同一个站点的所有页面都可以访问这个Cookie。
5)Domain,子域,指定在该子域下才可以访问Cookie,例如要让Cookie在a.test.com下可以访问,但在b.test.com下不能访问,则可将domain设置成a.test.com。
6)Secure,安全性,指定Cookie是否只能通过https协议访问,一般的Cookie使用HTTP协议既可访问,如果设置了Secure(没有值),则只有当使用https协议连接时cookie才可以被页面访问。
7)HttpOnly,如果在Cookie中设置了"HttpOnly"属性,那么通过程序(JS脚本、Applet等)将无法读取到Cookie信息。
2. Cookie工作工程
具体工作过程描述如下:
1)We b 客户端通过浏览器向 We b 服务器发送连接请求, 通过 HTTP 报文请求行中的 URL 打开某一 Web页面。
2)We b 服务器接收到请求后,根据用户端提供的信息产生一个 Set-Cookies Head
3)将生成的Set-Cookies Header通过 Response Header存放在 HTTP 报文中回传给 Web 客户端,建立一次会话连接。
4)We b 客户端收到 H T T P 应答报文后,如果要继续已建立的这次会话,则将 Cookies 的内容从 HTTP 报文中取出,形成一个 Cookies文本文件储存在客户端计算机的硬盘中或保存 在客户端计算机的内存中。
5)当 We b 客户端再次向 We b 服务器发送连接请求时, We b 浏览器首先根据要访问站点的 U R L 在本地计算机上寻找对应的 Cookies文本文件或在本地计算机的内存中寻找对应的 Cookies 内容。如果找到,则将此 Cookies 内容存放在 HTTP 请求报文中发给 Web 服务器。
6)Web 服务器接收到包含 Co okies 内容的 HT TP 请求后, 检索其 Cookies 中与用户有关的信息,并根据检索结果生成一个客户端所请求的页面应答传递给客户端 。
3. Cookie 特点
① 由服务器写入,保存在本地,传输于HTTP头部
② Cookie由三元组【名字name,域名domain,路径path】确定,会出现重名,即cookie不唯一
③ Cookie 存在同源策略,仅以domain和path 作为同源限制,不区分端口和协议。Cookie 的同源策略类似于Web的同源策略(sop),但比其安全性高。Web的同源策略以协议,端口,域名作为同源限制。Web 同源策略的目的是为了保护用户信息的安全,防止恶意的网站窃取数据。Cookie的同源策略目的也是为了安全性。
l Domain向上通配:一个页面可以为本域和任何父域设置cookie。
Eg: 服务器写入cookie时,当页面为 http://www.bank.com ,cookie为X时:
Ø Set-Cookie: user1=aaa; domain=.bank.com; path=/; -------> domain不配陪
Ø Set-Cookie: user2=bbb; domain=www.bank.com; path=/; -------> domain匹配
Ø Set-Cookie: user3=ccc; domain=.www.bank.com; path=/; ------->domian匹配
Ø Set-Cookie: user4=ddd; domain=other.bank.com;path=/; ------->domain不匹配
l Path向下通配:一个页面可以为本路径和任何子路径设置cookie。
Eg: 服务器写入cookie时,当页面为 http://www.bank.com ,path为/hello时:
Ø Set-Cookie: user1=aaa; domain=www.bank.com; path=/; -------> path不配陪
Ø Set-Cookie: user1=aaa; domain=www.bank.com; path=/hello; -------> path配陪
Ø Set-Cookie: user2=bbb; domain=www.bank.com; path=/hello/world; -------> path匹配
4. Cookie版本
主流有两个版本 :
版本 0 : 由 Netscape 公司制定的,也被几乎所有的浏览器 支持。Java中为了保持兼容性 , 目前只支持到版本 0, Cookie的内容中不能空格,方括号,圆括号,等于号(=),逗号,双引号, 斜杠,问号,@ 符号,冒号,分号。
版本 1 : 根据 R F C 2109 文档制定的。放宽了很多限制。 版本 0 中所限制的字符都可以使用。但为了保持兼容性,程序 开发者都会尽量避免使用这些特殊字符。
三、COOKIE安全分析
1. Cookie 泄漏(欺骗)
如下图,cookie在http协议中是明文传输的,并且直接附在http报文的前面,所以只要在网络中加个嗅探工具,获取http包,就可以分析并获得cookie的值。
此时,当我们获取到别人的cookie的值,就产生了一种攻击漏洞,即cookie欺骗。我们将获取到的cookie值加在http请求前,服务器就会把我们当作是该cookie的用户,我们就成功的冒充了其他用户,可以使用其他用户在服务器的资源等。
既然明文cookie不安全,那么我们就使用加密传输cookie。这样即使数据包被截取,cookie也不会被泄漏。把http协议改成加密的https,如下图:
但是攻击者依旧可以通过社会工程学等等诱使用户主动访问在http协议下的服务器,从而获取明文cookie,因此加密后的cookie依旧不安全。如下图:用户先是通过HTTPS访问了bank.com服务器。而后,攻击者在网站weibo.com中插入js代码,该代码中img指向访问http下的non.bank.com服务器。攻击者通过社会工程学诱使用户去访问这条链接,当用户一点击该链接,就自动访问non.bank.com,让服务器给用户一个cookie。因为cookie同源策略中domain是向上匹配的。所以服务器会将该用户在bank.com的cookie 也分配给non.bank.com。这时就得到了bank.com给用户的cookie就被泄漏了。
在HTTPS也不安全的情况下,我们考虑cookie 自身属性。
Cookie 中有个属性secure,当该属性设置为true时,表示创建的 Cookie 会被以安全的形式向服务器传输,也就是只能在 HTTPS 连接中被浏览器传递到服务器端进行会话验证,如果是 HTTP 连接则不会传递该cookie信息,所以不会被窃取到Cookie 的具体内容。就是只允许在加密的情况下将cookie加在数据包请求头部,防止cookie被带出来。
另一个是 HttpOnly属性,如果在Cookie中设置了"HttpOnly"属性,那么通过程序(JS脚本、Applet等)将无法读取到Cookie信息,这样能有效的防止XSS攻击。
secure属性是防止信息在传递的过程中被监听捕获后信息泄漏,HttpOnly属性的目的是防止程序获取cookie后进行攻击。
但是这两个属性并不能解决cookie在本机出现的信息泄漏的问题(FireFox的插件FireBug能直接看到cookie的相关信息)。
2. Cookie 注入\覆盖
Cookie 欺骗是攻击者登录的是受害者的身份。而Cookie 注入是认证为攻击者的攻击方式,受害者登录的是攻击者的身份。
Cookie注入简单来说就是利用Cookie而发起的注入攻击。从本质上来讲,Cookie注入与一般的注入(例如,传统的SQL注入)并无不同,两者都是针对数据库的注入,只是表现形式上略有不同。Cookie 注入就是将提交的参数以cookie的方式提交。而一般的注入是使用get和post方式提交。Get方式提交就是直接在网址之后加需注入的内容,而post 是经过表单提取的方式。Post和get不同就在于,get方式我们可以在ie地址栏看到我们提交的参数,而post 不能。
在 ASP 脚本中 Request 对象是用户与网站数据交互之中非常关键的点,Request 对象 获取客户端提交数据常用的 GET 和 POST 两种方式,同时可以不通过集合来获取数据,即直接用“request(“name”)”等。
相对post和get方式注入来说,cookie注入就要稍微繁琐,要进行cookie注入,我们首先就要修改cookie,这里就需要使用到Javascript语言。另外cookie注入的形成有两个必须条件: 条件1是程序对get和post方式提交的数据进行了过滤,但未对cookie方式提交的数据库进行过滤;条件2是在条件1的基础上还需要程序对提交数据获取方式是直接request("xxx")的方式,未指明使用request对象的具体方法进行获取。
Cookie 注入 从技术手段来讲,比较有技术含量。如果只是简单的注入,例如,让受害者登录攻击者的邮箱,那么只要攻击者查看邮箱的信件就会发现异常,容易被发现。那么这种情况下,就需要进行精准的攻击。例如攻击”一个网页“中的一个组成界面,替换“一次http行为”中的某些阶段行为。精确攻击将在下文cookie惯性思维中细讲,这里不多做描述。精确攻击就很难被发现,极为隐蔽。
如下图,用户先是用HTTPS的方式访问bank.com,而后,我们让用户使用HTTP的方式来访问non.bank.com,这时我们能得到一个cookie ,攻击者此时就可以将该明文cookie 替换成攻击者attack的cookie。在domain 向上匹配的同源策略下和cookie 优先级的情况下,访问non.bank.com时得到的cookie 会更优先,这时用户通过https访问bank.com时,就会使用attack优先级更高的cookie。
四、COOKIE惯性思维
1.盲目认为cooke可信,没有做复杂验证
cookie来自服务器还是第三方?我们通常认为cookie服务器颁发的,所以很可能认为cookie是安全的。但是cookie是从客户端向服务器提交的,所以严格来说,服务器接收到的cookie很可能是来自第三方的。攻击者窃取了他人的cookie然后提交给主机的。我们如果能够进行复杂的验证,例如过滤等,就会有效降低cookie的威胁。但是这个验证,本身存在一定的技术困难。
2.cookie 是唯一的?
事实是cookie不唯一,因此cookie会存在重名的情况。同名的cookie处理有歧义,因为RFC标准中对于cookie同名的处理就是不严格的,所以存在cookie同名上的安全隐患。
浏览器的cookie优先级排序:
Ø path更长;
Ø path相同,更早创建(删除对方的cookie)
由于存在重名cookie的优先级,那么攻击者就可能利用cookie的同源策略来制造同名cookie,并且利用浏览器对于重名cookie的优先级的定义,从而使重名cookie中,攻击者所有的哪个cookie优先级更高。
3.一个“HTTP页面”? NO!!!
我们经常认为一个网页界面是一个http页面,但其实,那是由很多个界面叠加组成的。这些不同的界面可能由于path 不同而拥有不同的cookie。此时,就可能形成了一种精准攻击,针对于某个界面进行cookie注入,而其他界面仍然是正常界面。那么这种情景下,用户是很难发现异常的。如下图:
4.一次“HTTP”操作“? NO!!!
如下图,举个例子,我们在网上进行支付行为,我们外表看来的一次支付行为可能分为很多个HTTP操作,其中的跳转可能就不止一个。而每个不同的跳转和页面都会有不同的cookie。因此,这也会造成精准攻击。攻击者用自己的cookie 替换掉中间两个跳转,攻击者就可以从受害者卡里划走一笔钱到自己的账户中。同样,这种精准攻击也是极其难发现的。因为可能上面的登录名还是受害者的,但是钱却不知不觉的转到攻击者账户区。
5.精确清理cookie?
实际上,我们并不经常清理cookie,或者说,cookie难以清理。由于cookie 的便利性和我们对于本地cookie的不熟悉性,我们并不能精准的清理cookie,这就会导致泄漏的cookie可能一支被利用,从而形成持久化攻击。
五、COOKIE防护
1.”重名检查“
但是这个有难度。因为cookie 时RFC定义的,而修改RFC中的cookie 标准是有困难的。
2.清理cookie
Cookie是由于便利性而存在的,那么总是在使用后清除cookie,其实就达不到cookie的便利作用了。
3.不在 Cookies 中存放敏感信息。
这是一个 理想化的思路,其实质就是抛弃 Cookies,但明显违背安全平台的设计思路,不能因为 Cookies 可能存在欺骗攻击而废止它的便利性。
4. 严格保护数据库不泄露。
保护数据库不泄露不仅仅是 Cookies 防御技术中需要注意的安全措施,也是其它安全措施中必须注意的重点。在数据库足够安全的情况下,即使产生cookie注入,cookie 注入的危害也会被极大的减小。这时从cookie 造成损失的后果上来减小cookie的危害。可以对数据库进行加密等等。
5. 严格堵住脚本系统中可能提交盗取 Cookies 的代码,把好验证关。
为了实现正常的用户交互功能,一般的脚 本系统都有发帖、留言、讨论、评论等功能,这些功能都允许用户提交或者上传一些自己的代码、程序,这样的代码有可能就是盗取 Cookies 的代码,因此,出于安全考虑,管理员要对这些代码进行严格审查,或者使用过滤插件、过滤软件过滤掉用户提交的一些非法信息来减小恶意代码的运行。
6. 使用 Session 和 Cookies 双重验证。
一般给予cookie 的系统会在cookie 中存储两个或多个变量,常见的是 username ( 用户名) 和 userlevel ( 用户等级) ,对于安全程序员来说, 既然cookie 是不安全的,而又必须把用户登录信息 存储下来以方便交互,就应该增加存储在 session。
cookie保存在客户端,容易被篡改,session保存在服务器端,用户难以修改,当用户与网站的交互结束时,Session 的生命周期随即结束,从这个层面上说,session类似一次一密,因此Session 的安全性比 Cookies 要高。所以两者结合适用,比较安全。
该方法技术实现为:在 cookie 中存储用户名和密码,当用户访问一个页面是先读取 session,如果有内容则以 session 为准,否则读取 cookie,按照 cookie 中提供的用户名和密码进行 “不透明”的登录一次,用以判断 cookie 中的内容是否合法,若合法再进而存入 session 中。
7.加防篡改验证码,加个登录随机验证码
在用户登录时,多增加一层验证,需要验证两个 cookie,一个验证的是用户名,一个验证的是随机数,而这个随机数是系统自动产生的,某时间段内相对为唯一的 “验证码”。
这种方法的技术实现方式为:修改用户登录页面代码,当用户名和密码通过系统正确验证之后,从数据库中取出对应这个用户名的 randnum,并写入 cookie,也就是说此时类似于产生了两个 cookie。
这样以来,就算是攻击者通过不法手段伪造了管理员的用户名,但这个随机产生的验证码就很难猜到了,而且这个随机数是不停变化的,就能在一定程度上增加了cookie攻击的难度。
8.运用HSTS平台,对于特定的域名强制进行HTTPS访问。
六、总结
Cookie 在web中是广泛使用的,它给我们的上网带来了极大的便利性,例如,当我们浏览过一次优酷,那么这条记录就会被保存在浏览器中。当然,有利也有弊,我们的上网安全也因之收到威胁。Cookie 可以也能被利用来进行XSS,CSRF等跨站攻击,它本身不是病毒也不是木马,对于主机本身不会产生威胁,但是容易被利用来进行攻击。对于cookie 安全,本文给出了一些安全分析,也给出了对应的防护策略。但我仍然认为,最佳的防御应该是优化网站本身,设置复杂而周全的规则策略使攻击者不能获取到有效信息,从而来堵住cookie漏洞,同时也经常给站点打补丁,进行分析。在大局势下,安全总是相对的,不安全却是绝对的。我们所能采取的措施就是 时刻保持警惕,不断了解最新的技术和安全报告, 一旦发现问题就迅速解决,尽可能地不给居心不良 者以可乘之机。
cookie安全加密
cookie一般情况下用于记录用户登录状态的,比如userid,千万不要记录密码,由于cookie是存储在客户端的,所以cookie很容易被人劫持修改。比如登录成功后在客户端写入cookie('userid') = 1,在服务器读取cookie userid的值,如果userid在数据库用户表中可以找到则证明当前用户userid为1且合法登录,显然这样是不可行的。如果用户自行修改userid为2或者其它用户的userid,那么服务器就认为当前合法登录的用户userid为2,这样用户就不需要知道userid为2的密码就合法登录了,修改cookie可以通过直接修改浏览器cookie文件或者通过javascript修改cookie值达到欺骗服务器的目的,所以需要对存储在客户端的cookie要进行加密。
提到加密可能大家首先想到MD5,通过MD5算法对userid进行加密然后存储在客户端cookie中,由于MD5是不逆的,所以服务器在收到cookie(‘userid’)的时候也不可以解密,那么服务器应该在用户数据表中添加一个字段专门存储MD5加密后的userid,然后通过SQL查询到userid。虽然MD5是不可逆的,但是MD5还是可以暴力破解的,尤其是对于userid这种纯数字的,比如userid为12345,MD5加密后的值为827CCB0EEA8A706C4C34A16891F84E7B,我们把加密后的值放到http://www.cmd5.com/中解密看看,不到2秒结果12345就出来了。如果用户知道了你的userid只是经过了一次MD5加密,那么用户随便对一个已经存在的userid进行MD5加密,然后伪造cookie(‘userid’),此时服务器会认为用户为合法用户了,获取了其它用户的权限。那么我的建议是对userid进行两次MD5加密或者加一个复杂的key,因为越复杂MD5暴力破解就越慢,如果暴力破解需要2万年那就没有任何意义了。
上面提到的使用已知加密算法(如MD5)还是有漏洞的,最好的是自己编写一套加密算法,这样用户就无法伪造其它用户了。当然了不是每个人都有编写加密算法的能力,我们还是可以用DES加密算的,DES加密需要密钥,而且还可以解密,当用户登录成功后使用预先设置好的密钥对userid进行DES加密,然后存储到客户端cookie中。服务器读取cookie(‘userid’)时在服务器端使用相同的密钥进行DES解密,然后取得userid,由于用户不知道密钥(密钥存储在服务器上),所以用户也无法伪造成其它用户了。我的项目用的是Thinkphp框架,采用的Thinkphp自带的加密算法。此外为了防止用户通过javascript修改伪造cookie,可以设置cookie的httponly属性为true,这样cookie就只能通过服务器读取不能通过javascript读取了,也防止了恶意用户通过XSS跨站脚本攻击获取其它用户的cookie信息,一定程度上提示了安全性。
别以为这样就万事大吉了,既然不能伪造cookie了,但还是可以通过抓包获取其它用户的cookie的,毕竟cookie是在网络中传输的,那怎么办呢?可以用https协议代替普通http协议,这样恶意用户抓到的报文已经是密文了,也就不知道cookie了。
简单易用的cookie加密方法
在保存用户信息阶段,主要的工作是对用户的信息进行加密并保存到客户端。加密用户的信息是较为繁琐的,大致上可分为以下几个步聚:
① 得到用户名、经MD5加密后的用户密码、cookie有效时间(本文设置的是两星期,可根据自己需要修改)
② 自定义的一个webKey,这个Key是我们为自己的网站定义的一个字符串常量,这个可根据自己需要随意设置
③ 将上两步得到的四个值得新连接成一个新的字符串,再进行MD5加密,这样就得到了一个MD5明文字符串
④ 将用户名、cookie有效时间、MD5明文字符串使用“:”间隔连接起来,再对这个连接后的新字符串进行Base64编码
⑤ 设置一个cookieName,将cookieName和上一步产生的Base64编码写入到客户端。
其实弄明白了保存原理,读取及校验原理就很容易做了。读取和检验可以分为下面几个步骤:
① 根据设置的cookieName,得到cookieValue,如果值为空,就不帮用户进行自动登陆;否则执行读取方法
② 将cookieValue进行Base64解码,将取得的字符串以split(“:”)进行拆分,得到一个String数组cookieValues(此操作与保存阶段的第4步正好相反),这一步将得到三个值:
cookieValues[0] ---- 用户名
cookieValues[1] ---- cookie有效时间
cookieValues[2] ---- MD5明文字符串
③ 判断cookieValues的长度是否为3,如果不为3则进行错误处理。
④ 如果长度等于3,取出第二个,即cookieValues[1],此时将会得到有效时间(long型),将有效时间与服务器系统当前时间比较,如果小于当前时间,则说明cookie过期,进行错误处理。
⑤ 如果cookie没有过期,就取cookieValues[0],这样就可以得到用户名了,然后去数据库按用户名查找用户。
⑥ 如果上一步返回为空,进行错误处理。如果不为空,那么将会得到一个已经封装好用户信息的User实例对象user
⑦ 取出实例对象user的用户名、密码、cookie有效时间(即cookieValues[1])、webKey,然后将四个值连接起来,然后进行MD5加密,这样做也会得到一个MD5明文字符串(此操作与保存阶段的第3步类似)
⑧ 将上一步得到MD5明文与cookieValues[2]进行equals比较,如果是false,进行错误处理;如果是true,则将user对象添加到session中,帮助用户完成自动登陆
[csharp] view plain copy
- using System;
- using System.Web;
- namespace Mvc4WebBootstrap1.Models
- {
- public class CookieController
- {
- private static String mystatickey = "Dazdingo";
- public static void CookieSetter(String username, int valuetime)
- {
- valuetime = 30;//暂时指定有效期为30天
- String todaystr = DateTime.Now.ToString("yyyyMMdd");
- String md5str = username + valuetime + todaystr + mystatickey;
- md5str = System.Web.Security.FormsAuthentication.HashPasswordForStoringInConfigFile(md5str, "MD5");
- String cookiestr = username + ":" + valuetime + ":" + todaystr + ":" + md5str;
- HttpCookie cookie = new HttpCookie(cookiestr);
- cookie.Name = "myweb.com";
- System.Web.HttpContext.Current.Response.Cookies.Add(cookie);
- }
- public static int CookieReader(String username)//0=no cookie 1=success 2=somewrong
- {
- username = "";
- if (System.Web.HttpContext.Current.Request.Cookies["MyCook"] == null) return 0;
- String cookiestr = System.Web.HttpContext.Current.Request.Cookies["myweb.com"].Value;
- String[] sarr = cookiestr.Split(new char[]{':'});
- username = sarr[0];
- String todaystr = DateTime.Now.ToString("yyyyMMdd");
- int cookiedate = int.Parse(sarr[2]);
- int todaydate = int.Parse(todaystr);
- int valuetime = int.Parse(sarr[1]);
- if ((todaydate - cookiedate) < valuetime) return 2;
- String md5str = sarr[0] + sarr[1] + sarr[2] + mystatickey;
- md5str = System.Web.Security.FormsAuthentication.HashPasswordForStoringInConfigFile(md5str, "MD5");
- if (md5str == sarr[3]) return 1;
- return 2;
- }
- }
- }
JavaScript Cookies
- JS Timing
- JS 库
cookie 用来识别用户。
实例
创建一个欢迎 cookie
利用用户在提示框中输入的数据创建一个 JavaScript Cookie,当该用户再次访问该页面时,根据 cookie 中的信息发出欢迎信息。
什么是cookie?
