目录
- 哈希表和堆
- 什么是哈希表 ?
- 什么是堆 ?
- 什么是图 ?
- 案例一:使用python实现最小堆
- 案例二 : 如何用Python通过哈希表的方式完成商品库存管理
- 闯关题 (包含案例三:python实现哈希表)
本文是在原本数据结构与算法闯关的基础上总结得来,加入了自己的理解和部分习题讲解
原活动链接
邀请码: JL57F5
哈希表和堆
什么是哈希表 ?
哈希表存储的是由键(key)和值(value)组成的数据。例如,我们将每个人的性别作为数据进行存储,键为人名,值为对应的性别, 一般来说,我们可以把键当成数据的标识符,把值当成数据的内容。

为了对比一下哈希表的优势 , 我们先把这些数据存储到数组中看看效果

此处准备了6个箱子(即长度为6的数组)来存储数据。假设我们需要查询Ally的性别,由于不知道Ally的数据存储在哪个箱子里,所以只能从头开始查询。这个操作便叫作“线性查找”。 当我们查找到索引为4的时候, 才找到数据的键为Ally然后可以根据键把对应的值取出来
但是我们发现 , 数据量越多,线性查找耗费的时间就越长。由此可知:由于数据的查询较为耗时,所以此处并不适合使用数组来存储数据。但使用哈希表便可以解决这个问题。首先准备好数组,这次我们用5个箱子的数组来存储数据。
首先尝试把Joe存进去。注意 这个时候就不能把它放在所以为0的数组上了 要不然没啥意义 , 那怎么放, 通过什么方式呢 ? 这个我们涉及到用哈希函数(Hash)去进行操作。 使用哈希函数(Hash)计算Joe的键,也就是字符串“Joe”的哈希值 。 得到的结果为4928 ( 哈希函数可以把给定的数据转换成固定长度的无规律数值。 我们可以想象使数据更加的安全)
将得到的哈希值除以数组的长度5,求得其余数。这样的求余运算叫作“mod运算”。此处mod运算的结果为3。
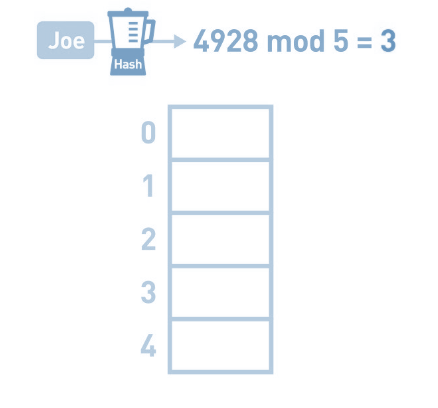
同理 : Sue键的哈希值为7291, mod 5的结果为1,将Sue的数据存进1号箱中。
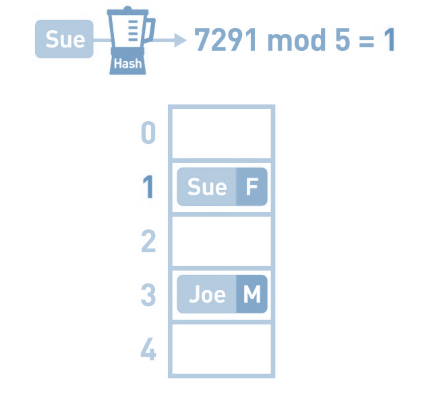
但是我们会发现, 如果余数都一样 , 冲突了怎么办 ? 比如 : Nell键的哈希值为6276, mod 5的结果为1。本应将其存进数组的1号箱中,但此时1号箱中已经存储了Sue的数据。这种存储位置重复了的情况便叫作“冲突”。
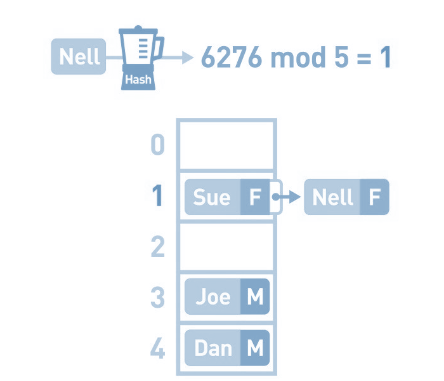
遇到这种情况,可使用链表在已有数据的后面继续存储新的数据, 这样我们如果查找Ally的性别该如何操作呢 ?
