《Using Domain Knowledge to Guide Dialog Structure Induction via Neural Probabilistic 》
名词解释
Dialog Structure Induction(DSI)是推断给定目标导向对话的潜在对话结构(即一组对话状态及其时间转换)的任务。它是现代对话系统设计和话语分析的关键组件。
Probabilistic Soft Logic (概率软逻辑,PSL)是一种在统计关系学习和推理中使用的框架。它结合了逻辑编程的可解释性与概率模型的不确定性处理能力,适用于处理不确定和复杂的关系数据。PSL使用软逻辑(一种近似布尔逻辑的形式)来表达知识,其中逻辑命题的真值不再是简单的真(true)或假(false),而是在[0,1]范围内的实数,表示真实程度的不同。在PSL中,逻辑规则被转化为概率模型的一部分。这使得PSL能够以概率方式处理不确定性,例如,在数据缺失或噪声情况下进行推理。
文章的主要工作
(1) 提出了 NEUPSL DSI,这是一种新颖的平滑PSL(概率软逻辑)约束松弛方法,旨在确保在反向传播过程中提供丰富的梯度信号;
(2) 在合成和现实对话数据集上评估了 NEUPSL DSI,在标准泛化、领域泛化和领域适应三种设置下进行了测试。我们定量地展示了注入领域知识相比于无监督和少量样本方法的优势;
(3) 全面调查了软逻辑增强学习对学习神经模型不同方面的影响,通过检查其在表示学习和结构归纳方面的质量。
前置知识
VRNN
DD-VRNN
Probabilistic Soft Logic(PSL)
这项工作以一种类似于概率软逻辑(Probabilistic Soft Logic,PSL)的声明方式引入了软约束。PSL 是一种声明式统计关系学习(Statistical Relational Learning,SRL)框架,用于定义一种特定的概率图模型,即铰链损失马尔可夫随机场(Hinge-Loss Markov Random Field,HL-MRF)(Bach 等人,2017年)。PSL 使用一阶逻辑规则来模拟关系依赖性和结构约束,这些规则被称为模板,其参数称为原子。例如,“对话中的第一句话很可能属于问候状态”的陈述可以表示为:
FirstUtt ( U ) → STATE ( U , greet ) (5) \text{FirstUtt}(U) \rightarrow \text{STATE}(U,\text{greet})\tag{5} FirstUtt(U)→STATE(U,greet)(5)
在公式(5)中, FirstUtt ( U ) → STATE ( U , greet ) \text{FirstUtt}(U) \rightarrow \text{STATE}(U,\text{greet}) FirstUtt(U)→STATE(U,greet) 的 FirstUtt ( U ) \text{FirstUtt}(U) FirstUtt(U) 和 STATE ( U , greet ) \text{STATE}(U,\text{greet}) STATE(U,greet) 是原子(即原子布尔语句),分别指出一个话语 U U U 是否为对话的第一句话,或者它是否属于问候状态。在PSL规则中的原子通过替换自由变量(例如上文的 U U U)为感兴趣领域的具体实例(例如,具体话语 ‘Hello!’)来实现具体化,我们称这些为具体化原子。概率模型的观测变量和目标/决策变量对应于从领域中构建的具体化原子,例如, FirstUtt ( ′ H e l l o ! ′ ) \text{FirstUtt}('Hello!') FirstUtt(′Hello!′) 可能是一个观测变量,而 STATE ( ′ H e l l o ! ′ , greet ) \text{STATE}('Hello!', \text{greet}) STATE(′Hello!′,greet) 可能是一个目标变量。
