前言:Hello大家好,我是Dream。 今天来学习一下机器学习实战中的案例:创建客户细分,在此过程中也会补充很多重要的知识点,欢迎大家一起前来探讨学习~
一、导入数据
在此项目中,我们使用 UCI 机器学习代码库中的数据集。该数据集包含关于来自多种产品类别的各种客户年度消费额(货币单位计价)的数据。该项目的目标之一是准确地描述与批发商进行交易的不同类型的客户之间的差别。这样可以使分销商清晰地了解如何安排送货服务,以便满足每位客户的需求。对于此项目,我们将忽略特征 'Channel' 和 'Region',重点分析记录的六个客户产品类别。
# Import libraries necessary for this project
import numpy as np
import pandas as pd
from IPython.display import display # Allows the use of display() for DataFrames
import visuals as vs
%matplotlib inline
try:data = pd.read_csv("customers.csv")data.drop(['Region', 'Channel'], axis = 1, inplace = True)print("Wholesale customers dataset has {} samples with {} features each.".format(*data.shape))
except:print("Dataset could not be loaded. Is the dataset missing?")
Wholesale customers dataset has 440 samples with 6 features each.
二、分析数据
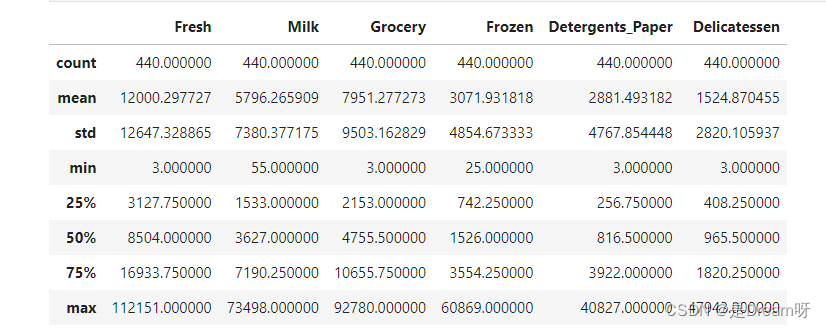
我们通过可视化图表和代码开始探索数据,并了解每个特征相互之间的关系。观察数据集的统计学描述内容。注意数据集由 6 个重要的产品类别构成:“Fresh”、“Milk”、“Grocery”、“Frozen”、“Detergents_Paper”和“Delicatessen”。思考每个类别代表你可以购买的哪些产品。
# Display a description of the dataset
display(data.describe())
选择样本
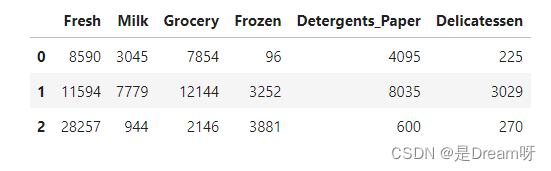
为了更好地通过分析了解客户以及他们的数据会如何变化,最好的方式是选择几个样本数据点并更详细地分析这些数据点。向 indices 列表中添加三个你所选的索引,表示将跟踪的客户。
# TODO: Select three indices of your choice you wish to sample from the dataset
indices = [60,100,380]
samples = pd.DataFrame(data.loc[indices], columns = data.keys()).reset_index(drop = True)
print("Chosen samples of wholesale customers dataset:")
display(samples)
Chosen samples of wholesale customers dataset:
benchmark = data.mean()
((samples-benchmark) / benchmark).plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x234812d7320>

# TODO: Apply PCA by fitting the good data with the same number of dimensions as features
from sklearn.decomposition import PCA
log_data = np.log(samples)
log_samples = np.log(log_data)
pca = PCA(n_components=6)
pca.fit(log_data)pca_samples = pca.transform(log_samples)pca_results = vs.pca_results(log_data, pca)
- 你所选的每个样本可以代表什么样的(客户)场所?
提示: 场所示例包括市场、咖啡厅、熟食店、零售店等地点。避免使用具体的名称,例如在将样本客户描述为餐厅时使用“麦当劳”。可以使用参考均值与你的样本进行比较。均值如下所示:
- Fresh:12000.2977
- Milk:5796.2
- Grocery:7951.28
- Frozen:3071.9
- Detergents_paper:2881.4
- Delicatessen:1524.8
-
样本0:Detergents_Paper在75%,Fresh、Milk接近中位数、Grocery接近均值、 Delicatessen和Frozen比较少,推断是零售店;
-
样本1:Detergents_Paper、Fresh、Milk、Grocery、 Delicatessen和Frozen所有特征都在均值以上,但是没有哪样特别多,推断是大型超市;
-
样本2:Fresh超过75%、Frozen为均值附近、其他特征较少,推测是新鲜肉菜市场;
特征相关性
一个值得考虑的有趣问题是,在六个产品类别中是否有一个(或多个)类别实际上在了解客户购买情况时相互有关联性。也就是说,是否能够判断购买一定量的某个类别产品的客户也一定会购买数量成比例的其他类别的产品?我们可以通过以下方式轻松地做出这一判断:删除某个特征,并用一部分数据训练监督式回归学习器,然后对模型评估所删除特征的效果进行评分。
- 通过使用
DataFrame.drop函数删除你所选的特征,为new_data分配一个数据副本。 - 使用
sklearn.cross_validation.train_test_split将数据集拆分为训练集和测试集。- 使用删除的特征作为目标标签。将
test_size设为0.25并设置random_state。
- 使用删除的特征作为目标标签。将
- 导入决策树回归器,设置
random_state,并将学习器拟合到训练数据中。 - 使用回归器
score函数报告测试集的预测分数。
# TODO: Make a copy of the DataFrame, using the 'drop' function to drop the given feature
from sklearn.metrics import accuracy_score
from sklearn import tree
y = data['Detergents_Paper']
new_data = data.copy()new_data.drop(['Detergents_Paper'], axis = 1, inplace = True)from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(new_data, y,test_size=.25,random_state=50)regressor = tree.DecisionTreeRegressor(random_state=10)
regressor.fit(X_train,y_train)
score = regressor.score(X_test,y_test)
print("预测分数:",score)
预测分数: 0.8017669397135979
1:你尝试预测的是哪个特征?
