前言:
讲真,复习这块我是比较头大的,之前的线代、高数、概率论、西瓜书、樱花书、NG的系列课程、李宏毅李沐等等等等…那可是花了三年学习佳实践下来的,现在一想脑子里就剩下几个名词就觉得废柴一个了,朋友们有没有同感,高中的留给高中老师,大学的给大学老师,研究生的留给谁了呢~但是呢,想想我马上要成为风口上的众多马上飞起的(* ̄(oo) ̄),不说废话,撸起袖子开干!!!
tips:不做具体视频课程学习,基本会按照有PPT的看PPT,知识点忘得比较干净的上最新的课程里面查漏补缺,也不能忘得一干二净不是,还是留了点的O(∩_∩)O哈哈~
学习资料
以我的专栏笔记为主线(基本涵盖了下面的资料),李宏毅老师的课程过一遍,其他为辅助资料查漏补缺;

- 李航《统计学习方法》:机器学习数学基础补齐
- 机器学习算法:ShowMeAI
- 吴恩达的《Machine Learning》 :以PPT为主
- 《李宏毅机器学习2023》:以课程为主
- 书籍 - 周志华的《机器学习》-西瓜书 :知识补齐用
- 书籍 - Peter Harrington的《机器学习实战》
- 机器学习入门强推的B站课程
知识点串联
机器学习基础
概念:从数据中自动分析得出数据模型,并对数据进行预测;
机器学习流程
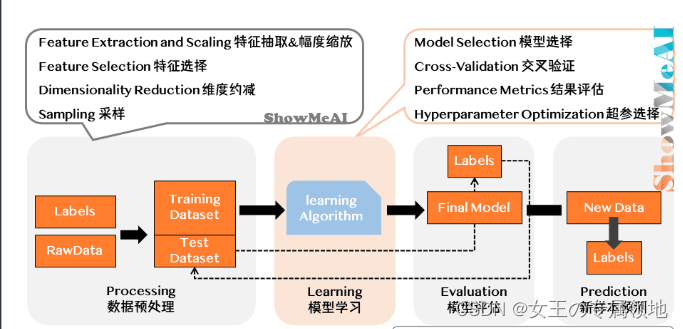
- 获取数据
名词:样本、特征、目标值(标签值)、特征值
数据结构:① 特征值 + 目标值(连续|离散);②只有特征值;
数据分割:训练数据(构建模型)、测试数据(评估模型)
- 数据基本处理:缺失值、异常值处理等
- 特征工程
特征提取:文本/图像/语音等输入>>> 机器学习的数字特征
特征预处理:特征数据–【通过转换函数】–适合算法模型的数据
特征降维:降低随机变量(特征)个数,得到“不相关”主变量过程,eg:地球仪 》地图
- 机器学习(模型训练/学习):监督、无监督、半监督、强化
- 模型评估
分类模型评估:错误率(Error Rate)、精确率(Accuracy)、查准率(Precision)、查全率(Recall)、F1、ROC曲线、AUC曲线和R平方等
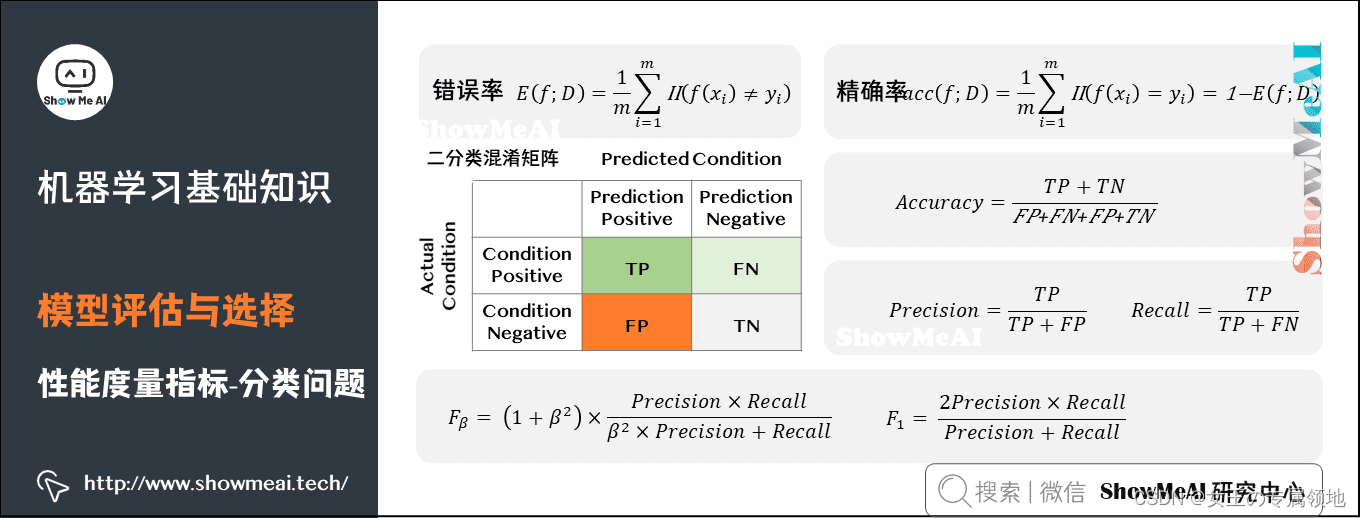