观测变量是指在概率模型或统计分析中可以直接测量或记录的变量。它们是数据收集过程中实际观察到的值。在统计和机器学习的上下文中,观测变量通常用于推断或预测那些我们无法直接测量的潜在变量或未知参数。
目标变量,又称为因变量或预测变量,在数据分析、统计建模和机器学习中是指那些模型试图预测或解释的变量。
概率软逻辑(PSL)通过允许原本具有布尔值的原子采用区间 [0, 1] 内的连续真值来执行推理,从而软化了逻辑约束。利用这种放松,PSL用一种称为卢卡西维奇逻辑(Lukasiewicz logic)的软逻辑形式替换了逻辑运算(Klir 和 Yuan, 1995):
A ∧ B = max ( 0.0 , A + B − 1.0 ) A \land B = \max(0.0, A+B - 1.0) A∧B=max(0.0,A+B−1.0)
A ∨ B = min ( 1.0 , A + B ) (6) A \lor B = \min(1.0, A+B) \tag{6} A∨B=min(1.0,A+B)(6)
¬ A = 1.0 − A \lnot A = 1.0 - A ¬A=1.0−A
其中 A A A 和 B B B 代表基础原子或原子上的逻辑表达式,并且取值在 [0, 1] 范围内。例如,PSL将公式 5 中的语句转换为以下形式:
min { 1 , 1 − FirstUtt ( U ) + STATE ( U , greet ) } (7) \min\{1, 1 - \text{FirstUtt}(U) + \text{STATE}(U, \text{greet})\}\tag{7} min{1,1−FirstUtt(U)+STATE(U,greet)}(7)
鉴于 A → B A \rightarrow B A→B 等价于 ¬ A ∨ B \lnot A \lor B ¬A∨B,我们可以创建一系列函数 { ℓ i } i = 1 m \{ \ell_i \}^m_{i=1} {ℓi}i=1m,称为模板,它们将数据映射到 [0, 1] 区间。使用这些模板,PSL定义了一个条件概率密度函数,用于在给定观测数据 x x x 的情况下,对未观测随机变量 y y y 进行推理,这称为铰链损失马尔可夫随机场(HL-MRF):
P ( y ∣ x ) ∝ exp ( − ∑ i = 1 m λ i ⋅ ϕ i ( y , x ) ) (8) P(y|x) \propto \exp\left(-\sum_{i=1}^{m} \lambda_i \cdot \phi_i(y, x)\right) \tag{8} P(y∣x)∝exp(−i=1∑mλi⋅ϕi(y,x))(8)
这里 λ i \lambda_i λi 是一个非负权重,而 ϕ i \phi_i ϕi 是基于模板的潜在函数:
ϕ i ( y , x ) = max { 0 , ℓ i ( y , x ) } (9) \phi_i(y, x) = \max\{0, \ell_i(y, x)\} \tag{9} ϕi(y,x)=max{0,ℓi(y,x)}(9)
然后,模型预测 y y y 的推理通过最大后验(MAP)估计继续进行,即通过最大化目标函数 P ( y ∣ x ) P(y|x) P(y∣x)(公式 8)相对于 y y y 的值。
Neural Probabilistic Soft Logic Dialogue Structure Induction(NEUPSL DSI)方法
问题表述
在给定面向目标的对话语料库 D D D 的情况下,我们考虑了学习潜在于该语料库的图 G G G 的对话结构识别(DSI)问题。更正式地说,对话结构被定义为有向图 G = ( S , P ) G = (S, P) G=(S,P),其中 S = { s 1 , … , s m } S = \{s_1, \ldots, s_m\} S={s1,…,sm} 编码了一组对话状态,而 P P P 是概率分布 p ( s t ∣ s < t ) p(s_t|s_{<t}) p(st∣s<t),表示状态之间转移的可能性(见下图作为例子)。