先说说jni层的思路, 首先拿到udp过来的裸数据, 然后简单的还原传输时的分包, 然后按照之前mediaCodec的逻辑, 一帧帧丢进解码器, 进行解码, 解码完成之后, 对surface view进行渲染.
这个流程有个前期的准备已经做好了就是我报的安卓的课程有jni音视频解码的部分, 里面花了7个小时, 讲解了如何解码, 如果同步音视频, 如何防止内存泄露, 如果没有这个课程, 我得折腾到猴年才能折腾明白, 特别是关于内存泄漏的检查部分…
Derry老师虽然课讲的不咋地, 但是让我基本入门了.
接着看看jni部分都做了啥.
首先是入口native-lib
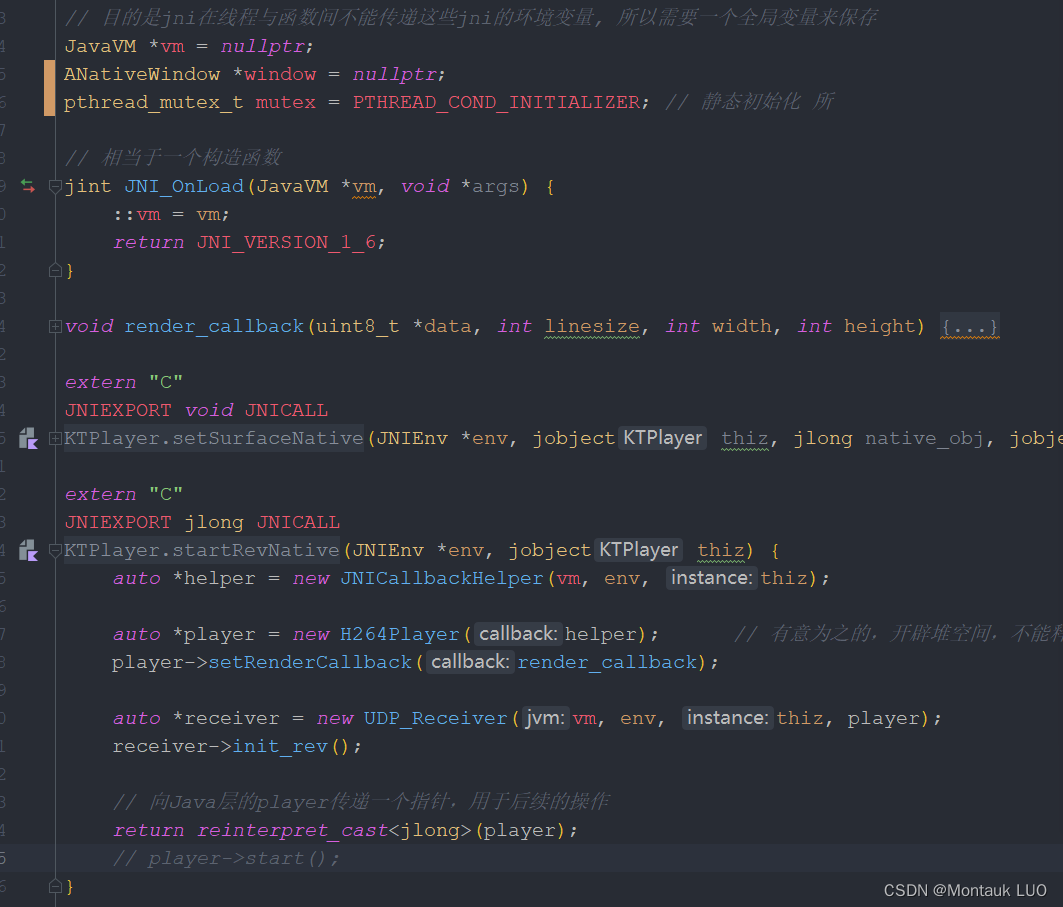
startRevNative中, 新建了一个Jni层的Player, 一个用于往上层发通知的回调, 暂时没用.
见了一个UDP的接收者, 用于接收收到的UDP的数据包.
render_callback中, 用已经解码的数据对所持有的ANativeWindow进行渲染.