回答: Detergents_Paper
2:报告的预测分数是多少?
回答: 0.801766939714
3:该特征对确定客户的消费习惯有影响吗?
回答: Detergents_Paper=0.801拟合性表现很好;说明这个特征与其他特征相关性不重要;对消费习惯有一定影响,但可以用其他特征体现。
确定系数 R^2 的范围是 0 到 1,1 表示完美拟合。负的 R^2 表示模型无法拟合数据。如果特定特征的分数很低,则表明使用其他特征很难预测该特征点,因此在考虑相关性时这个特征很重要。
可视化特征分布图
为了更好地理解数据集,我们可以为数据中的六个产品特征分别构建一个散布矩阵。如果你发现你在上面尝试预测的特征与识别特定客户有关,那么下面的散布矩阵可能会显示该特征与其他特征之间没有任何关系。相反,如果你认为该特征与识别特定客户不相关,散布矩阵可能会显示该特征与数据中的另一个特征有关系。运行以下代码块,以生成散布矩阵。
# Produce a scatter matrix for each pair of features in the data
pd.plotting.scatter_matrix(data, alpha = 0.3, figsize = (14,8), diagonal = 'kde');

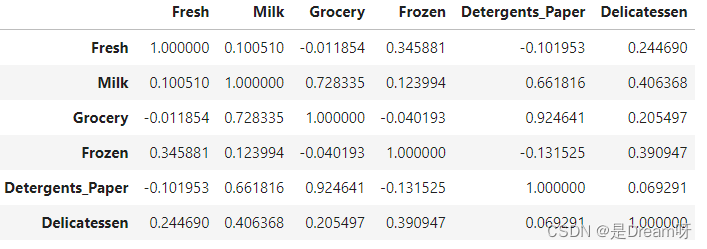
data.corr()
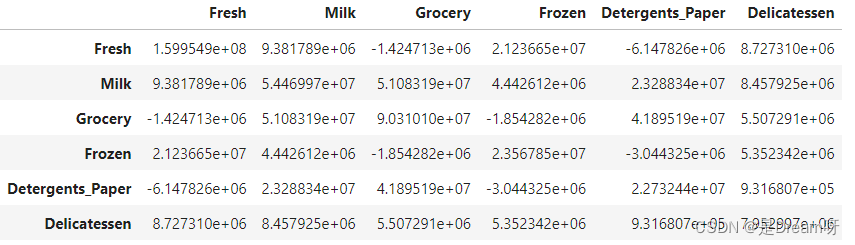
data.cov()
- 将散布矩阵作为参考,讨论数据集的分布情况,尤其是正态性、离群值、大量接近 0 的数据点等。如果你需要区分某些图表,以便进一步阐述你的观点,也可以这么做。
Grocery和Detergents_Paper相关性强;Grocery和Milk也有一定的相关性。具体可以通过data.corr()显示的数据,越接近1的相关性越强;
数据的分布不是正态性,大部分数据集中在8000以内,离群的数据只有一小部分;
三、数据预处理
在此部分,预处理数据(对数据进行缩放并检测离群值,或许还会删除离群值),以便更好地表示客户数据。预处理数据通常是很关键的步骤,可以确保通过分析获得的结果有显著统计意义。
特征缩放
如果数据不是正态分布数据,尤其是如果均值和中值差别很大(表明非常偏斜),通常[比较合适的方法]是应用非线性缩放——尤其是对金融数据来说。实现这种缩放的一种方式是采用[博克斯-卡克斯检定],该检定会计算能缩小偏斜情况的最佳次方转换方式。适合大多数情况的更简单方式是采用自然对数。
- 通过应用对数缩放将数据副本赋值给
log_data。你可以使用np.log函数完成这一步。 - 在应用对数缩放后,将样本数据副本赋值给
log_samples。同样使用np.log。
# TODO: Scale the data using the natural logarithm
log_data = np.log(data)log_samples = np.log(samples)pd.plotting.scatter_matrix(log_data, alpha = 0.3, figsize = (14,8), diagonal = 'kde');
