Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection
- 摘要
- 1.介绍
- 2.相关工作
- 异常检测
- Memory networks
- 3. Memory-augmented Autoencoder
- 3.1概述
- 3.2. Encoder and Decoder
- 3.3. Memory Module with Attention-based Sparse Addressing
- 3.3.1 Memory-based Representation
- 3.3.2 Attention for Memory Addressing
- 3.3.3 Hard Shrinkage for Sparse Addressing
- 3.4. Training
- 4.实验
- 4.1. Experiments on Image Data
- 4.2. Experiments on Video Anomaly Detection
- 4.3. Experiments on Cybersecurity Data
- 4.4. Ablation Studies
- 5.总结
- 6.阅读总结
文章信息:

发表于ICCV 2019
原文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Gong_Memorizing_Normality_to_Detect_Anomaly_Memory-Augmented_Deep_Autoencoder_for_Unsupervised_ICCV_2019_paper.pdf
源码链接:https://github.com/donggong1/memae-anomaly-detection
摘要
提出了一种改进的自编码器(Memory-Augmented Autoencoder,MemAE),用于异常检测。传统的深度自编码器在正常数据上训练,期望对于异常输入产生更高的重构误差,以此作为鉴别异常的标准。然而,在实践中,这个假设并不总是成立,有时自编码器的“泛化”效果很好,甚至可以很好地重构异常数据,导致漏检。为了克服这一自编码器异常检测方法的缺陷,文章提出了将自编码器与内存模块相结合的MemAE。
MemAE的基本思想是在训练阶段通过memory来存储和表示正常数据的原型元素,从而引入了对正常数据的更深层次的学习。具体而言,对于给定的输入,MemAE首先通过编码器获取编码,然后将其用作查询以检索用于重构的最相关的memory项。在训练阶段,memory内容会被更新,并被鼓励表示正常数据的原型元素。在测试阶段,学到的memory将保持固定,重构将从少数选择的正常数据的memory记录中获得。因此,重构将倾向于接近正常样本,从而增强了对异常的检测。
MemAE摆脱了对数据类型的假设,因此具有广泛适用性,可应用于不同的任务。实验证明了MemAE在各种数据集上的出色泛化能力和高效性。通过引入内存模块,MemAE在异常检测中取得了更好的性能,克服了传统自编码器在某些情况下过度泛化的问题。
1.介绍