UDP_Receiver中
为避免阻塞, 将这个接收数据的部分用单独的线程处理
void *rev_thread(void *args) {char packetBuf[UDP_PACKET_LEN]; // udp包最大是1400int recvLen;int dataFrameLen = 0;// 强转为receiver对象指针, 为了取到sockfdauto *receiver = static_cast<UDP_Receiver *>(args);char dataFrameBuf[DATA_BUFFER_LEN];while (true) {// 读取udp数据包recvLen = read(receiver->sockfd, (char *) packetBuf, UDP_PACKET_LEN);if (recvLen < 0) {LOGD("recvfrom failed");break;}if (recvLen > 0) {// LOGD("Got data: %d bytes", recvLen);// 获取数据包的类型// 这里的注释暂时不要删除, 知道显示确定无问题frame_type_e frameType = receiver->get_frame_type(packetBuf, recvLen);// 经过分析, 只有I帧/P帧即数据帧才发送到解码器if (SPS_FRAME == frameType) {if (!receiver->ifStartRender) {LOGD("Start render");receiver->ifStartRender = true;}LOGD("SFrame insert buffered data into packet queue");// 将已经缓存的数据帧插入到队列中receiver->insert_data_into_players_packet_queue(dataFrameBuf, dataFrameLen);dataFrameLen = 0;// 加入缓存, 跟I帧一起发送memcpy(&dataFrameBuf[dataFrameLen], packetBuf, recvLen);dataFrameLen = recvLen;} else if (PPS_FRAME == frameType) {// 加入缓存, 跟I帧一起发送memcpy(&dataFrameBuf[dataFrameLen], packetBuf, recvLen);dataFrameLen = dataFrameLen + recvLen;} else if (I_FRAME == frameType) {// 加入缓存memcpy(&dataFrameBuf[dataFrameLen], packetBuf, recvLen);dataFrameLen = dataFrameLen + recvLen;} else if (D_START_PACKET == frameType) {// D帧开始了, 就把之前的先发送receiver->insert_data_into_players_packet_queue(dataFrameBuf, dataFrameLen);dataFrameLen = 0;// 加入缓存memcpy(&dataFrameBuf[dataFrameLen], packetBuf, recvLen);dataFrameLen = recvLen;} else if (D_REST_PACKET == frameType) {// 数据帧的中间部分, 直接缓存memcpy(&dataFrameBuf[dataFrameLen], packetBuf, recvLen);dataFrameLen = dataFrameLen + recvLen;}}usleep(1);}return nullptr;
}
这里先对接收的数据帧进行一个判断, 因为发送端已经将帧做成了包, 所以数据包到安卓端, 就是几种情况:
- SPS帧, 这个是第一个发送的.
- PPS帧, 这个是第二个
- 如果在发送端不做丢弃处理, 这里还会发送一个SEI帧, 但是解码器遇到这个帧会报错, 甚至在雷神的那个解码工具看到的也是unknow
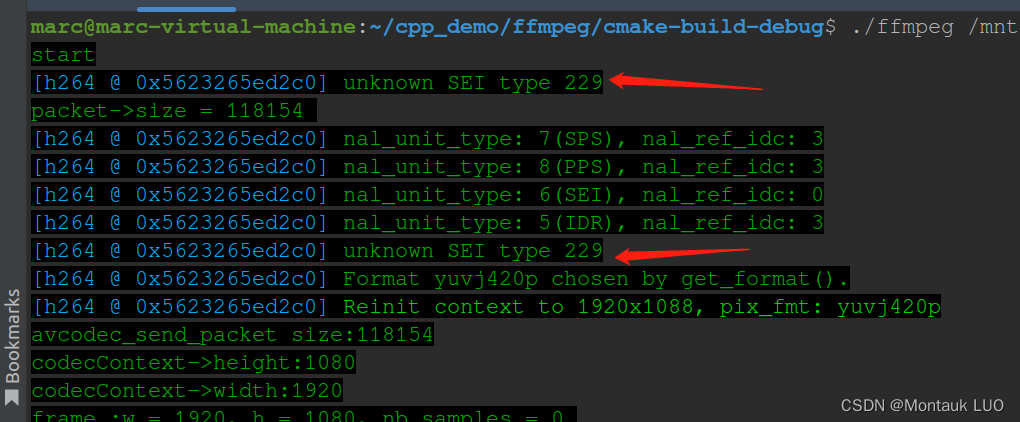
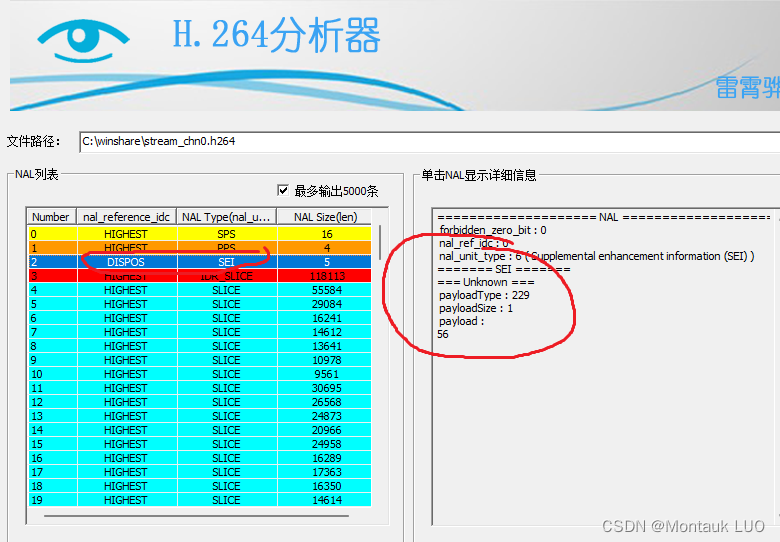
所以我后来选择直接在发送端把这个9字节的SEI给丢了.
- 接着就遇到个天坑, 我之前用MediaCodec的逻辑就是, 有啥就传啥, 拿到啥就往mediaCodec的inputBuffer里面扔, 然后在outputBuffer那里等着, 拿到数据就 渲染, 没问题, (但是我也发现了, 如果遇到错误帧, 解码的速度会变慢. 画面卡顿)
但是在这里, 如果我把些SPS, PPS跟I帧一个个扔到ffmpeg的解码器中时, 它居然给我报错, 而且是每秒给我报3个错, 在我去掉SEI帧之后, 报2个错, 我自然而然想到可能是这SPS跟PPS的问题.
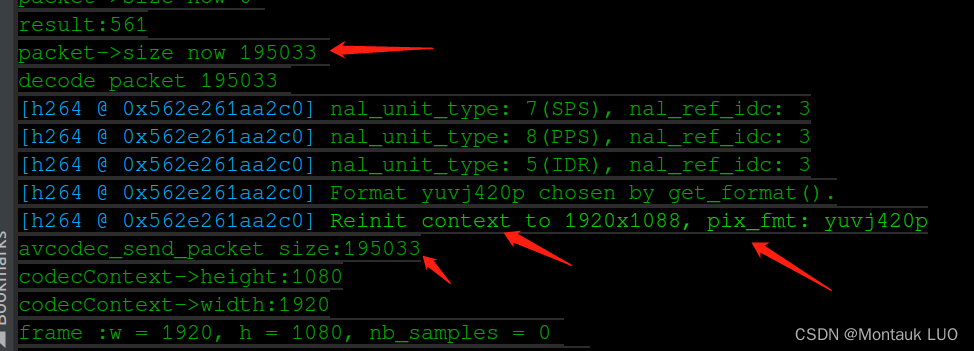
折腾了一天之后, 对比ffmpeg对h264裸流文件解码的例程, 我发现, 注意看上面的图, 传给这个avcodec_send_packet的数据尺寸是195033字节, 而我通过分析工具看到的这个I帧, 才195001+4个分隔标识符, 也就是说, 他们居然是把SPS, PPS, 跟I帧打包成一个Packet, 丢给解码器的.