给定潜在的对话结构 G G G,对话 d i = { x 1 , … , x T } ∈ D d_i = \{x_1, \ldots, x_T\} \in D di={x1,…,xT}∈D 是按时间顺序排列的话语集合 x t x_t xt。假设 x t x_t xt 根据过去历史条件下的话语分布 p ( x t ∣ s ≤ t , x < t ) p(x_t|s_{\leq t}, x_{<t}) p(xt∣s≤t,x<t) 定义,状态 s t s_t st 根据 p ( s t ∣ s < t ) p(s_t|s_{<t}) p(st∣s<t) 定义。给定对话语料库 D = { d i } i = 1 n D = \{d_i\}_{i=1}^n D={di}i=1n,DSI 的任务是学习一个尽可能接近潜在图的有向图形模型 G = ( S , P ) G = (S, P) G=(S,P)。
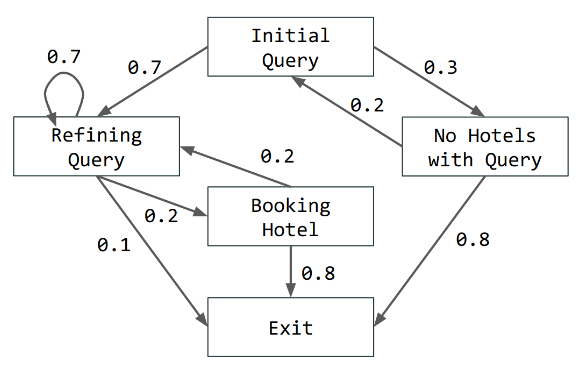
NEUPSL DSI 下整合神经和符号学习
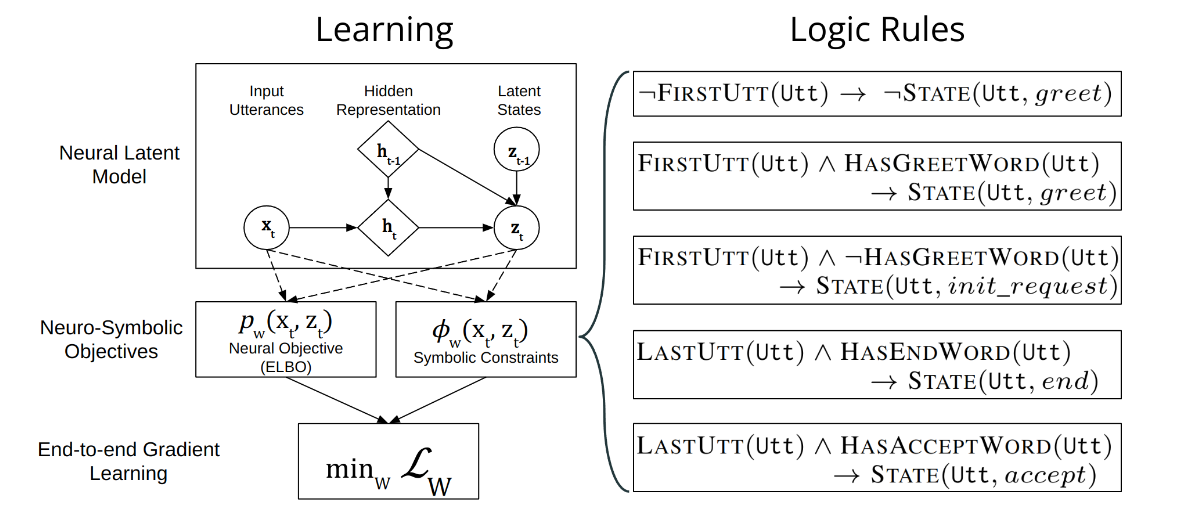
上图提供了 DD-VRNN 和符号约束集成的图形表示。直观上,NEUPSL DSI 可以描述为三个部分:实例化、推理和学习。
实例化 NEUPSL DSI 模型使用一组一阶逻辑模板来创建一组潜力,这些潜力定义了用于学习和评估的损失函数。设 p w p_w pw 为 DD-VRNN 的潜在状态预测函数,其中包含隐藏参数 w w w 和输入话语 x vrnn x_{\text{vrnn}} xvrnn。这个函数的输出,定义为 p w ( x vrnn ) p_w(x_{\text{vrnn}}) pw(xvrnn),将是代表给定话语每个潜在类别可能性的概率分布。给定一个一阶符号规则 ℓ i ( y , x ) \ell_i(y, x) ℓi(y,x),其中 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 是代表来自神经模型的潜在状态预测的决策变量,而 x x x 代表未在神经特征 x vrnn x_{\text{vrnn}} xvrnn 中纳入的符号观察,NEUPSL DSI 实例化一组形式为以下的deep hinge-loss potentials(深度铰链损失潜能):
ϕ w , i ( x vrnn , x ) = max ( 0 , ℓ i ( p w ( x vrnn ) , x ) ) (10) \phi_{w,i}(x_{\text{vrnn}}, x) = \max(0, \ell_i(p_w(x_{\text{vrnn}}), x))\tag{10} ϕw,i(xvrnn,x)=max(0,ℓi(pw(xvrnn),x))(10)
例如,在参考公式7时,决策变量 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 与 STATE(x, greet) 随机变量关联,导致以下情况:
ℓ i ( p w ( x vrnn ) , x ) = min { 1 , 1 − FIRSTUTT ( U ) + p w ( x vrnn ) } (11) \ell_i(p_w(x_{\text{vrnn}}), x) = \min\{1, 1 - \text{FIRSTUTT}(U) + p_w(x_{\text{vrnn}})\} \tag{11} ℓi(pw(xvrnn),x)=min{1,1−FIRSTUTT(U)+pw(xvrnn)}(11)
在上述实例化模型的描述中,NEUPSL DSI 推理目标被拆分为神经推理目标和符号推理目标。神经推理目标通过评估 DD-VRNN 模型预测相对于 DSI 的标准损失函数来计算。鉴于深度铰链损失潜能 { ϕ w , i } i = 1 m \{\phi_{w,i}\}_{i=1}^m {ϕw,i}i=1m,符号推理目标是在决策变量 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 处评估的 HL-MRF 似然(公式8):