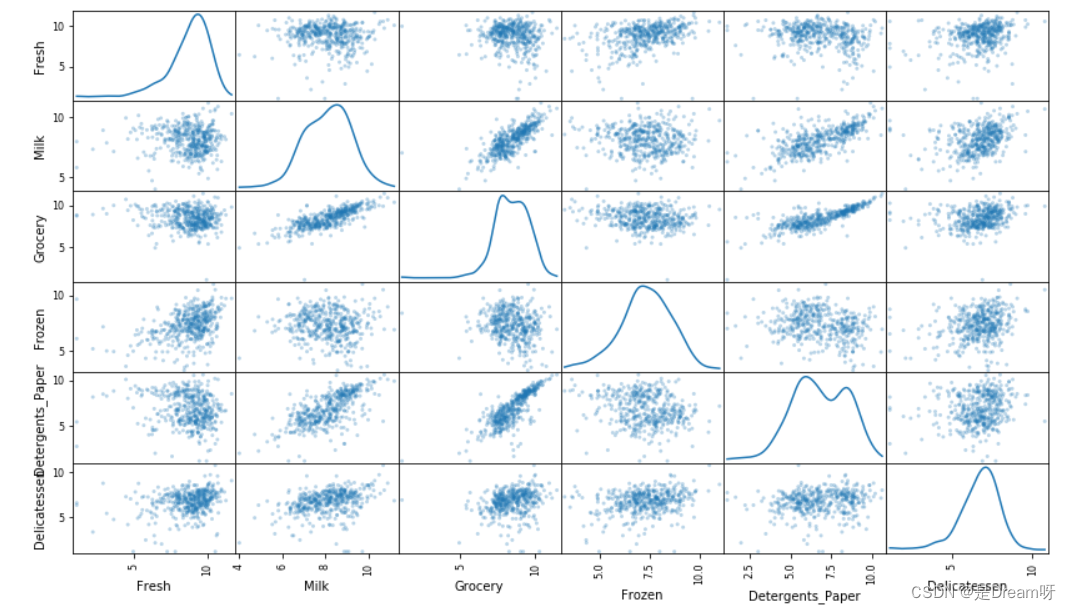
观察
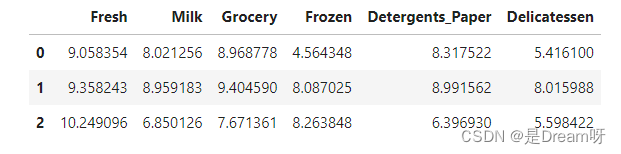
在对数据应用自然对数缩放后,每个特征的分布应该看起来很正态了。对于之前可能发现相互有关联的任何特征对,在此部分观察这种联系是否依然存在:
# Display the log-transformed sample data
display(log_samples)
检测离群值
对于任何分享的数据预处理步骤来说,检测数据中的离群值都极为重要。如果结果考虑了离群值,那么这些离群值通常都会使结果出现偏斜。在判断什么样的数据属于离群值时,可以采用很多“一般规则”。在此项目中,我们将使用 Tukey 方法检测离群值:离群值步长等于 1.5 倍四分位距 (IQR)。如果某个数据点的特征超出了该特征的离群值步长范围,则该特征属于异常特征。
- 将给定特征的第 25 百分位值赋值给
Q1。 为此,请使用np.percentile。 - 将给定特征的第 75 百分位值赋值给
Q3。同样使用np.percentile。 - 将给定特征的离群值步长计算结果赋值给
step。 - (可选步骤)通过向
outliers列表添加索引,从数据集中删除某些数据点。
注意: 如果你选择删除任何离群值,确保样本数据不包含任何此类数据点! 实现这一步骤后,数据集将存储在变量 good_data 中。
# For each feature find the data points with extreme high or low values
for feature in log_data.keys():f_s = log_data[feature]Q1 =np.percentile(f_s,25)Q3 = np.percentile(f_s,75)step = 1.5 * (Q3 - Q1)print("Data points considered outliers for the feature '{}':".format(feature))display(log_data[~((log_data[feature] >= Q1 - step) & (log_data[feature] <= Q3 + step))])outliers = [65,66,75,128,154]
good_data = log_data.drop(log_data.index[outliers]).reset_index(drop = True)
Data points considered outliers for the feature ‘Fresh’:
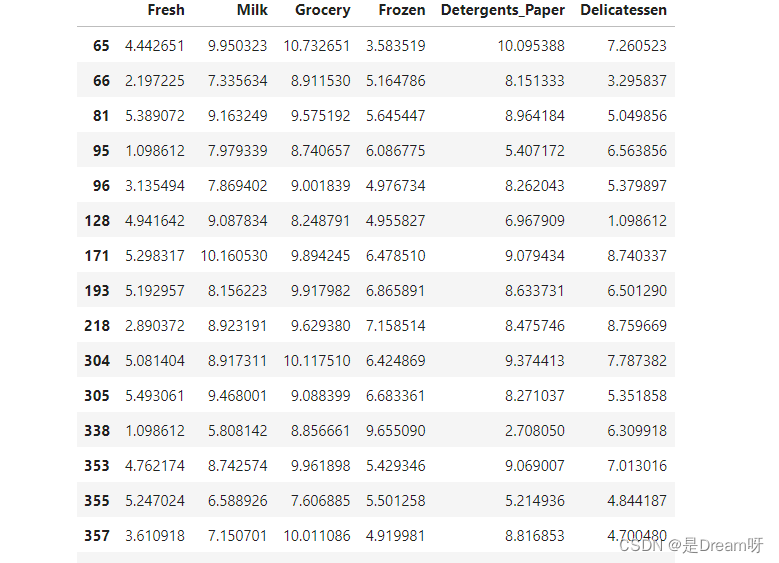
Data points considered outliers for the feature ‘Milk’:

Data points considered outliers for the feature ‘Grocery’:

Data points considered outliers for the feature ‘Frozen’:
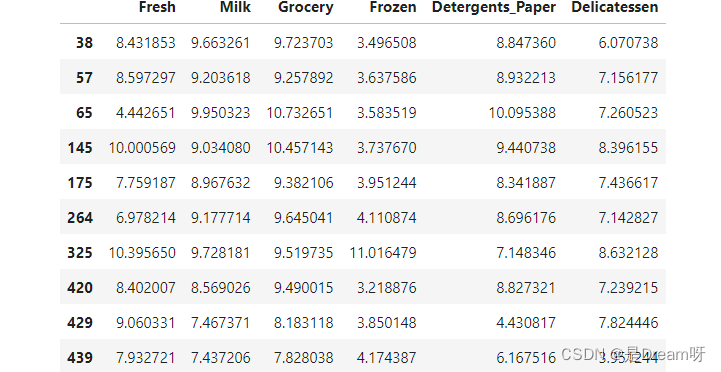