cookie 是存储于访问者的计算机中的变量。每当同一台计算机通过浏览器请求某个页面时,就会发送这个 cookie。你可以使用 JavaScript 来创建和取回 cookie 的值。
有关cookie的例子:
名字 cookie
当访问者首次访问页面时,他或她也许会填写他/她们的名字。名字会存储于 cookie 中。当访问者再次访问网站时,他们会收到类似 "Welcome John Doe!" 的欢迎词。而名字则是从 cookie 中取回的。
密码 cookie
当访问者首次访问页面时,他或她也许会填写他/她们的密码。密码也可被存储于 cookie 中。当他们再次访问网站时,密码就会从 cookie 中取回。
日期 cookie
当访问者首次访问你的网站时,当前的日期可存储于 cookie 中。当他们再次访问网站时,他们会收到类似这样的一条消息:"Your last visit was on Tuesday August 11, 2005!"。日期也是从 cookie 中取回的。
创建和存储 cookie
在这个例子中我们要创建一个存储访问者名字的 cookie。当访问者首次访问网站时,他们会被要求填写姓名。名字会存储于 cookie 中。当访问者再次访问网站时,他们就会收到欢迎词。
首先,我们会创建一个可在 cookie 变量中存储访问者姓名的函数:
function setCookie(c_name,value,expiredays)
{
var exdate=new Date()
exdate.setDate(exdate.getDate()+expiredays)
document.cookie=c_name+ "=" +escape(value)+
((expiredays==null) ? "" : ";expires="+exdate.toGMTString())
}
上面这个函数中的参数存有 cookie 的名称、值以及过期天数。
在上面的函数中,我们首先将天数转换为有效的日期,然后,我们将 cookie 名称、值及其过期日期存入 document.cookie 对象。
之后,我们要创建另一个函数来检查是否已设置 cookie:
function getCookie(c_name)
{
if (document.cookie.length>0)
{
c_start=document.cookie.indexOf(c_name + "=")
if (c_start!=-1)
{
c_start=c_start + c_name.length+1
c_end=document.cookie.indexOf(";",c_start)
if (c_end==-1) c_end=document.cookie.length
return unescape(document.cookie.substring(c_start,c_end))
}
}
return ""
}
上面的函数首先会检查 document.cookie 对象中是否存有 cookie。假如 document.cookie 对象存有某些 cookie,那么会继续检查我们指定的 cookie 是否已储存。如果找到了我们要的 cookie,就返回值,否则返回空字符串。
最后,我们要创建一个函数,这个函数的作用是:如果 cookie 已设置,则显示欢迎词,否则显示提示框来要求用户输入名字。
function checkCookie()
{
username=getCookie('username')
if (username!=null && username!="")
{alert('Welcome again '+username+'!')}
else
{
username=prompt('Please enter your name:',"")
if (username!=null && username!="")
{
setCookie('username',username,365)
}
}
}
这是所有的代码:
<html>
<head>
<script type="text/javascript">
function getCookie(c_name)
{
if (document.cookie.length>0)
{
c_start=document.cookie.indexOf(c_name + "=")
if (c_start!=-1)
{
c_start=c_start + c_name.length+1
c_end=document.cookie.indexOf(";",c_start)
if (c_end==-1) c_end=document.cookie.length
return unescape(document.cookie.substring(c_start,c_end))
}
}
return ""
}
function setCookie(c_name,value,expiredays)
{
var exdate=new Date()
exdate.setDate(exdate.getDate()+expiredays)
document.cookie=c_name+ "=" +escape(value)+
((expiredays==null) ? "" : ";expires="+exdate.toGMTString())
}
function checkCookie()
{
username=getCookie('username')
if (username!=null && username!="")
{alert('Welcome again '+username+'!')}
else
{
username=prompt('Please enter your name:',"")
if (username!=null && username!="")
{
setCookie('username',username,365)
}
}
}
</script>
</head>
<body onLoad="checkCookie()">
</body>
</html>
cookie的存储和获取
在做用户登录时经常会用到cookie,如何将用户名和密码保存至cookie中呢?如何获取cookie中的数据呢?
一、用jquery.cookie.js保存数据
在页面内引入jQuery.cookie.js,如果在页面上有 记住密码 这个单选框,判断checked是否为true。
-----如果是,获取用户名和密码框的值,$.cookie(id,对应id存储的值,{expires:存储的期限})
1 if($("#rememberme").prop("checked") == true) {
2 var userName = $("#user").val();
3 var passWord = $("#psw").val();
4 $.cookie("rememberme", "true", {expires: 7}); // 存储一个带7天期限的 cookie
5 $.cookie("user", userName, {expires: 7});
6 $.cookie("psw", passWord, {expires: 7});
7 }
-----如果没有勾选 记住密码,设置存储期限为-1即可
这样提交之后cookie中就会存储这些数据啦!
你可以打开控制台 选中Application-->Storage-->Cookie进行查看
二、获取cookie中的数据
方法 :$.cookie(name)
例:$.cookie('rememberme'),$.cookie('user'),$.cookie('psw')
如果cookie设置的期限还没过,我们就需要将cookie中的数据显示到页面上,先判断cookie中的rememberme是否为true,如果为true,将cookie中的值赋给对应的文本框,勾选记住密码单选框。
1 if($.cookie('rememberme')==='true'){
2 $("#user").val($.cookie('user'));
3 $("#psw").val($.cookie('psw'));
4 $("#rememberme").prop('checked',true);
5 }
前端性能优化之CSS详细解读
避免使用@import
外部的CSS文件中使用@import会使得页面在加载时增加额外的延迟。
一个CSS文件first.css包含了以下内容:@import url(“second.css”)。浏览器先把first.css下载、解析和执行后,发现及处理第二个文件second.css。简单的 解决方法是使用<link>标记来替代@import,并行下载CSS文件,从而加快页面加载速度.
避免AlphaImageLoader滤镜
什么是AlphaImageLoader?IE独有属性,用于修正7.0以下版本中显示PNG图片的半透明效果。
问题:浏览器加载图片时它会终止内容的呈现并且冻结浏览器,在每一个元素(不仅仅是图片)它都会运算一次,增加了内存开支。
解决方案:1、PNG8格式来代替,这种格式能在IE中很好地工作。
2、确实需要使用AlphaImageLoader,使用下划线_filter,使IE7以上版本的用户无效。
避免CSS表达式
例:background-color: expression((new Date()).getHours()%2?"#FFFFFF": "#000000" );
CSS表达式是动态设置CSS属性的强大(但危险)方法。Internet Explorer从第5个版本开始支持CSS表达式。
问题:在页面显示和缩放、滚动、移动鼠标时都会要 重新计算一次。给CSS表达式增加一个计数器可以跟踪表达式的计算频率。在页面中随便移动鼠标都可以轻松达到10000次以上的计算量。
解决:减少CSS表 达式计算次数的方法就是使用一次性的表达式,它在第一次运行时将结果赋给指定的样式属性,并用这个属性来代替CSS表达式。如果样式属性必须在页面周期内 动态地改变,使用事件句柄来代替CSS表达式是一个可行办法。如果必须使用CSS表达式,一定要记住它们要计算成千上万次并且可能会对你页面的性能产生影 响。
避免通配选择器
在学习CSS初期,我们在做网页的时候经常会使用*{margin:0;padding:0;},以此来消除标签的默认布局和不同浏览器对于同一个标签的渲染。
而我们有时候会看到reset的写法。body,p,h1,h2,h3,h4,h5,input,select,textarea,table{margin:0;padding:0;}
这些人为什么要这么写,下面的内容我们会得到答案
例:#header > a {font-weight:blod;}
CSS选择器是从右到左进行规则匹配。所以在浏览器中这条语句实现为:
浏览器遍历页面中所有的a元素——>其父元素的id是否为header。
例:#header a {font-weight:blod;}
这个例子比上一个消耗的时间更多
遍历页面中所有a元素——>向其上级遍历直到根节点
例:.selected * {color: red;}
匹配文档中所有的元素——>分别向上逐级匹配class为selected的元素,直到文档的根节点
所以我们应该避免使用通配选择器。
移除无匹配的样式
第一,删除无用的样式后可以缩减样式文件的体积,加快资源下载速度;
第二,对于浏览器而言,所有的样式规则的都会被解析后索引起来,即使是当前页面无匹配的规则。移除无匹配的规则,减少索引项,加快浏览器查找速度;
避免单规则的属性选择器
浏览器匹配所有的元素——>检查是否有href属性并且herf属性值等于”#index”——>分别向上逐级匹配class为selected的元素,直到文档的根节点。
避免类正则的属性选择器
正则表达式匹配会比基于类别的匹配会慢很多。大部分情况下我们应尽量避免使用 *=, |=, ^=, $=, 和 ~=语法的属性选择器
Web前段优化,提高加载速度 css
前言:
在同样的网络环境下,两个同样能满足你的需求的网站,一个“Duang”的一下就加载出来了,一个纠结了半天才出来,你会选择哪个?研究表明:用户最满意的打开网页时间是2-5秒,如果等待超过10秒,99%的用户会关闭这个网页。也许这样讲,各位还不会有太多感触,接下来我列举一组数据:Google网站访问速度每慢400ms就导致用户搜索请 求下降0.59%;Amazon每增加100ms网站延迟将导致收入下降1%;雅虎如果有400ms延迟会导致流量下降5-9%。网站的加载速度严重影响了用户体验,也决定了这个网站的生死存亡。
可能有人会说:网站的性能是后端工程师的事情,与前端并无多大关系。我只能说,too young too simple。事实上,只有10%~20%的最终用户响应时间是用在从Web服务器获取HTML文档并传送到浏览器的,那剩余的时间去哪儿了?来瞄一下性能黄金法则:
只有10%~20%的最终用户响应时间花在了下载HTML文档上。其余的80%~90%时间花在了下载页面中的所有组件上。
接下来我们将研究一下前端攻城狮如何来提高页面的加载速度。
一、减少HTTP请求
上面说到80%~90%时间花在了下载页面中的所有组件进行的HTTP请求上。因此,改善响应时间最简单的途径就是减少HTTP请求的数量。
图片地图:
假设导航栏上有五幅图片,点击每张图片都会进入一个链接,这样五张导航的图片在加载时会产生5个HTTP请求。然而,使用一个图片地图可以提高效率,这样就只需要一个HTTP请求。
![]()
服务器端图片地图:将所有点击提交到同一个url,同时提交用户点击的x、y坐标,服务器端根据坐标映射响应
客户端图片地图:直接将点击映射到操作
<img src="planets.jpg" border="0" usemap="#planetmap" alt="Planets" />
<map name="planetmap" id="planetmap">
<area shape="rect" coords="180,139,14" href ="venus.html" alt="Venus" />
<area shape="rect" coords="129,161,10" href ="mercur.html" alt="Mercury" />
<area shape="rect" coords="0,0,110,260" href ="sun.html" alt="Sun" />
<area shape="rect" coords="140,0,110,260" href ="star.html" alt="Sun" />
</map>
使用图片地图的缺点:指定坐标区域时,矩形或圆形比较容易指定,而其它形状手工指定比较难
CSS Sprites
CSS Sprites直译过来就是CSS精灵,但是这种翻译显然是不够的,其实就是通过将多个图片融合到一副图里面,然后通过CSS的一些技术布局到网页上。特别是图片特别多的网站,如果能用css sprites降低图片数量,带来的将是速度的提升。

<div>
<span id="image1" class="nav"></span>
<span id="image2" class="nav"></span>
<span id="image3" class="nav"></span>
<span id="image4" class="nav"></span>
<span id="image5" class="nav"></span>
</div>
.nav {
width: 50px;
height: 50px;
display: inline-block;
border: 1px solid #000;
background-image: url('E:/1.png');
}
#image1 {
background-position: 0 0;
}
#image2 {
background-position: -95px 0;
}
#image3 {
background-position: -185px 0;
}
#image4 {
background-position: -275px 0;
}
#image5 {
background-position: -366px -3px;
}
运行结果:

PS:使用CSS Sprites还有可能降低下载量,可能大家会认为合并后的图片会比分离图片的总和要大,因为还有可能会附加空白区域。实际上,合并后的图片会比分离的图片总和要小,因为它降低了图片自身的开销,譬如颜色表、格式信息等。
字体图标
在可以大量使用字体图标的地方我们可以尽可能使用字体图标,字体图标可以减少很多图片的使用,从而减少http请求,字体图标还可以通过CSS来设置颜色、大小等样式,何乐而不为。
合并脚本 和样式表
将多个样式表或者脚本文件合并到一个文件中,可以减少HTTP请求的数量从而缩短效应时间。
然而合并所有文件对许多人尤其是编写模块化代码的人来说是不能忍的,而且合并所有的样式文件或者脚本文件可能会导致在一个页面加载时加载了多于自己所需要的样式或者脚本,对于只访问该网站一个(或几个)页面的人来说反而增加了下载量,所以大家应该自己权衡利弊。
二、使用CDN
如果应用程序web服务器离用户更近,那么一个HTTP请求的响应时间将缩短。另一方面,如果组件web服务器离用户更近,则多个HTTP请求的响应时间将缩短。
CDN(内容发布网络)是一组分布在多个不同地理位置的Web服务器,用于更加有效地向用户发布内容。在优化性能时,向特定用户发布内容的服务器的选择基于对网络慕课拥堵的测量。例如,CDN可能选择网络阶跃数最小的服务器,或者具有最短响应时间的服务器。
CDN还可以进行数据备份、扩展存储能力,进行缓存,同时有助于缓和Web流量峰值压力。
CDN的缺点:
1、响应时间可能会受到其他网站流量的影响。CDN服务提供商在其所有客户之间共享Web服务器组。
2、如果CDN服务质量下降了,那么你的工作质量也将下降
3、无法直接控制组件服务器
三、添加Expires头
页面的初次访问者会进行很多HTTP请求,但是通过使用一个长久的Expires头,可以使这些组件被缓存,下次访问的时候,就可以减少不必要的HTPP请求,从而提高加载速度。
Web服务器通过Expires头告诉客户端可以使用一个组件的当前副本,直到指定的时间为止。例如:
Expires: Fri, 18 Mar 2016 07:41:53 GMT
Expires缺点: 它要求服务器和客户端时钟严格同步;过期日期需要经常检查
HTTP1.1中引入Cache-Control来克服Expires头的限制,使用max-age指定组件被缓存多久。
Cache-Control: max-age=12345600
若同时制定Cache-Control和Expires,则max-age将覆盖Expires头
四、压缩组件
从HTTP1.1开始,Web客户端可以通过HTTP请求中的Accept-Encoding头来表示对压缩的支持
Accept-Encoding: gzip,deflate
如果Web服务器看到请求中有这个头,就会使用客户端列出来的方法中的一种来进行压缩。Web服务器通过响应中的Content-Encoding来通知 Web客户端。
Content-Encoding: gzip
代理缓存
当浏览器通过代理来发送请求时,情况会不一样。假设针对某个URL发送到代理的第一个请求来自于一个不支持gzip的浏览器。这是代理的第一个请求,缓存为空。代理将请求转发给服务器。此时响应是未压缩的,代理缓存同时发送给浏览器。现在,假设到达代理的请求是同一个url,来自于一个支持gzip的浏览器。代理会使用缓存中未压缩的内容进行响应,从而失去了压缩的机会。相反,如果第一个浏览器支持gzip,第二个不支持,你们代理缓存中的压缩版本将会提供给后续的浏览器,而不管它们是否支持gzip。