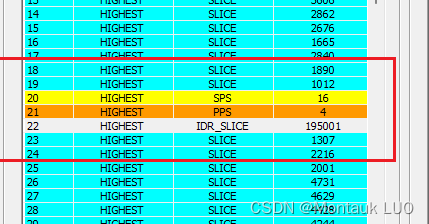
好吧, 我也只能如法炮制了, 这样一来, 使用avcodec_send_packet发送数据到解码器的时候, 返回就不报错了.
- 接着我又遇到个坑, 注意看这个函数
void UDP_Receiver::insert_data_into_players_packet_queue(char *data, int dataLen) {if (this->ifStartRender) {AVPacket *packet = av_packet_alloc();// packet->data = (uint8_t *) av_malloc(dataLen);packet->data = (uint8_t *) data;// memcpy(packet->data, data, dataLen);packet->size = dataLen;packet->stream_index = 0;this->player->videoChannel->packet_decode(packet);av_packet_unref(packet);av_packet_free(&packet);packet = nullptr;}
}之前我是用注释中的写法, 先为AVPacket申请内存, 然后用av_molloc给data指针申请内存, 然后使用memcpy, 将收到的内存复制到packet的data中, 看起来完美吧, 结果就发现, 即便接下来啥也不错, 也不解码, native的内存就会600K/秒的速度在增长…2分钟涨到了70M
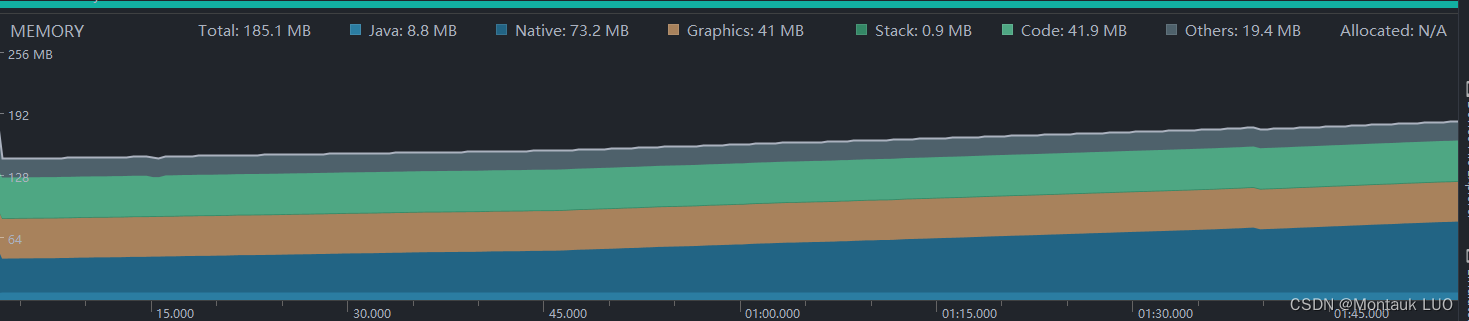
