本文是在实际操作中踩到的一些坑,并不是操作手册。具体的还是需要仔细按照官方文档操作。
参考文档:https://developers.google.com/analytics/
重点看标红的文档即可

普通事件埋点
各端需要跟产品端确定好统一的事件名称和参数,否则数据混乱,通过api获取数据非常不准确
以前端代码为例
gtag('event', '<event_name>', {
<event_parameters>
});//举例
gtag('event', 'banner_view', {
banner_id:4332
});后端
event_name根据确定好的场景进行设置(注意:禁止将id直接设置在事件名称中,比如 product_view_23423之类的。事件数量暂无限制,google analytics本身预设了click、first_visit、page_view、scroll、session_start等事件,日常的行为均被记录到预设事件中), event_parameters则是事件向google analytics传递的参数。如果要根据参数中的某个值查询,则需要这个参数在自定义维度中添加过。比如banner_id,

这个自定义维度不能超过50个。自定义维度和指标在后台设置后需要一两天后数据才可查询。

注意:如果某个维度在一天内的唯一值超过 500 个,该维度就会被视为高基数维度。如果存在高基数维度,报告就更有可能达到其行数上限,从而导致出现“(其他)”行。只有当信息很重要且是实现业务目标所必需的,才应使用高基数维度。
如何理解以上这段话,举例:
gta('event','product_view',{id:21332
})这里设置了一个维度id,当商品的数量达到成千上万,这里的id唯一值将超过500,这种维度会视作高基数维度。那要对商品进行某些维度上的分析,如何做呢?google analytics针对电商平台设置了专门的维度,参考https://developers.google.com/analytics/devguides/collection/ga4/ecommerce?client_type=gtag。
如何去理解维度和指标?https://support.google.com/analytics/answer/9143382
维度:是描述数据的属性,例如各种id,渠道,来源,机型,年龄,性别,事件,位置,国家城市等等,维度通常用于对数据进行分组或筛选
指标:是描述数据的数量,时间,百分比,数量,活跃数,用户数等等
谷歌预定维度和指标 https://developers.google.com/analytics/devguides/reporting/data/v1/api-schema?hl=zh-cn#dimensions
如何衡量同一个用户在不同平台的活动?https://support.google.com/analytics/answer/9213390
借助 User-ID 功能,您可以将自己的标识符与具体用户关联起来,以便在不同的会话以及各种设备和平台上关联他们的行为。Google Analytics(分析)会将每个 User-ID 解读为一个单独的用户,这使得您可以获得更准确的用户计数,让您更全面地了解用户与您的业务的关系。
