栈回溯和符号解析是使用 perf 的两大阻力,本文以应用程序 fio 的观测为例子,提供一些处理它们的经验法则,希望帮助大家无痛使用 perf。
前言
系统级性能优化通常包括两个阶段:性能剖析和代码优化:
-
性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码;
-
代码优化的目标是针对具体性能问题而优化代码或调整编译选项,以改善软件性能。
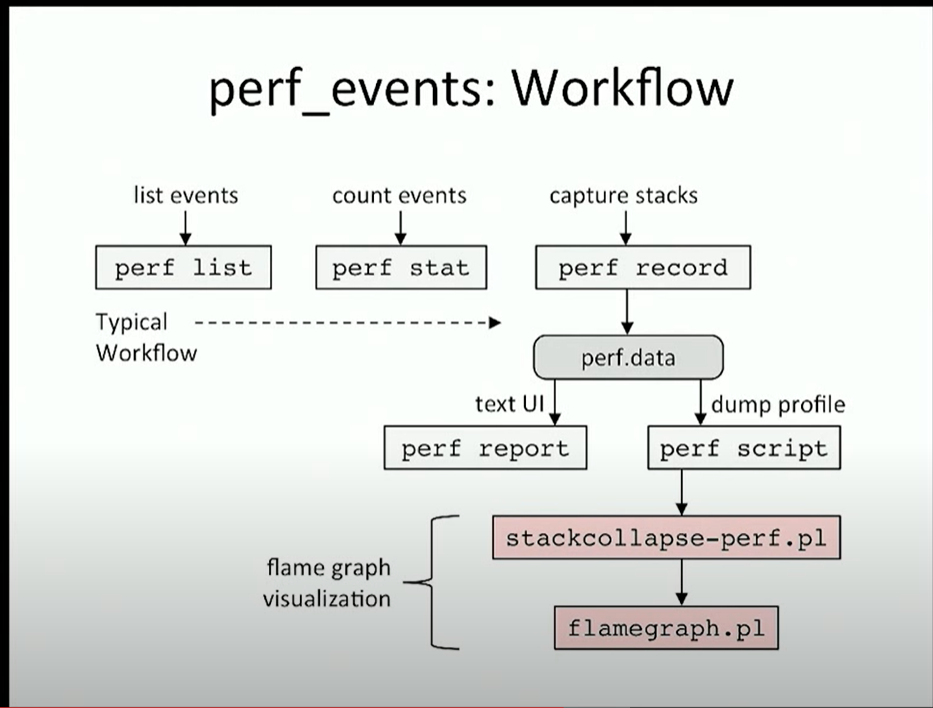
在步骤一性能剖析阶段,最常用的工具就是 perf。perf 是 linux 官方提供的性能分析工具,被包含在 Linux 内核源码树中。它是一个庞大的工具集合,功能相当繁杂。但在工作中,通常我们只会使用到 perf 其中相当小的一个子集,主要包含以下四个步骤:
-
perf record: 采集数据,采的时间越长越心安;
-
perf report: 查看采集数据,因为采集太长时间,解析数据会卡很久,我们试图理解数据,通常无法理解;
-
perf script: 尝试查看原始采样点,通常无法理解;
-
生成火焰图: 色彩丰富,通常发给领导理解。
综上,后三个步骤是我们无法控制的,本文主要聊聊如何在步骤一尽量生成可信的采样数据。
workflow of perf
虽然听起来调侃,但上述步骤确实是标准的分析流程,毕竟有火焰图发明人 Brandon 的背书:
@Brandon
可以看到,它们被包含在 perf 工作流第三列的 capture stacks 中,简单回顾一下这四个步骤:
-
perf record: 通过指定 -g 选项可以收集系统整体的函数调用栈(包含用户态和内核态),默认以 4000HZ 的频率收集,大约每秒生成 4000 个采样点,被保存在 perf.data 文件中;
$ perf record -g -C 0 -- sleep 1
[ perf record: Captured and wrote 0.906 MB perf.data (4001 samples) ]
-
perf report: 通过解析 perf.data,生成热点函数占用 CPU 的比例。例如以下输出中,CPU0 大部分时间(99.73%)停留在内核代码的 idle 函数中,即 CPU0 大部分时间处于空闲状态:
$ perf report --no-child --stdio
99.73% swapper [kernel.kallsyms] [k] native_safe_halt|---native_safe_haltacpi_idle_do_entryacpi_idle_entercpuidle_enter_statecpuidle_enterdo_idlecpu_startup_entrystart_kernelsecondary_startup_64_no_verify
-
perf script: 查看每个采样样本(栈),例如以下栈样本表明:
cpu-clock:pppH:事件于时间45399.463561发生,在 CPU0 触发了中断,中断打断的任务是进程号为 0 的内核线程swapper,栈从下往上看,被打断时 CPU 正在执行 native_safe_halt 偏移 0xe 处的指令:
$ perf script
swapper 0 [000] 45399。463561: 250000 cpu-clock:pppH: ffffffffa234c45e native_safe_halt+0xe ([kernel.kallsyms])ffffffffa234c806 acpi_idle_do_entry+0x46 ([kernel.kallsyms])ffffffffa1f4bafb acpi_idle_enter+0x9b ([kernel.kallsyms])ffffffffa211efb7 cpuidle_enter_state+0x87 ([kernel.kallsyms])ffffffffa211f33c cpuidle_enter+0x2c ([kernel.kallsyms])ffffffffa1b16ff4 do_idle+0x234 ([kernel.kallsyms])ffffffffa1b171ef cpu_startup_entry+0x6f ([kernel.kallsyms])ffffffffa3601262 start_kernel+0x518 ([kernel.kallsyms])ffffffffa1a00107 secondary_startup_64_no_verify+0xc2 ([kernel.kallsyms])
-
使用脚本生成火焰图,以下是官网例图:
可以发现,后续的分析步骤都基于步骤一采集得到的 perf.data。显然,只有获取到足够精准的调用栈信息,后续才能准确定位到性能瓶颈。可惜的是,获取函数调用栈并没有一个通用解,导致我们需要额外了解一些小知识。
choose your unwinder
获取函数调用栈过程又称栈回溯(unwind),栈回溯的方法被称为 unwinder,常见的 unwinder 有:
-
fp:perf 默认选项,ARM 和 X86 都支持,消耗低;
-
dwarf:通过
--call-graph=dwarf指定,ARM 和 X86 都支持,对CPU和磁盘消耗高; -
lbr:通过
--call-graph=lbr指定,仅 Intel 新型号支持,消耗低,但可回溯的栈深度有限; -
orc:内核 unwinder,无需指定。 在 perf record 中,若不通过
--call-graph指定 unwinder,默认使用 fp 作为用户态栈的 unwinder;至于内核态的 unwinder,不由 perf 参数指定,由内核编译选项控制,低版本内核使用 fp,高版本内核使用 orc。
因此问题转化为:用户态使用哪个 unwinder 是更合适的?结论先行,以下是可供参考的方案:
-
Intel CPU:优先使用 lbr,lbr 的好处是硬件实现,精准可靠,大部分情况下深度够用;
-
ARM 架构:优先使用 fp,因为 ARM 架构寄存器比较多,保留了寄存器记录栈基址;
- X86 上没有 lbr 时:优先使用 dwarf,虽然 X86 架构也把栈基址保存在 %rbp,但只要编译优化大于等于
-O1,%rbp 寄存器基本作为通用寄存器使用,使得在 X86 上用 fp 获取用户态栈大部分时候不可靠。有以下注意点:-
在 linux 5.19 版本以下,dwarf 可能采样不到动态链接库的栈(参考提交 perf unwind: Fix egbase for ld.lld linked objects);
-
dwarf 需要复制保存每一个采样点的用户栈,因此采样期间 CPU 消耗较高,生成的采样数据也远大于其它 unwinder;
-
如果 dwarf 无法满足需求,可以 gcc 编译时添加选项
-fno-omit-frame-pointer放弃复用 %rbp 寄存器的编译优化,重新编译应用后使用 fp。虽然该选项无法百分百保证 %rbp 一定可靠,但总体可信。
-
让我们通过在 X86 架构上观测应用程序 fio,对这些 unwinder 有个初步的了解:
$ perf record -a --user-callchains --call-graph=dwarf -p `pidof fio` -o perf.data.dwarf -- sleep 2
$ perf report --no-ch --stdio -i perf.data.dwarf10.69% fio [kernel.kallsyms] [k] iowrite16|---syscallio_submit0x55a0a986682e # <- 我们会在下下节解决符号问题td_io_committd_io_queue0x55a0a985945a <-0x55a0a985b7d0 <- start_thread__GI___clone (inlined)
$ perf record -a --user-callchains --call-graph=fp -p `pidof fio` -o perf.data.fp -- sleep 2
$ perf report --no-ch --stdio -i perf.data.fp8.27% fio [kernel.kallsyms] [k] iowrite16|---syscall|--0.75%--0x70700000707|--0.75%--0x62d0000062d|--0.75%--0x5e1000005e1|--0.75%--0x55b0000055a|--0.75%--0x54800000548|--0.75%--0x52f0000052f|--0.75%--0x51000000510|--0.75%--0x44f0000044f|--0.75%--0x3cb000003cb|--0.75%--0x39800000398--0.75%--0x37c0000037b
以上采集数据的命令中使用 --user-callchains 选项指定了 perf 采样时只采集用户栈,排除掉我们暂时不关心的内核栈。输出中可以看到虽然 dwarf 采集得到的栈没有被完全翻译,但正确地回溯到了进程刚诞生的函数 __GI___clone,这表明 dwarf 采样得到了完整的栈;反观 fp,只得到了些奇怪的地址。我们的方案三是有效的!
