目录
HDFS的机制
元数据简介
元数据存储流程:namenode 生成了多个edits文件和一个fsimage文件
edits和fsimage文件
SecondaryNameNode辅助NameNode的方式:
HDFS的存储原理
写入数据原理: 发送写入请求,获取主节点同意,开始写入,写入完成
读取数据原理:发送读取请求,获取主节点同意,开始读取,读取完成
HDFS安全机制
HDFS归档机制
HDFS垃圾桶机制
分布式存储:一台计算机无法进行存储,则由多台计算机来存储,分布式存储最早是由谷歌提出的,其目的是通过廉价的服务器来提供使用与大规模,高并发场景下的 Web 访问问题。它 采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
接着此前的内容
https://blog.csdn.net/m0_49956154/article/details/134324386?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_49956154/article/details/134298109?spm=1001.2014.3001.5501
hive切块的作用:为了方便统一管理
hive副本的作用:默认3个,为了保证数据的安全性
HDFS的机制
副本机制: 为了保证数据安全和效率,block块信息存储多个副本,第一副本保存在客户端所在服务器,第二副本保存在和第一副本不同机架服务器上,第三副本保存在和第二副本相同机架不同服务器
负载均衡机制: namenode为了保证不同的datanode中block块信息大体一样,分配存储任务的时候会优先保存在余量比较大的datanaode上
心跳机制: datanode每隔3秒钟向namenode汇报自己的状态信息,如果某个时刻,datanode连续10次不汇报了(30秒),namenode会认为datanode有可能宕机了,namenode就会每5分钟(300000毫秒)发送一次确认消息,连续2次没有收到回复,就认定datanode此时一定宕机了(确认datanode宕机总时间3*10+5*2*60=630秒)
元数据简介
元数据:为了描述数据的数据
元数据: 内存元数据 和 文件元数据 两种分别在内存和磁盘上
内存元数据: namnode运行过程中产生的元数据会先保存在内存中,再保存到文件元数据中。
内存元数据优缺点: 优点: 因为内存处理数据的速度要比磁盘快。 缺点: 内存一断电,数据全部丢失
文件元数据: Edits 编辑日志文件和fsimage 镜像文件
Edits编辑日志文件: 存放的是Hadoop文件系统的所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到edits文件中
Fsimage镜像文件: 是元数据的一个持久化的检查点,包含Hadoop文件系统中的所有目录和文件元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode加入集群的时候,namenode询问datanode得到的,并且不间断的更新
元数据存储流程:namenode 生成了多个edits文件和一个fsimage文件

edits和fsimage文件
edits文件会被合并到fsimage中,这个合并由SecondaryNamenode来操作.