异常检测是一项具有关键应用的重要任务,例如在视频监控领域。在无监督异常检测中,任务是仅根据正常数据示例学习正常模式,然后识别不符合正常模式的样本作为异常。这是一项具有挑战性的任务,因为缺乏人为监督。特别是当数据点位于高维空间(例如视频)时,问题变得更加困难,因为对高维数据建模通常非常具有挑战性。
深度自编码器(AE)是在无监督设置中对高维数据进行建模的强大工具。它包括一个编码器,用于从输入中获取压缩编码,以及一个解码器,可以从编码中重构数据。编码实质上充当了信息瓶颈,迫使网络提取高维数据的典型模式。在异常检测的背景下,AE通常通过最小化正常数据上的重构误差进行训练,然后使用重构误差作为异常的指标。通常假设重构误差对于正常输入会更低,因为它们接近训练数据,而对于异常输入则会更高。然而,这个假设并不总是成立,有时AE的“泛化”效果很好,甚至可以很好地重构异常输入。
为了缓解AE的缺点,文章提出了通过memory模块增强深度自编码器的方法,并引入了一种新模型,即Memory-Augmented Autoencoder(MemAE)。在MemAE中,给定一个输入,不直接将其编码馈送到解码器,而是将其用作查询以检索memory中最相关的项目。这些项目然后被聚合并传递给解码器。具体来说,这个过程通过使用基于注意力的memory寻址实现。作者进一步提出使用可微分的硬收缩运算符来引入memory寻址权重的稀疏性,这隐含地鼓励memory项在特征空间中接近查询。在MemAE的训练阶段,memory内容将与编码器和解码器一起进行更新。由于稀疏寻址策略,MemAE模型被鼓励以最优和高效的方式使用有限数量的内存槽,使memory记录充当正常训练数据中原型正常模式的记录,从而获得低平均重构误差。在测试阶段,学到的memory内容是固定的,重构将使用少数选择的正常内存项进行,这些项被选为输入编码的邻域。由于重构是从memory中的正常模式获得的,因此它倾向于接近正常数据。因此,如果输入与正常数据不相似,即异常,重构误差趋于突出。
提出的MemAE不受数据类型的假设限制,因此可以广泛应用于解决不同任务。在各种来自不同应用领域的公共异常检测数据集上,作者进行了广泛的实验证明了MemAE的出色泛化能力和高效性。
总结:通过memory模块自编码器,同时memory使用稀疏寻址的方式,简单来说就弱化一些特征,只取强的特征。
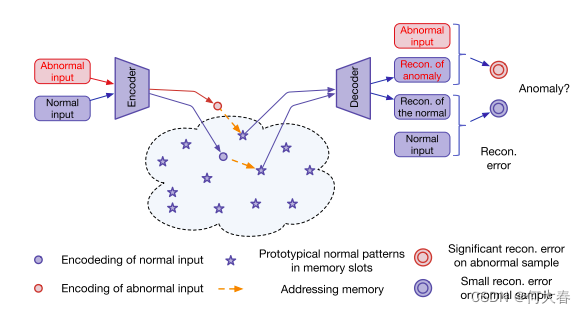
图1:MemAE架构(在训练完之后,memory记录了正常视频的正常模式)
2.相关工作
异常检测
这个不多说了
Memory networks
记忆增强网络已经引起了越来越多的关注,用于解决不同的问题[8, 38, 32]。Graves等人[8]使用外部memory扩展神经网络的能力,其中使用基于内容的注意力来寻址内存。考虑到memory可以稳定地记录信息,Santoro等人[32]使用memory网络来处理一次性学习的问题。外部memory还被用于多模态数据生成[14, 20],以规避模式崩溃问题并保留详细的数据结构。
3. Memory-augmented Autoencoder
3.1概述