Data points considered outliers for the feature ‘Detergents_Paper’:

Data points considered outliers for the feature ‘Delicatessen’:
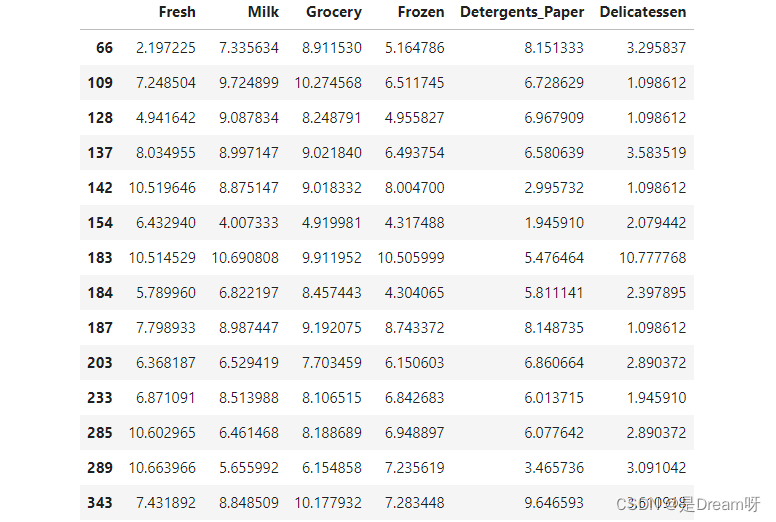
## 计算大于等于两次的异常数据
def caltwiceoutliers(row):out = 0for feature in log_data.keys():p = row[feature]f = log_data[feature]Q1 = np.percentile(f,25)Q3 = np.percentile(f,75)step = 1.5*(Q3-Q1)if (p <= Q1 - step) or (p >= Q3 + step): out += 1return out > 1 lst = []
for i,row in log_data.iterrows():if caltwiceoutliers(row): lst.append(i)
display(log_data.loc[lst])
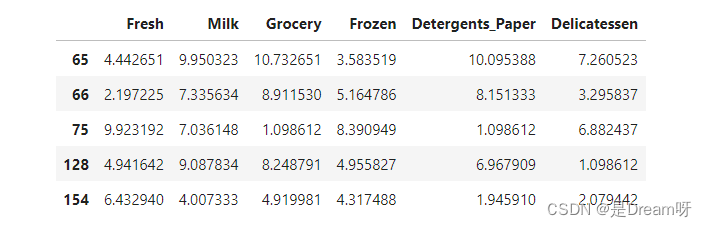
[65,66,75,128,154]这几个样本在不同的特征上都超出离群值步长范围,表现为异常特征。删除前后对于PCA最大方差的数值并见影响,所以可以不删除。
四、特征转换
在此部分,利用主成分分析 (PCA) 得出批发客户数据的基本结构。因为对数据集使用 PCA 会计算哪些维度最适合最大化方差,我们将发现哪些特征组合最能描述客户。
实现:PCA
现在数据已经缩放为更正态的分布,并且删除了任何需要删除的离群值,现在可以向 good_data 应用 PCA,以发现哪些数据维度最适合最大化所涉及的特征的方差。除了发现这些维度之外,PCA 还将报告每个维度的可解释方差比——数据中有多少方差可以仅通过该维度进行解释。注意 PCA 的成分(维度)可以视为空间的新“特征”,但是它是数据中存在的原始特征的成分:
- 导入
sklearn.decomposition.PCA并将对good_data进行六维度 PCA 转化的结果赋值给pca。 - 使用
pca.transform对log_samples应用 PCA 转化,并将结果赋值给pca_samples。
# TODO: Apply PCA by fitting the good data with the same number of dimensions as features
from sklearn.decomposition import PCA
good_data = log_data
pca = PCA(n_components=6)
pca.fit(good_data)pca_samples = pca.transform(log_samples)pca_results = vs.pca_results(good_data, pca)
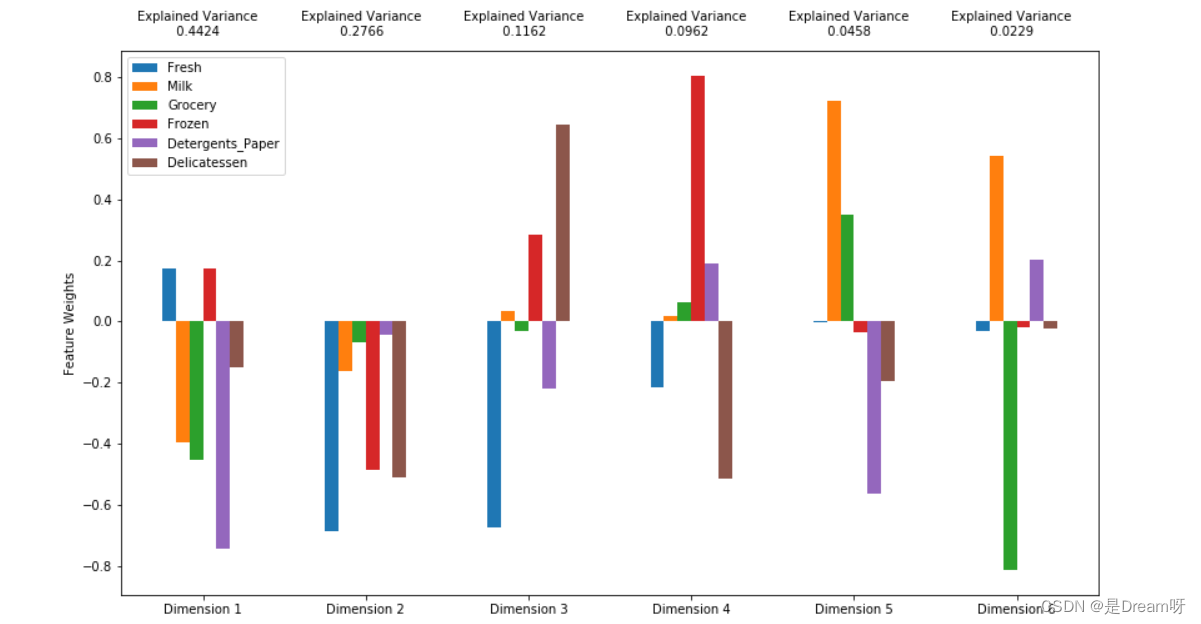
内容补充
- 由第一个主成分和第二个主成分解释的数据方差* 总量 *是多少?
