引言
今天利用MatchPyramid实现文本匹配。
原论文解析→点此←。
MatchPyramid
核心思想是计算两段文本间的匹配矩阵,把它当成一个图形利用多层卷积网络提取不同层级的交互模式。
匹配矩阵是通过计算两段输入文本基本单元(比如字或词)之间相似度得到的,作者提出了三种相似度计算函数。我们的实现采用余弦相似度。
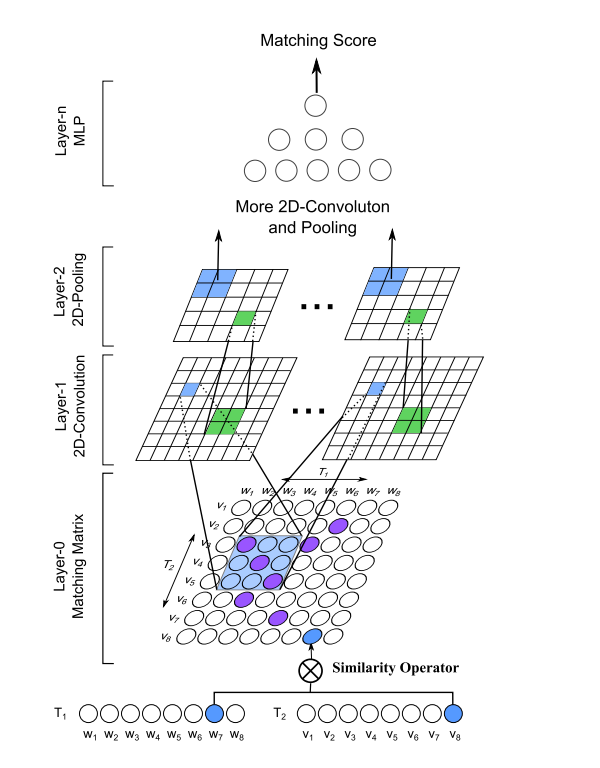
整体结构如上图所示。使用了两层卷积网络;每层卷积网络接一个最大池化层;最后利用两个全连接层将维度映射到目标类别数;特征图个数(out_channel)分别是8和16;卷积核大小分别是 5 × 5 5\times 5 5×5和 3 × 3 3 \times 3 3×3。
模型的实现可以说非常简单,比之前的RE2简单多了。所以先直接贴出完整代码,再分析。
class MatchPyramid(nn.Module):def __init__(self, args: Namespace):super().__init__()self.embedding = nn.Embedding(args.vocab_size, args.embedding_dim, padding_idx=0)self.conv1 = nn.Conv2d(in_channels=1,out_channels=args.out_channels[0],kernel_size=args.kernel_sizes[0],)self.conv2 = nn.Conv2d(in_channels=args.out_channels[0],out_channels=args.out_channels[1],kernel_size=args.kernel_sizes[1],)self.pool1 = nn.AdaptiveMaxPool2d(args.pool_sizes[0])self.pool2 = nn.AdaptiveMaxPool2d(args.pool_sizes[1])self.linear = torch.nn.Linear(args.out_channels[1] * args.pool_sizes[1][0] * args.pool_sizes[1][1],args.hidden_size,bias=True,)self.prediction = torch.nn.Linear(args.hidden_size, args.num_classes, bias=True)def forward(self, a:Tensor, b: Tensor) -> Tensor:"""Args:a (Tensor): (batch_size, a_seq_len)b (Tensor): (batch_size, b_seq_len)Returns:Tensor: (batch_size, num_classes)"""batch_size = a.size()[0]# (batch_size, a_seq_len, embedding_dim)a = self.embedding(a)# (batch_size, b_seq_len, embedding_dim)b = self.embedding(b)# (batch_size, a_seq_len, 1, embedding_dim) x (batch_size, 1, b_seq_len, embedding_dim)# -> (batch_size, a_seq_len, b_seq_len)similarity_matrix = F.cosine_similarity(a.unsqueeze(2), b.unsqueeze(1), dim=-1)# (batch_size, 1, a_seq_len, b_seq_len)similarity_matrix = similarity_matrix.unsqueeze(1)# (batch_size, out_channels[0], a_seq_len - kernel_sizes[0][0] + 1, b_seq_len - kernel_sizes[0][1] + 1)similarity_matrix = F.relu(self.conv1(similarity_matrix))# (batch_size, out_channels[0], pool_sizes[0][0], pool_sizes[0][1])similarity_matrix = self.pool1(similarity_matrix)# (batch_size, out_channels[1], pool_sizes[1][0] - kernel_sizes[1][0] + 1, pool_sizes[1][1] - kernel_sizes[1][1] + 1)similarity_matrix = F.relu(self.conv2(similarity_matrix))# (batch_size, out_channels[1], pool_sizes[1][0], pool_sizes[1][1])similarity_matrix = self.pool2(similarity_matrix)# (batch_size, out_channels[1] * pool_sizes[1][0] * pool_sizes[1][1])similarity_matrix = similarity_matrix.view(batch_size, -1)# (batch_size, num_classes)return self.prediction(F.relu(self.linear(similarity_matrix)))
在初始化中,首先创建另一个嵌入层;然后是两个卷积层和对应的池化层;最后是线性层加预测层。
采用AdaptiveMaxPool2d可以对输入的二维数据进行自适应最大池化操作,即可以指定输出的目标大小。
在forward中
- 分别计算两段输入的嵌入向量;
- 计算两个嵌入向量间的余弦相似度矩阵;
- 传入第一个卷积网络接着是池化;
- 传入第二个卷积网络接着是池化;
- 传入预测层
数据准备
数据准备包括
- 构建词表(Vocabulary)
- 构建数据集(Dataset)
本次用的是LCQMC通用领域问题匹配数据集,它已经分好了训练、验证和测试集。
我们通过pandas来加载一下。
import pandas as pdtrain_df = pd.read_csv(data_path.format("train"), sep="\t", header=None, names=["sentence1", "sentence2", "label"])train_df.head()

数据是长这样子的,有两个待匹配的句子,标签是它们是否相似。
下面用jieba来处理每个句子。
def tokenize(sentence):return list(jieba.cut(sentence))train_df.sentence1 = train_df.sentence1.apply(tokenize)
train_df.sentence2 = train_df.sentence2.apply(tokenize)
得到分好词的数据后,我们就可以得到整个训练语料库中的所有token:
train_sentences = train_df.sentence1.to_list() + train_df.sentence2.to_list()
train_sentences[0]
['喜欢', '打篮球', '的', '男生', '喜欢', '什么样', '的', '女生']
现在就可以来构建词表了,我们定义一个类:
class Vocabulary:"""Class to process text and extract vocabulary for mapping"""def __init__(self, token_to_idx: dict = None, tokens: list[str] = None) -> None:"""Args:token_to_idx (dict, optional): a pre-existing map of tokens to indices. Defaults to None.tokens (list[str], optional): a list of unique tokens with no duplicates. Defaults to None."""assert any([tokens, token_to_idx]), "At least one of these parameters should be set as not None."if token_to_idx:self._token_to_idx = token_to_idxelse:self._token_to_idx = {}if PAD_TOKEN not in tokens:tokens = [PAD_TOKEN] + tokensfor idx, token in enumerate(tokens):self._token_to_idx[token] = idxself._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}self.unk_index = self._token_to_idx[UNK_TOKEN]self.pad_index = self._token_to_idx[PAD_TOKEN]@classmethoddef build(cls,sentences: list[list[str]],min_freq: int = 2,reserved_tokens: list[str] = None,) -> "Vocabulary":"""Construct the Vocabulary from sentencesArgs:sentences (list[list[str]]): a list of tokenized sequencesmin_freq (int, optional): the minimum word frequency to be saved. Defaults to 2.reserved_tokens (list[str], optional): the reserved tokens to add into the Vocabulary. Defaults to None.Returns:Vocabulary: a Vocubulary instane"""token_freqs = defaultdict(int)for sentence in tqdm(sentences):for token in sentence:token_freqs[token] += 1unique_tokens = (reserved_tokens if reserved_tokens else []) + [UNK_TOKEN]unique_tokens += [tokenfor token, freq in token_freqs.items()if freq >= min_freq and token != UNK_TOKEN]return cls(tokens=unique_tokens)def __len__(self) -> int:return len(self._idx_to_token)def __iter__(self):for idx, token in self._idx_to_token.items():yield idx, tokendef __getitem__(self, tokens: list[str] | str) -> list[int] | int:"""Retrieve the indices associated with the tokens or the index with the single tokenArgs:tokens (list[str] | str): a list of tokens or single tokenReturns:list[int] | int: the indices or the single index"""if not isinstance(tokens, (list, tuple)):return self._token_to_idx.get(tokens, self.unk_index)return [self.__getitem__(token) for token in tokens]def lookup_token(self, indices: list[int] | int) -> list[str] | str:"""Retrive the tokens associated with the indices or the token with the single indexArgs:indices (list[int] | int): a list of index or single indexReturns:list[str] | str: the corresponding tokens (or token)"""if not isinstance(indices, (list, tuple)):return self._idx_to_token[indices]return [self._idx_to_token[index] for index in indices]def to_serializable(self) -> dict:"""Returns a dictionary that can be serialized"""return {"token_to_idx": self._token_to_idx}@classmethoddef from_serializable(cls, contents: dict) -> "Vocabulary":"""Instantiates the Vocabulary from a serialized dictionaryArgs:contents (dict): a dictionary generated by `to_serializable`Returns:Vocabulary: the Vocabulary instance"""return cls(**contents)def __repr__(self):return f"<Vocabulary(size={len(self)})>"
可以通过build方法传入所有分好词的语句,同时传入min_freq指定保存最少出现次数的单词。
新增了
__iter__方法,可以用于迭代。
这里实现了__getitem__来获取token对应的索引,如果传入的是单个token就返回单个索引,如果传入的是token列表,就返回索引列表。类似地,通过lookup_token来根据所以查找对应的token。
vocab = Vocabulary.build(train_sentences)
vocab
100%|██████████| 477532/477532 [00:00<00:00, 651784.13it/s]
<Vocabulary(size=35925)>
我们的词表有35925个token。
有了词表之后,我们就可以向量化句子了,这里也通过一个类来实现。
