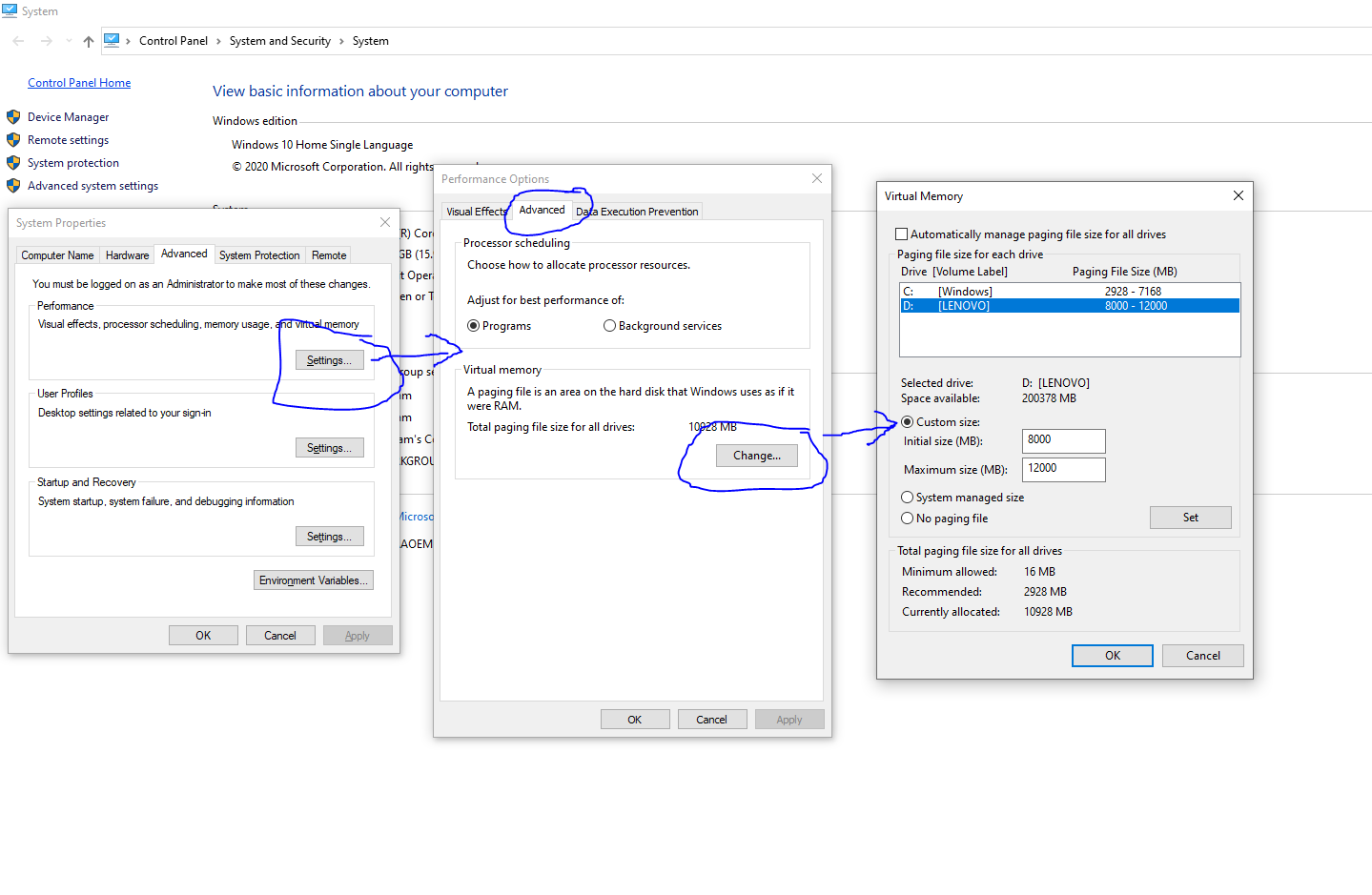
本文部分图文来自《老饼讲解-BP神经网络》bp.bbbdata.com
目录
一、BP神经网络的背景生物学原理
二、BP神经网络模型
2.1 BP神经网络的结构
2.2 BP神经网络的激活函数
三、BP神经网络的误差函数
四、BP神经网络的训练
4.1 BP神经网络的训练流程
4.2 BP神经网络的训练流程图
五、自行实现BP神经网络
六、借助matlab工具箱实现BP神经网络
七、关于BP神经网络的正向传播与反向传播
BP(back propagation)神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,由Rumelhart和McClelland为首的科学家于1986年提出。它是应用最广泛的神经网络模型之一,能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
一、BP神经网络的背景生物学原理
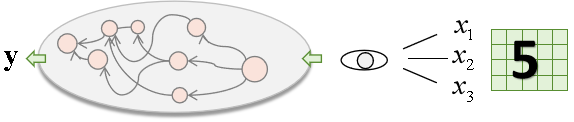
BP神经网络的设计思路是什么呢?它借鉴于人脑的工作原理
在眼睛看到符号“5”的后,大脑将判别出它是5。
BP正是要模仿这个行为,把这个行为过程简单拆分为:
(1) 眼睛接受了输入
(2) 把输入信号传给其它脑神经元
(3) 脑神经元综合处理后,输出结果为5
我们都知道, 神经元与神经元之间是以神经冲动的模式进行传值,信号到了神经元,都是以电信号的形式存在,
当电信号在神经元积累到超过阈值时,就会触发神经冲动,将电信号传给其它神经元。
正是根据这个思路,就构造出了以上的神经网络结构
二、BP神经网络模型
2.1 BP神经网络的结构
BP神经网络模型拓扑结构包括输入层(input)、隐层(hidden layer)和输出层(output layer)。
BP神经网络的结构包括输入层、输出层和若干层隐含层,每层都有若干个节点,层与层之间节点的链接状态通过权重来体现。其中,输入层的节点个数等于输入的维度,输出层的节点个数等于输出的维度,而隐含层的节点个数可以根据实际情况自行设定。在BP神经网络中,每个节点都包含一个感知器(即一个单独的神经元),其包含输入项、权重、偏置、激活函数和输出。在正向传播过程中,输入数据经过感知器节点的计算后,通过激活函数的处理得到输出结果;而在反向传播过程中,将结果与期望结果进行比较,通过多次迭代不断调整网络上各个节点的权重。
一个三层的BP神经网络模型如下:

一个多层的BP神经网络模型如下:

它每层的计算公式为
其中,T代表的是激活函数,b代表的是激活阈值,W代表的是连接权重
对于多层网络,采用的是前馈传播的方式进行计算,即每一层都按以上的公式进行计算,直到最后一个输出层。
2.2 BP神经网络的激活函数
BP神经网络的激活函数最常用的为以下两种:
tansig函数为S型函数:
purelin 为恒等线性映射函数:
三、BP神经网络的误差函数
BP神经网络的误差函数为均方差函数:
其中,m为训练样本个数,k为输出个数,
为第i个样本第j个输出的预测值,
为对应的真实值。
四、BP神经网络的训练
BP神经网络的学习也就是就是求解一组W、b,使得BP神经网络的误差函数最小。
4.1 BP神经网络的训练流程