gtag('config', 'TAG_ID', { 'user_id': 'USER_ID'
});各端在用户登录后,可将USER_ID设置为用户id,这样该用户在各端的数据都能统一起来。
电商平台事件埋点
https://developers.google.com/analytics/devguides/collection/ga4/ecommerce?client_type=gtag
针对电商类网站,google analytics有专门设置特定的参数,按照文档设置即可
后端通过API埋点
推送参数参考
https://developers.google.com/analytics/devguides/collection/protocol/ga4/sending-events
推送地址:https://www.google-analytics.com/mp/collect
验证地址: https://www.google-analytics.com/debug/mp/collect
Android和IOS的firebase_app_id,web的measurement_id数据流中查看
Measurement Protocol API 密钥,也是在数据流中创建
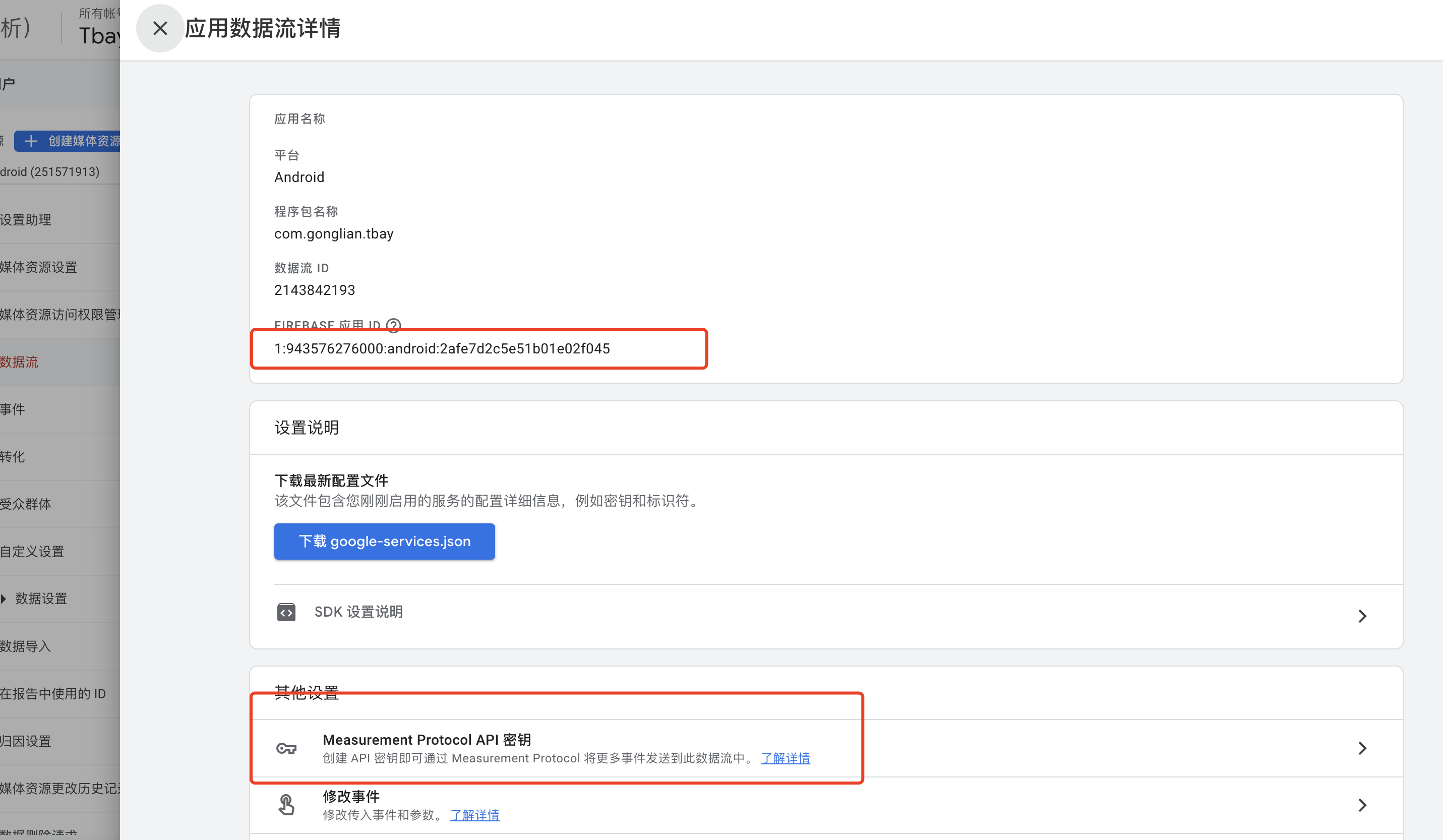
新事件必须先调用验证,在推送埋点数据,否则不会被谷歌收录
汇总数据流
每个视图都是分散的,挨个获比较麻烦,需要把各端数据流合并
管理》数据流
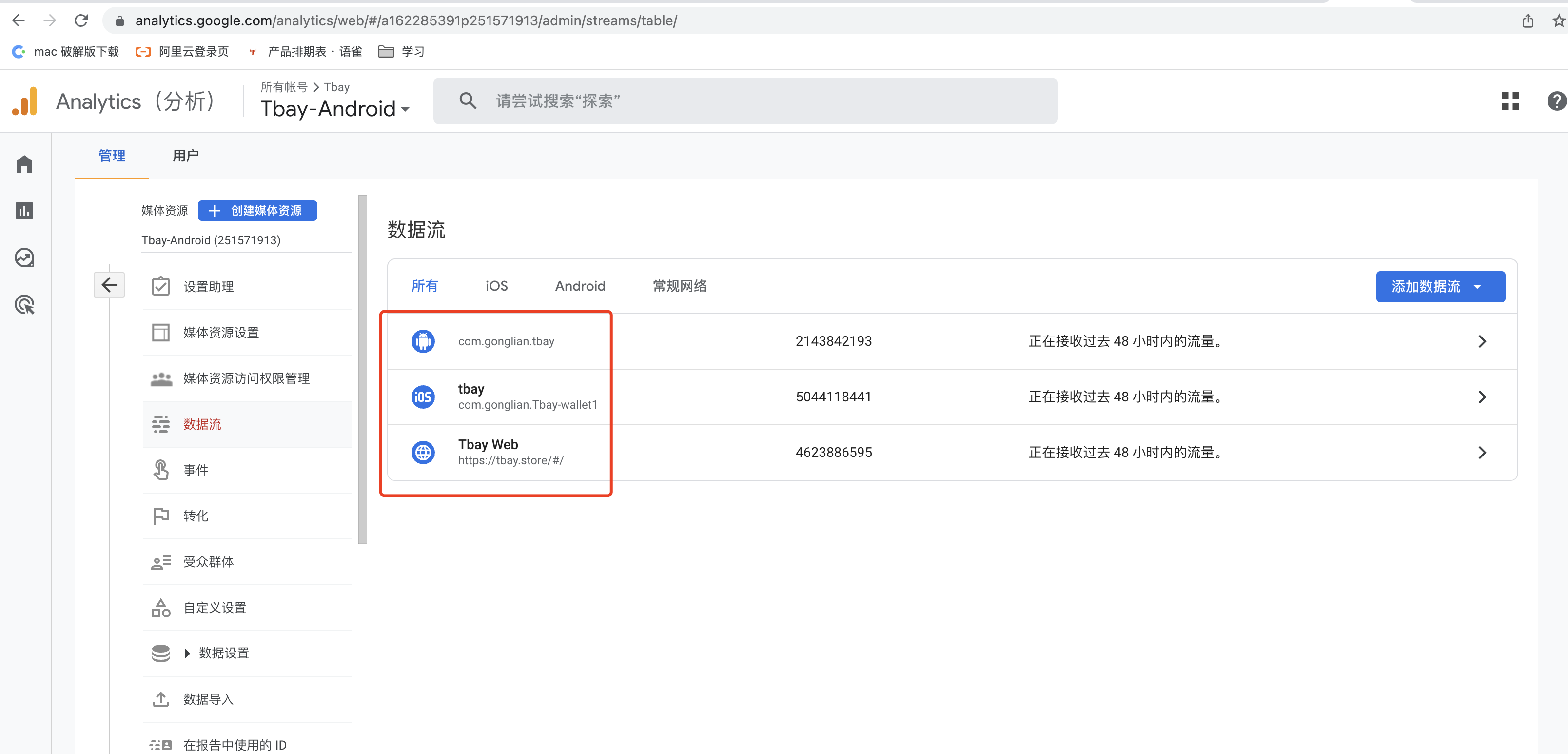
客户端汇总每个视图都是分散的,挨个获比较麻烦,需要把各端数据流合并
如果后端的埋点数据需要区分来源,那么不同端的数据需要打到对应的数据流中
通过API拉取数据
拉取参数参考
https://ga-dev-tools.web.app/ga4/query-explorer/
1、API启用
https://developers.google.com/analytics/devguides/reporting/data/v1/quickstart-client-libraries
2、身份验证
创建和管理服务帐号密钥
https://console.cloud.google.com/projectselector2/iam-admin/serviceaccounts?supportedpurview=project
创建完后将类似redmou-test@redmou-test.iam.gserviceaccount.com账号回填到google analytics 后台并设置好相关权限
3、API接入 按照SDK文档
java构建实例:https://github.com/googleapis/java-analytics-data/tree/main/samples/snippets/src/main/java/com/example/analytics
1)PROPERTY_ID指的是
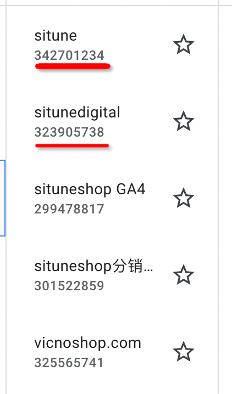