class TMVectorizer:"""The Vectorizer which vectorizes the Vocabulary"""def __init__(self, vocab: Vocabulary, max_len: int) -> None:"""Args:vocab (Vocabulary): maps characters to integersmax_len (int): the max length of the sequence in the dataset"""self.vocab = vocabself.max_len = max_lenself.padding_index = vocab.pad_indexdef _vectorize(self, indices: list[int], vector_length: int = -1) -> np.ndarray:"""Vectorize the provided indicesArgs:indices (list[int]): a list of integers that represent a sequencevector_length (int, optional): an arugment for forcing the length of index vector. Defaults to -1.Returns:np.ndarray: the vectorized index array"""if vector_length <= 0:vector_length = len(indices)vector = np.zeros(vector_length, dtype=np.int64)if len(indices) > vector_length:vector[:] = indices[:vector_length]else:vector[: len(indices)] = indicesvector[len(indices) :] = self.padding_indexreturn vectordef _get_indices(self, sentence: list[str]) -> list[int]:"""Return the vectorized sentenceArgs:sentence (list[str]): list of tokensReturns:indices (list[int]): list of integers representing the sentence"""return [self.vocab[token] for token in sentence]def vectorize(self, sentence: list[str], use_dataset_max_length: bool = True) -> np.ndarray:"""Return the vectorized sequenceArgs:sentence (list[str]): raw sentence from the datasetuse_dataset_max_length (bool): whether to use the global max vector lengthReturns:the vectorized sequence with padding"""vector_length = -1if use_dataset_max_length:vector_length = self.max_lenindices = self._get_indices(sentence)vector = self._vectorize(indices, vector_length=vector_length)return vector@classmethoddef from_serializable(cls, contents: dict) -> "TMVectorizer":"""Instantiates the TMVectorizer from a serialized dictionaryArgs:contents (dict): a dictionary generated by `to_serializable`Returns:TMVectorizer:"""vocab = Vocabulary.from_serializable(contents["vocab"])max_len = contents["max_len"]return cls(vocab=vocab, max_len=max_len)def to_serializable(self) -> dict:"""Returns a dictionary that can be serializedReturns:dict: a dict contains Vocabulary instance and max_len attribute"""return {"vocab": self.vocab.to_serializable(), "max_len": self.max_len}def save_vectorizer(self, filepath: str) -> None:"""Dump this TMVectorizer instance to fileArgs:filepath (str): the path to store the file"""with open(filepath, "w") as f:json.dump(self.to_serializable(), f)@classmethoddef load_vectorizer(cls, filepath: str) -> "TMVectorizer":"""Load TMVectorizer from a fileArgs:filepath (str): the path stored the fileReturns:TMVectorizer:"""with open(filepath) as f:return TMVectorizer.from_serializable(json.load(f))
命名为TMVectorizer表示是用于文本匹配(Text Matching)的专门类,调用vectorize方法一次传入一个分好词的句子就可以得到向量化的表示,支持填充Padding。
同时还支持保存功能,主要是用于保存相关的词表以及TMVectorizer所需的max_len字段。
在本小节的最后,通过继承Dataset来构建专门的数据集。
class TMDataset(Dataset):"""Dataset for text matching"""def __init__(self, text_df: pd.DataFrame, vectorizer: TMVectorizer) -> None:"""Args:text_df (pd.DataFrame): a DataFrame which contains the processed data examplesvectorizer (TMVectorizer): a TMVectorizer instance"""self.text_df = text_dfself._vectorizer = vectorizerdef __getitem__(self, index: int) -> Tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray, int]:row = self.text_df.iloc[index]vector1 = self._vectorizer.vectorize(row.sentence1)vector2 = self._vectorizer.vectorize(row.sentence2)mask1 = vector1 != self._vectorizer.padding_indexmask2 = vector2 != self._vectorizer.padding_indexreturn (vector1, vector2, mask1, mask2, row.label)def get_vectorizer(self) -> TMVectorizer:return self._vectorizerdef __len__(self) -> int:return len(self.text_df)构建函数所需的参数只有两个,分别是处理好的DataFrame和TMVectorizer实例。