BP神经网络的训练采用反向传播算法(Back Propagation),反向传播是一种优化算法,通过不断调整网络中各个神经元之间的连接权值,使得神经网络能够对输入和输出之间的映射关系进行学习。具体来说,反向传播算法通过计算每一层的状态和激活值,从最后一层向前推进计算误差,并更新参数以最小化网络的预测输出与实际输出之间的误差。这个过程会不断迭代,直到满足停止准则(比如相邻两次迭代的误差差别很小)。
总的来说,就是每迭代一步,就使误差下降一小步,最终求得一个局部最优的权重和阈值,
BP的训练算法流程:
1.初始化权重、阈值
2.计算权重、阈值的梯度
3.将权重、阈值往负梯度方向迭代
4.检查是否终止条件,否则重复2.3
4.2 BP神经网络的训练流程图
BP神经网络训练流程图如下:

五、自行实现BP神经网络
自行编写代码求解BP神经网络
现有如下数据:
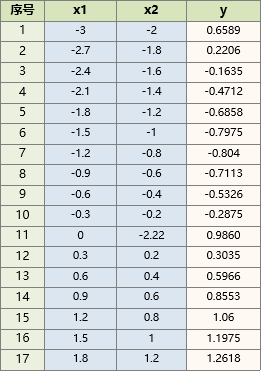
y实际是由 生成
现在需要利用数据训练一个BP神经网络,对其进行拟合,
并测试网络的预测结果与真实结果 的差异
下面是 梯度下降法 求解 BP神经网络 的代码实现
matla2018 a 已新测跑通
close all;clear all;
%-----------数据----------------------
x1 = [-3,-2.7,-2.4,-2.1,-1.8,-1.5,-1.2,-0.9,-0.6,-0.3,0,0.3,0.6,0.9,1.2,1.5,1.8];% x1:x1 = -3:0.3:2;
x2 = [-2,-1.8,-1.6,-1.4,-1.2,-1,-0.8,-0.6,-0.4,-0.2,-2.2204,0.2,0.4,0.6,0.8,1,1.2]; % x2:x2 = -2:0.2:1.2;
X = [x1;x2]; % 将x1,x2作为输入数据
y = [0.6589,0.2206,-0.1635,-0.4712,-0.6858,-0.7975,-0.8040,...-0.7113,-0.5326,-0.2875 ,0.9860,0.3035,0.5966,0.8553,1.0600,1.1975,1.2618]; % y: y = sin(x1)+0.2*x2.*x2;%--------参数设置与常量计算-------------
setdemorandstream(88);
hide_num = 3;
lr = 0.05;
[in_num,sample_num] = size(X);
[out_num,~] = size(y);%--------初始化w,b和预测结果-----------
w_ho = rand(out_num,hide_num); % 隐层到输出层的权重
b_o = rand(out_num,1); % 输出层阈值
w_ih = rand(hide_num,in_num); % 输入层到隐层权重
b_h = rand(hide_num,1); % 隐层阈值
simy = w_ho*tansig(w_ih*X+repmat(b_h,1,size(X,2)))+repmat(b_o,1,size(X,2)); % 预测结果
mse_record = [sum(sum((simy - y ).^2))/(sample_num*out_num)]; % 预测误差记录% ---------用梯度下降训练------------------