解决办法:在web服务器的响应中添加vary头Web服务器可以告诉代理根据一个或多个请求头来改变缓存的响应。因为压缩的决定是基于Accept-Encoding请求头的,因此需要在vary响应头中包含Accept-Encoding。
vary: Accept-Encoding
五、将样式表放在头部
首先说明一下,将样式表放在头部对于实际页面加载的时间并不能造成太大影响,但是这会减少页面首屏出现的时间,使页面内容逐步呈现,改善用户体验,防止“白屏”。
我们总是希望页面能够尽快显示内容,为用户提供可视化的回馈,这对网速慢的用户来说是很重要的。
将样式表放在文档底部会阻止浏览器中的内容逐步出现。为了避免当样式变化时重绘页面元素,浏览器会阻塞内容逐步呈现,造成“白屏”。这源自浏览器的行为:如果样式表仍在加载,构建呈现树就是一种浪费,因为所有样式表加载解析完毕之前务虚会之任何东西
六、将脚本放在底部
更样式表相同,脚本放在底部对于实际页面加载的时间并不能造成太大影响,但是这会减少页面首屏出现的时间,使页面内容逐步呈现。
js的下载和执行会阻塞Dom树的构建(严谨地说是中断了Dom树的更新),所以script标签放在首屏范围内的HTML代码段里会截断首屏的内容。
下载脚本时并行下载是被禁用的——即使使用了不同的主机名,也不会启用其他的下载。因为脚本可能修改页面内容,因此浏览器会等待;另外,也是为了保证脚本能够按照正确的顺序执行,因为后面的脚本可能与前面的脚本存在依赖关系,不按照顺序执行可能会产生错误。
七、避免CSS表达式
CSS表达式是动态设置CSS属性的一种强大并且危险的方式,它受到了IE5以及之后版本、IE8之前版本的支持。
p {
width: expression(func(),document.body.clientWidth > 400 ? "400px" : "auto");
height: 80px;
border: 1px solid #f00;
}
<p><span></span></p>
<p><span></span></p>
<p><span></span></p>
<p><span></span></p>
<p><span></span></p>
<script>
var n = 0;
function func() {
n++;
alert();
console.log(n);
}
</script>
鼠标移动了几次,函数的运行次数轻而易举的达到了几千次,危险性显而易见。
如何解决:
一次性表达式:
p {
width: expression(func(this));
height: 80px;
border: 1px solid #f00;
}
<p><span></span></p>
<p><span></span></p>
<p><span></span></p>
<p><span></span></p>
<p><span></span></p>
<script>
var n = 0;
function func(elem) {
n++;
elem.style.width 400 ? '400px' : "auto";
console.log(n);
}
</script>
事件处理机制
用js事件处理机制来动态改变元素的样式,使函数运行次数在可控范围之内。
八、使用外部的JavaScript和CSS
内联脚本或者样式可以减少HTTP请求,按理来说可以提高页面加载的速度。然而在实际情况中,当脚本或者样式是从外部引入的文件,浏览器就有可能缓存它们,从而在以后加载的时候能够直接使用缓存,而HTML文档的大小减小,从而提高加载速度。
影响因素:
1、每个用户产生的页面浏览量越少,内联脚本和样式的论据越强势。譬如一个用户每个月只访问你的网站一两次,那么这种情况下内联将会更好。而如果该用户能够产生很多页面浏览量,那么缓存的样式和脚本将会极大减少下载的时间,提交页面加载速度。
2、如果你的网站不同的页面之间使用的组件大致相同,那么使用外部文件可以提高这些组件的重用率。
加载后下载
有时候我们希望内联样式和脚本,但又可以为接下来的页面提供外部文件。那么我们可以在页面加载完成止呕动态加载外部组件,以便用户接下来的访问。
1 function doOnload() {
2 setTimeout("downloadFile()",1000);
3 }
4
5 window.onload = doOnload;
6
7 function downloadFile() {
8 downloadCss("http://abc.com/css/a.css");
9 downloadJS("http://abc.com/js/a.js");
10 }
11
12 function downloadCss(url) {
13 var ele = document.createElement('link');
14 ele.rel = "stylesheet";
15 ele.type = "text/css";
16 ele.href = url;
17
18 document.body.appendChild(ele);
19 }
20
21 function downloadJS(url) {
22 var ele = document.createElement('script');
23 ele.src = url;
24 document.body.appendChild(ele);
25 }
在该页面中,JavaScript和CSS被加载两次(内联和外部)。要使其正常工作,必须处理双重定义。将这些组件放到一个不可见的IFrame中是一个比较好的解决方式。
九、减少DNS查找
当我们在浏览器的地址栏输入网址(譬如: www.linux178.com) ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
域名解析是页面加载的第一步,那么域名是如何解析的呢?以Chrome为例:
1. Chrome浏览器 会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有www.linux178.com 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
注:我们怎么查看Chrome自身的缓存?可以使用 chrome://net-internals/#dns 来进行查看
2. 如果浏览器自身的缓存里面没有找到对应的条目,那么Chrome会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
注:怎么查看操作系统自身的DNS缓存,以Windows系统为例,可以在命令行下使用 ipconfig /displaydns 来进行查看
3. 如果在Windows系统的DNS缓存也没有找到,那么尝试读取hosts文件(位于C:\Windows\System32\drivers\etc),看看这里面有没有该域名对应的IP地址,如果有则解析成功。
4. 如果在hosts文件中也没有找到对应的条目,浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找打根域的DNS地址,就会向其发起请求(请问www.linux178.com这个域名的IP地址是多少啊?),根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.linux178.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.linux178.com这个域名的IP地址,但是我知道linux178.com这个域的DNS地址,你去找它去,于是运营商的DNS又向linux178.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.linux178.com这个域名的IP地址是多少?),这个时候linux178.com域的DNS服务器一查,诶,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.linux178.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.linux178.com对应的IP地址,该进行一步的动作了。
注:一般情况下是不会进行以下步骤的
如果经过以上的4个步骤,还没有解析成功,那么会进行如下步骤:
5. 操作系统就会查找NetBIOS name Cache(NetBIOS名称缓存,就存在客户端电脑中的),那这个缓存有什么东西呢?凡是最近一段时间内和我成功通讯的计算机的计算机名和Ip地址,就都会存在这个缓存里面。什么情况下该步能解析成功呢?就是该名称正好是几分钟前和我成功通信过,那么这一步就可以成功解析。
6. 如果第5步也没有成功,那会查询WINS 服务器(是NETBIOS名称和IP地址对应的服务器)
7. 如果第6步也没有查询成功,那么客户端就要进行广播查找
8. 如果第7步也没有成功,那么客户端就读取LMHOSTS文件(和HOSTS文件同一个目录下,写法也一样)
如果第八步还没有解析成功,那么就宣告这次解析失败,那就无法跟目标计算机进行通信。只要这八步中有一步可以解析成功,那就可以成功和目标计算机进行通信。
DNS也是开销,通常浏览器查找一个给定域名的IP地址要花费20~120毫秒,在完成域名解析之前,浏览器不能从服务器加载到任何东西。那么如何减少域名解析时间,加快页面加载速度呢?
当客户端DNS缓存(浏览器和操作系统)缓存为空时,DNS查找的数量与要加载的Web页面中唯一主机名的数量相同,包括页面URL、脚本、样式表、图片、Flash对象等的主机名。减少主机名的 数量就可以减少DNS查找的数量。
减少唯一主机名的数量会潜在减少页面中并行下载的数量(HTTP 1.1规范建议从每个主机名并行下载两个组件,但实际上可以多个),这样减少主机名和并行下载的方案会产生矛盾,需要大家自己权衡。建议将组件放到至少两个但不多于4个主机名下,减少DNS查找的同时也允许高度并行下载。
十、精简JavaScript
精简
精简就是从代码中移除不必要的字符以减少文件大小,降低加载的时间。代码精简的时候会移除不必要的空白字符(空格,换行、制表符),这样整个文件的大小就变小了。
混淆
混淆是应用在源代码上的另外一种方式,它会移除注释和空白符,同时它还会改写代码。在混淆的时候,函数和变量名将会被转换成更短的字符串,这时代码会更加精炼同时难以阅读。通常这样做是为了增加对代码进行反向工程的难度,这也同时提高了性能。
缺点:
混淆本身比较复杂,可能会引入错误。
需要对不能改变的符号做标记,防止JavaScript符号(譬如关键字、保留字)被修改。
混淆会使代码难以阅读,这使得在产品环境中调试问题更加困难。
在以上提到了关于用gzip之类的压缩方式来压缩文件,这边说明一下,就算使用gzip等方式来压缩文件,精简代码依然是有必要的。一般来说,压缩产生的节省是高于精简的,在生产环境中,精简和压缩同时使用能够最大限度的获得更多的节省。
CSS的精简
CSS的精简带来的节省一般来说是小于JavaScript精简的,因为CSS中注释和空白相对较少。
除了移除空白、注释之外,CSS可以通过优化来获得更多的节省:
合并相同的类;
移除不使用的类;
使用缩写,譬如
.right {
color: #fff;
padding-top: 0;
margin: 0 10px;
border: 1px solid #111
}
.wrong {
color: #ffffff;
padding-top: 0px;
margin-top: 0;
margin-bottom: 0;
margin-left: 10px;
margin-right: 10px;
border-color: #111;
border-width: 1px;
border-style: solid;
}
上面.right是正确的的写法,颜色使用缩写,使用0代替0px,合并可以合并的样式。另外,在精简的时候其实样式最后一行的';'也是可以省略的。
来看看精简的例子:
![]()


以上分别是jQuery-2.0.3的学习版(未精简)和精简版,可见精简文件的大小比源文件小了155k,而且,在精简版中jquery还做了混淆,譬如用e代替window等,从而获得最大的节省。
十一、避免重定向
什么是重定向?
重定向用于将用户从一个URL重新路由到另一个URL。
常用重定向的类型
301:永久重定向,主要用于当网站的域名发生变更之后,告诉搜索引擎域名已经变更了,应该把旧域名的的数据和链接数转移到新域名下,从而不会让网站的排名因域名变更而受到影响。
302:临时重定向,主要实现post请求后告知浏览器转移到新的URL。
304:Not Modified,主要用于当浏览器在其缓存中保留了组件的一个副本,同时组件已经过期了,这是浏览器就会生成一个条件GET请求,如果服务器的组件并没有修改过,则会返回304状态码,同时不携带主体,告知浏览器可以重用这个副本,减少响应大小。
重定向如何损伤性能?
当页面发生了重定向,就会延迟整个HTML文档的传输。在HTML文档到达之前,页面中不会呈现任何东西,也没有任何组件会被下载。
来看一个实际例子:对于ASP.NET webform开发来说,对于新手很容易犯一个错误,就是把页面的连接写成服务器控件后台代码里,例如用一个Button控件,在它的后台click事件中写上:Response.Redirect("");然而这个Button的作用只是转移URL,这是非常低效的做法,因为点击Button后,先发送一个Post请求给服务器,服务器处理Response.Redirect("")后就发送一个302响应给浏览器,浏览器再根据响应的URL发送GET请求。正确的做法应该是在html页面直接使用a标签做链接,这样就避免了多余的post和重定向。
重定向的应用场景
1. 跟踪内部流量
重定向经常用于跟踪用户流量的方向,当拥有一个门户主页的时候,同时想对用户离开主页后的流量进行跟踪,这时可以使用重定向。例如: 某网站主页新闻的链接地址http://a.com/r/news,点击该链接将产生301响应,其Location被设置为http://news.a.com。通过分析a.com的web服务器日志可以得知人们离开首页之后的去向。
我们知道重定向是如何损伤性能的,为了实现更好的效率,可以使用Referer日志来跟踪内部流量去向。每个HTTP请求都有一个Referer表示原始请求页(除了从书签打开或直接键入URL等操作),记录下每个请求的Referer,就避免了向用户发送重定向,从而改善了响应时间。
2. 跟踪出站流量
有时链接可能将用户带离你的网站,在这种情况下,使用Referer就不太现实了。
同样也可以使用重定向来解决跟踪出站流量问题。以百度搜索为例,百度通过将每个链接包装到一个302重定向来解决跟踪的问题,例如搜索关键字“前端性能优化”,搜索结果中的一个URL为https://www.baidu.com/link?url=pDjwTfa0IAf_FRBNlw1qLDtQ27YBujWp9jPN4q0QSJdNtGtDBK3ja3jyyN2CgxR5aTAywG4SI6V1NypkSyLISWjiFuFQDinhpVn4QE-uLGG&wd=&eqid=9c02bd21001c69170000000556ece297,即使搜索结果并没有变,但这个字符串是动态改变的,暂时还不知道这里起到怎样的作用?(个人感觉:字符串中包含了待访问的网址,点击之后会产生302重定向,将页面转到目标页面(待修改,求大神们给我指正))
除了重定向外,我们还可以选择使用信标(beacon)——一个HTTP请求,其URL中包含有跟踪信息。跟踪信息可以从信标Web服务器的访问日记中提取出来,信标通常是一个1px*1px的透明图片,不过204响应更优秀,因为它更小,从来不被缓存,而且绝不会改变浏览器的状态。
十二、删除重复脚本
在团队开发一个项目时,由于不同开发者之间都可能会向页面中添加页面或组件,因此可能相同的脚本会被添加多次。
重复的脚本会造成不必要的HTTP请求(如果没有缓存该脚本的话),并且执行多余的JavaScript浪费时间,还有可能造成错误。
如何避免重复脚本呢?
1. 形成良好的脚本组织。重复脚本有可能出现在不同的脚本包含同一段脚本的情况,有些是必要的,但有些却不是必要的,所以需要对脚本进行一个良好的组织。
2. 实现脚本管理器模块。
例如:
1 function insertScript($file) {
2 if(hadInserted($file)) {
3 return;
4 }
5 exeInsert($file);
6
7 if(hasDependencies($file)) {
8
9 $deps = getDependencies($file);
10
11 foreach ($deps as $script) {
12 insertScript($script);
13 }
14
15 echo "<script type='text/javascript' src='".getVersion($file)."'></script>";
16
17 }
18 }
先检查是否插入过,如果插入过则返回。如果该脚本依赖其它脚本,则被依赖的脚本也会被插入。最后脚本被传送到页面,getVersion会检查脚本并返回追加了对应版本号的文件名,这样如果脚本的版本变化了,那么以前浏览器缓存的就会失效。
十三、配置ETag
以前浏览器缓存的就会失效。
什么是ETag?
实体标签(EntityTag)是唯一标识了一个组件的一个特定版本的字符串,是web服务器用于确认缓存组件的有效性的一种机制,通常可以使用组件的某些属性来构造它。
条件GET请求
如果组件过期了,浏览器在重用它之前必须首先检查它是否有效。浏览器将发送一个条件GET请求到服务器,服务器判断缓存还有效,则发送一个304响应,告诉浏览器可以重用缓存组件。
那么服务器是根据什么判断缓存是否还有效呢?有两种方式:
ETag(实体标签);
最新修改日期;
最新修改日期
原始服务器通过Last-Modified响应头来返回组件的最新修改日期。
举个栗子:
当我们不带缓存访问www.google.com.hk的时候,我们需要下载google的logo,这时会发送这样一个HTTP请求:
Request:
GET googlelogo_color_272x92dp.png HTTP 1.1
Host: www.google.com.hk
Response:
HTTP 1.1 200 OK
Last-Modified:Fri, 04 Sep 2015 22:33:08 GMT

当需要再次访问相同组件的时候,同时缓存已经过期,浏览器会发送如下条件GET请求:
Request:
GET googlelogo_color_272x92dp.png HTTP 1.1
If-Modified-Since:Fri, 04 Sep 2015 22:33:08 GMT
Host: www.google.com.hk
Response:
HTTP 1.1 304 Not Modified

实体标签
ETag提供了另外一种方式,用于检测浏览器缓存中的组件与原始服务器上的组件是否匹配。摘抄自书上的例子:
不带缓存的请求:
Request:
GET /i/yahoo/gif HTTP 1.1
Host: us.yimg.com
Response:
HTTP 1.1 200 OK
Last-Modified:Tue,12 Dec 200603:03:59 GMT
ETag:”10c24bc-4ab-457elc1f“
再次请求相同组件:
Request:
GET /i/yahoo/gif HTTP 1.1
Host: us.yimg.com
If-Modified-Since:Tue,12 Dec 200603:03:59 GMT
If-None-Match:”10c24bc-4ab-457elc1f“
Response:
HTTP 1.1 304 Not Midified
为什么要引入ETag?