实现__getitem__方法,因为这个方法会被DataLoader调用,在该方法中对语句进行向量化。
模型训练
编写训练函数:
def train(data_iter: DataLoader,model: nn.Module,criterion: nn.CrossEntropyLoss,optimizer: torch.optim.Optimizer,grad_clipping: float,
) -> None:model.train()tqdm_iter = tqdm(data_iter)running_loss = 0.0for step, (x1, x2, _, _, y) in enumerate(tqdm_iter):x1 = x1.to(device).long()x2 = x2.to(device).long()y = torch.LongTensor(y).to(device)output = model(x1, x2)loss = criterion(output, y)running_loss += loss.item()optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clipping)optimizer.step()description = f" TRAIN iter={step+1} loss={running_loss / (step + 1):.6f}"tqdm_iter.set_description(description)
和之前代码的区别在于,增加了梯度裁剪和动态设置tqdm的描述,使打印信息更精炼。
定义模型:
model = MatchPyramid(args)early_stopper = EarlyStopper(mode="max")if args.load_embeding and os.path.exists(args.embedding_saved_path):model.embedding.load_state_dict(torch.load(args.embedding_saved_path))print("loading saved embedding")
elif args.load_embeding and os.path.exists(args.embedding_pretrained_path):wv = KeyedVectors.load_word2vec_format(args.embedding_pretrained_path)embeddings = load_embedings(vocab, wv)model.embedding.load_state_dict({"weight": torch.tensor(embeddings)})torch.save(model.embedding.state_dict(), args.embedding_saved_path)print("loading pretrained embedding")
else:print("init embedding from stratch")
定义模型支持加载预训练好的word2vec向量,以及保存加载好的嵌入向量方便下次直接使用。
同时支持早停策略:
class EarlyStopper:def __init__(self, patience: int = 5, mode: str = "min") -> None:self.patience = patienceself.counter = 0self.best_value = 0.0if mode not in {"min", "max"}:raise ValueError(f"mode {mode} is unknown!")self.mode = modedef step(self, value: float) -> bool:if self.is_better(value):self.best_value = valueself.counter = 0else:self.counter += 1if self.counter >= self.patience:return Truereturn Falsedef is_better(self, a: float) -> bool:if self.mode == "min":return a < self.best_valuereturn a > self.best_value
比如如果连续5次的准确率都不再提升,直接退出训练循环,因此我们可以把训练迭代次数设高一点。
最后的训练循环如下:
optimizer = torch.optim.Adam(parameters, lr=args.learning_rate)
criterion = nn.CrossEntropyLoss()lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="max", factor=0.85, patience=0)best_value = 0.0for epoch in range(args.num_epochs):train(train_data_loader,model,criterion,optimizer,args.grad_clipping)with torch.no_grad():acc, p, r, f1 = evaluate(dev_data_loader, model)lr_scheduler.step(acc)if acc > best_value:best_value = accprint(f"Save model with best acc :{acc}")torch.save(model.state_dict(), model_save_path)if early_stopper.step(acc):print(f"Stop from early stopping.")breakprint(f"EVALUATE [{epoch+1}/{args.num_epochs}] accuracy={acc:.3f} precision={p:.3f} recal={r:.3f} f1 score={f1:.4f}")这里使用了ReduceLROnPlateau学习率调度器,当验证集的准确率不再提升时,就调整(减小)学习率。
python .\text_matching\match_pyramid\train.py