namenode管理元数据: 基于edits和FSImage的配合,完成整个文件系统文件的管理。每次对HDFS的操作,均被edits文件记录, edits达到大小上限后,开启新的edits记录,定期进行edits的合并操作
如当前没有fsimage文件, 将全部edits合并为第一个fsimage文件
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
edits编辑文件: 记录hdfs每次操作(namenode接收处理的每次客户端请求)
fsimage镜像文件: 记录某一个时间节点前的当前文件系统全部文件的状态和信息(namenode所管理的文件系统的一个镜像)
SecondaryNameNode辅助NameNode的方式:
SecondaryNameNode辅助合并元数据: SecondaryNameNode会定期从NameNode拉取数据(edits和fsimage)然后合并完成后提供给NameNode使用。
对于元数据的合并,是一个定时过程,基于两个条件:(也叫checkpoint)
dfs.namenode.checkpoint.period:默认3600(秒)即1小时
dfs.namenode.checkpoint.txns: 默认1000000,即100W次事务
dfs.namenode.checkpoint.check.period: 检查是否达到上述两个条件,默认60秒检查一次,只要有一个达到条件就执行拉取合并
HDFS的存储原理
写入数据原理: 发送写入请求,获取主节点同意,开始写入,写入完成
1.客户端发起写入数据的请求给namenode
2.namenode接收到客户端请求,开始校验(是否有权限,路径是否存在,文件是否存在等),如果校验没问题,就告知客户端可以写入
3.客户端收到消息,开始把文件数据分割成默认的128m大小的的block块,并且把block块数据拆分成64kb的packet数据包,放入传输序列
4.客户端携带block块信息再次向namenode发送请求,获取能够存储block块数据的datanode列表
5.namenode查看当前距离上传位置较近且不忙的datanode,放入列表中返回给客户端
6.客户端连接datanode,开始发送packet数据包,第一个datanode接收完后就给客户端ack应答(客户端就可以传入下一个packet数据包),同时第一个datanode开始复制刚才接收到的数据包给node2,node2接收到数据包也复制给node3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道
7.其他packet数据根据第一个packet数据包经过的传输通道和应答通道,循环传入packet,直到当前block块数据传输完成(存储了block信息的datanode需要把已经存储的块信息定期的同步给namenode)
8.其他block块数据存储,循环执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(namenode把该文件的元数据保存上)
9.最后客户端和namenode互相确认文件数据已经保存完成(也会汇报不能使用的datanode)
读取数据原理:发送读取请求,获取主节点同意,开始读取,读取完成