ETag主要是为了解决Last-Modified无法解决的一些问题:
1. 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
2. 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
3. 某些服务器不能精确的得到文件的最后修改时间。
ETag带来的问题
ETag的问题在于通常使用某些属性来构造它,有些属性对于特定的部署了网站的服务器来说是唯一的。当使用集群服务器的时候,浏览器从一台服务器上获取了原始组件,之后又向另外一台不同的服务器发起条件GET请求,ETag就会出现不匹配的状况。例如:使用inode-size-timestamp来生成ETag,文件系统使用inode存储文件类型、所有者、组和访问模式等信息,在多台服务器上,就算文件大小、权限、时间戳等都相同,inode也是不同的。
最佳实践
1. 如果使用Last-Modified不会出现任何问题,可以直接移除ETag,google的搜索首页则没有使用ETag。
2. 确定要使用ETag,在配置ETag的值的时候,移除可能影响到组件集群服务器验证的属性,例如使用size-timestamp来生成时间戳。
十四、使Ajax可缓存
维基百科中这样定义Ajax:
AJAX即“Asynchronous JavaScript and XML”(异步的JavaScript与XML技术),指的是一套综合了多项技术的浏览器端网页开发技术。Ajax的概念由杰西·詹姆士·贾瑞特所提出。
传统的Web应用允许用户端填写表单(form),当提交表单时就向Web服务器发送一个请求。服务器接收并处理传来的表单,然后送回一个新的网页,但这个做法浪费了许多带宽,因为在前后两个页面中的大部分HTML码往往是相同的。由于每次应用的沟通都需要向服务器发送请求,应用的回应时间依赖于服务器的回应时间。这导致了用户界面的回应比本机应用慢得多。
与此不同,AJAX应用可以仅向服务器发送并取回必须的数据,并在客户端采用JavaScript处理来自服务器的回应。因为在服务器和浏览器之间交换的数据大量减少(大约只有原来的5%)[来源请求],服务器回应更快了。同时,很多的处理工作可以在发出请求的客户端机器上完成,因此Web服务器的负荷也减少了。
类似于DHTML或LAMP,AJAX不是指一种单一的技术,而是有机地利用了一系列相关的技术。虽然其名称包含XML,但实际上数据格式可以由JSON代替,进一步减少数据量,形成所谓的AJAJ。而客户端与服务器也并不需要异步。一些基于AJAX的“派生/合成”式(derivative/composite)的技术也正在出现,如AFLAX。
Ajax的目地是为突破web本质的开始—停止交互方式,向用户显示一个白屏后重绘整个页面不是一种好的用户体验。
异步与即时
Ajax的一个明显的有点就是向用户提供了即时反馈,因为它异步的从后端web服务器请求信息。
用户是否需要等待的关键因素在于Ajax请求是被动的还是主动的。被动请求是为了将来来使用而预先发起的,主动请求是基于用户当前的操作而发起的
什么样的AJAX请求可以被缓存?
POST的请求,是不可以在客户端缓存的,每次请求都需要发送给服务器进行处理,每次都会返回状态码200。(可以在服务器端对数据进行缓存,以便提高处理速度)
GET的请求,是可以(而且默认)在客户端进行缓存的,除非指定了不同的地址,否则同一个地址的AJAX请求,不会重复在服务器执行,而是返回304。
Ajax请求使用缓存
在进行Ajax请求的时候,可以选择尽量使用get方法,这样可以使用客户端的缓存,提高请求速度。
css优化,js优化以及web性能优化
2017年07月27日 00:09:07
阅读数:3021
Css优化总结
对于css的优化可以从网络性能和css语法优化两方面来考虑。
Css性能优化方法如下:
1、css压缩
Css 压缩虽然不是高端的知识,但是很有用。其原理也很简单,就是把我们css代码中没有用的空白符等删除,达到缩减字符个数的目的。
压缩css代码的工具:
A、YUI compressor,可以在线压缩css和js代码。
B、gulp自动化构建工具,中的gulp-minify-css。
2、gzip压缩
Gzip是一种流行的文件压缩算法,现在应用的十分广泛,尤其实在Linux这个平台上,这个不止是对css,当应用Gzip压缩一个文本时,效果是非常明显的。大约可以减少70%以上的文件大小(这取决于文件中的内容)。
在没有 gzip压缩的情况下,web服务器直接把html页面、css脚本以及js脚本发送到浏览器,而支持gzip的浏览器在本地进行解压和解码,并显示原文件。这样我们传输的文件字节数减少了,自然可以达到网络性能优化的目的。Gzip压缩需要服务器的支持,所以需要在服务器端进行配置。
3、合写css(通过少些css属性来达到减少css字节吗的目的)
例子:
background:#000 url(image.jpg) top left no-repeat;
font:font-style font-weight font-size font-familiy;
margin:5px 10px 20px 15px;
padding:5px;
border:2px 5px 10px 3px;
border-top:2px 5px 10px 3px;
4、利用继承
Css的继承机制可以帮我们在一定程度上缩减字节数,我们知道css很多属性可以继承,即在父容器设置了默认属性,子容器会默认也使用这些属性。
可继承的属性举例:
所有元素都可以继承的属性:visibility 、cursor
内联元素和块元素可以继承的属性:
Letter-spacing、word-spacing、white-space、line-height、color、font、font-family、font-size、font-style、font-variant、font-weight、text-decoration、text-transform、direction。
块状元素可以继承的属性:
Text-indent、text-align;
列表元素可以继承的属性:
List-style、list-style-type、list-style-position、list-style-image
表格元素可以继承的属性:
Border-collapse
不可以继承的属性:
Display、margin、border、padding、background、height、min-height、max-height、width、min-width、max-width、overflow、position、left、right、top、bottom、z-index、float、clear、table-layout、vertical-align、page-break-after、page-break-before、unicode-bidi
5、抽离、拆分css,不加载所有css
抽离原则:在很多时候,我们把页面通用的css写到了一个文件,这样加载一次后,就可以利用缓存,但这样做兵不适合所有的场景。所以抽离拆分的时候要考虑好。
6、css放在head中,减少repaint和reflow
Css方法在页面的顶部,有利于优化的原因???
当浏览器从上到下一遍下载html生成dom tree,一边根据浏览器默认以及现有css生成render tree来渲染页面。当遇到新的css的时候下载并结合现有css重新生成render tree。则刚才的渲染功能就全废了。当我们把所有css放在页面的顶部,就没有重新渲染的过程了。
脚本中应该尽量少用repaint和reflow:
Reflow:当dom元素出现隐藏/显示,尺寸变化。位置变化的时候,逗号让浏览器重新渲染页面,以前的渲染工作白费了。
Repaint:当元素的背景颜色,边框颜色变化的时候,不会引起reflow的变化,是会让浏览器重新渲染该元素。
7、避免使用通配符或隐式通配符:visible.
8、避免层级或过度限制css(css是从右向左解析的)
A、不要用标签或class来限制id。
#test .info /div #test这都属于画蛇添足
Id已经可以唯一而且快速的定位到一个元素了。
B、不要用标签限制class
Div .info 不好
在css代码编写中,如果直接使用class不能达到目的,一般是class设计出现了问题,css需要重构。
C、尽量使用最具体的类别,避免使用后代选择器,在css选择器中,后代选择器非但没有加快css查找,反而后代选择器是css中耗费最贵的。
JavaScript优化总结
1、避免全局查找
在一个函数中尽量将全局对象存储为局部变量来查找,因为访问局部变量的数要更快一些。
function(){
alert(window.location.href+window.location.host);
}
修改为:
funciton(){
var location=window.location;
alert(location.href+location.host);
}
2、定时器
如果针对的是不断运行的代码,不应该使用setTimeout,而应该使用setInterval。因为setTimeout每一次都会初始化一个定时器。而setInterval只会在开始的时候初始化一个定时器。
var timeoutTimes=0;
function timeout(){
timeoutTimes++;
if(timeoutTimes<10){
setTimeout(timeout,10);
}
}
修改为:
var intervalTimes=0;
function interval(){
intervalTimes++;
if(intervalTimes>=10){
clearInterval(interval)''
}
}
var interval = setInterval(interval,10);
3、字符串连接
如果需要连接多个字符串,应该少使用+=:
如
s+=a;s+=b;s+=c;
修改为:
s+=a+b+c;
而如果是收集字符串,比如多次对同一个字符进行+=操作的话,最好使用一个缓存,使用js数组来收集,最后join方法连接起来。
var buf=[];
for(var i=0;i<100;i++){
buf.push(i.toString());
}
var all=buf.join("");
4、避免with语句
和函数类似,with语句会创建自己的作用域,因此会增加其中执行的代码的作用域链的长度。犹豫额外的作用域链的查找,在with语句中执行的代码肯定会比外面执行的低吗要慢,在能不使用with语句的时候,尽量不要使用with语句。
with(a,b,c,d){
property1=1;
property2=2;
}
修改为:
var obj=a.b.c.d;
obj.property1=1;
obj.property2=2;
5、数字转为字符串
一般用“”+1来将数字转为字符串,虽然看起来比较丑一点,但事实上这个效率最高。
(“”+1)>String()>.toString()>new String()
6、浮点数转化为整型
很多人喜欢使用pareseInt(),其实parseInt()是用于将字符串转为数字,而不是浮点数和整型之间的转换。我们应该使用的是Math.floor()或Math.round();
7、多个类型声明
所有变量可以使用单个var语句来声明,这样就是组合在一起的语句,以减少整个脚本的执行时间。
var A=1,
B=2,
C=3;
8、使用直接量
var aTest=new Array();//var aTest=[]
var aTest=new Object();//var aTest={}
var reg=new RegExp();//var reg=/ /;
创建具有特殊性的一般对象,也可以使用字面量。
var oFruit=new O();
oFruit.color="red";
oFruit.name="apple";
应改为
varoFruit={color:"red",name:'apple'}
9、使用DocumentFragment优化多次的append
一旦需要跟新DOM,请考虑使用文档碎片来构建结构,然后再添加到现有的文档中。
for(var i=0;i<1000;i++){
varel=document.createElement('p');
el.innerHTML=i;
document.body.append(el);
}
应该改为
varfrag=document.createDocumentFragment();
for(var i=0;i<1000,i++){
varel=document.createElement('p');
el.innerHTML=i;
frag.append(el);
}
document.body.appendChild(frag);
10、使用一次innerHTML复制代替构建dom元素。
对于大的dom更改,使用innerHTML要比使用标准的dom方法创建同样的dom结构快的多。
varfrag=document.createDocumentFragment();
for(var i=0;i<1000;i++){
varel=document.createElement('p');
el.innerHTML=i;
frag.appendChild(el);
}
document.body.appendChild(frag);
应该改为
var html=[];
for(var i=0;i<1000;i++){
html.push('<p>'+i+"</p>");
}
document.body.innerHTML=html.join("");
11、使用firstChild和nextSibling代替childNodes遍历dom元素。
var nodes=element.childNodes;
for(var i=0,l=nodes.length;i<l;i++){
varnode=nodes[i];
}
应该改为
var node=element.firstChild;
while(node){
node.node.nextSibling;
}
12、删除dom节点
删除dom节点之前,一定要删除注册在该节点上的事件,不管是observe方式还是用attachEvent方式注册的事件。否则将会产生无法回收的内存。另外,removeChild和innerHTML=‘’两者之间尽量选择后者,因为在内存泄漏工具中监测的结果是用removeChild无法有效的释放dom节点。
13、简化终止条件
由于每次循环过程,都会计算终止条件。所以必须保证他尽可能的快。也就是避免属性查找或其他操作。最好是将循环控制量保存到局部变量中,也就是说对数组或列表对象遍历的时候,提前将length保存到局部变量中,避免循环的每一步重复取值。
varlist=document.getElementsByTagName('p');
for(var i=0;i<list.length;i++){
}
应该改为
for(var i=0,l=list.length;i<l;i++){
}
14、使用后测试循环
在js中,我们使用for(;;),while(),for(in)三种循环。for(in)的效率极差。因为他需要查询散列键,只要可以,就应该尽量少用。
for(;;)和while循环,while优于for(;;),可能for(;;)结构问题,需要经常的跳转。do..while更好。
15、尽量少用eval函数
使用eval函数相当于在运行时,再次调用解释引擎对内容进行运行,需要消耗大量时间,而且使用eval带来的安全性问题也是不容忽视的。
16、不要给setTimeout或setInterval传递字符串参数。
var num=0;
setTimeout(num++,10);
应该改为
var num=0;
function addNum(){
num++;
}
setTimeout(addNum,10);
17、缩短否定检测
if(oTest!="#ff0000"){}
if(oTest!=null){}
if(oTest!=false){}
以上都不太好
if(!oTest){这个比较好}
18、可以用三目运算符替换条件分支,可以提高效率。
Web性能优化
1、避免坏请求
有时候页面中的html或css会向服务器请求一个不存在的资源,比如图片或者html文件,这会造成浏览器与服务器之间过多的往返请求。
类似于:
浏览器:“我需要这个图像”
服务器:“我没有这个图像”
浏览器:“你确定吗?这个文档说你有”
服务器:“真的没有”
这个降低页面加载速度。因此检查坏连接很有必要。可通过Google的PageSpeed工具,找到问题后,补充相当资源文件或者修改资源链接地址即可。
2、避免css@import
使用@import方法引用css文件可能会带来一些影响页面加载速度的问题。比如导致文件按顺序加载(一个加载完成后才会加载另一个),无法并行加载;
检查工具:css delivery
查到@import url(“style.css”)
就替换为:<link….>
3、避免使用document.write
在js中,可以使用document.write。在网页上显示内容或者调用外部资源,而通过此方法,浏览器采取一些多余的步骤(下载资源,读取资源)。运行js来了解需要做什么,调用其他资源时,需要重新在执行一次这个过程。由于浏览器之前不知道要显示什么,所以会降低页面加载的速度。
要知道,任何能够被document.write调用的资源,都可以通过html调用。这样速度会更快
document.write('<scriptsrc="another.js"></script>');
改为
<scriptsrc="another.js"></script>
4、合并多个外部css文件
网站中每使用一个css文件,都会让你的页面加载速度慢一点。可以css delivery工具,来检测页面代码中css文件。然后通过复制粘贴合并成一个。
5、合并多个外部js文件
可以用resource check来检测页面中所引用的js文件数,然后可以通过复制粘贴的方法将多个文件合并成一个。
6、通过css sprites来整合图像
若页面中有6个小图像,那么浏览器在显示时会分别下载,你可以通过css sprites将这些图像合并成为一个,可以减少页面加载所需要的时间。
Css sprites两个步骤:整合图像,定位图像
7、延迟js加载
浏览器在执行js代码时,会停止处理页面。当页面中很多js文件或者代码要加载时,将导致严重的延迟。尽管可以使用defer,异步或将js代码放自爱页面底部来延迟js的加载。但这些都不是一个好的解决方案。
好方法
<script>
function downloadJSAtOnload(){
varelement=document.createElement("script");
element.src="defer.js";
document.body.appendChild(element);
}
if(window.addEventListener){
window.addEventListener('load',downloadJSAtOnload,false);
}else if(window.attachEvent){
window.attachEvent('onload',downloadJSAtOnload);
}else{
window.οnlοad=downloadJSAtOnload;
}
</script>
8、启用压缩/Gzip
使用gzip对html和css文件进行压缩,通常可以大约节省50%到70%,这样加载页面只需要更少的带宽和更少的时间。
9、如果你的css和js较小,可以将css和js内嵌到html页面中,这样可以减少页面加载所需要的文件数,从而加快页面的加载。
10、用minify css压缩css代码
11、尽量减少dns查询次数
当浏览器和服务器建立链接时,它需要进行dns解析,将域名解析为ip地址,然而,一旦客户端需要执行dns lookup时,等待时间将会取决于域名服务器的有效响应速度。
虽然所有的isp的dns服务器都能缓存域名和ip地址映射表。但如果缓存的dns记录过期了而需要更新,则可能需要遍历多个dns节点,有时候需要通过全球范围内来找到可信任的域名服务器,一旦域名服务器工作繁忙,请求解析时,就需要排队则进一步延时等待时间。
所有减少dns查询次数很重要,页面加载就尽量避免额外耗时,为了减少dns查询次数,最好的解决方法就是在页面中减少不同的域名请求的机会、
可通过request checker工具来检测页面中存在多少请求后,进行优化。
12、尽量减少重定向
有时候为了特定需求,需要在网页中使用重定向。重定向的意思是,用户的原始请求(如请求A)被重定向到其他的请求(如请求B);
网页中使用重定向会造成网站性能和速度下降,因为浏览器访问网址是一连串的过程,如果访问到一半,而跳转到新的地址,就会重复发起一连串的过程,这将浪费很多时间。所有我们尽量避免重定向。Google建议
A、 不要链接到一个包含重定向的页面
B、 不要请求包含重定向的资源
13、优化样式表和脚步顺序
Style标签和样式表调用代码应该放置在js代码的前面,这样可以使页面的加载速度加快。
14、避免js阻塞渲染
浏览器在遇到一个引入外部js文件的<script>标签时,会停下所有工作下载并解析执行它。在这个过程中,页面渲染和用户交互完全被阻塞了。这是页面加载就会停止。
谷歌建议删除干扰页面第一屏内容加载 的js,第一屏指的是用户在屏幕中最初看到的页面,无论桌面浏览器,还是手机
15、指定图像尺寸
当浏览器加载页面的html时,有时候需要在图片下载完成前,对页面布局进行定位。如果hmtl里的图片没有指定尺寸,或者代码描述的尺寸和实际的图片尺寸不符合时,浏览器需要在图片下载完成后在回溯到该图片,并重新显示,这将消耗额外的时间。
最好的页面中每一张图片都指定尺寸,不管在html里的img中,还是在css中。
网站性能优化(一)减少HTTP请求数量
娜姐聊前端 关注
2017.02.26 23:20* 字数 1122 阅读 3282评论 0喜欢 16
大部分网站的响应时间都花在HTTP请求,尤其是资源文件请求。
当然,HTTP 1.1 中已经支持了持久连接-keep-alive,即一个TPC/IP连接中,可以连续发起多次HTTP请求。随后,采用“管线化”技术,能够做到同时并行发送多个HTTP请求,而不需要一个接一个等待响应(Chrome目前支持在一个域名domain下,同时发起6个并行的HTTP请求)。尽管这样,为了进一步提高网站性能,还是需要考虑如何有效的减少HTTP请求数量。
1. 图片:雪碧图,图标字体文件,data:url
优化图片有很多方式,除了压缩,最常见得就是雪碧图,即把多张小图片合并为一张图,利用CSS -background-position调整图片显示位置。这种方式适用面比较广泛,缺点是,如果一张小图,需要N个颜色,就必须做N个不同颜色的小图,合并到大图里面。
所以,如果需要大小统一并颜色自定义的图片,那么,图标字体文件最好不过了。比如流行的font-awesome(http://fontawesome.io/), icomoon(https://icomoon.io/, 支持图片自定义)等等。只需要引入字体文件,然后即能够随心所欲的使用各类图片,利用CSS定义图标颜色。
data:url模式可以在页面中渲染图片但无需额外的HTTP请求,格式如下:
<img scr="data:image/jpg;base64, xxxxxxxxxxxxxxxx">
这个的缺点是,如果一张图片在多个页面被用到,无法利用浏览器缓存。为了解决这个问题,我们可以换个思路,把图片数据放在CSS文件里面定义,比如:
.imageA {
background-image:url(data:image/jpg;base64, xxxxxxxxxxxxxxxx);
}这样即可以利用浏览器缓存技术缓存CSS文件,又可以避免额外的图片请求。
注意:移动端不建议用src="data:image...",性能非常不好。
2. 合并JS和CSS文件
这个是最常用的做法。
利用项目构建工具,如gulp, grunt, webpack等等,都可以做到JS或者CSS文件的压缩,合并。只不过,合并后文件大小如何,需要斟酌而定。如果仅仅为了减少HTTP请求开销,而下载一个巨大的JS或CSS,反倒会延长网站渲染时间,导致白板或者页面卡顿。
小贴士:HTTP1.1默认在requestheader里面开启gzip。
使用gzip编码来压缩HTTP响应包,由此可以减少网络响应时间。
例子:Accept-Encoding:gzip,
3. 充分利用浏览器缓存
如果图片或者脚本,样式文件内容比较固定,不经常被修改,那么,尽可能利用缓存技术,减少HTTP请求次数或文件下载次数。
命中浏览器缓存分为两类:强缓存,协商缓存。
- 强缓存:不会发起HTTP请求,直接从浏览器缓存中读取文件。
- HTTP 1.0中,采用
Expires头指定资源过期时间; - HTTP 1.1中,采用
Cache-Control: max-age指定资源被缓存多久;
- HTTP 1.0中,采用
- 协商缓存:向服务器发起HTTP请求,如果资源文件并未更新,response响应码即为304,随后从浏览器缓存中下载该文件,并不会从服务器下载。
- HTTP 1.0中,采用
Last-Modified(response header)和If-Modified-Since(request header)来指定资源过期时间; - HTTP 1.1中,采用
E-Tag(response/request header)和If-None-Match来决定该资源是否过期;
- HTTP 1.0中,采用
哪怕是协商缓存,一旦命中,这个HTTP请求响应速度也是极快的。
当然,如何配置浏览器缓存,大多是后台资源服务器控制的。比如,通常我们建议将共有图片,第三方JS插件库或者CSS放到CDN(内容发布网络)上,不仅仅因为CDN的分布式特性可以加快资源文件下载速度,而且,一般CDN服务器都做了缓存配置,可以充分浏览器缓存。
小贴士:如果用JQuery动态加载脚本文件,或者请求其他类型资源文件,可以设置```cache```属性。
cache为true时,开启缓存;反之,JQuery自动在请求上加后缀,强行从服务器重新下载资源文件。
代码如下:$.ajaxSetup({cache:true//开启缓存
});小结
网站性能优化是一个长期过程,一点点做起,最终总会见到成效。系列文章还将继续......