P w ( y ∣ x vrnn , x , λ ) = exp ( − ∑ i = 1 m λ i ⋅ ϕ w , i ( x vrnn , x ) ) (12) P_w(y|x_{\text{vrnn}}, x, \lambda) = \exp\left(-\sum_{i=1}^m \lambda_i \cdot \phi_{w,i}(x_{\text{vrnn}}, x)\right) \tag{12} Pw(y∣xvrnn,x,λ)=exp(−i=1∑mλi⋅ϕw,i(xvrnn,x))(12)
在 NEUPSL DSI 下,决策变量 y = p w ( x vrnn ) y = p_w(x_{\text{vrnn}}) y=pw(xvrnn) 是由神经网络权重 w w w 隐含控制的,因此,对决策变量 y ∗ y^* y∗ 进行符号学习的传统 MAP 推理,可以简单地通过神经权重最小化 arg min w P w ( y ∣ x vrnn , x , λ ) \arg\min_w P_w(y|x_{\text{vrnn}}, x, \lambda) argminwPw(y∣xvrnn,x,λ) 来完成。结果,NEUPSL DSI 学习最小化一个受限优化目标:
w ∗ = arg min w [ L DD-VRNN + L constraint ] (13) w^* = \arg\min_w \left[ \mathcal{L}_{\text{DD-VRNN}} + \mathcal{L}_{\text{constraint}} \right] \tag{13} w∗=argwmin[LDD-VRNN+Lconstraint](13)
我们将约束损失定义为 HL-MRF 分布的对数似然:
L Constraint = − log P w ( y ∣ x vrnn , x , λ ) (14) \mathcal{L}_{\text{Constraint}} = -\log P_w (y|x_{\text{vrnn}}, x, \lambda) \tag{14} LConstraint=−logPw(y∣xvrnn,x,λ)(14)
为了改进梯度学习的软逻辑约束,直接使用的线性软约束以及经典的Lukasiewicz松弛无法传递具有幅度的梯度,而是仅传递方向(例如,±1)。正式来说,关于 w w w 的潜能 ϕ w ( x vrnn , x ) = max ( 0 , ℓ ( p w ( x vrnn ) , x ) ) \phi_w(x_{\text{vrnn}}, x) = \max(0, \ell(p_w(x_{\text{vrnn}}), x)) ϕw(xvrnn,x)=max(0,ℓ(pw(xvrnn),x)) 的梯度为:
∂ ϕ w ∂ w = ∂ ℓ ( p w , x ) ∂ w ⋅ 1 ϕ w > 0 \frac{\partial \phi_w}{\partial w} = \frac{\partial \ell(p_w, x)}{\partial w} \cdot 1_{\phi_w>0} ∂w∂ϕw=∂w∂ℓ(pw,x)⋅1ϕw>0
= [ ∂ ∂ p w ℓ ( p w , x ) ] ⋅ ∂ p w ∂ w ⋅ 1 ϕ w > 0 (15) = \left[ \frac{\partial}{\partial p_w} \ell(p_w, x) \right] \cdot \frac{\partial p_w}{\partial w} \cdot 1_{\phi_w>0} \tag{15} =[∂pw∂ℓ(pw,x)]⋅∂w∂pw⋅1ϕw>0(15)