Arguments : Namespace(dataset_csv='text_matching/data/lcqmc/{}.txt', vectorizer_file='vectorizer.json', model_state_file='model.pth', pandas_file='dataframe.{}.pkl', save_dir='D:\\workspace\\nlp-in-action\\text_matching\\match_pyramid\\model_storage', reload_model=False, cuda=True, learning_rate=0.0005, batch_size=128, num_epochs=50, max_len=50, embedding_dim=300, embedding_saved_path='text_matching/data/embeddings.pt', embedding_pretrained_path='./word2vec.zh.300.char.model', load_embeding=False, fix_embeddings=False, hidden_size=150, out_channels=[8, 16], kernel_sizes=[(5, 5), (3, 3)], pool_sizes=[(10, 10), (5, 5)], dropout=0.2, min_freq=2, project_func='linear', grad_clipping=2.0, num_classes=2)
Using device: cuda:0.
Loads cached dataframes.
Loads vectorizer file.
init embedding from stratch
Model: MatchPyramid((embedding): Embedding(4827, 300, padding_idx=0)(conv1): Conv2d(1, 8, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1))(pool1): AdaptiveMaxPool2d(output_size=(10, 10))(pool2): AdaptiveMaxPool2d(output_size=(5, 5))(linear): Linear(in_features=400, out_features=150, bias=True)(prediction): Linear(in_features=150, out_features=2, bias=True)
)
New modelTRAIN iter=1866 loss=0.507334: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:56<00:00, 2.60it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.57it/s]
Save model with best acc :0.642808
EVALUATE [1/50] accuracy=0.643 precision=0.607 recal=0.811 f1 score=0.6944TRAIN iter=1866 loss=0.432987: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:56<00:00, 2.61it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.62it/s]
Save model with best acc :0.651897
EVALUATE [2/50] accuracy=0.652 precision=0.628 recal=0.748 f1 score=0.6824TRAIN iter=1866 loss=0.398575: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.75it/s]
Save model with best acc :0.685526
EVALUATE [3/50] accuracy=0.686 precision=0.667 recal=0.740 f1 score=0.7019TRAIN iter=1866 loss=0.369512: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:43<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.71it/s]
Save model with best acc :0.697342
EVALUATE [4/50] accuracy=0.697 precision=0.683 recal=0.736 f1 score=0.7086TRAIN iter=1866 loss=0.346564: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [12:42<00:00, 2.45it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.76it/s]
EVALUATE [5/50] accuracy=0.694 precision=0.662 recal=0.793 f1 score=0.7215TRAIN iter=1866 loss=0.325961: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:43<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.78it/s]
Save model with best acc :0.719382
EVALUATE [6/50] accuracy=0.719 precision=0.699 recal=0.772 f1 score=0.7334TRAIN iter=1866 loss=0.309486: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:43<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.67it/s]
Save model with best acc :0.721654
EVALUATE [7/50] accuracy=0.722 precision=0.717 recal=0.731 f1 score=0.7244TRAIN iter=1866 loss=0.294962: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [12:17<00:00, 2.53it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.70it/s]
EVALUATE [8/50] accuracy=0.719 precision=0.701 recal=0.762 f1 score=0.7305TRAIN iter=1866 loss=0.280962: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.65it/s]
Save model with best acc :0.723018
EVALUATE [9/50] accuracy=0.723 precision=0.702 recal=0.774 f1 score=0.7365TRAIN iter=1866 loss=0.269775: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [13:26<00:00, 2.31it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.84it/s]
Save model with best acc :0.724949