2)接口请求参数里metrics是指标,返回参数里会根据所列的指标返回响应的数值。dimensions是维度。一般查询事件 metrics 是 eventValue,dimensions 是eventName,会把所有事件结果返回。请求参数里还有dimensionFilter是根据之前请求维度筛选,同理metricFilter。 自定义维度查询,比如:customeEvent:banner_id。
具体可以通过
https://ga-dev-tools.web.app/ga4/query-explorer/
进行操作。
请求参数举例:复制代码通过json格式化在线工具 格式化查看更清晰
{"dimensions":[{"name":"platform"},{"name":"customEvent:icon_id"}],"metrics":[{"name":"eventCount"}],"dateRanges":[{"startDate":"30daysAgo","endDate":"yesterday"}],"keepEmptyRows":true,"metricAggregations":["TOTAL"]
}返回数据举例:
{"dimensionHeaders":[{"name":"platform"},{"name":"customEvent:icon_id"}],"metricHeaders":[{"name":"eventCount","type":"TYPE_INTEGER"}],"rows":[{"dimensionValues":[{"value":"web"},{"value":"(not set)"}],"metricValues":[{"value":"135"}]},{"dimensionValues":[{"value":"web"},{"value":"1002"}],"metricValues":[{"value":"5"}]},{"dimensionValues":[{"value":"web"},{"value":"1003"}],"metricValues":[{"value":"4"}]},{"dimensionValues":[{"value":"web"},{"value":"1001"}],"metricValues":[{"value":"2"}]},{"dimensionValues":[{"value":"web"},{"value":"1004"}],"metricValues":[{"value":"2"}]},{"dimensionValues":[{"value":"web"},{"value":"1005"}],"metricValues":[{"value":"2"}]}],"totals":[{"dimensionValues":[{"value":"RESERVED_TOTAL"},{"value":"RESERVED_TOTAL"}],"metricValues":[{"value":"150"}]}],"rowCount":6,"metadata":{"currencyCode":"CNY","timeZone":"Asia/Shanghai"},"kind":"analyticsData#runReport"
}