如何减少页面的HTTP请求
2015年03月23日 11:59:08
阅读数:1190
我们访问网站的时候,会对服务器发出HTTP请求,网站打开的速度快慢与页面的大小有关外,还有个重要的因素就是HTTP的请求数。尽量减少页面的HTTP请求,可以提高页面载入速度。
减少页面中的元素
网页中的的图片、form、flash等等元素都会发出HTTP请求,尽可能的减少页面中非必要的元素,可以减少HTTP请求的次数。
图片地图(Image Maps)
也就是图像热点,图像地图就是把一张图片分成若干区域,每个区域指向不同的URL地址,这些区域也称为热点。Image Maps只适用于连续的图标。
CSS Sprites(CSS精灵)
图片是增加HTTP请求的最大可能者,把全站的图标都放在一个图像文件中,然后用CSS的background-image和background-position属性定位来显示其中的一小部分。
这种方法把CSS写到HMTL文件里,而不采用外部调用,与Div+CSS中「表现与内容分离、把CSS都立出来」相悖,缺点就是不利于SEO;当然,从整体上减少HTTP请求、提高页面载入速度,是有利于SEO的。
JS文件和CSS文件只有一个
合并脚本和CSS文件,可以减少了HTTP请求。有的人喜欢把CSS分成结构清晰的几个部分,比如base.css、header.css、mianbody.css、 footer.css这样对页面的维护和修改是比较方便的,但是对加快服务器响应时间就存在问题了。
少用location.reload()
使用location.reload() 会刷新页面,刷新页面时页面所有资源(css,js,img等)会重新请求服务器。
建议使用location.href="当前页url" 代替location.reload() ,使用location.href 浏览器会读取本地缓存资源。
动态页面静态化
动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器才返回一个完整的网页。
用户访问动态页面需要与数据库服务器进行数据交换。动态页面静态化,也就是把动态网页生成HTML文件,用空间换效率。
最全整理浏览器兼容性问题与解决方案
2018年02月26日 11:44:36
阅读数:6098
常见浏览器兼容性问题与解决方案
所谓的浏览器兼容性问题,是指因为不同的浏览器对同一段代码有不同的解析,造成页面显示效果不统一的情况。在大多数情况下,我们的需求是,无论用户用什么浏览器来查看我们的网站或者登陆我们的系统,都应该是统一的显示效果。所以浏览器的兼容性问题是前端开发人员经常会碰到和必须要解决的问题。
在学习浏览器兼容性之前,我想把前端开发人员划分为两类:
第一类是精确按照设计图开发的前端开发人员,可以说是精确到1px的,他们很容易就会发现设计图的不足,并且在很少的情况下会碰到浏览器的兼容性问题,而这些问题往往都死浏览器的bug,并且他们制作的页面后期易维护,代码重用问题少,可以说是比较牢固放心的代码。
第二类是基本按照设计图来开发的前端开发人员,很多细枝末节差距很大,不如间距,行高,图片位置等等经常会差几px。某种效果的实现也是反复调试得到,具体为什么出现这种效果还模模糊糊,整体布局十分脆弱。稍有改动就乱七八糟。代码为什么这么写还不知所以然。这类开发人员往往经常为兼容性问题所困。修改好了这个浏览器又乱了另一个浏览器。改来改去也毫无头绪。其实他们碰到的兼容性问题大部分不应该归咎于浏览器,而是他们的技术本身了。
文章主要针对的是第一类,严谨型的开发人员,因此这里主要从浏览器解析差异的角度来分析兼容性问题。
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
W.SVP.ZU%9
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:CSS里 *
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设置各个标签的内外补丁是0。
浏览器兼容问题二:块属性标签float后,又有横行的margin情况下,在IE6显示margin比设置的大
问题症状:常见症状是IE6中后面的一块被顶到下一行
碰到频率:90%(稍微复杂点的页面都会碰到,float布局最常见的浏览器兼容问题)
解决方案:在float的标签样式控制中加入 display:inline;将其转化为行内属性
备注:我们最常用的就是div+CSS布局了,而div就是一个典型的块属性标签,横向布局的时候我们通常都是用div float实现的,横向的间距设置如果用margin实现,这就是一个必然会碰到的兼容性问题。
浏览器兼容问题三:设置较小高度标签(一般小于10px),在IE6,IE7,遨游中高度超出自己设置高度
问题症状:IE6、7和遨游里这个标签的高度不受控制,超出自己设置的高度
碰到频率:60%
解决方案:给超出高度的标签设置overflow:hidden;或者设置行高line-height 小于你设置的高度。
备注:这种情况一般出现在我们设置小圆角背景的标签里。出现这个问题的原因是IE8之前的浏览器都会给标签一个最小默认的行高的高度。即使你的标签是空的,这个标签的高度还是会达到默认的行高。
浏览器兼容问题四:行内属性标签,设置display:block后采用float布局,又有横行的margin的情况,IE6间距bug
问题症状:IE6里的间距比超过设置的间距
碰到几率:20%
解决方案:在display:block;后面加入display:inline;display:table;
备注:行内属性标签,为了设置宽高,我们需要设置display:block;(除了input标签比较特殊)。在用float布局并有横向的margin后,在IE6下,他就具有了块属性float后的横向margin的bug。不过因为它本身就是行内属性标签,所以我们再加上display:inline的话,它的高宽就不可设了。这时候我们还需要在display:inline后面加入display:talbe。
浏览器兼容问题五:图片默认有间距
问题症状:几个img标签放在一起的时候,有些浏览器会有默认的间距,加了问题一中提到的通配符也不起作用。
碰到几率:20%
解决方案:使用float属性为img布局
备注:因为img标签是行内属性标签,所以只要不超出容器宽度,img标签都会排在一行里,但是部分浏览器的img标签之间会有个间距。去掉这个间距使用float是正道。(我的一个学生使用负margin,虽然能解决,但负margin本身就是容易引起浏览器兼容问题的用法,所以我禁止他们使用)
浏览器兼容问题六:标签最低高度设置min-height不兼容
问题症状:因为min-height本身就是一个不兼容的CSS属性,所以设置min-height时不能很好的被各个浏览器兼容
碰到几率:5%
解决方案:如果我们要设置一个标签的最小高度200px,需要进行的设置为:{min-height:200px; height:auto !ImportAnt; height:200px; overflow:visible;}
备注:在B/S系统前端开时,有很多情况下我们又这种需求。当内容小于一个值(如300px)时。容器的高度为300px;当内容高度大于这个值时,容器高度被撑高,而不是出现滚动条。这时候我们就会面临这个兼容性问题。
浏览器兼容问题七:透明度的兼容CSS设置
做兼容页面的方法是:每写一小段代码(布局中的一行或者一块)我们都要在不同的浏览器中看是否兼容,当然熟练到一定的程度就没这么麻烦了。建议经常会碰到兼容性问题的新手使用。很多兼容性问题都是因为浏览器对标签的默认属性解析不同造成的,只要我们稍加设置都能轻松地解决这些兼容问题。如果我们熟悉标签的默认属性的话,就能很好的理解为什么会出现兼容问题以及怎么去解决这些兼容问题。
1. /* CSS hack*/
我很少使用hacker的,可能是个人习惯吧,我不喜欢写的代码IE不兼容,然后用hack来解决。不过hacker还是非常好用的。使用hacker我可以把浏览器分为3类:IE6 ;IE7和遨游;其他(IE8 Chrome ff Safari opera等)
◆IE6认识的hacker 是下划线_ 和星号 *
◆IE7 遨游认识的hacker是星号 *
比如这样一个CSS设置:
1. height:300px;*height:200px;_height:100px;
IE6浏览器在读到height:300px的时候会认为高时300px;继续往下读,他也认识*heihgt, 所以当IE6读到*height:200px的时候会覆盖掉前一条的相冲突设置,认为高度是200px。继续往下读,IE6还认识_height,所以他又会覆盖掉200px高的设置,把高度设置为100px;
IE7和遨游也是一样的从高度300px的设置往下读。当它们读到*height200px的时候就停下了,因为它们不认识_height。所以它们会把高度解析为200px,剩下的浏览器只认识第一个height:300px;所以他们会把高度解析为300px。因为优先级相同且想冲突的属性设置后一个会覆盖掉前一个,所以书写的次序是很重要的。
在网站设计的时候,应该注意css样式兼容不同浏览器问题,特别是对完全使用DIV CSS设计的网,就应该更注意IE6 IE7 FF对CSS样式的兼容,不然,你的网乱可能出去不想出现的效果!
所有浏览器 通用
height: 100px;
IE6 专用
_height: 100px;
IE6 专用
*height: 100px;
IE7 专用
*+height: 100px;
IE7、FF 共用
height: 100px !important;
一、CSS 兼容
以下两种方法几乎能解决现今所有兼容.
1, !important (不是很推荐,用下面的一种感觉最安全)
随着IE7对!important的支持, !important 方法现在只针对IE6的兼容.(注意写法.记得该声明位置需要提前.)
代码:
<style>
#wrapper {
width: 100px!important; /* IE7+FF */
width: 80px; /* IE6 */
}
</style>
2, IE6/IE77对FireFox <from 针对firefoxie6 ie7的css样式>
*+html 与 *html 是IE特有的标签, firefox 暂不支持.而*+html又为 IE7特有标签.
代码:
<style>
#wrapper { width: 120px; } /* FireFox */
*html #wrapper { width: 80px;} /* ie6 fixed */
*+html #wrapper { width: 60px;} /* ie7 fixed, 注意顺序 */
</style>
注意:
*+html 对IE7的兼容 必须保证HTML顶部有如下声明:
代码:
<!DOCTYPE HTML PUBLIC "-//W3C//DTDHTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
二、万能 float 闭合(非常重要!) 可以用这个解决多个div对齐时的间距不对,
关于 clear float 的原理可参见 [How ToClear Floats Without Structural Markup]
将以下代码加入Global CSS 中,给需要闭合的div加上 class=”clearfix” 即可,屡试不爽.
代码:
<style>
/* Clear Fix */
.clearfix:after {
content:".";
display:block;
height:0;
clear:both;
visibility:hidden;
}
.clearfix {
display:inline-block;
}
/* Hide from IE Mac \*/
.clearfix {display:block;}
/* End hide from IE Mac */
/* end of clearfix */
</style>
***********************************************************************************************************************
三、其他兼容技巧(相当有用)
1, FF下给 div 设置 padding 后会导致 width 和 height 增加, 但IE不会.(可用!important解决)
2, 居中问题.
1).垂直居中.将 line-height 设置为当前 div 相同的高度, 再通过 vetical-align: middle.( 注意内容不要换行.)
2).水平居中. margin: 0 auto;(当然不是万能)
3, 若需给 a 标签内内容加上 样式, 需要设置 display: block;(常见于导航标签)
4, FF 和 IE 对 BOX 理解的差异导致相差 2px 的还有设为 float的div在ie下 margin加倍等问题.
5, ul 标签在 FF 下面默认有 list-style 和 padding . 最好事先声明, 以避免不必要的麻烦. (常见于导航标签和内容列表)
6, 作为外部 wrapper 的 div 不要定死高度, 最好还加上 overflow: hidden.以达到高度自适应.
7, 关于手形光标. cursor: pointer. 而hand只适用于 IE.贴上代码:
兼容代码:兼容最推荐的模式。
/* FF */
.submitbutton {
float:left;
width: 40px;
height: 57px;
margin-top: 24px;
margin-right: 12px;
}
/* IE6 */
*html .submitbutton {
margin-top: 21px;
}
/* IE7 */
*+html .submitbutton {
margin-top: 21px;
}
什么是浏览器兼容:当我们使用不同的浏览器(Firefox IE7 IE6)访问同一个网站,或者页面的时候,会出现一些不兼容的问题,有的显示出来正常,有的显示出来不正常,我们在编写CSS的时候会很恼火,刚修复了这个浏览器的问题,结果另外一个浏览器却出了新问题。而兼容就是一种办法,能让你在一个CSS里面独立的写支持不同浏览器的样式。这下就和谐了。呵呵!
最近微软发布的IE7浏览器的兼容性确实给一些网页制 作人员添加了一个沉重的负担,虽然IE7已经走向标准化,但还是有许多和FF不同的地方,所以需要用到IE7的兼容,有许多朋友问过IE7的兼容是什么, 其实我也不知道。暂时还没找到IE7专用的兼容。除了前面那片文章,《针对firefox ie6 ie7的css样式》中的兼容方式也是很好用的。
有一点逻辑思想的人都会知道可以用IE和FF的兼容结合起来使用,下面介绍三个兼容,例如:(适合新手,呵呵,高手就在这里路过吧。)
程序代码
第一个兼容,IE FF 所有浏览器 公用(其实也不算是兼容)
height:100px;
第二个兼容 IE6专用
_height:100px;
第三个兼容 IE6 IE7公用
*height:100px;
介绍完了这三个兼容了,下面我们再来看看如何在一个样式里分别给一个属性定义IE6 IE7 FF专用的兼容,看下面的代码,顺序不能错哦:
程序代码
height:100px;
*height:120px;
_height:150px;
下面我简单解释一下各浏览器怎样理解这三个属性:
在FF下,第2、3个属性FF不认识,所以它读的是height:100px;
在IE7下,第三个属性IE7不认识,所以它读第1、2个属性,又因为第二个属性覆盖了第一个属性,所以IE7最终读出的是第2个属性*height:120px;
在IE6下,三个属性IE6都认识,所以三个属性都可以读取,又因为第三个属性覆盖掉前2个属性,所以IE6最终读取的是第三个属性。
1 针对firefox ie6 ie7的css样式
现在大部分都是用!important来兼容,对于ie6和firefox测试可以正常显示,但是ie7对!important可以正确解释,会导致页面 没按要求显示!找到一个针对IE7不错的兼容方式就是使用“*+html”,现在用IE7浏览一下,应该没有问题了现在写一个CSS可以这样:
#1 { color: #333; } /* Moz */
* html #1 { color: #666; } /* IE6 */
*+html #1 { color: #999; } /* IE*/
那么在firefox下字体颜色显示为#333,IE6下字体颜色显示为#666,IE7下字体颜色显示为#999。
2 css布局中的居中问题
主要的样式定义如下:
body {TEXT-ALIGN: center;}
#center { MARGIN-RIGHT: auto; MARGIN-LEFT: auto; }
说明:
首先在父级元素定义TEXT-ALIGN: center;这个的意思就是在父级元素内的内容居中;对于IE这样设定就已经可以了。
但在mozilla中不能居中。解决办法就是在子元素定义时候设定时再加上“MARGIN-RIGHT: auto;MARGIN-LEFT: auto; ”
需要说明的是,如果你想用这个方法使整个页面要居中,建议不要套在一个DIV里,你可以依次拆出多个div,只要在每个拆出的div里定义MARGIN-RIGHT:auto;MARGIN-LEFT: auto; 就可以了。
3 盒模型不同解释.