这里 ℓ ( p w , x ) = a ⋅ p w ( x vrnn ) + b \ell(p_w, x) = a \cdot p_w(x_{\text{vrnn}}) + b ℓ(pw,x)=a⋅pw(xvrnn)+b 其中 a , b ∈ R a, b \in \mathbb{R} a,b∈R 和 p w ( x vrnn ) ∈ [ 0 , 1 ] p_w(x_{\text{vrnn}}) \in [0, 1] pw(xvrnn)∈[0,1],这导致梯度 ∂ ∂ p w ℓ ( p w , x ) = a \frac{\partial}{\partial p_w} \ell(p_w, x) = a ∂pw∂ℓ(pw,x)=a。观察在PSL描述的三个Lukasiewicz操作,很明显 a a a 的结果总是 ±1,除非每个约束有多个 p w ( x vrnn ) p_w(x_{\text{vrnn}}) pw(xvrnn)。
因此,这种经典的软逻辑松弛导致了一个幼稚(naive)、不平滑的梯度:
∂ ϕ w ∂ w = [ a 1 ϕ w > 0 ] ⋅ ∂ p w ∂ w (16) \frac{\partial \phi_w}{\partial w} = [a 1_{\phi_w>0}] \cdot \frac{\partial p_w}{\partial w} \tag{16} ∂w∂ϕw=[a1ϕw>0]⋅∂w∂pw(16)
这主要由预测概率的梯度 ∂ ∂ w p w \frac{\partial}{\partial w} p_w ∂w∂pw 组成。它几乎不向模型提供 p w p_w pw 满足符号约束 ϕ w \phi_w ϕw 的程度的信息(除了非平滑的阶跃函数 1 ϕ w > 0 1_{\phi_w>0} 1ϕw>0),从而在基于梯度的学习中产生挑战。
在这项工作中,我们提出了一种新颖的基于对数的松弛方法,它提供了更平滑且更具信息性的梯度信息用于符号约束:
ψ w ( x ) = log ( ϕ w ( x vrnn , x ) ) \psi_w(x) = \log (\phi_w(x_{\text{vrnn}}, x)) ψw(x)=log(ϕw(xvrnn,x))
= log ( max ( 0 , ℓ ( p w ( x vrnn ) , x ) ) ) (17) = \log (\max(0, \ell(p_w(x_{\text{vrnn}}), x))) \tag{17} =log(max(0,ℓ(pw(xvrnn),x)))(17)
这个看似简单的转换给梯度行为带来了非平凡的变化:
$$ \frac{\partial \psi_w}{\partial w} = \frac{1}{\phi_w} \cdot \frac{\partial \phi_w}{\partial w}
= \left[ \frac{a}{\phi_w} 1_{\phi_w>0} \right] \cdot \frac{\partial p_w}{\partial w} \tag{18}$$
如上所示,来自符号约束的梯度现在包含了一个新项 1 ϕ w \frac{1}{\phi_w} ϕw1。它向模型提供了模型预测满足符号约束 ℓ \ell ℓ 的程度信息,使得它不再是相对于 ϕ w \phi_w ϕw 的离散阶跃函数。结果,当一个规则的满足度 ϕ w \phi_w ϕw 是非负但低(即,不确定)时,梯度的大小将会很高,而当规则的满足度很高时,梯度的大小将会低。通过这种方式,符号约束项 ϕ i \phi_i ϕi 的梯度现在引导神经模型更有效地专注于学习那些不遵守现有符号规则的挑战性例子这导致神经和符号组件在模型学习期间更有效的协作,并且从经验上导致了泛化性能的提高。
通过加权词袋模型更强地控制后验坍塌
后验坍塌(Posterior Collapse)是一种在训练变分自编码器(VAEs)时常见的问题,尤其是在自然语言处理(NLP)任务中。这个问题发生在模型的编码器部分学会忽略输入数据,导致模型的隐含变量(latent variables)不再能够捕获数据的有用信息。换句话说,后验分布(即给定观察数据后的潜在变量的条件分布)倾向于与先验分布(潜在变量的分布)相同,因此潜在变量没有为数据的生成过程提供任何有意义的信息。这种情况下,模型的解码器部分将只能基于先验知识来重构数据,而无法利用潜在表示的好处。