提出的MemAE模型由三个主要组件组成 - 编码器(用于对输入进行编码和生成查询),解码器(用于重构)和memory模块(带有内存和相关内存寻址运算符)。如图2所示,给定一个输入,编码器首先获取输入的编码。通过使用编码表示作为查询,memory模块通过基于注意力的寻址运算符检索memory中最相关的项目,然后将它们传递给解码器进行重构。在训练期间,编码器和解码器被优化以最小化重构误差。同时更新memory内容以记录编码正常数据的原型元素。给定一个测试样本,模型仅使用memory中记录的有限数量的正常模式进行重构。因此,重构倾向于接近正常样本,导致正常样本的重构误差较小,而异常样本的误差较大,这将被用作检测异常的标准。
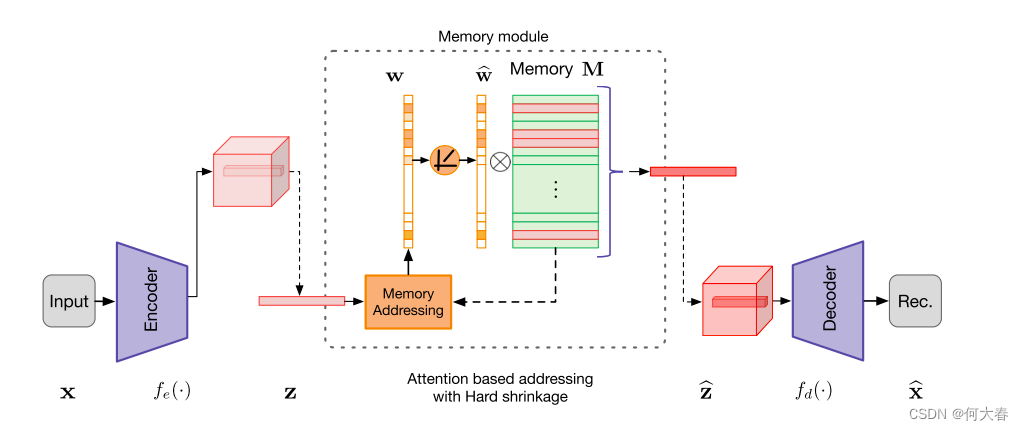
图2:拟建MemAE示意图。存储器寻址单元以编码z作为查询,得到软寻址权值。内存槽可以用于对整个编码或编码的一个像素上的特征进行建模(如图所示)。请注意 w ^ \widehat{w} w 在硬收缩操作之后被归一化。
3.2. Encoder and Decoder
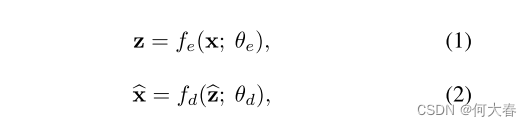
结合图2: f e ( ⋅ ) f_e(·) fe(⋅)表示编码器, f d ( ⋅ ) f_d(·) fd(⋅)表示解码器。x为输入, z ^ \widehat{z} z 为z经过memory处理过后的结果, θ e θ_e θe和 θ d θ_d θd分别为编码器和解码器的参数。
3.3. Memory Module with Attention-based Sparse Addressing
所提出的存储器模块由一个用于记录原型编码模式的存储器和一个用于访问存储器的基于注意力的寻址算子组成。
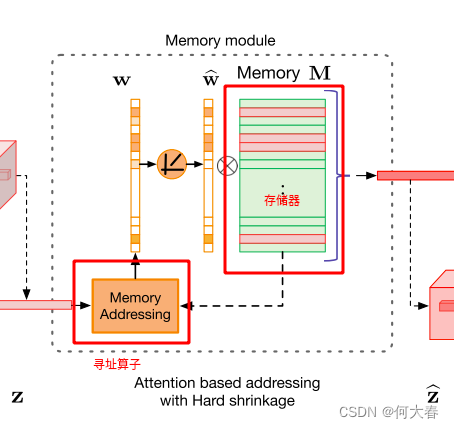
3.3.1 Memory-based Representation
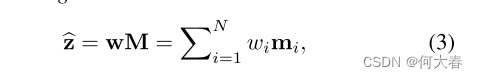
给定一个查询),经过存储器网络得到 z ^ \widehat{z} z
其中w是具有和为1的非负条目的行向量, w i w_i wi表示w的第i个条目。根据z计算权重向量w。如等式(3)所示,访问存储器需要寻址权重w。超参数N定义了存储器的最大容量。作者的实验表明,MemAE对N,也就是memory的存储大小并不是很敏感。
3.3.2 Attention for Memory Addressing
在MemAE中,存储器M被设计为明确记录训练期间的原型正常模式。我们将存储器定义为具有寻址方案的内容可寻址存储器[38,29],该寻址方案基于存储器项和查询z的相似性来计算注意力权重w。如图1所示,我们通过softmax运算来计算每个权重 w i w_i wi:
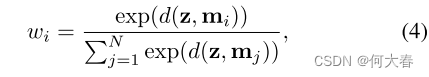
d ( ⋅ , ⋅ ) d(·,·) d(⋅,⋅)是余弦相似度,定义如下:
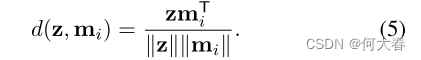
在训练阶段,MemAE中的解码器被限制为仅使用极少数被寻址的存储器项来执行重构,从而满足了对存储器项的有效利用的要求。因此,重建监督迫使存储器记录输入正常模式中最具代表性的原型模式