#box{
width:600px;
//for ie6.0- w\idth:500px;
//for ff+ie6.0
}
#box{
width:600px!important
//for ff
width:600px;
//for ff+ie6.0
width /**/:500px;
//for ie6.0-
}
4 浮动ie产生的双倍距离
#box{ float:left; width:100px; margin:0 0 0 100px; //这种情况之下IE会产生200px的距离display:inline; //使浮动忽略}
这里细说一下block,inline两个元素,Block元素的特点是:总是在新行上开始,高度,宽度,行高,边距都可以控制(块元素);Inline元素的特点是:和其他元素在同一行上,…不可控制(内嵌元素);
#box{ display:block; //可以为内嵌元素模拟为块元素 display:inline; //实现同一行排列的的效果 diplay:table;
5 IE与宽度和高度的问题
IE不认得min-这个定义,但实际上它把正常的width和height当作有min的情况来使。这样问题就大了,如果只用宽度和高度,正常的浏览器里这两个值就不会变,如果只用min-width和min-height的话,IE下面根本等于没有设置宽度和高度。比如要设置背景图片,这个宽度是比较重 要的。要解决这个问题,可以这样:
#box{ width: 80px; height: 35px;}html>body #box{width: auto; height: auto; min-width: 80px; min-height: 35px;}
6 页面的最小宽度
min-width是个非常方便的CSS命令,它可以指定元素最小也不能小于某个宽度,这样就能保证排版一直正确。但IE不认得这个,而它实际上把 width当做最小宽度来使。为了让这一命令在IE上也能用,可以把一个<div> 放到 <body> 标签下,然后为div指定一个类:
然后CSS这样设计:
#container{
min-width: 600px;
width:e-xpression(document.body.clientWidth < 600? “600px”: “auto” );
}
第一个min-width是正常的;但第2行的width使用了Javascript,这只有IE才认得,这也会让你的HTML文档不太正规。它实际上通过Javascript的判断来实现最小宽度。
7 清除浮动
.兼容box{
display:table;
//将对象作为块元素级的表格显示
}
或者
.兼容box{
clear:both;
}
或者加入:after(伪对象),设置在对象后发生的内容,通常和content配合使用,IE不支持此伪对象,非Ie 浏览器支持,所以并不影响到IE/WIN浏览器。这种的最麻烦的
……#box:after{
content: “.”;
display: block;
height: 0;
clear: both;
visibility: hidden;
}
8&nbp;DIV浮动IE文本产生3象素的bug
左边对象浮动,右边采用外补丁的左边距来定位,右边对象内的文本会离左边有3px的间距.
#box{
float:left;
width:800px;}
#left{
float:left;
width:50%;}
#right{
width:50%;
}
*html #left{
margin-right:-3px;
//这句是关键
}
HTML代码
<DIV id=box>
<DIV id=left></DIV>
<DIV id=right></DIV>
</DIV>
9 属性选择器(这个不能算是兼容,是隐藏css的一个bug)
p[id]{}div[id]{}
p[id]{}div[id]{}
这个对于IE6.0和IE6.0以下的版本都隐藏,FF和OPera作用
属性选择器和子选择器还是有区别的,子选择器的范围从形式来说缩小了,属性选择器的范围比较大,如p[id]中,所有p标签中有id的都是同样式的.
10 IE捉迷藏的问题
当div应用复杂的时候每个栏中又有一些链接,DIV等这个时候容易发生捉迷藏的问题。
有些内容显示不出来,当鼠标选择这个区域是发现内容确实在页面。
解决办法:对#layout使用line-height属性或者给#layout使用固定高和宽。页面结构尽量简单。
11 高度不适应
高度不适应是当内层对象的高度发生变化时外层高度不能自动进行调节,特别是当内层对象使用
margin 或paddign 时。例:
<div id=”box”>
<p>p对象中的内容</p>
</div>
CSS:
#box {background-color:#eee; }
#box p {margin-top: 20px;margin-bottom: 20px; text-align:center; }
解决方法:在P对象上下各加2个空的div对象CSS代码:.1{height:0px;overflow:hidden;}或者为DIV加上border属性。
屏蔽IE浏览器(也就是IE下不显示)
*:lang(zh) select {font:12px !important;} /*FF,OP可见*/
select:empty {font:12px !important;} /*safari可见*/
这里select是选择符,根据情况更换。第二句是MAC上safari浏览器独有的。
仅IE7识别
*+html {…}
当面临需要只针对IE7做样式的时候就可以采用这个兼容。
IE6及IE6以下识别
* html {…}
这个地方要特别注意很多地主都写了是IE6的兼容其实IE5.x同样可以识别这个兼容。其它浏览器不识别。
html/**/ >body select {……}
这句与上一句的作用相同。
仅IE6不识别
select { display /*IE6不识别*/:none;}
这里主要是通过CSS注释分开一个属性与值,流释在冒号前。
仅IE6与IE5不识别
select/**/ { display /*IE6,IE5不识别*/:none;}
这里与上面一句不同的是在选择符与花括号之间多了一个CSS注释。
仅IE5不识别
select/*IE5不识别*/ { display:none;}
这一句是在上一句中去掉了属性区的注释。只有IE5不识别
盒模型解决方法
selct {width:IE5.x宽度; voice-family:""}""; voice-family:inherit; width:正确宽度;}
盒模型的清除方法不是通过!important来处理的。这点要明确。
清除浮动
select:after {content:"."; display:block; height:0; clear:both;visibility:hidden;}
在Firefox中,当子级都为浮动时,那么父级的高度就无法完全的包住整个子级,那么这时用这个清除浮动的兼容来对父级做一次定义,那么就可以解决这个问题。
截字省略号
select { -o-text-overflow:ellipsis; text-overflow:ellipsis;white-space:nowrapoverflow:hidden; }
这个是在越出长度后会自行的截掉多出部分的文字,并以省略号结尾,很好的一个技术。只是目前Firefox并不支持。
只有Opera识别
@media all and (min-width: 0px){ select {……} }
针对Opera浏览器做单独的设定。
以上都是写CSS中的一些兼容,建议遵循正确的标签嵌套(divul li 嵌套结构关系),这样可以减少你使用兼容的频率,不要进入理解误区,并不是一个页面就需要很多的兼容来保持多浏览器兼容),很多情况下也许一个兼容都不用 也可以让浏览器工作得非常好,这些都是用来解决局部的兼容性问题,如果希望把兼容性的内容也分离出来,不妨试一下下面的几种过滤器。这些过滤器有的是写在 CSS中通过过滤器导入特别的样式,也有的是写在HTML中的通过条件来链接或是导入需要的补丁样式。
IE5.x的过滤器,只有IE5.x可见
@media tty {
i{content:"";/*" "*/}} @import ’ie5win.css’; /*";}
}/* */
IE5/MAC的过滤器,一般用不着
/**//*/
@import "ie5mac.css";
/**/
下面是IE的条件注释,个人觉得用条件注释调用相应 兼容是比较完美的多浏览器兼容的解决办法。把需要兼容的地方单独放到一个文件里面,当浏览器版本符合的时候就可以调用那个被兼容的样式,这样不仅使用起来非常方便,而且对于制作这个CSS本身来讲,可以更严格的观察到是否有必要使用兼容,很多情况下,当我本人写CSS如果把全部代码包括兼容都写到一个 CSS文件的时候的时候会很随意,想怎么兼容就怎么兼容,而你独立出来写的时候,你就会不自觉的考虑是否有必要兼容,是先兼容 CSS?还是先把主CSS里面的东西调整到尽可能的不需要兼容?当你仅用很少的兼容就让很多浏览器很乖很听话的时候,你是不是很有成就感呢?你知道怎么选择了吧~~呵呵
IE的if条件兼容 自己可以灵活使用参看这篇IE条件注释
Only IE
所有的IE可识别
只有IE5.0可以识别
Only IE 5.0+
IE5.0包换IE5.5都可以识别
仅IE6可识别
Only IE 7/-
IE6以及IE6以下的IE5.x都可识别
Only IE 7/-
仅IE7可识别
Css 当中有许多的东西不不按照某些规律来的话,会让你很心烦,虽然你可以通过很多的兼容,很多的!important来控制它,但是你会发现长此以往你会很不甘心,看看许多优秀的网站,他们的CSS让IE6,Ie7,Firefox,甚至Safari,Opera运行起来完美无缺是不是很羡慕?而他们看似复杂的模版下面使用的兼容少得可怜。其实你要知道IE 和 Firefox 并不不是那么的不和谐,我们找到一定的方法,是完全可以让他们和谐共处的。不要你认为发现了兼容的办法,你就掌握了一切,我们并不是兼容的奴隶。
div ul li 的嵌套顺序
今天只讲一个规则。就是<div><ul><li>的三角关系。我的经验就是<div>在最外面,里面 是<ul>,然后再是<li>,当然<li>里面又可以嵌套<div>什么的,但是并不建议你嵌套很多 东西。当你符合这样的规则的时候,那些倒霉的,不听话的间隙就不会在里面出现了,当你仅仅是<div>里面放<li>,而不 用<ul>的时候,你会发现你的间隙十分难控制,一般情况下,IE6和IE7会凭空多一些间距。但很多情况你来到下一行,间隙就没了,但是前 面的内容又空了很大一块,出现这种情况虽然你可以改变IE的Margin,然后调整Firefox下面的Padding,以便使得两者显示起来得效果很相 似,但是你得CSS将变得臭长无比,你不得不多考虑更多可能出现这种问题补救措施,虽然你知道千篇一律来兼容它们,但是你会烦得要命。
具体嵌套写法
遵循上面得嵌套方式,<div><ul><li></li></ul></div>然后在CSS 里面告诉 ul {Margin:0pxadding:0px;list- style:none;},其中list-style:none是不让<li>标记的最前方显示圆点或者数字等目录类型的标记,因为IE和 Firefox显示出来默认效果有些不一样。因此这样不需要做任何手脚,你的IE6、和IE7、Firefox显示出来的东西(外距,间距,高度,宽度) 就几乎没什么区别了,也许细心的你会在某一个时刻发现一、两个象素的差别,但那已经很完美了,不需要你通过调整大片的CSS来控制它们的显示了,你愿意, 你可以仅仅兼容一两个地方,而且通常这种兼容可以适应各种地方,不需要你重复在不同的地方调试不同的兼容方式–减轻你的烦 overflow:hidden; }
这个是在越出长度后会自行的截掉多出部分的文字,并以省略号结尾,很好的一个技术。只是目前Firefox并不支持。
只有Opera识别
@media all and (min-width: 0px){ select {……} }
针对Opera浏览器做单独的设定。
以上都是写CSS中的一些兼容,建议遵循正确的标签嵌套(divul li 嵌套结构关系),这样可以减少你使用兼容的频率,不要进入理解误区,并不是一个页面就需要很多的兼容来保持多浏览器兼容),很多情况下也许一个兼容都不用 也可以让浏览器工作得非常好,这些都是用来解决局部的兼容性问题,如果希望把兼容性的内容也分离出来,不妨试一下下面的几种过滤器。这些过滤器有的是写在 CSS中通过过滤器导入特别的样式,也有的是写在HTML中的通过条件来链接或是导入需要的补丁样式。
IE5.x的过滤器,只有IE5.x可见
@media tty {
i{content:"";/*" "*/}} @import ’ie5win.css’; /*";}
}/* */
IE5/MAC的过滤器,一般用不着
/**//*/
@import "ie5mac.css";
/**/
下面是IE的条件注释,个人觉得用条件注释调用相应 兼容是比较完美的多浏览器兼容的解决办法。把需要兼容的地方单独放到一个文件里面,当浏览器版本符合的时候就可以调用那个被兼容的样式,这样不仅使用起来非常方便,而且对于制作这个CSS本身来讲,可以更严格的观察到是否有必要使用兼容,很多情况下,当我本人写CSS如果把全部代码包括兼容都写到一个 CSS文件的时候的时候会很随意,想怎么兼容就怎么兼容,而你独立出来写的时候,你就会不自觉的考虑是否有必要兼容,是先兼容 CSS?还是先把主CSS里面的东西调整到尽可能的不需要兼容?当你仅用很少的兼容就让很多浏览器很乖很听话的时候,你是不是很有成就感呢?你知道怎么选择了吧~~呵呵
IE的if条件兼容 自己可以灵活使用参看这篇IE条件注释
Only IE
所有的IE可识别
只有IE5.0可以识别
Only IE 5.0+
IE5.0包换IE5.5都可以识别
仅IE6可识别
Only IE 7/-
IE6以及IE6以下的IE5.x都可识别
Only IE 7/-
仅IE7可识别
Css 当中有许多的东西不不按照某些规律来的话,会让你很心烦,虽然你可以通过很多的兼容,很多的!important来控制它,但是你会发现长此以往你会很不甘心,看看许多优秀的网站,他们的CSS让IE6,Ie7,Firefox,甚至Safari,Opera运行起 来完美无缺是不是很羡慕?而他们看似复杂的模版下面使用的兼容少得可怜。其实你要知道IE 和 Firefox 并不不是那么的不和谐,我们找到一定的方法,是完全可以让他们和谐共处的。不要你认为发现了兼容的办法,你就掌握了一切,我们并不是兼容的奴隶。
div ul li 的嵌套顺序
今天只讲一个规则。就是<div><ul><li>的三角关系。我的经验就是<div>在最外面,里面 是<ul>,然后再是<li>,当然<li>里面又可以嵌套<div>什么的,但是并不建议你嵌套很多 东西。当你符合这样的规则的时候,那些倒霉的,不听话的间隙就不会在里面出现了,当你仅仅是<div>里面放<li>,而不 用<ul>的时候,你会发现你的间隙十分难控制,一般情况下,IE6和IE7会凭空多一些间距。但很多情况你来到下一行,间隙就没了,但是前 面的内容又空了很大一块,出现这种情况虽然你可以改变IE的Margin,然后调整Firefox下面的Padding,以便使得两者显示起来得效果很相 似,但是你得CSS将变得臭长无比,你不得不多考虑更多可能出现这种问题补救措施,虽然你知道千篇一律来兼容它们,但是你会烦得要命。
具体嵌套写法
遵循上面得嵌套方式,<div><ul><li></li></ul></div>然后在CSS 里面告诉 ul{Margin:0pxadding:0px;list- style:none;},其中list-style:none是不让<li>标记的最前方显示圆点或者数字等目录类型的标记,因为IE和 Firefox显示出来默认效果有些不一样。因此这样不需要做任何手脚,你的IE6、和IE7、Firefox显示出来的东西(外距,间距,高度,宽度) 就几乎没什么区别了,也许细心的你会在某一个时刻发现一、两个象素的差别,但那已经很完美了,不需要你通过调整大片的CSS来控制它们的显示了,你愿意, 你可以仅仅兼容一两个地方,而且通常这种兼容可以适应各种地方,不需要你重复在不同的地方调试不同的兼容方式–减轻你的烦 overflow:hidden; }
这个是在越出长度后会自行的截掉多出部分的文字,并以省略号结尾,很好的一个技术。只是目前Firefox并不支持。
只有Opera识别
@media all and (min-width: 0px){ select {……} }
针对Opera浏览器做单独的设定。
以上都是写CSS中的一些兼容,建议遵循正确的标签嵌套(divul li 嵌套结构关系),这样可以减少你使用兼容的频率,不要进入理解误区,并不是一个页面就需要很多的兼容来保持多浏览器兼容),很多情况下也许一个兼容都不用 也可以让浏览器工作得非常好,这些都是用来解决局部的兼容性问题,如果希望把兼容性的内容也分离出来,不妨试一下下面的几种过滤器。这些过滤器有的是写在 CSS中通过过滤器导入特别的样式,也有的是写在HTML中的通过条件来链接或是导入需要的补丁样式。
IE5.x的过滤器,只有IE5.x可见
@media tty {
i{content:"";/*" "*/}} @import ’ie5win.css’; /*";}
}/* */
IE5/MAC的过滤器,一般用不着
/**//*/
@import "ie5mac.css";
/**/
下面是IE的条件注释,个人觉得用条件注释调用相应 兼容是比较完美的多浏览器兼容的解决办法。把需要兼容的地方单独放到一个文件里面,当浏览器版本符合的时候就可以调用那个被兼容的样式,这样不仅使用起来非常方便,而且对于制作这个CSS本身来讲,可以更严格的观察到是否有必要使用兼容,很多情况下,当我本人写CSS如果把全部代码包括兼容都写到一个 CSS文件的时候的时候会很随意,想怎么兼容就怎么兼容,而你独立出来写的时候,你就会不自觉的考虑是否有必要兼容,是先兼容 CSS?还是先把主CSS里面的东西调整到尽可能的不需要兼容?当你仅用很少的兼容就让很多浏览器很乖很听话的时候,你是不是很有成就感呢?你知道怎么选择了吧~~呵呵
IE的if条件兼容 自己可以灵活使用参看这篇IE条件注释
Only IE
所有的IE可识别
只有IE5.0可以识别
Only IE 5.0+
IE5.0包换IE5.5都可以识别
仅IE6可识别
Only IE 7/-
IE6以及IE6以下的IE5.x都可识别
Only IE 7/-
仅IE7可识别
Css 当中有许多的东西不不按照某些规律来的话,会让你很心烦,虽然你可以通过很多的兼容,很多的!important来控制它,但是你会发现长此以往你会很不甘心,看看许多优秀的网站,他们的CSS让IE6,Ie7,Firefox,甚至Safari,Opera运行起 来完美无缺是不是很羡慕?而他们看似复杂的模版下面使用的兼容少得可怜。其实你要知道IE 和 Firefox 并不不是那么的不和谐,我们找到一定的方法,是完全可以让他们和谐共处的。不要你认为发现了兼容的办法,你就掌握了一切,我们并不是兼容的奴隶。
div ul li 的嵌套顺序
今天只讲一个规则。就是<div><ul><li>的三角关系。我的经验就是<div>在最外面,里面 是<ul>,然后再是<li>,当然<li>里面又可以嵌套<div>什么的,但是并不建议你嵌套很多 东西。当你符合这样的规则的时候,那些倒霉的,不听话的间隙就不会在里面出现了,当你仅仅是<div>里面放<li>,而不 用<ul>的时候,你会发现你的间隙十分难控制,一般情况下,IE6和IE7会凭空多一些间距。但很多情况你来到下一行,间隙就没了,但是前 面的内容又空了很大一块,出现这种情况虽然你可以改变IE的Margin,然后调整Firefox下面的Padding,以便使得两者显示起来得效果很相 似,但是你得CSS将变得臭长无比,你不得不多考虑更多可能出现这种问题补救措施,虽然你知道千篇一律来兼容它们,但是你会烦得要命。
具体嵌套写法
遵循上面得嵌套方式,<div><ul><li></li></ul></div>然后在CSS 里面告诉 ul {Margin:0pxadding:0px;list- style:none;},其中list-style:none是不让<li>标记的最前方显示圆点或者数字等目录类型的标记,因为IE和 Firefox显示出来默认效果有些不一样。因此这样不需要做任何手脚,你的IE6、和IE7、Firefox显示出来的东西(外距,间距,高度,宽度) 就几乎没什么区别了,也许细心的你会在某一个时刻发现一、两个象素的差别,但那已经很完美了,不需要你通过调整大片的CSS来控制它们的显示了,你愿意, 你可以仅仅兼容一两个地方,而且通常这种兼容可以适应各种地方,不需要你重复在不同的地方调试不同的兼容方式–减轻你的烦。你可以ul.class1, ul.class2, ul.class3{xxx:xxxx}的方式方便的整理出你要兼容的地方,而统一兼容。尝试一下吧,再也不要乱嵌套了,虽然在Div+CSS的方式下你几乎可以想怎么嵌套就怎么嵌套,但是按照上面的规律你将轻松很多,从而事半功倍!