为了找到它的存储位置,先要算出Ally键的哈希值,再对其进行mod运算。最终得到的结果为3。于是我们找到了键为Ally的数据。取出其对应的值,便知道了Ally的性别为女(F)。
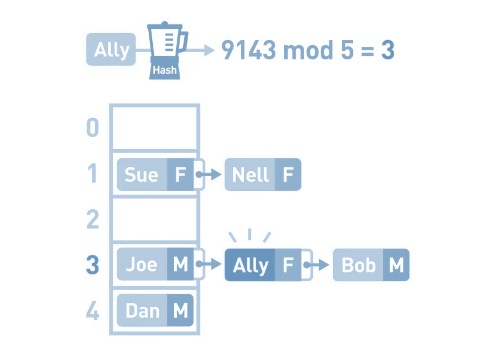
注意 : 在存储数据的过程中,如果发生冲突,可以利用链表在已有数据的后面插入新数据来解决冲突。这种方法被称为“链地址法”。比如这里的 1位置 和 3位置 都存在"冲突"
什么是堆 ?
堆是一种图的树形结构, 可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。
什么是图 ?
那什么又是图呢 ? 说到“图”,我想可能大部分人想到的是散点图、柱状图,而计算机科学领域中说的“图”却是下面这样的。
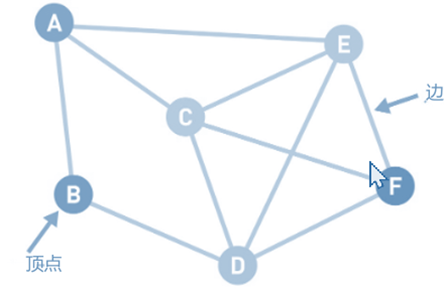
上图中的圆圈叫作“顶点”(也可以叫“结点”),连接顶点的线叫作“边”。也就是说,由顶点和连接每对顶点的边所构成的图形就是图。
ok , 回到我们讲的堆
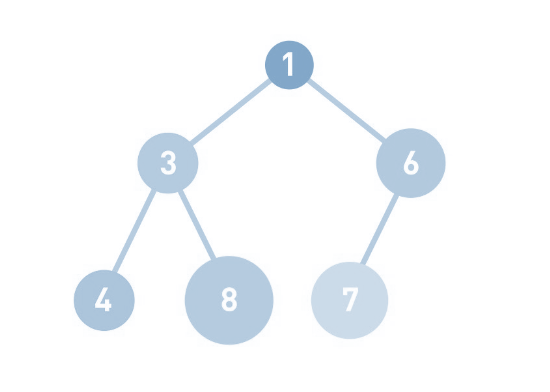
上图 , 这就是堆的例子 。结点内的数字就是它存储的数据。特别注意 : 堆中的每个结点最多有两个子结点。树的形状取决于数据的个数。另外,结点的排列顺序为从上到下,同一行里则为从左到右。
堆中存储数据时必须遵守这样的规则:
子结点必定大于父结点。因此,最小值被存储在顶端的根结点中。往堆中添加数据时,为了遵守这条规则,一般会把新数据放在最下面一行靠左的位置。当最下面一行里没有多余空间,就再往下另起一行,把数据加在这一行的最左端。所以说大家记住了吗 ?