- 第一个主成分和第二个主成分解释的数据方差总量是:0.719;
- 前四个主成分解释的数据方差是多少?
- 前四个主成分解释的数据方差是0.9314;
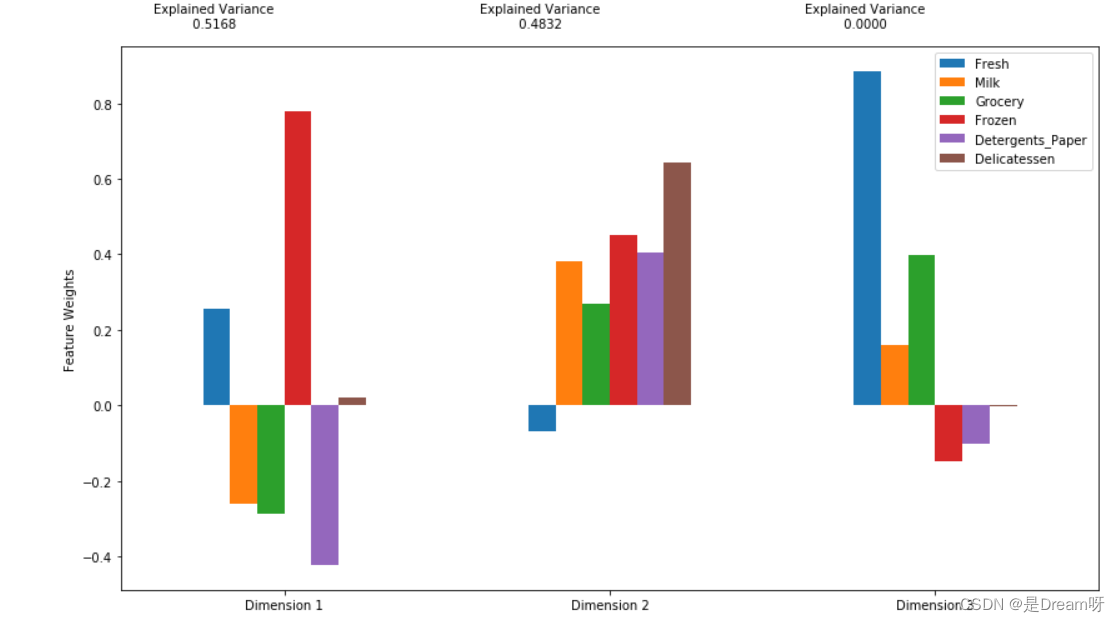
- 使用上面提供的可视化图表描述每个维度和每个维度解释的累积方程,侧重于每个维度最能表示哪些特征(包括能解释的正方差和负方差)。讨论前四个维度最能表示什么样的客户消费规律。
-
维度一特征权重高的:清洁剂,牛奶,杂货,代表客户为零售商店。
-
维度二特征权重高的:新鲜食品,冷冻食品,和熟食 代表客户为餐厅。
-
维度三特征权重高的:新鲜食品、熟食 代表客户为快餐店
-
维度四特征权重高的:冷冻食品,熟食为主 代表客户为西餐厅
特定维度的正增长对应的是正加权特征的增长以及负加权特征的降低。增长或降低比例由具体的特征权重决定。
观察
运行以下代码,看看经过对数转换的样本数据在六维空间里应用 PCA 转换后有何变化:
# Display sample log-data after having a PCA transformation applied
display(pd.DataFrame(np.round(pca_samples, 4), columns = pca_results.index.values))

降维
在使用主成分分析时,主要目标之一是降低数据维度,以便降低问题的复杂度。降维有一定的代价:使用的维度越少,则解释的总方差就越少。因此,为了了解有多少个维度对问题来说是必要维度,累积可解释方差比显得极为重要。此外,如果大量方差仅通过两个或三个维度进行了解释,则缩减的数据可以之后可视化:
- 将对
good_data进行二维拟合 PCA 转换的结果赋值给pca。 - 使用
pca.transform对good_data进行 PCA 转换,并将结果赋值给reduced_data。 - 使用
pca.transform应用log_samplesPCA 转换,并将结果赋值给pca_samples。
# TODO: Apply PCA by fitting the good data with only two dimensions
pca = PCA(n_components=2)
pca.fit(good_data)
# TODO: Transform the good data using the PCA fit above
reduced_data = pca.transform(good_data)
# TODO: Transform log_samples using the PCA fit above
pca_samples = pca.transform(log_samples)reduced_data = pd.DataFrame(reduced_data, columns = ['Dimension 1', 'Dimension 2'])
观察前两个维度的值与六维空间里的 PCA 转换相比如何没有变化:
# Display sample log-data after applying PCA transformation in two dimensions
display(pd.DataFrame(np.round(pca_samples, 4), columns = ['Dimension 1', 'Dimension 2']))
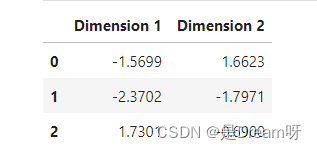
五、可视化双标图
双标图是一种散点图,每个数据点由主成分上的分数表示。坐标轴是主成分(在此图中是 Dimension 1 和 Dimension 2)。此外,双标图显示了原始特征沿着成分的投影情况。双标图可以帮助我们解释降维数据,并发现主成分与原始特征之间的关系。
以生成降维数据双标图:
# Create a biplot
vs.biplot(good_data, reduced_data, pca)