去掉ie有默认最低高度
<div style="height:2px;background:red;overflow:hidden;"></div>
其中height:2px为你要设的高度,overflow:hidden最为关键,他就是帮你去掉默认高度
随着最新CSS的不断完善,越来越多的网站采用DIV+CSS布局。而原来使用table套 table的网页布局模式也逐渐应该淘汰了。由于目前IE6不能支持有些标准的CSS,需要用微软特有的CSS来修复这些BUG.而且现在随着浏览器层出不穷,要是页面能够适应尽量多的浏览器成为一个课题。 但是随着CSS标准的进一步完善,浏览器将最终都会遵循这个标准,到时候写DIV+CSS布局的页 面就不那么麻烦了。
但是现在,我们还是需要处理CSS在不同浏览器下的兼容性。一下是一个网友写的CSS兼容技巧,值得大家参考。
CSS兼容技巧
1 FF下给 div 设置 padding 后会导致 width 和 height 增加, 但IE不会.
可用important解决
2 居中问题.
1).垂直居中.将 line-height 设置为 当前 div 相同的高度, 再通过vertical-align: middle.( 注意内容不要换行.)
2).水平居中. margin: 0 auto;(当然不是万能)
3 若需给 a 标签内内容加上样式, 需要设置 display: block;(常见于导航标签)
4 FF 和 IE 对 BOX 理解的差异导致相差 2px 的还有设为 float的div在ie下 margin加倍等问题.
5 ul 标签在 FF 下面默认有list-style 和 padding . 最好事先声明, 以避免不必要的麻烦. (常见于导航标签和内容列表)
6 作为外部 wrapper 的 div 不要定死高度, 最好还加上 overflow: hidden.以达到高度自适应.
7 关于手形光标. cursor: pointer. 而hand 只适用于 IE.
针对firefox ie6 ie7的css样式
现在大部分都是用!important来hack,对于ie6和firefox测试可以正常显示,
但是ie7对!important可以正确解释,会导致页面没按要求显示!找到一个针
对IE7不错的hack方式就是使用“*+html”,现在用IE7浏览一下,应该没有问题了。
现在写一个CSS可以这样:
#1 { color: #333; } /* Moz */
* html #1 { color: #666; } /* IE6*/
*+html #1 { color: #999; } /* IE7*/
那么在firefox下字体颜色显示为#333,IE6下字体颜色显示为#666,IE7下字体颜色显示为#999。
css布局中的居中问题
主要的样式定义如下:
body {TEXT-ALIGN: center;}
#center { MARGIN-RIGHT: auto;MARGIN-LEFT: auto; }
说明:
首先在父级元素定义TEXT-ALIGN: center;这个的意思就是在父级元素内的内容居中;对于IE这样设定就已经可以了。
但在mozilla中不能居中。解决办法就是在子元素定义时候设定时再加上“MARGIN-RIGHT: auto;MARGIN-LEFT: auto; ”
需要说明的是,如果你想用这个方法使整个页面要居中,建议不要套在一个DIV里,你可以依次拆出多个div,
只要在每个拆出的div里定义MARGIN-RIGHT: auto;MARGIN-LEFT: auto; 就可以了。
盒模型不同解释
#box{ width:600px; //for ie6.0-w/idth:500px; //for ff+ie6.0}
#box{ width:600px!important //forff width:600px; //for ff+ie6.0 width /**/:500px; //for ie6.0-}
浮动ie产生的双倍距离
#box{ float:left; width:100px;margin:0 0 0 100px; //这种情况之下IE会产生200px的距离 display:inline; //使浮动忽略}
这里细说一下block,inline两个元素,Block元素的特点是:总是在新行上开始,高度,宽度,行高,边距都可以控制(块元素);Inline元素的特点是:和其他元素在同一行上,…不可控制(内嵌元素);
#box{ display:block; //可以为内嵌元素模拟为块元素 display:inline; //实现同一行排列的的效果 diplay:table;
IE不认得min-这个定义,但实际上它把正常的width和height当作有min的情况来使。这样问题就大了,如果只用宽度和高度,
正常的浏览器里这两个值就不会变,如果只用min-width和min-height的话,IE下面根本等于没有设置宽度和高度。
比如要设置背景图片,这个宽度是比较重要的。要解决这个问题,可以这样:
#box{ width: 80px; height:35px;}html>body #box{ width: auto; height: auto; min-width: 80px;min-height: 35px;}
页面的最小宽度
min-width是个非常方便的CSS命令,它可以指定元素最小也不能小于某个宽度,这样就能保证排版一直正确。但IE不认得这个,
而它实际上把width当做最小宽度来使。为了让这一命令在IE上也能用,可以把一个
放到 标签下,然后为div指定一个类:
然后CSS这样设计:
#container{ min-width: 600px;width:expression(document.body.clientWidth < 600? “600px”: “auto” );}
第一个min-width是正常的;但第2行的width使用了Javascript,这只有IE才认得,这也会让你的HTML文档不太正规。它实际上通过Javascript的判断来实现最小宽度。
清除浮动
.hackbox{ display:table; //将对象作为块元素级的表格显示}或者.hackbox{ clear:both;}
或者加入:after(伪对象),设置在对象后发生的内容,通常和content配合使用,IE不支持此伪对象,非Ie 浏览器支持,
所 以并不影响到IE/WIN浏览器。这种的最麻烦的……#box:after{ content: “.”; display: block; height: 0; clear: both; visibility: hidden;}
DIV浮动IE文本产生3象素的bug
左边对象浮动,右边采用外补丁的左边距来定位,右边对象内的文本会离左边有3px的间距.
#box{ float:left;width:800px;}#left{ float:left; width:50%;}#right{ width:50%;}*html #left{margin-right:-3px; //这句是关键}
HTML代码
属性选择器(这个不能算是兼容,是隐藏css的一个bug)
p[id]{}div[id]{}
这个对于IE6.0和IE6.0以下的版本都隐藏,FF和OPera作用
属性选择器和子选择器还是有区别的,子选择器的范围从形式来说缩小了,属性选择器的范围比较大,如p[id]中,所有p标签中有id的都是同样式的.
IE捉迷藏的问题
当div应用复杂的时候每个栏中又有一些链接,DIV等这个时候容易发生捉迷藏的问题。
有些内容显示不出来,当鼠标选择这个区域是发现内容确实在页面。
解决办法:对#layout使用line-height属性或者给#layout使用固定高和宽。页面结构尽量简单。
高度不适应
高度不适应是当内层对象的高度发生变化时外层高度不能自动进行调节,特别是当内层对象使用
margin 或paddign时。
例:
p对象中的内容
CSS:#box{background-color:#eee; }
#box p {margin-top:20px;margin-bottom: 20px; text-align:center; }
解决方法:在P对象上下各加2个空的div对象CSS代码:.1{height:0px;overflow:hidden;}或者为DIV加上border属性。
一、超链接点击过后hover样式就不出现的问题?
被点击访问过的超链接样式不再具有hover和active样式了,解决方法是改变CSS属性的排列顺序: L-V-H-A
二、IE6的margin双倍边距bug问题
例如:
|
|
浮动后本来外边距10px,但IE解释为20px,解决办法是加上display:inline;
三、为什么中火狐浏览器下文本无法撑开容器的高度?
标准浏览器中固定高度值的容器是不会象IE6里那样被撑开的,那我又想固定高度,又想能被撑开需要怎样设置呢?办法就是去掉height设置min-height:200px; 这里为了照顾不认识min-height的IE6 可以这样定义:
| div { height:auto!important; height:200px; min-height:200px; } |
四、为什么web标准中无法设置IE浏览器滚动条颜色了?
原来样式设置:
|
|
解决办法是将body换成html
五、如何定义1px左右高度的容器?
IE6下这个问题是因为默认的行高造成的,解决的方法也有很多,例如:overflow:hidden | zoom:0.08 | line-height:1px
六、怎么样才能让层显示在FLASH之上呢?
解决的办法是给FLASH设置透明:
| <a href="http://www.chinaz.com/">:</a> |
七、怎样使一个div层居中于浏览器中?
|
|
这里使用百分比绝对定位,与外补丁负值的方法,负值的大小为其自身宽度高度除以二
八、firefox浏览器中嵌套div标签的居中问题的解决方法
假定有如下情况:
|
|
如果要实现b在a中居中放置,一般只需用CSS设置a的text-align属性为center。这样的方法在IE里看起来一切正常;但是在Firefox中b却会是居左的。
解决办法就是设置b的横向margin为auto。例如设置b的CSS样式为:margin: 0 auto;
浏览器的内核
Mozilla Firefox ( Gecko )
Internet Explorer ( Trident )
Opera ( Presto )
Safari ( WebKit )
Google Chrome ( WebKit )
腾讯TT、世界之窗、360浏览器、遨游浏览器都是给IE加了个外壳,不过如果电脑上装的是ie8的话,这些浏览器还是调用ie7的内核。搜狗浏览器比较特殊,它有两种浏览模式:一是兼容模式,该模式使用IE内核;二是高速模式,该模式使用WebKit内核。解决ie7、ie8兼容性最好的办法是在head标签中加入meta 类型<metahttp-equiv="X-UA-Compatible" content="IE=EmulateIE7" />,只要IE8一读到这个标签,它就会自动启动IE7兼容模式
CSSHack
解决浏览器兼容性问题的主要方法是CSS hack。由于不同的浏览器,比如Internet Explorer 6,Internet Explorer 7,Mozilla Firefox等,对CSS的解析认识不一样,因此会导致生成的页面效果不一样,得不到我们所需要的页面效果。这个时候我们就需要针对不同的浏览器去写不同的CSS,让它能够同时兼容不同的浏览器,能在不同的浏览器中也能得到我们想要的页面效果。这个针对不同的浏览器写不同的CSS code的过程,就叫CSS hack,也叫写CSS hack。
CSS Hack的原理是什么
由于不同的浏览器对CSS的支持及解析结果不一样,还由于CSS中的优先级的关系。我们就可以根据这个来针对不同的浏览器来写不同的CSS。比如 IE6能识别下划线"_"和星号" * ",IE7能识别星号" * ",但不能识别下划线"_",而firefox两个都不能认识。等等
各浏览器CSS hack兼容表:
|
| IE6 | IE7 | IE8 | Firefox | Opera | Safari |
| !important |
| Y | Y | Y | Y | Y |
| _ | Y |
|
|
|
|
|
| * | Y | Y |
|
|
|
|
| *+ |
| Y |
|
|
|
|
| \9 | Y | Y | Y |
|
|
|
| \0 |
|
| Y |
|
|
|
| nth-of-type(1) |
|
|
|
| Y | Y |
如何解决浏览器的兼容性
在head标签中加入meta 类型<meta http-equiv="X-UA-Compatible"content="IE=EmulateIE7" />,这样就解决了ie7、ie8兼容问题。现在剩下ie6、ie7、Firefox、Chrome(Safari与Chrome使用同一内核)、Opera这几种浏览器的兼容性问题,我们需要使用CSS Hack来解决该问题。代码如下所示:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<head>
<meta http-equiv="Content-Type"content="text/html; charset=utf-8" />
<meta http-equiv="X-UA-Compatible"content="IE=EmulateIE7" />
<title>浏览器兼容性问题</title>
<style type="text/css">
.t1
{
color:#000000; /*所有浏览器都支持 此处填写Firefox的css*/
*color:#0000FF;/* ie6 id7 支持此处填写ie7的css*/
_color:#66CCCC;/* ie6支持 此处填写ie6的css*/
}
@media all and (-webkit-min-device-pixel-ratio:10000),not all and (-webkit-min-device-pixel-ratio:0)
{ .t1{color:#9900FF}} /* oprea支持 此处填写oprea的css*/
@media screen and (-webkit-min-device-pixel-ratio:0)
{
.t1{color:#336600}/* Chrome、Safari支持 此处填写Chrome的css*/
}
</style>
</head>
<body>
<div class="t1">ff、ie8、ie7、ie6、oprea、Safari兼容性css 书写模式<br>
.t1{
color:#000000; /*所有浏览器都支持 此处填写Firefox的css**/<br>
*color:#0000FF;/* ie6 id7 支持此处填写ie7的css*/<br>
_color:#66CCCC;/* ie6支持 此处填写ie6的css*/<br>
}<br>
/* oprea支持此处填写oprea的css*/<br>
@media all and (-webkit-min-device-pixel-ratio:10000),not all and (-webkit-min-device-pixel-ratio:0)<br>
{ .t1{color:#CC66FF}}<br>
/* Chrome、Safari支持 此处填写Chrome的css*/<br>
@media screen and (-webkit-min-device-pixel-ratio:0)
{
.t1{color:#336600}}
}
</div>
</div>
</body>
</html>
常见的浏览器兼容问题
Css样式是与DOCTYPE引入的W3C//DTD有关的,不同的dtd对css的解析也不同,我们现在统一使用<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
css兼容问题:
1. 默认的内外边距不同
问题:
各个浏览器默认的内外边距不同
解决:
*{margin:0;padding:0;}
2. 水平居中的问题
问题:
设置 text-align: center
ie6-7文本居中,嵌套的块元素也会居中
ff /opera /safari /ie8文本会居中,嵌套块不会居中
解决:
块元素设置
1、margin-left:auto;margin-right:auto
2、margin:0 auto;
3、<div align=”center”></div>
3. 垂直居中的问题
问题:
在浏览器中 想要垂直居中,设置vertical-align:middle; 不起作用。例如:ie6下文本与文本输入框对不齐,需设置vertical-align:middle,但是文本框的内容不会垂直居中
解决:
给容器设置一个与其高度相同的行高
line-height:与容器的height一样
4. 关于高度问题
问题:
如果是动态地添加内容,高度最好不要定义。浏览器可以自动伸缩,然而如果是静态的内容,高度最好定好。
如果设定了高度,内容过多时,ie6下会自动增加高度、其他浏览器会超出边框
解决:
1.设置overflow:hidden;
2.高度自增height:auto!important;height:100px;
5. IE6 默认的div高度
问题:
ie6默认div高度为一个字体显示的高度,所在ie6下div的高度大于等于一个字的高度,因此在ie6下定义高度为1px的容器,显示的是一个字体的高度
解决:
为这个容器设置下列属性之一
1、设置overflow:hidden;
2、设置line-height:1px;
3、设置zoom:0.08
6. IE6 最小高度(宽度)的问题
问题:
ie6不支持min-height、min-width属性,默认height是最小高度,width是最小宽度。
解决:
使用ie6不支持但其余浏览器支持的属性!important。
设置属性min-height:200px; height:auto !important;height:200px;
7. td高度的问题
问题:
table中td的宽度都不包含border的宽度,但是oprea和ff中td的高度包含了border的高度
解决:
设置line-height和height一样。在ie中如果td中的没有内容,那么border将不会显示
8. div嵌套p时,出现空白行
问题:
div中显示<p>文本</p>,ff、oprea、Chrome:top和bottom都会出现空白行,但是在ie下不会出现空白行。
解决:
设置p的margin:0px,再设置div的padding-top和padding-bottom
9. IE6-7图片下面有空隙的问题
问题:
块元素中含有图片时,ie6-7中会出现图片下有空隙
解决:
1、在源代码中让</div>和<img>在同一行
2、将图片转换为块级对象display:block;
3、设置图片的垂直对齐方式 vertical-align:top/middle/bottom
4、改变父对象的属性,如果父对象的宽、高固定,图片大小随父对象而定,那么可以对父元素设置:overflow:hidden;
5、设置图片的浮动属性 float:left;
10. IE6双倍边距的问题
问题:
ie6中设置浮动,同时又设置margin时,会出现双倍边距的问题
例float:left;width:100px;margin:0 100px;
解决:
设置display:inline;
11. IE6 weidth为奇数,右边多出1px的问题
问题:
父级元素采用相对定位,且宽度设置为奇数时,子元素采用绝对定位,在ie6中会出现右侧多出1像素
解决:
将宽度的奇数值改成偶数
12. IE6两个层之间3px的问题
问题:
左边层采用浮动,右边没有采用浮动,这时在ie6中两层之间就会产生3像素的间距
解决:
1、右边层也采用浮动 float
2、左边层添加属性 margin-right:-3px;
13. IE6 子元素绝对定位的问题
问题:
父级元素使用padding后,子元素使用绝对定位,不能精确定位
解决:
在子元素中设置 _left:-20px; _top:-1px;
14. 显示手型cursor:hand
问题:
ie6/7/8、opera 都支持 但是safari 、 ff 不支持
解决:
写成 cursor:pointer; (所有浏览器都能识别)
15. IE6-7 line-height失效的问题
问题:
在ie中img与文字放一起时, line-height不起作用
解决:
都设置成float
16. td自动换行的问题
问题:
Table宽度固定,td自动换行
解决:
设置Table的table-layout:fixed,td的word-wrap:break-word
17. 子容器浮动后,父容器扩展问题
问题:
子容器都float以后,父容器没有设定高度,父容器将不会扩展
解决:
只需要添加一个clear:both的div,代码如下:
<div style="border:1px solid#333;width:204px">
<divstyle="width:100px;border:1px solid #333; float:left; ">子容器a</div>
<divstyle="width:100px;border:1px solid #333; float:left;">子容器b</div>
<divstyle="clear:both"></div>
</div>
18. 透明png图片会带背景色
问题:
在ie6下透明的png图片会带一个背景色
解决:
background-image: url(icon_home.png);/* 其他浏览器 */
background-repeat: no-repeat;
_filter:progid:DXImageTransform.Microsoft.AlphaImageLoader(src='icon_home.png');/* IE6 */
_background-image: none; /* IE6 */
19. list-style-position默认值的问题
问题:
ie下list-style-position默认为inside, firefox默认为outside
解决:
css中指定为outside即可解决兼容性问题
20. list-style-image准确定位的问题
问题:
li前设置图片时,图片与其后的文字对齐问题
解决:
1、采用背景定位 和 字符缩进的方法
background:url() no-repeat left center;text-index:16px;
2、采用相对定位方法
li 设置list-style:url();
li的子元素position:relative;top:-5px;
21. ul标签默认值的问题
问题:
ul标签在ff中默认是有padding值的,而在ie中只有margin有值
解决:
定义ul{margin:0;padding:0;}就能解决大部分问题
22. IE中li指定高度后,出现排版错误
问题:
在ie下如果为li指定高度可能会出现排版错位
解决:
设置line-height
23. ul或li浮动后,显示在div外
问题:
div中的ul或li设置float以后,都不在div中
解决:
必须在ul标签后加<divstyle="clear:both"></div>来闭合外层div
24. ul浮动后,margin变大
问题:
ul设置 float后,在ie中margin将变大
解决:
设置ul的display:inline,li的list-style-position:outside
25. li浮动后,margin变大