for i = 1:5000%计算梯度hide_Ac = tansig(w_ih*X+repmat(b_h,1,sample_num)); % 隐节点激活值dNo = 2*(simy - y )/(sample_num*out_num); % 输出层节点梯度dw_ho = dNo*hide_Ac'; % 隐层-输出层权重梯度db_o = sum(dNo,2); % 输出层阈值梯度dNh = (w_ho'*dNo).*(1-hide_Ac.^2); % 隐层节点梯度dw_ih = dNh*X'; % 输入层-隐层权重梯度db_h = sum(dNh,2); % 隐层阈值梯度%往负梯度更新w,bw_ho = w_ho - lr*dw_ho; % 更新隐层-输出层权重 b_o = b_o - lr*db_o; % 更新输出层阈值w_ih = w_ih - lr*dw_ih; % 更新输入层-隐层权重 b_h = b_h - lr*db_h; % 更新隐层阈值% 计算网络预测结果与记录误差simy = w_ho*tansig(w_ih*X+repmat(b_h,1,size(X,2)))+repmat(b_o,1,size(X,2));mse_record =[mse_record, sum(sum((simy - y ).^2))/(sample_num*out_num)];
end% -------------绘制训练结果与打印模型参数-----------------------------
h = figure;
subplot(1,2,1)
plot(mse_record)
subplot(1,2,2)
plot(1:sample_num,y);
hold on
plot(1:sample_num,simy,'-r');
set(h,'units','normalized','position',[0.1 0.1 0.8 0.5]);
%--模型参数--
w_ho % 隐层到输出层的权重
b_o % 输出层阈值
w_ih % 输入层到隐层权重
b_h % 隐层阈值运行结果:


在训练过程中,还需要注意以下几点:
- 激活函数的选择:常用的激活函数包括Sigmoid函数、Purelin函数等(对于深度学习,一般还会选择Relu等函数),需要根据具体问题选择合适的激活函数。
- 初始权重的选择:权重的初始值对网络的训练结果有很大的影响,需要进行适当的选择。
- 学习率的选择:学习率决定了每次更新权重的幅度,太大的学习率可能导致训练不稳定,太小的学习率则会导致训练速度变慢。
- 迭代次数和停止条件的选择:需要根据问题的复杂程度和数据集的大小来确定迭代次数和停止条件。
- 正则化方法的选择:正则化方法可以防止过拟合现象的发生,常用的正则化方法包括L1正则化、L2正则化等。
六、借助matlab工具箱实现BP神经网络
借助matlab工具箱实现BP神经网络却较为简单,只需调用newff函数构建网络,并设置相应的参数进行训练就可以,代码如下:
x1 = [-3,-2.7,-2.4,-2.1,-1.8,-1.5,-1.2,-0.9,-0.6,-0.3,0,0.3,0.6,0.9,1.2,1.5,1.8]; % x1:x1 = -3:0.3:2;