ok, 我们来举个例子吧
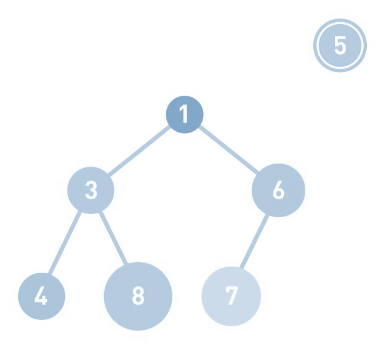
我们试试往堆里添加数字5。如果放在6的右下角显然不符合堆的原则, 因为5小于6 , 按照规定必须是子节点大于父节点 , 那么此时 5 和 6调换一下位置就刚刚好 , 如果遇到同样的问题, 重复这样的操作直到数据都符合规则,不再需要交换为止。现在,父结点的1小于子结点的5,父结点的数字更小,所以不再交换。 因为 如果从堆中取出数据时,取出的是最上面的数据。这样,堆中就能始终保持最上面的数据最小, 需要注意的是 : 一旦最上面的数据被取出,因此堆的结构也需要根据原则进行重新调整。在此我们不过多赘述
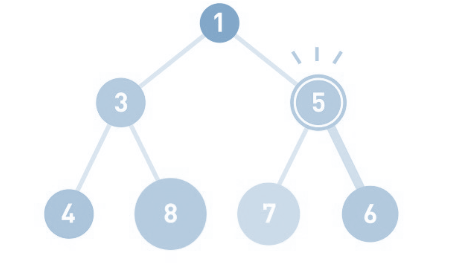
堆中最顶端的数据始终最小,所以无论数据量有多少,取出最小值的时间复杂度都为O(1)
案例一:使用python实现最小堆
import heapqdef find_top_k_largest(nums,k):min_heap = []for num in nums:if len(min_heap)<k:heapq.heappush(min_heap,num)else:if num > min_heap[0]:heapq.heappop(min_heap)heapq.heappush(min_heap,num)return min_heap# return sorted(min_heap,reverse = True)# 示例用法
nums = [4,2,9,7,5,1,6,8,3]
k = 3
top_k_largest = find_top_k_largest(nums,k)
print(top_k_largest)
[7, 9, 8]
逐行解析代码:
import heapqdef find_top_k_largest(nums, k):min_heap = []
import heapq: 这行代码导入了 Python 的heapq模块,它提供了堆队列算法的实现,特别是最小堆。def find_top_k_largest(nums, k): 定义了一个函数find_top_k_largest,它接受两个参数:一个数组nums和一个整数k。min_heap = []: 初始化一个空列表min_heap,这个列表将被用作最小堆。
for num in nums:
for num in nums: 遍历数组nums中的每个元素,每个元素被引用为num。
if len(min_heap) < k:heapq.heappush(min_heap, num)
if len(min_heap) < k: 检查当前最小堆的大小是否小于k。heapq.heappush(min_heap, num): 如果是,则将当前元素num添加到最小堆中。
else:if num > min_heap[0]:heapq.heappop(min_heap)heapq.heappush(min_heap, num)
else: 如果最小堆的大小已经达到k。if num > min_heap[0]: 检查当前元素num是否大于最小堆的顶部元素(即最小元素)。heapq.heappop(min_heap): 如果是,首先从最小堆中移除顶部元素(最小元素)。heapq.heappush(min_heap, num): 然后将当前元素num加入到最小堆中。
return min_heap
return min_heap: 函数返回最终构建的最小堆,这个堆包含了数组nums中的前k个最大元素。
在您的示例用法中,这个函数被用来找出数组 [4, 2, 9, 7, 5, 1, 6, 8, 3] 中的前 3 个最大元素,最终结果为 [7, 8, 9]。这个方法是通过维护一个大小为 k 的最小堆实现的,它确保了堆中始终保持数组中的前 k 个最大元素。
- 提问:输出的顺序是[7,9,8] 非 [7,8,9]
您提到的输出 [7, 9, 8] 实际上也是正确的。这个结果出现的原因在于堆不保证元素的有序性,尤其是在非根部的位置。在您的例子中,最小堆确实维护了数组中的前 k 个最大元素,但是这些元素在堆中的顺序并不是有序的。
在最小堆中,只有根部(即堆顶元素,min_heap[0])是保证最小的,其他位置的元素并没有特定的顺序。当您提取出堆中的元素时,它们的顺序依赖于堆在内部的具体排列,这个排列是由 heapq 模块在执行插入和删除操作时决定的。
如果您需要一个有序的结果,您可以在返回前对堆中的元素进行排序。例如:
return sorted(min_heap, reverse=True)
这将确保返回的列表是按照从大到小的顺序排列的。但请注意,这个排序步骤会增加额外的时间复杂度。如果您不关心结果的顺序,那么直接返回未排序的堆就足够了。
案例二 : 如何用Python通过哈希表的方式完成商品库存管理
背景:
在一个电商系统中,我们需要管理商品的库存信息。每个商品都有一个唯一的商品编号(item_id)和对应的库存数量(stock)。当用户下单购买商品时,需要实时检查商品的库存情况,以确保有足够的库存供应。