问题:
li设置 float后,在ie中margin将变大
解决:
设置li的display:inline
26. 嵌套使用ul、li的问题
问题:
ie的bug,嵌套使用ul、li时,里层的li设置float以后,外层li不设置float, 里面的ul顶部和它外面的li总是有一段间距
解决:
设置里面的ul的zoom:1
27. IE6-7 li底部有3px的问题
问题:
这个bug产生的充要条件是li的子元素浮动并且li设置了以下CSS属性之一:width、height、zoom、padding-top、padding-bottom、margin-top、margin-bottom。
解决:
1、div设置clear:left|both,这时li不能设置width、height、zoom。
2、li设置float:left,这时li可以设置width、height、zoom。
3、li设置clear:left|both,这时li不能设置width、height、zoom。
4、IE6/IE7的这个Bug可以通过给li中的div设置vertical-align:top|middle|bottom解决。
28. IE6 垂直列表间隙的问题
问题:
li中有a且设置display:block时,ie6中列表间会出现空隙
解决:
1、li中加display:inline;
2、li使用float 然后 clear:both;
3、给包含的文本末尾添加一个空格
4、设置width
29. IE6 列表背景颜色失效的问题
问题:
当父元素设置position:relative;时,在ie6中第一个ul、ol、dl的背景颜色失效
解决:
ul、ol、dl 都设置为position:relative;
30. IE6-7 列表背景颜色失效的问题2
问题:
做横向导航栏时,ul设置为float且有背景色,li设置为float。ie6-7背景颜色失效
解决:
很多ie的bug都可以通过触发layout来解决 ul添加属性
1、height:1%;
2、float:left;
3、zoom:1;
31. 列表不能换行的问题
问题:
li设置为浮动,后面的li紧随其后,不能换行
解决:
1、为这个ul定义合适的宽高
2、给包含这个ul 的父div定义合适的宽高。
32. li中的内容以省略号显示
问题:
li中内容超过长度时,想以省略号显示, 此方法适用于ie6-7-8、opera、safari浏览器
ff浏览器不支持
解决:
li{width:200px;white-space:nowrap;text-overflow:ellipsis;
-o-text-overflow:ellipsis; overflow: hidden; }
33. 超链接访问过后hover样式不出现的问题
问题:
点击超链接后,hover、active样式没有效果
解决:
改变CSS属性的排列顺序: L-V-H-A
34. 禁用中文输入法的问题
问题:
不能在输入框中输入汉字
解决:
只在ie系列 和ff中有效
ime-mode:disabled (但可以粘贴)
禁用粘贴:
οnpaste="return false"
35. 除去滚动条的问题
问题:
隐藏滚动条
解决:
1、只有ie6-7支持<bodyscroll="no">
2、除ie6-7不支持 body{overflow:hidden}
3、所有浏览器 html{overflow:hidden}
36. 让层显示在FLASH之上
问题:
想让层的内容显示在flash上
解决:
把FLASH设置透明
1、<param name=" wmode "value="transparent" />
2、<param name="wmode"value="opaque"/>
37. 去除链接虚线边框的问题
问题:
当点击超链接后,ie6/7/8 ff会出现虚线边框 ,而opera、safari没有虚线边框
解决:
ie6/7中 设置为a { blr:expression(this.onFocus=this.blur()) }
ie8 和 ff 都不支持expression 在ie8 、ff中设置为 :focus { outline: none; }
38. css滤镜的问题
问题:
css滤镜只在ie中有效,Firefox, Safari(WebKit), Opera只能够设置透明,它们不支持滤镜filter,无法实现图片切换中间变换的效果,只能通过透明度来设置。
解决:
ff中设置透明度 -moz-opacity:0.10; opacity:0.6;
ie中只设置filter:alpha(opacity=50); 时,ie6-7失效,还要设置
1、zoom:1; 2、width:100%;
39. IE6背景闪烁的问题
问题:
链接、按钮用CSSsprites作为背景,在ie6下会有背景图闪烁的现象。原因是:IE6没有将背景图缓存,每次触发hover的时候都会重新加载
解决:
可以用JavaScript设置ie6缓存这些图片:
document.execCommand("BackgroundImageCache",false,true);
40. 出现重复文字的问题
问题:
<div style="width:400px">
<divstyle="float:left"></div>
<!– _ –>
<div style="float:right;width:400px">↓这就是多出来的那只猪</div>
</div>
解决:
1、 改变结构,不出现【一个容器包含2两个具有“float”样式的子容器】的结构。
2、减小第二个容器的宽度,使父容器宽度减去第二个容器宽度的值大于3
3、去掉所有的注释。
4、修正注释的写法。<!--[if !IE]>这里是注释内容<![endif]-->
5、在第二个容器后面加一个或者多个<divstyle="clear"></div>来解决。
41. ff、chrome绝对定位无效
问题:
在IE给td设置position:relative,然后给它包含的一个容器使用position:absolute进行定位是有效的,但在FF和Chrome下却不可以。
解决:
设置td的display:block。
42. IE6 绝对定位的问题
问题:
<div style="position:relative;border:1px solidorange;text-align:center;">
<div style="position:absolute;top:0;left:0;
background:#CCC;">dovapour</div>
<a href="#" title="vapour的blog">内容</a>
</div>
解决:
left的定位错误问题
1、给父层设置zoom:1触发layout。
2、给父层设置宽度width
bottom的定位错误问题
1、给父层设置zoom:1触发layout。
2、给父层设置高度height
43. 子容器宽度大于父容器宽度时,内容超出
问题:
子DIV的宽度和父DIV的宽度都已经定义,在IE6中如果其子DIV的宽度大于父DIV的宽度,父DIV的宽度将会被扩展,在其他浏览器中父DIV的宽度将不会扩展,子DIV将超出父DIV
解决:
设置overflow:hidden,子DIV将不会超出父DIV。
44. float的div闭合的问题
问题:
例如:<#div id=”floatA” ><#div id=”floatB”><#div id=” NOTfloatC” >这里的NOTfloatC并不希望继续平移,而是希望往下排。(其中floatA、floatB的属性已经设置为 float:left;)
这段代码在IE中毫无问题,问题出在其他浏览器中。原因是NOTfloatC并非float标签,必须将float标签 闭合。
解决:
在 <#div class=”floatB”> <#divclass=”NOTfloatC”>之间加上 < #div class=”clear”>这个div一定要注意位置,而且必须与两个具有float属性的div同级,之间不能存在嵌套关系,否则会 产生异常。并且将clear这种样式定义为为如下即可:.clear{ clear:both;}
45. 单选框、复选框与后面的文字对不齐
问题:
单选框、复选框与后面的文字对不齐。
解决:
.align{font-size:12px;}
.align input{ display:block; float:left;}
.align label{ display:block; float:left;padding-top:3px; *padding-top:5px;}
需注意的问题:
1. 设置padding后高度和宽带都会增加
说明:
除了ie5.5,其他所有浏览器中,设置padding以后高度和宽带都会增加
2. 使用XHTML 1.0 Transitional后,div宽度
说明:
在使用XHTML 1.0Transitional以后div宽度都不包含border的宽度了,设置宽度的时候需要注意下。
3. 外层相对定位,内层绝对定位
说明:
ie6下,外层div的postion: relative,并设置text-align,内层div的postion:absolute,这时内层的位置是相对于text-align而言的
例如:
<div style="position:relative;border:1px solidorange;text-align:center;zoom:1"> position:relative
<divstyle="position:absolute;top:0;left:0;background:#CCC;">position:absolute</div>
</div>
4. 显示的大小不一致
说明:
默认字本显示问题,导致 显示的大小不一致,在ie下比较小一点,其他的浏览器都一致,当你使用了 造成问题时请注意。
5. 边框重叠说明
说明:
为 table、td 都指定了边框后,然后使用border-collapse:collapse让边框重叠,可以看出在发生重叠时,Firefox是用 td 覆盖 table 的,而 IE 是用 table 覆盖 td 的。使用时候需要注意。
6. 设置td padding的说明
说明:
设置td的padding以后高度和宽带都会增加,padding-left和padding-right的效果都一样增加了td的宽带,但是padding-top和padding-bottom的效果不一样。最好不要使用td的ding-top和padding-bottom
7. ul设置的说明
说明:
ul一般设置:list-style-type:none;margin:0px;padding:0px;li一般设置:list-style-type:none;list-style-position:outside
8. 使一个层垂直居中于浏览器中
说明:
使用百分比绝对定位,与外补丁负值的技巧,负值的大小为其自身宽度高度除以二
div {
position:absolute; top:50%; lef:50%; margin:-100px 0 0 -100px;
width:200px; height:200px; border:1px solid red;
}
9. 万能 float 闭合
说明:
可以用这个解决多个div对齐时的间距不对, 将以下代码加入GlobalCSS 中,给需要闭合的div加上 class=”clearfix” 即可
<style>
/* Clear Fix */
.clearfix:after { content:".";display:block;height:0; clear:both;visibility:hidden;
}
.clearfix {
display:inline-block;
}
/* Hide from IE Mac \*/
.clearfix {display:block;}
/* End hide from IE Mac */
/* end of clearfix */
</style>
10. 触发layout
说明:
IE6中很多Bug都可以通过触发layout得到解决.下列的CSS属性或取值会让一个元素获得layout:
position:absolute 绝对定位元素的包含区块(containing block)就会经常在这一方面出问题
float:left|right 由于layout元素的特性,浮动模型会有很多怪异的表现
display:inline-block 当一个内联级别的元素需要layout的时候就往往符用到它,这也可能也是这个CSS属性的唯一效果----让某个元素有layout
width: 除auto外的任何值
height: 除auto外的任何值
zoom: 除auto外的任何值
11、如何使连续长字段自动换行
ff最新版本 word-wrap:break-word;就可以了
ff旧版本 还要使用javascript完成文字换行
<style type="text/css">
div {
width:300px;
word-wrap:break-word;
border:1px solidred;
}
</style>
<script type="text/javascript">
function toBreakWord(intLen){
var obj=document.getElementById("ff");
var strContent=obj.innerHTML;
var strTemp="";
while(strContent.length>intLen){
strTemp+=strContent.substr(0,intLen)+" ";
strContent=strContent.substr(intLen,strContent.length);
}
strTemp+=" "+strContent;
obj.innerHTML=strTemp;
}
if(document.getElementById && !document.all) toBreakWord(37)
12、设置滚动条颜色 只对ie系列有效 在html中 而不是设置body
<style type="text/css">
html {
scrollbar-face-color:#f6f6f6;
scrollbar-highlight-color:#fff;
scrollbar-shadow-color:#eeeeee;
scrollbar-3dlight-color:#eeeeee;
scrollbar-arrow-color:#000;
scrollbar-track-color:#fff;
scrollbar-darkshadow-color:#fff;
}
</style>
IE不支持float:inherit overflow:hidden有2个用法,一个是隐藏溢出,另一个是清除浮动。
<div>, <p>, <h1>, <form>, <ul>和 <li>是块元素的例子
<span>, <a>, <label>, <input>,<img>, <strong> 和<em>是inline元素
<body οncοntextmenu="return false"οndragstart="return false" tstart="returnfalse" scroll="auto">
这行代码放在body中,去掉了页面鼠标右键快捷菜单,达到防止图片另存为的目的。
javascript部分
1. document.form.item 问题
问题:
代码中存在 document.formName.item("itemName") 这样的语句,不能在FF下运行
解决方法:
改用 document.formName.elements["elementName"]
2. 集合类对象问题
问题:
代码中许多集合类对象取用时使用(),IE能接受,FF不能
解决方法:
改用 [] 作为下标运算,例:
document.getElementsByName("inputName")(1) 改为document.getElementsByName("inputName")[1]
3. window.event
问题:
使用 window.event 无法在FF上运行
解决方法:
FF的 event 只能在事件发生的现场使用,此问题暂无法解决。可以把 event 传到函数里变通解决:
onMouseMove = "functionName(event)"
function functionName (e) {
e = e || window.event;
......
}
4. HTML对象的 id 作为对象名的问题
问题:
在IE中,HTML对象的 ID 可以作为 document 的下属对象变量名直接使用,在FF中不能
解决方法:
使用对象变量时全部用标准的 getElementById("idName")
5. 用 idName 字符串取得对象的问题
问题:
在IE中,利用eval("idName") 可以取得 id 为 idName 的HTML对象,在FF中不能
解决方法:
用 getElementById("idName") 代替 eval("idName")
6. 变量名与某HTML对象 id 相同的问题
问题:
在FF中,因为对象 id 不作为HTML对象的名称,所以可以使用与HTML对象 id 相同的变量名,IE中不能
解决方法:
在声明变量时,一律加上 var ,以避免歧义,这样在IE中亦可正常运行
最好不要取与HTML对象 id 相同的变量名,以减少错误
7. event.x 与 event.y 问题
问题:
在IE中,event 对象有x,y属性,FF中没有
解决方法:
在FF中,与 event.x 等效的是 event.pageX ,但event.pageX IE中没有
故采用 event.clientX 代替 event.x ,在IE中也有这个变量
event.clientX 与 event.pageX 有微妙的差别,就是滚动条
要完全一样,可以这样:
mX = event.x ? event.x : event.pageX;
然后用 mX 代替 event.x
8. 关于frame
问题:
在IE中可以用 window.testFrame 取得该frame,FF中不行
解决方法:
window.top.document.getElementById("testFrame").src = 'xx.htm'
window.top.frameName.location = 'xx.htm'
9. 取得元素的属性
在FF中,自己定义的属性必须 getAttribute() 取得
10. 在FF中没有parentElement,parement.children 而用 parentNode,parentNode.childNodes
问题:
childNodes 的下标的含义在IE和FF中不同,FF的 childNodes 中会插入空白文本节点
解决方法:
可以通过 node.getElementsByTagName() 来回避这个问题
问题:
当html中节点缺失时,IE和FF对 parentNode 的解释不同,例如:
<form>
<table>
<input/>
</table>
</form>
FF中 input.parentNode 的值为form,而IE中 input.parentNode 的值为空节点
问题:
FF中节点自己没有 removeNode 方法
解决方法:
必须使用如下方法 node.parentNode.removeChild(node)
11. const 问题
问题:
在IE中不能使用 const 关键字
解决方法:
以 var 代替
12. body 对象
FF的 body 在 body 标签没有被浏览器完全读入之前就存在,而IE则必须在 body 完全被读入之后才存在
这会产生在IE下,文档没有载入完时,在body上appendChild会出现空白页面的问题
解决方法:
一切在body上插入节点的动作,全部在onload后进行
13. url encoding
问题:
一般FF无法识别js中的&
解决方法:
在js中如果书写url就直接写&不要写&
14. nodeName 和 tagName 问题
问题:
在FF中,所有节点均有 nodeName 值,但 textNode 没有 tagName 值,在IE中,nodeName 的使用有问题
解决方法:
使用 tagName,但应检测其是否为空
15. 元素属性
IE下 input.type 属性为只读,但是FF下可以修改
16. document.getElementsByName() 和document.all[name] 的问题
问题:
在IE中,getElementsByName()、document.all[name] 均不能用来取得 div 元素
是否还有其它不能取的元素还不知道(这个问题还有争议,还在研究中)
17. 调用子框架或者其它框架中的元素的问题
在IE中,可以用如下方法来取得子元素中的值
document.getElementById("frameName").(document.)elementName
window.frames["frameName"].elementName
在FF中则需要改成如下形式来执行,与IE兼容:
window.frames["frameName"].contentWindow.document.elementName
window.frames["frameName"].document.elementName
18. 对象宽高赋值问题
问题:
FireFox中类似 obj.style.height = imgObj.height 的语句无效
解决方法:
统一使用 obj.style.height = imgObj.height + "px";
19. innerText的问题
问题:
innerText 在IE中能正常工作,但是innerText 在FireFox中却不行
解决方法:
在非IE浏览器中使用textContent代替innerText
20. event.srcElement和event.toElement问题
问题:
IE下,even对象有srcElement属性,但是没有target属性;Firefox下,even对象有target属性,但是没有srcElement属性
解决方法:
var source = e.target || e.srcElement;
var target = e.relatedTarget || e.toElement;
21. 禁止选取网页内容
问题:
FF需要用CSS禁止,IE用JS禁止
解决方法:
IE: obj.onselectstart = function() {return false;}
FF: -moz-user-select:none;
22. 捕获事件
问题:
FF没有setCapture()、releaseCapture()方法
解决方法:
IE:
obj.setCapture();
obj.releaseCapture();
FF:
window.captureEvents(Event.MOUSEMOVE|Event.MOUSEUP);
window.releaseEvents(Event.MOUSEMOVE|Event.MOUSEUP);
if (!window.captureEvents) {
o.setCapture();
}else {
window.captureEvents(Event.MOUSEMOVE|Event.MOUSEUP);
}
if (!window.captureEvents) {
o.releaseCapture();
}else {
window.releaseEvents(Event.MOUSEMOVE|Event.MOUSEUP);
}