在测试阶段,给定训练过的存储器,只能检索存储器中的正常模式进行重建。因此,正常样本自然可以很好地重建。相反,异常输入的编码将被检索到的正常模式所取代,从而导致异常的显著重建错误。
3.3.3 Hard Shrinkage for Sparse Addressing
一些异常可能依旧会重构的非常好,对此作者对w采用了稀疏压缩策略,如公式所示:
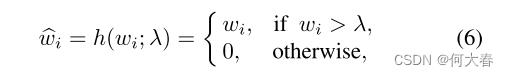
就是将权重向量 w i w_i wi如果小于等于 λ \lambda λ,则置为。排除一些特征。如图,抹去一些相关性低的特征:
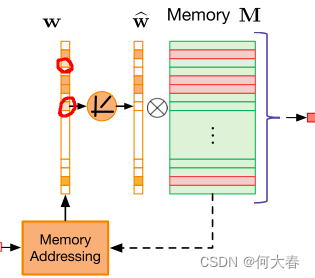
w ^ i \widehat{w}_i w i为压缩后的权重向量。
考虑到w都是非负的,使用RULE函数更简单,公式变成下面的了:
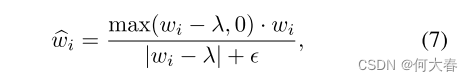
这种寻址方式只需要前向传播就可以更新了,而不需要反向传播。
3.4. Training
损失函数有两部分组成
重构误差
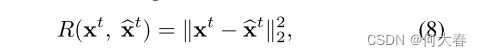
最小化 w ^ i \widehat{w}_i w i的熵
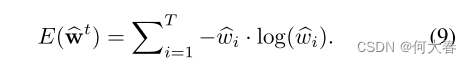
目的是:通过调整或优化 w ^ i \widehat{w}_i w i的值,使得相关的概率分布变得更加确定或不那么随机。
4.实验
作者做了三个实验,一个是在图像上异常检测,一个是在视频上的异常检测、还有一个实在网络安全方面的异常检测,这个不太了解。
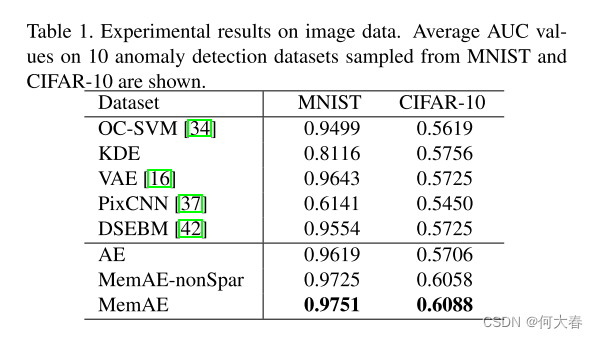
4.1. Experiments on Image Data
分别在MNIST和CIFAR-10两个数据集上进行了测试。具体实验设置参考原论文,效果如下:
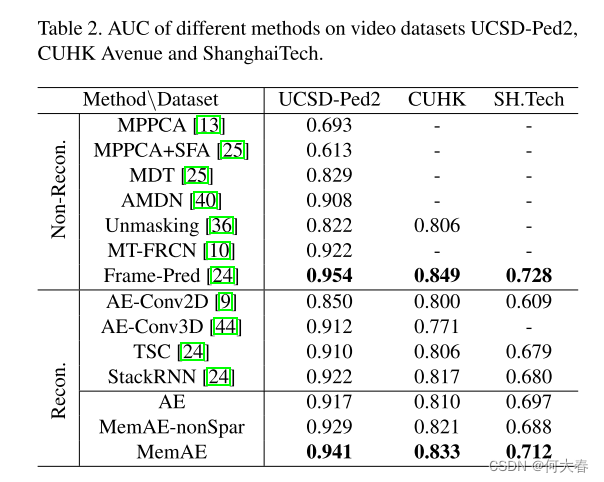
4.2. Experiments on Video Anomaly Detection
分别在Ped2、CUHK、SH.Tech三个数据集上进行了测试。效果如下
4.3. Experiments on Cybersecurity Data
略
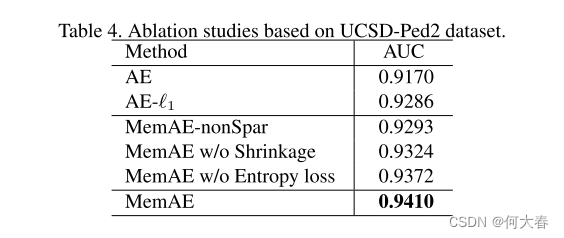
4.4. Ablation Studies
作者对自己提出的模块进行了消融实验,分别对memory和稀疏压缩、熵loss进行了控制变量,结果如下:
5.总结
- 提出了一个memory moudle模块
- 提出了一个稀疏性压缩
- 使用了熵减loss
6.阅读总结
这篇和前面的两篇思想都是有很大相似性的:引入memory moudle模块,在memory moudle所在的位置和更新策略上有不同的点,损失函数也有一些变化。
2020 cvpr Learning Memory-guided Normality for Anomaly Detection 论文阅读
2021 cvpr Learning Normal Dynamics in Videos with Meta Prototype Network 论文阅读