EVALUATE [10/50] accuracy=0.725 precision=0.705 recal=0.775 f1 score=0.7381TRAIN iter=1866 loss=0.259390: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:43<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.72it/s]
Save model with best acc :0.733810
EVALUATE [11/50] accuracy=0.734 precision=0.718 recal=0.770 f1 score=0.7431TRAIN iter=1866 loss=0.248994: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.70it/s]
EVALUATE [12/50] accuracy=0.732 precision=0.702 recal=0.807 f1 score=0.7504TRAIN iter=1866 loss=0.238763: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:56<00:00, 2.60it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.75it/s]
Save model with best acc :0.740854
EVALUATE [13/50] accuracy=0.741 precision=0.726 recal=0.773 f1 score=0.7489TRAIN iter=1866 loss=0.230795: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.74it/s]
Save model with best acc :0.741877
EVALUATE [14/50] accuracy=0.742 precision=0.729 recal=0.769 f1 score=0.7488TRAIN iter=1866 loss=0.222789: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.67it/s]
EVALUATE [15/50] accuracy=0.741 precision=0.719 recal=0.791 f1 score=0.7531TRAIN iter=1866 loss=0.214246: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [12:18<00:00, 2.53it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.77it/s]
EVALUATE [16/50] accuracy=0.740 precision=0.722 recal=0.782 f1 score=0.7507TRAIN iter=1866 loss=0.207212: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:43<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.75it/s]
EVALUATE [17/50] accuracy=0.737 precision=0.712 recal=0.794 f1 score=0.7512TRAIN iter=1866 loss=0.201221: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [12:07<00:00, 2.57it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.67it/s]
Save model with best acc :0.750170
EVALUATE [18/50] accuracy=0.750 precision=0.737 recal=0.779 f1 score=0.7571TRAIN iter=1866 loss=0.196648: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:43<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.77it/s]
EVALUATE [19/50] accuracy=0.741 precision=0.708 recal=0.819 f1 score=0.7594TRAIN iter=1866 loss=0.191739: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.80it/s]
EVALUATE [20/50] accuracy=0.742 precision=0.723 recal=0.785 f1 score=0.7528TRAIN iter=1866 loss=0.187552: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [12:07<00:00, 2.56it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.79it/s]
EVALUATE [21/50] accuracy=0.740 precision=0.724 recal=0.777 f1 score=0.7495TRAIN iter=1866 loss=0.183918: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [11:44<00:00, 2.65it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.75it/s]
EVALUATE [22/50] accuracy=0.738 precision=0.717 recal=0.785 f1 score=0.7496TRAIN iter=1866 loss=0.180852: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1866/1866 [13:26<00:00, 2.31it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 69/69 [00:05<00:00, 11.71it/s]
Stop from early stopping.
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 98/98 [00:08<00:00, 11.87it/s]
TEST accuracy=0.757 precision=0.702 recal=0.894 f1 score=0.7865
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 98/98 [00:08<00:00, 11.90it/s]
TEST[best score] accuracy=0.765 precision=0.717 recal=0.876 f1 score=0.7883
触发了早停。
最终达到了76.5%的测试集准确率。
完整代码
https://github.com/nlp-greyfoss/nlp-in-action-public/tree/master/text_matching