回归模型评估:均方根误差RMSE、相对平方误差RSE、平均绝对误差MAE、相对绝对误差RAE、决定系数

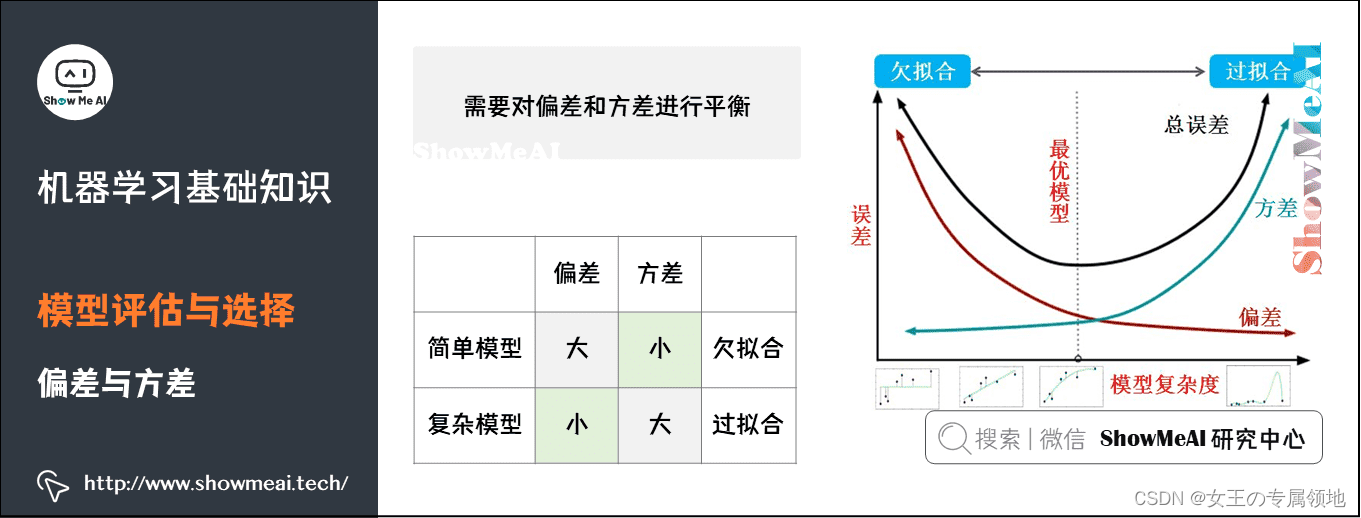
拟合:欠拟合(过于差,学到的太少)、过拟合(过于优越,学到的太多)
- 样本预测
机器学习类型
监督学习:
- 原理:输入特征值+目标值,输出连续的值(回归)/离散的值(分类)
- 案例:猫狗分类、房价预测
- 分类算法:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
- 回归算法:线性回顾、岭回归
非监督学习:
- 原理:仅输入特征值,观察到的结果(聚类)
- 目的:发现潜在结构
- 案例:物以类聚
- 聚类:K-means
半监督学习:
- 输入部分① 特征值+目标值;部分②特征值
- 应用:训练数据量过多的情况
- 监督学习不满足需求时,增强效果;
强化学习:
- 决策流程及激励系统:4要素(Agent、action、environment、observation),输入动态变化,上一步的输出是下一步的输入,根据奖惩机制调整决策;
- 目的:长期利益最大化,回报函数(只会提示你是否在朝着方向前进的延迟反应)
- 案例:学下棋
- 算法:马尔科夫决策、动态规划
十大常用算法
-
KNN算法及其应用
-
逻辑回归算法详解
-
朴素贝叶斯算法详解
-
决策树模型详解
-
随机森林分类模型详解
-
回归树模型详解
-
GBDT模型详解
-
XGBoost模型详解
-
LightGBM模型详解
-
支持向量机模型详解
-
聚类算法详解
-
降维算法详解
机器学习环境安装与使用
- 库的使用:常用的numpy、pandas、matplotlib、jupyter、tables等 (这一部分我的专栏【Python模块】专门有讲这些库的用法,安装方式上网一找一大堆),其中numpy、pandas以及matplotlib在上周Python的复习过程中已经涉及到了!见【第三周:Python能力复盘】
- 工具使用:Anaconda、Jupyter notebook、Markdown(哈哈,CSDN我就是那markdown编辑的,现成的技能😁)
机器学习案例
- Azure机器学习实验搭建:https://www.codenong.com/cs106570915/