x2 = [-2,-1.8,-1.6,-1.4,-1.2,-1,-0.8,-0.6,-0.4,-0.2,-2.2204,0.2,0.4,0.6,0.8,1,1.2]; % x2:x2 = -2:0.2:1.2;
y = [0.6589,0.2206,-0.1635,-0.4712,-0.6858,-0.7975,-0.8040,...-0.7113,-0.5326,-0.2875 ,0,0.3035,0.5966,0.8553,1.0600,1.1975,1.2618]; % y: y = sin(x1)+0.2*x2.*x2;inputData = [x1;x2]; % 将x1,x2作为输入数据
outputData = y; % 将y作为输出数据
setdemorandstream(88888);%指定随机种子,这样每次训练出来的网络都一样。%使用用输入输出数据(inputData、outputData)建立网络,
%隐节点个数设为3.其中隐层、输出层的传递函数分别为tansig和purelin,使用trainlm方法训练。net = newff(inputData,outputData,3,{'tansig','purelin'},'trainlm');%设置一些常用参数
net.trainparam.goal = 0.0001; % 训练目标:均方误差低于0.0001
net.trainparam.show = 400; % 每训练400次展示一次结果
net.trainparam.epochs = 15000; % 最大训练次数:15000.
[net,tr] = train(net,inputData,outputData); % 调用matlab神经网络工具箱自带的train函数训练网络simout = sim(net,inputData); % 调用matlab神经网络工具箱自带的sim函数得到网络的预测值
figure; % 新建画图窗口窗口
t=1:length(simout);
plot(t,y,t,simout,'r') % 画图,对比原来的y和网络预测的y运行结果:

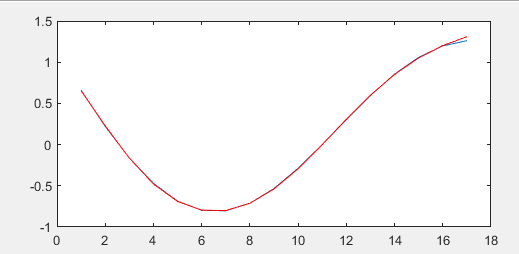
第一个图是matlab训练过程的示图,第二个图是BP神经网络的拟合结果(红色)与原始数据(蓝色)的曲线
七、关于BP神经网络的正向传播与反向传播
BP神经网络的计算过程包括正向传播和反向传播两个阶段。
在正向传播阶段,输入数据通过输入层进入网络,经过隐含层和输出层的计算后得到输出结果。每一层的神经元之间存在连接关系,连接的权重和偏置都可以通过训练进行学习和调整。在正向传播过程中,输入数据经过感知器节点的计算后,通过激活函数的处理得到输出结果。
在反向传播阶段,将输出结果与期望结果进行比较,计算误差,然后从输出层向隐层逐层反向传播误差,并更新网络中各神经元的权重和偏置,以减小误差。这个过程会不断迭代,直到满足停止准则。在反向传播过程中,根据梯度下降法,利用梯度搜索技术来更新权重和偏置。
在BP神经网络的计算过程中,需要选择合适的激活函数、初始权重、学习率、迭代次数和停止条件等参数,以保证网络的训练效果和泛化能力。
好了,这就是BP神经网络
更多文章
相关文章
1-LVQ的学习目录:老饼|BP神经网络-竞争神经网络
2-径向基神经网络学习目录:老饼|BP神经网络-感知机与SVM
3-BP的学习目录:老饼|BP神经网络-BP入门