任务:
请实现一个基于哈希表(字典)的商品库存管理系统。具体要求如下:
定义一个函数 add_stock(item_id, quantity),用于向库存系统中添加商品库存。如果商品已存在于系统中,则将库存数量累加;如果商品还不存在于系统中,则添加新的商品及其库存信息。
定义一个函数 subtract_stock(item_id, quantity),用于从库存系统中减少商品库存。如果商品不存在于系统中,则抛出异常;如果商品库存不足以满足要求的减少量,则抛出异常;否则,更新商品的库存数量。
定义一个函数 get_stock(item_id),用于获取指定商品的库存数量。
# 商品库存管理系统
stock_dict = {} # 创建一个字典作为商品库存表def add_stock(item_id, quantity):"""向库存系统中添加商品库存如果商品已存在于系统中,则将库存数量累加;如果商品还不存在于系统中,则添加新的商品及其库存信息。"""if item_id in stock_dict:stock_dict[item_id] += quantityelse:stock_dict[item_id] = quantitydef subtract_stock(item_id, quantity):"""从库存系统中减少商品库存如果商品不存在于系统中,则抛出异常;如果商品库存不足以满足要求的减少量,则抛出异常;否则,更新商品的库存数量。"""if item_id not in stock_dict:raise Exception("Item does not exist in stock")if stock_dict[item_id] < quantity:raise Exception("Insufficient stock")stock_dict[item_id] -= quantitydef get_stock(item_id):"""获取指定商品的库存数量"""return stock_dict.get(item_id, 0)# 示例演示
add_stock("item001", 100) # 添加商品 "item001",库存数量为 100
add_stock("item002", 50) # 添加商品 "item002",库存数量为 50print("Current stock:")
print(stock_dict) # 打印当前商品库存情况subtract_stock("item001", 20) # 减少商品 "item001" 库存 20
stock = get_stock("item001") # 获取商品 "item001" 的库存
print("Current stock:", stock)subtract_stock("item002", 70) # 尝试减少商品 "item002" 库存 70(超过实际库存量)
# 库存不足异常将被抛出,程序终止运行Current stock:
{'item001': 100, 'item002': 50}
Current stock: 80---------------------------------------------------------------------------Exception Traceback (most recent call last)<ipython-input-1-3a5c254f3c86> in <module>45 print("Current stock:", stock)46
---> 47 subtract_stock("item002", 70) # 尝试减少商品 "item002" 库存 70(超过实际库存量)48 # 库存不足异常将被抛出,程序终止运行<ipython-input-1-3a5c254f3c86> in subtract_stock(item_id, quantity)24 25 if stock_dict[item_id] < quantity:
---> 26 raise Exception("Insufficient stock")27 28 stock_dict[item_id] -= quantityException: Insufficient stock
在以上代码示例中,我们创建了一个名为 stock_dict 的字典,用于存储商品库存信息。通过 add_stock 函数向库存系统中添加商品库存,通过 subtract_stock 函数减少商品库存,通过 get_stock 函数获取指定商品的库存数量。在函数实现上,我们利用字典的键值对特性,将商品编号作为键,库存数量作为对应的值进行存储和访问。
在主程序中,我们先添加了两个商品的库存信息,然后演示了减少库存和获取库存的操作。在减少库存时,如果库存不足或商品不存在,将会抛出相应的异常信息。
闯关题 (包含案例三:python实现哈希表)
STEP1:根据要求完成题目
Q1.(单选) 一个大小为n的数组中,可以快速找到前k大的数,应该使用哪种数据结构?