what do dwarf do
为叙述完整,该节补充一点 dwarf 栈回溯原理,不影响 perf 使用,不涉及的朋友可以跳转下一节解决符号问题。
在编译过程中 gcc 无论是否指定 -g 选项, 默认都会生成 .eh_frame 和 .eh_frame_hdr 段. gcc 在翻译代码为汇编代码时, 会帮忙插上一些 CFI 伪指令, 如
$ gcc -S test.c # c语言生成汇编代码
$ vim test.s # 查看汇编代码
$ cat test.s.cfi_startproc # 刚进函数, 当前我们处于 callee 栈帧的起始处, 更新 CFA = rsp + 8pushq %rbp# 每次 push 寄存器到栈上, 需要将 CFA += 8, 因为相比上一状态需要多往前走一个单位才是 caller 的栈帧.cfi_def_cfa_offset 16.cfi_offset 6, -16 # 并且更新该寄存器关于 CFA 的偏移, 使回溯过程可以恢复该寄存器的值# ...movq %rsp %rbp # 将 rsp 寄存器赋值给 rbp.cfi_def_cfa_register 6 # 将寄存器 6 (rbp) 定义为 CFA 寄存器, 之后 CFA 的计算都基于 rbp# ...leave.cfi_def_cfa 7, 8 # leave 中将 rbp 寄存器的值赋值给 rsp, 即 rsp 此时指向 callee 栈帧开始处, 此时 CFA = rsp + 8.cfi_endproc
$ readelf -wF test.o # 查看对应的 .eh_frame 印证
0000000000000661 rsp+8 u c-8
0000000000000662 rsp+16 c-16 c-8
0000000000000665 rbp+16 c-16 c-8
00000000000006a6 rsp+8 c-16 c-8
其中 CFA (Canonical Frame Address, which is the address of %rsp in the caller frame) 指上一级调用者的堆栈指针.
如上所示, 汇编器会将这些 CFI 伪指令收集到可执行文件中的 .eh_frame 段. 典型形式如下:
$ readelf -wF a.out
Contents of the .eh_frame section:00000000 0000000000000014 00000000 CIE "zR" cf=1 df=-8 ra=16LOC CFA ra
0000000000000000 rsp+8 u ...000000c8 0000000000000044 0000009c FDE cie=00000030 pc=00000000000006b0..0000000000000715LOC CFA rbx rbp r12 r13 r14 r15 ra
00000000000006b0 rsp+8 u u u u u u c-8
00000000000006b2 rsp+16 u u u u u c-16 c-8
00000000000006b4 rsp+24 u u u u c-24 c-16 c-8
00000000000006b9 rsp+32 u u u c-32 c-24 c-16 c-8
00000000000006bb rsp+40 u u c-40 c-32 c-24 c-16 c-8
00000000000006c3 rsp+48 u c-48 c-40 c-32 c-24 c-16 c-8
00000000000006cb rsp+56 c-56 c-48 c-40 c-32 c-24 c-16 c-8
00000000000006d8 rsp+64 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070a rsp+56 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070b rsp+48 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070c rsp+40 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070e rsp+32 c-56 c-48 c-40 c-32 c-24 c-16 c-8
0000000000000710 rsp+24 c-56 c-48 c-40 c-32 c-24 c-16 c-8
0000000000000712 rsp+16 c-56 c-48 c-40 c-32 c-24 c-16 c-8
0000000000000714 rsp+8 c-56 c-48 c-40 c-32 c-24 c-16 c-8
可以看到 .eh_frame 总体架构由 CIE 和 FDE 组成。通常一个 CIE 代表一个文件, 一个 FDE 代表一个函数. 其中核心的是 FDE 的组织:

利用 .eh_frame 进行栈 unwind 时候, 遵循以下步骤:
-
根据当前的PC在