<matplotlib.axes._subplots.AxesSubplot at 0x23480c59898>
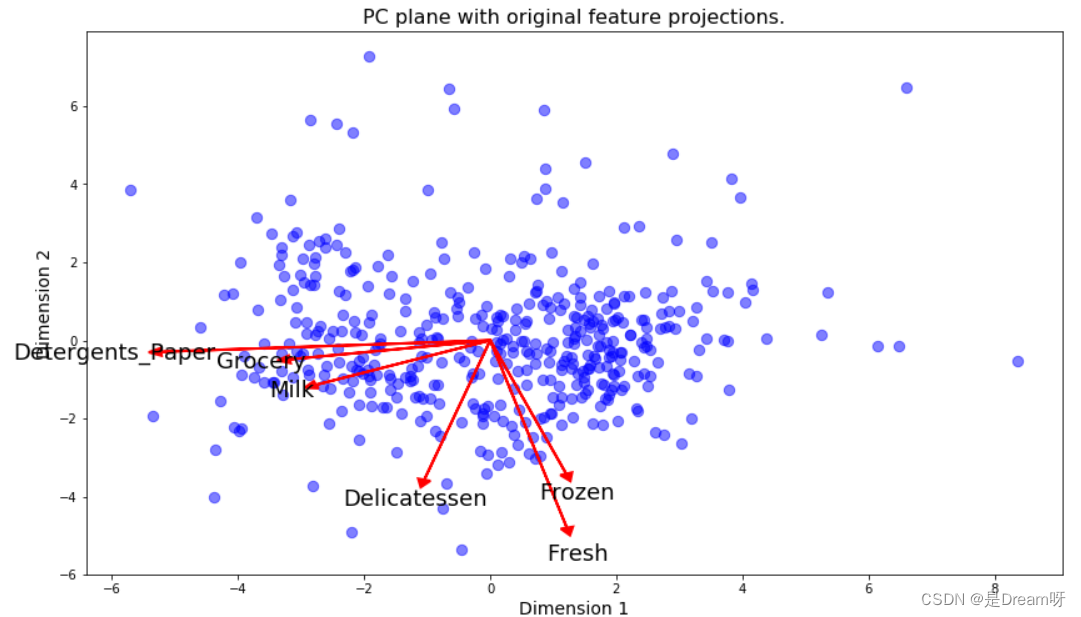
获得原始特征投影(红色部分)后,更容易解释每个点在散点图中的相对位置。例如,图中右下角的点更有可能对应于在 'Milk'、'Grocery' 和 'Detergents_Paper' 上花费很多、但是在其他产品类别上花费不多的客户。
六、聚类
在此部分,使用 K 均值聚类算法或高斯混合模型聚类算法发现数据中隐藏的各种客户细分。通过将数据点重新转换成原始维度和范围,从聚类中还原具体的数据点以了解它们的显著性。
k-means 算法优的势:
-
是解决聚类问题的一种经典算法,简单、快速
-
对处理大数据集,该算法保持可伸缩性和高效性
-
聚类是密集的,且类与类之间区别明显时,效果较好。
高斯混合模型聚类算法的优势:
-
类区别划分不是那么明显时
-
计算快,是学习混合模型最快的算法
-
低偏差,不容易欠拟合
由于Kmeans的优势是密集型类与类之间区别明显时效果较好,本数据离散值比较多,而且有很多相同属性,所以采用高斯混合模型聚类算法。
创建聚类
根据具体的问题,预计从数据中发现的距离数量可能是已知的数量。如果无法根据先验判断聚类的数量,则无法保证给定的聚类数量能够以最佳方式细分数据,因为不清楚数据存在什么样的结构。但是,我们可以根据每个数据点的轮廓系数量化聚类的“优势” 。数据点的[轮廓系数]会衡量数据点与所分配的聚类之间的相似度,程度用 -1(不相似)到 1(相似) 表示。计算均值轮廓系数是对给定聚类进评分的简单方法:
- 对
reduced_data应用聚类算法并将结果赋值给clusterer。 - 使用
clusterer.predict预测reduced_data中每个数据点的聚类,并将它们赋值给preds。 - 使用算法的相应属性得出聚类中心,并将它们赋值给
centers。 - 预测
pca_samples中每个样本数据点的聚类,并将它们赋值给sample_preds。 - 导入
sklearn.metrics.silhouette_score并对照preds计算reduced_data的轮廓分数。- 将轮廓分数赋值给
score并输出结果。
- 将轮廓分数赋值给
# TODO: Apply your clustering algorithm of choice to the reduced data
from sklearn.mixture import GaussianMixture
from sklearn.metrics import silhouette_score
best_score =0
for i in [2, 3, 4, 5, 6, 7, 8]:clusterer = GaussianMixture(n_components=i, random_state=0)clusterer.fit(reduced_data)preds = clusterer.predict(reduced_data)centers = clusterer.means_sample_preds = clusterer.predict(pca_samples)#边界系数,[-1, 1] 越大越清晰score = silhouette_score(reduced_data, preds)print("For clusters = ", i,"The score is :", score)if (score > best_score):best_clusterer = clustererbest_score = scorebest_cluster = iprint("For clusters = ",best_clusterer.n_components,'The score is best!')