在VAEs中,后验坍塌通常表现为隐变量的概率分布趋向于标准正态分布,使得隐变量无法有效地编码任何关于输入数据的信息。因此,解码器学习忽视这些变量,依靠数据中的其他特征来重构输入,这降低了模型的表现力。
避免VRNN解决方案坍塌至关重要,这种坍塌指的是模型将其所有预测仅放在少数几个状态中。这个问题被称为潜在变量消失问题(Zhao等人,2017)。Zhao等人(2017)通过为VRNN引入一个词袋(BOW)损失来解决这个问题,这要求网络预测响应 x x x 中的词袋。他们将 x x x 分成两个变量: x o x_o xo(词序)和 x bow x_{\text{bow}} xbow(无词序),并假设在给定 z z z 和 c c c 的条件下,这两个变量是条件独立的:
p ( x ∣ z , c ) = p ( x o ∣ z , c ) p ( x bow ∣ z , c ) p ( z ∣ c ) . (19) p(x|z,c) = p(x_o|z,c)p(x_{\text{bow}}|z,c)p(z|c). \tag{19} p(x∣z,c)=p(xo∣z,c)p(xbow∣z,c)p(z∣c).(19)
这里, c c c 是对话历史:前面的话语,对话地位(如果话语来自同一个说话者则为1,否则为0),以及元特征(例如,主题)。让 f f f 是一个具有参数 z , x z, x z,x 的多层感知机的输出,其中 f ∈ R V f \in \mathbb{R}^V f∈RV 且 V V V 是词汇量大小。然后词袋概率被定义为 log p ( x bow ∣ z , c ) \log p(x_{\text{bow}}|z,c) logp(xbow∣z,c):
log ∏ t = 1 ∣ x ∣ e f x t ∑ j V e f j \log \prod_{t=1}^{|x|} \frac{e^{f_{x_t}}}{\sum_{j}^V e^{f_j}} logt=1∏∣x∣∑jVefjefxt
其中, ∣ x ∣ |x| ∣x∣ 是 x x x 的长度, x t x_t xt 是 x x x 中第 t t t 个词的索引。
为了对抗后验坍塌施加强有力的正则化,我们使用基于训练语料库计算得到的 tf-idf 权重的 tf-idf 加权方案。直观上,这种重加权方案帮助模型专注于重构每个对话状态中独特的非通用术语,这鼓励模型在其表示空间中“拉开”不同对话状态的句子,以更好地最小化加权 BOW 损失。相比之下,一个在均匀加权 BOW 损失下的模型可能会因重构高频率术语(例如,“what is”,“can I”和“when”)而分心,这些术语是所有对话状态共有的。因此,我们指定 tf-idf 加权 BOW 概率为:
tf-idf 加权 BOW 概率定义为:
log p ( x bow ∣ z , c ) = log ∏ t = 1 ∣ x ∣ w x t e f x t ∑ j V e f j (20) \log p(x_{\text{bow}}|z, c) = \log \prod_{t=1}^{|x|} \frac{w_{x_t} e^{f_{x_t}}}{\sum_{j}^V e^{f_j}} \tag{20} logp(xbow∣z,c)=logt=1∏∣x∣∑jVefjwxtefxt(20)
其中, w x t w_{x_t} wxt 是计算出的 tf-idf 权重,由下式给出:
w x t = ( 1 − α ) N + α w x t ′ w_{x_t} = \frac{(1 - \alpha)}{N} + \alpha w'_{x_t} wxt=N(1−α)+αwxt′
N N N 是语料库大小, w x t ′ w'_{x_t} wxt′ 是 x t x_t xt 索引的 tf-idf 词权重, α \alpha α 是一个超参数。在第5节中,我们探讨这种改变如何影响性能,并观察 PSL 约束是否仍然提供了性能提升。