.eh_frame中找到对应的条目,根据条目提供的各种偏移计算其他信息。 -
首先根据
CFA = rsp+4,把当前rsp+4得到CFA的值。再根据CFA的值计算出通用寄存器和返回地址在堆栈中的位置。 -
通用寄存器栈位置计算。例如:rbx = CFA-56。
-
返回地址ra的栈位置计算。ra = CFA-8。
-
根据ra的值,重复步骤1到4,就形成了完整的栈回溯。
handle missing symbols
函数调用栈本质是一串地址,perf 会尽量将地址翻译人类可读的符号。在以下样本点中,可以看到 IP 寄存器保存的地址属于 libc 库,它被正确翻译为 syscall+0x1d,但再往下回溯,我们只知道 syscall 函数是由 libaio 库某不知名函数调用的。这里出现 [unknown] 通常由于可执行程序的符号被裁剪所致,裁剪符号是有效减小可执行程序体积的做法。
$ perf script -D -i perf.data.dwarf
259594741631398 0x2d840 [0x20f8]: PERF_RECORD_SAMPLE(IP, 0x1): 273245/273258: 0xffffffff89d1869d period: 250000 addr: 0
... FP chain: nr:0
[...]
.... IP 0x00007f3afb87f52d
... ustack: size 8192, offset 0xe0
[...]
fio 273258 259594.741631: 250000 cpu-clock:pppH: 7f3afb87f52d syscall+0x1d (/usr/lib64/libc-2.28.so)7f3afc50ab7d [unknown] (/usr/lib64/libaio.so.1.0.1)55a0a9866a95 [unknown] (/usr/bin/fio)55a0a98197a5 td_io_getevents+0x75 (/usr/bin/fio)55a0a983b216 io_u_queued_complete+0x66 (/usr/bin/fio)55a0a98577d4 [unknown] (/usr/bin/fio)55a0a98591fa [unknown] (/usr/bin/fio)55a0a985b7d0 [unknown] (/usr/bin/fio)7f3afc0db179 start_thread+0xe9 (/usr/lib64/libpthread-2.28.so)7f3afb884dc2 __GI___clone+0x42
那怎么将符号补全呢?我们可以通过安装 -debuginfo 或 -dbgsym 包解决,例如对于 fio:
# centos 上,先使能 yum 的 debuginfo 源,再安装对应应用的 -debuginfo 包即可
$ cat /etc/yum.repos.d/CentOS-Linux-Debuginfo.repo
[debuginfo]
name=CentOS Linux $releasever - Debuginfo
baseurl=http://debuginfo.centos.org/$releasever/$basearch/
gpgcheck=0
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
$ yum clean all && yum makecache
$ yum -y install fio-debuginfo.x86_64# ubuntu 上,先导入调试符号签名密钥,再安装对应应用的 -dbgsym 包即可
$ apt install ubuntu-dbgsym-keyring
$ apt install fio-dbgsym
补全后的栈如下所示:
$ perf script -i perf.data.dwarf
fio 2469 2823.211391: 250000 cpu-clock:pppH: 7f03631a89bd syscall+0x1d (/usr/lib64/libc-2.28.so)7f0363ef1c14 io_submit+0x34 (/usr/lib64/libaio.so.1.0.1)555976f418ce fio_libaio_commit+0xde (/usr/bin/fio)555976ef4a98 td_io_commit+0x58 (/usr/bin/fio)555976ef4fb5 td_io_queue+0x3f5 (/usr/bin/fio)555976f344ea do_io+0x71a (/usr/bin/fio)555976f36880 thread_main+0x18b0 (/usr/bin/fio)555976f38561 run_threads+0xcb1 (/usr/bin/fio)
后记
当你面对一个性能问题,如果选择使用 perf 观测,那么问题就变成了三个,另外两个是在解决性能问题前,必须先解决栈回溯和符号解析,前者影响观测准确性,后者影响观测可读性。perf 大部分时候都帮忙做好了,但如果遇到了些小困难,希望本文能有幸帮上一点忙。