For clusters = 2 The score is : 0.4099683245278784
For clusters = 3 The score is : 0.40194571937717044
For clusters = 4 The score is : 0.31214203486720543
For clusters = 5 The score is : 0.276392991643947
For clusters = 6 The score is : 0.30088433392758923
For clusters = 7 The score is : 0.22666071211515948
For clusters = 8 The score is : 0.26631198668498973
For clusters = 2 The score is best!
聚类可视化
使用上述评分指标为你的聚类算法选择最佳聚类数量后,可视化结果:
# Display the results of the clustering from implementation
vs.cluster_results(reduced_data, preds, centers, pca_samples)
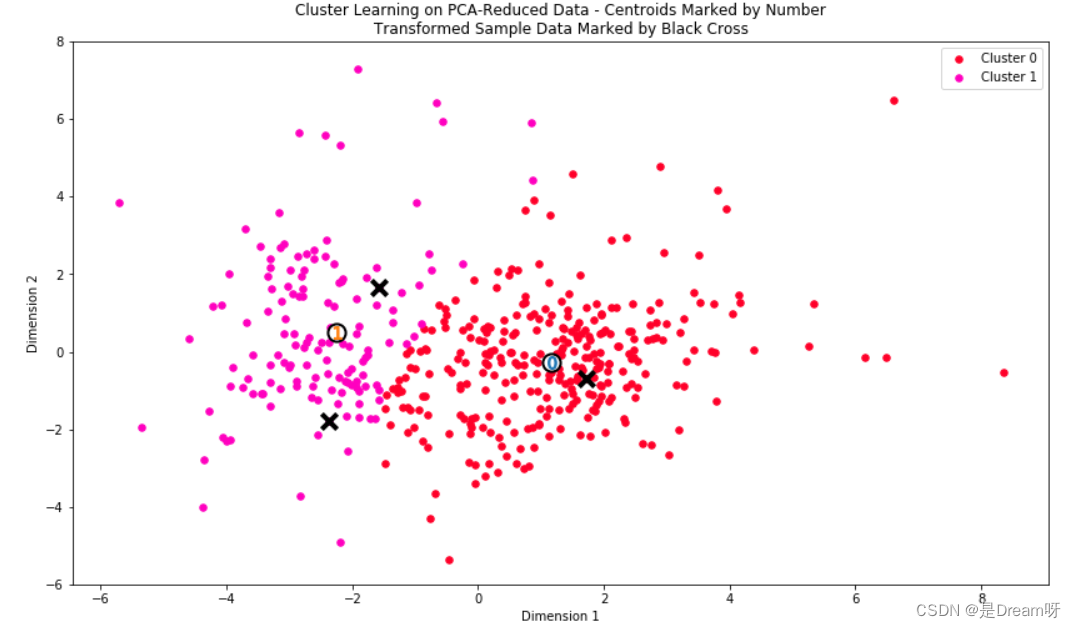
数据恢复
上述可视化图表中出现的每个聚类都有一个中心点。这些中心(或均值)并不是来自数据中的特定数据点,而是相应聚类预测的所有数据点的平均值。对于创建客户细分这个问题来说,聚类的中心点对应的是该细分的平均客户数量。因为数据目前是降维状态并且进行了对数缩放,我们可以通过应用逆转换从这些数据点中还原代表性客户支出:
- 使用
pca.inverse_transform对centers应用逆转换,并将新的中心点赋值给log_centers。 - 使用
np.exp对log_centers应用np.log的逆函数,并将真正的中心点赋值给true_centers。
# TODO: Inverse transform the centers
log_centers = pca.inverse_transform(centers)true_centers = np.exp(log_centers)segments = ['Segment {}'.format(i) for i in range(0,len(centers))]
true_centers = pd.DataFrame(np.round(true_centers), columns = data.keys())
true_centers.index = segments
display(true_centers)
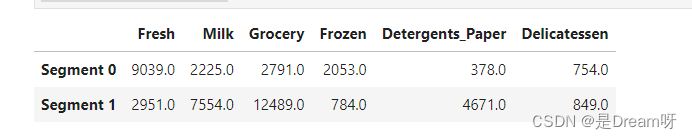
思考上述代表性数据点的每个产品类别的总购买成本,并参考该项目开头的数据集统计学描述(具体而言,查看各个特征点的均值)。每个客户细分可以表示什么样的场所集合?