如果在华为手机上跑, 估计要不了3分钟, 就被系统自动杀死了…
先是在后面解码, 刷新的部分寻找泄漏点, 发现即便一点点注释掉后面的内容, 依然在泄露, 后来不知道哪根筋转了过来, 发现就是这个memcpy的过程, 泄露了内存而没有回收, 那我试试直接把接收到的数据传给解码器吧, 终于…
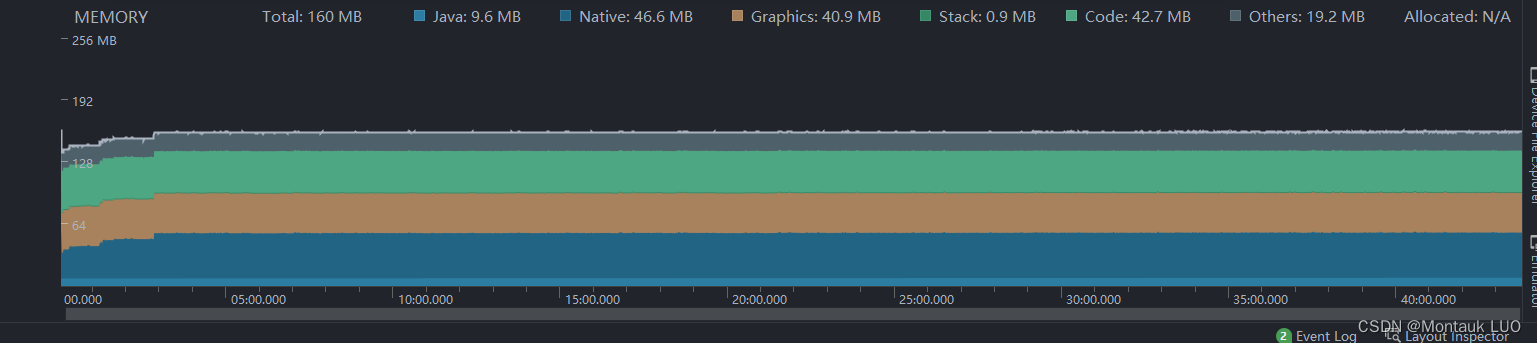
40分钟内, 内存平静如水, native消耗才46.6M
-
数据包的解码原本是放在一个单独线程里面进行的, 但是我感觉这部分既然是同步的操作, 直接就在数据接收端进行了, 因为毕竟接收数据间隔是30ms 而解码只需要:

大约14ms, 这特么才是硬解码吧? -
play是一个单独线程, 所以现在一共只有两个子线程, 一个接收数据, 一个play, play的工作就是把解码后的jyuv420数据, 解码成rgba, 然后传给渲染函数, 渲染函数这里使用了一个函数指针, 函数指针我还不熟, 就不多解释了, 总之最终是在native-lib文件中的render_callback完成了渲染, 因为只有这儿有这个ANativeWindow *window 的实例.
这个render_callback也算是个小坑吧, 因为对函数指针确实不熟. -
至此, 安卓跑起来, 海思先通过wifi的网卡连到安卓的热点, 然后直接向热点的网关发送数据, 就可以看到画面了.
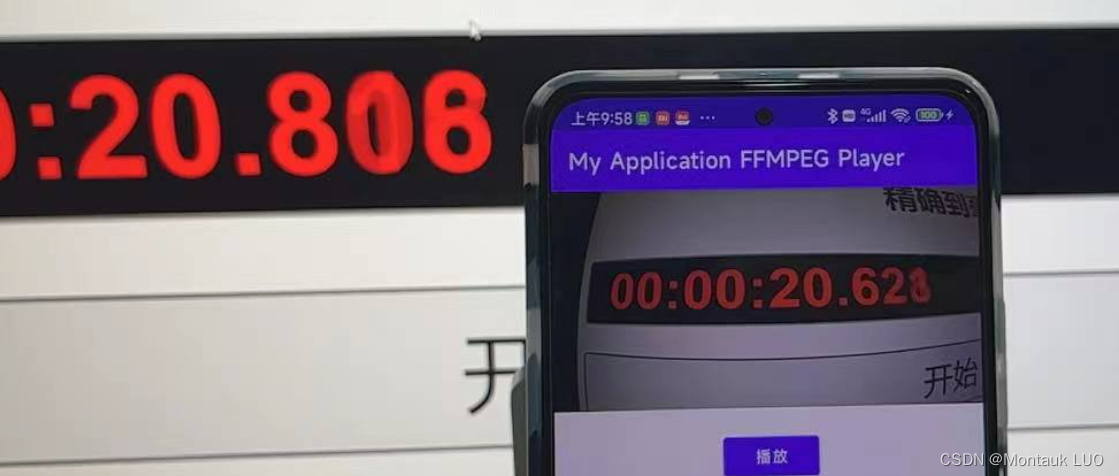
高速摄影机拍摄到的画面…其实是我屏幕的刷新率不够…从摄像头捕捉到画面到安卓渲染完成, 大概是150ms左右.
遗留的问题:
1 还能更快么??
2. 目前速度的瓶颈在哪? 编码端? WiFi?
3 测试一下公网中转?