A. 数组
B. 链表
C. 栈
D. 堆
E. 哈希表
Q2.(单选)以下哪一组操作不是哈希表的基本操作?
A. 插入
B. 删除
C. 清空
D. 查找
E. 排序
Q3.(判断对错)堆中的每个结点最多有两个子结点, 这两个节点要求是所有结点中最大的 (T/F)
Q4.(判断对错)结点的排列顺序为从上到下,同一行里则为从左到右 (T/F)
使用 Python 实现一个哈希表,要求具有以下方法:
- set(key, value):将键值对(key, value)插入哈希表中,如果 key 已经存在,则覆盖其原有的值
- get(key):返回哈希表中指定 key 的值,如果 key 不存在,则返回 None
- delete(key):从哈希表中删除指定 key 的键值对
提示:
- 可以使用 Python 内置的字典 dict 来实现哈希表
- 在 set 和 delete 方法中,要注意先检查字典中是否存在该 key
class HashTable:# 定义哈希表类,使用 Python 内置的 dict 实现def __init__(self):self.table = {}def set(self, key, value):"""向哈希表中插入键值对"""#题目q5 : 向哈希表中插入键值对self.table[key] = valuedef get(self, key):"""获取指定 key 对应的 value"""if key in self.table:# 题目q6 :返回指定的键对应的值return self.table[key]else:return Nonedef delete(self, key):"""从哈希表中删除指定的键值对"""if key in self.table:del self.table[key]
观察上面的代码,完成下面的单选题(注意查看前后代码)
Q5. 代码第11行为空,现在需要实现向哈希表中插入键值对,下面哪个选项为正确代码,选择正确选项并把结果赋值给a5
A : self.table[key] = value
B : table[key] = value
C : self.table = {}
D : self.table[key] = {key : value}
Q6. 代码第19行为空,现在需要实现返回指定的键对应的值,下面哪个选项为正确代码,选择正确选项并把结果赋值给a6
A : return table[key]
B : return self.table[key]
C : return value
D : return {value}
#填入你的答案
a1 = 'D' # 如 a1 = 'A'
a2 = 'E' # 如 a2 = 'A'
a3 = 'F' # 如 a3 = 'T'
a4 = 'T' # 如 a4 = 'T'
a5 = 'A' # 如 a5 = 'C'
a6 = 'B' # 如 a6 = 'A'
STEP2:将结果保存为 csv 文件
csv 需要有两列,列名:id、answer。其中,id 列为题号,如 q1、q2;answer 列为 STEP1 中各题你计算出来的结果。💡 这一步的代码你无需修改,直接运行即可。
# 生成 csv 作业答案文件
def save_csv(a1, a2, a3, a4, a5,a6) : import pandas as pddf = pd.DataFrame({"id": ["q1", "q2", "q3", "q4","q5","q6"], "answer": [a1, a2, a3,a4,a5,a6]})df.to_csv("answer_ago_1_3.csv", index=None)save_csv(a1, a2, a3, a4, a5,a6) # 运行这个cell,生成答案文件;该文件在左侧文件树project工作区下,你可以自行右击下载或者读取查看