-
segment0 Fres、Milk、Grocery、Frozen、Detergents_Paper和Delicatessen所有特征的均少于均值应该是小型零售店;
-
segment1 Milk、Detergents_Paper、Grocery 超过均值、其他均低于平均值数,应该代表牛奶咖啡厅;
看看每个样本点预测属于哪个聚类:
# Display the predictions
for i, pred in enumerate(sample_preds):print("Sample point", i, "predicted to be in Cluster", pred)
Sample point 0 predicted to be in Cluster 1
Sample point 1 predicted to be in Cluster 1
Sample point 2 predicted to be in Cluster 0
display(pd.concat([true_centers,samples]))
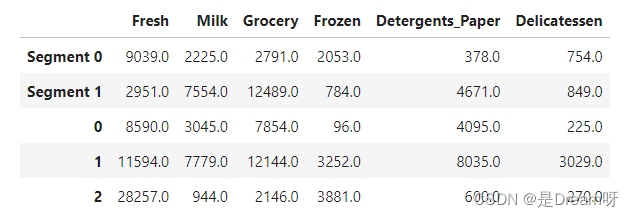
样本0和样本1 在Detergents_papaer,Grocery,Milk,更接近聚类1的中心点,其他可能更聚类1样本2在Fresh,Detergents_Paper,Frozen,Grocery,Milk均接近聚类0的中心点,更可能属于类别0。每个样本点的预测与此细分保持一致
七、总结
在最后一部分,研究可以对聚类数据采用的方式。思考特定的送货方案对不同的客户群(即客户细分)有何不同影响。以及思考为每个客户设定标签(该客户属于哪个细分)可以如何提供关于客户数据的额外特征。最后,比较客户细分和数据中的隐藏变量,看看聚类分析是否发现了特定的关系。
可视化底层分布图
在该项目开始时,我们提到我们会从数据集中排除 'Channel' 和 'Region' 特征,以便在分析过程中侧重于客户产品类别。通过向数据集中重新引入 'Channel' 特征,在考虑之前对原始数据集应用的相同 PCA 降维算法时,发现了有趣的结构。
看看每个数据点在降维空间里为何标记成 'HoReCa'(酒店/餐厅/咖啡厅)或 'Retail'。此外,将发现样本数据点在图中被圈起来了,这样可以标识它们的标签。
# Display the clustering results based on 'Channel' data
vs.channel_results(reduced_data, outliers, pca_samples)
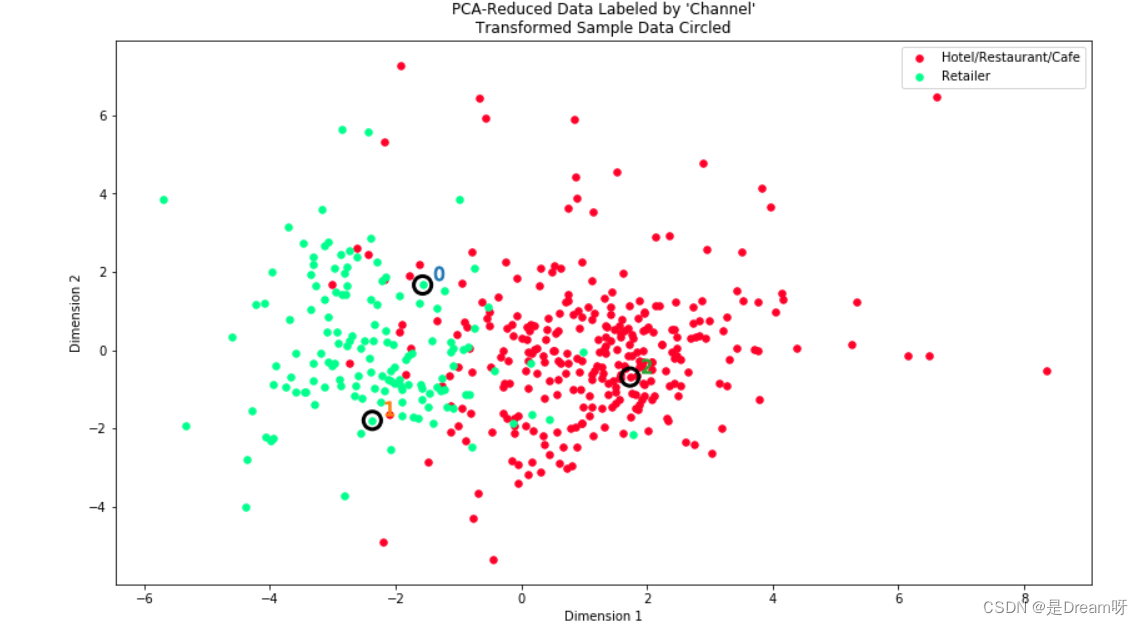
补充总结
我选择的聚类算法和聚类数量,与酒店/餐厅/咖啡厅客户和零售客户分布图相比,效果还不错,但也还存在一些异常数据。根据Dimension看到划分’零售客户’或者是’酒店/餐厅/咖啡厅客户’分布还不错。这些分类和之前的客户细分定义大体一致。但选择的样本数据点属于异常数据,咖啡厅购买的商品类别和其他餐馆不一致,而零售商由于没有特别类别的需求和购买量,基本上各种商品都比较少且杂,因此会处于边界周边。
文末免费送书福利
《机器学习平台架构实战》免费包邮送出3本!
内容介绍:
《机器学习平台架构实战》详细阐述了与机器学习平台架构相关的基本解决方案,主要包括机器学习和机器学习解决方案架构,机器学习的业务用例,机器学习算法,机器学习的数据管理,开源机器学习库,Kubernetes容器编排基础设施管理,开源机器学习平台,使用AWS机器学习服务构建数据科学环境,使用AWS机器学习服务构建企业机器学习架构,高级机器学习工程,机器学习治理、偏差、可解释性和隐私,使用人工智能服务和机器学习平台构建机器学习解决方案等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。

抽奖方式: 评论区随机抽取3位小伙伴免费送出!
参与方式: 关注博主、点赞、收藏、评论区评论“人生苦短,我用Python!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间: 2023-12-17 20:00:00
当当: https://product.dangdang.com/29625469.html
京东: https://item.jd.com/13855627.html
😄😄😄名单公布方式: 下期活动开始将在评论区和私信一并公布,中奖者请三天内提供信息😄😄😄