1.客户端发送读取文件请求给namenode
2.namdnode接收到请求,然后进行一系列校验(路径是否存在,文件是否存在,是否有权限等),如果没有问题,就告知可以读取
3.客户端需要再次和namenode确认当前文件在哪些datanode中存储
4.namenode查看当前距离下载位置较近且不忙的datanode,放入列表中返回给客户端
5.客户端找到最近的datanode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包),放到内存缓冲区中
6.接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据)
7.最后从内存缓冲区把数据通过流写入到目标文件中
8.最后客户端和namenode互相确认文件数据已经读取完成(也会汇报不能使用的datanode)
序列化-本地到内存
反序列化 - 内存到本地
HDFS安全机制
#查看安全模式状态:
[root@node1 /]# hdfs dfsadmin -safemode get
Safe mode is OFF
#开启安全模式:
[root@node1 /]# hdfs dfsadmin -safemode enter
Safe mode is ON
#退出安全模式:
[root@node1 /]# hdfs dfsadmin -safemode leave
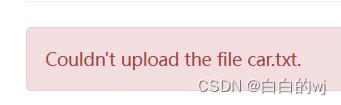
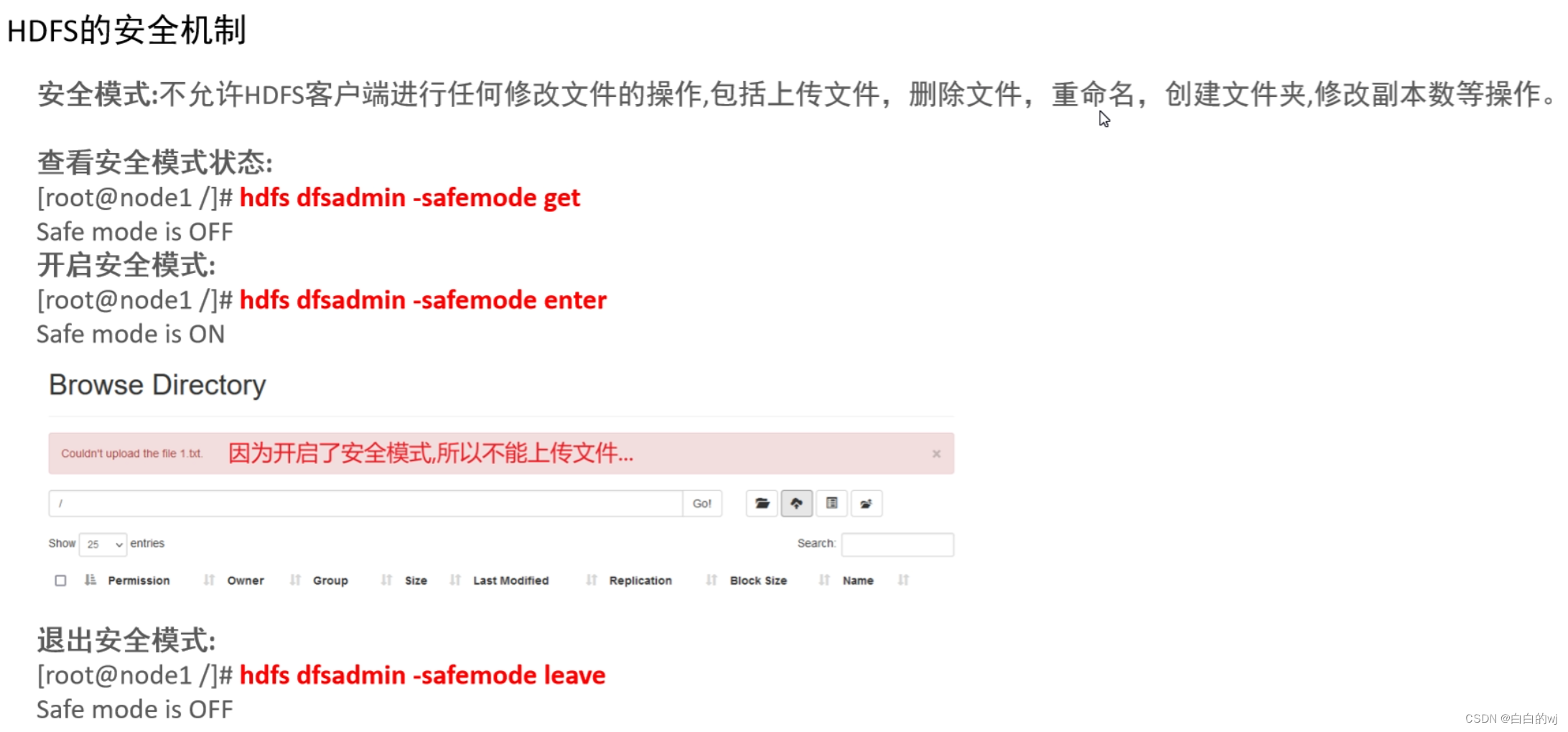
Safe mode is OFF开启后在网页端上传文件会提示:
首页也会进行提示

HDFS归档机制
归档原因: 每个小文件单独存放到hdfs中(占用一个block块),那么hdfs就需要依次存储每个小文件的元数据信息,相对来说浪费资源
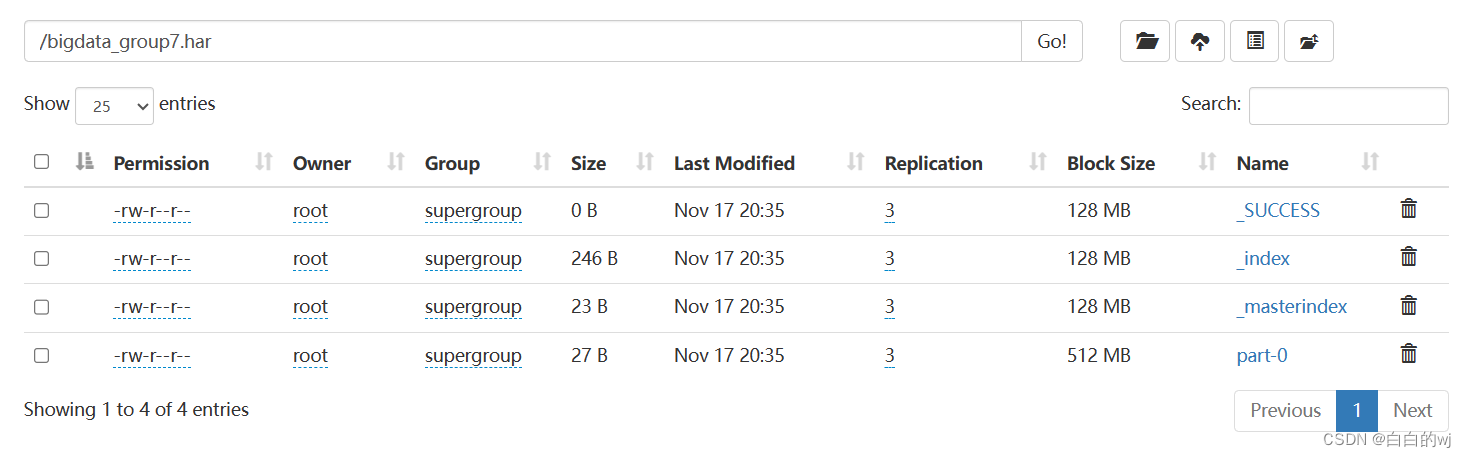
归档格式: hadoop archive -archiveName 归档名.har -p 原始文件的目录 归档文件的存储目录
[root@node1 ~]# hadoop archive -archiveName bigdata_group7.har -p /input /
结果

HDFS垃圾桶机制
设置了垃圾桶机制好处: 文件不会立刻消失,可以去垃圾桶里把文件恢复,继续使用

在hdfs的网页里删除就是永久删除
在linux里面远程命令删除,就会放到回收站里
在虚拟机中rm命令删除文件,默认是永久删除
在虚拟机中需要手动设置才能使用垃圾桶回收: 把删除的内容放到: /user/root/.Trash/Current/ 先关闭服务: 在 node1 中执行 stop-all.sh 新版本不关闭服务也没有问题 再修改文件 core-site.xml : 进入/export/server/hadoop-3.3.0/etc/hadoop目录下进行修改:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
# 没有开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm /binzi/hello.txt
Deleted /binzi/hello.txt# 开启垃圾桶
[root@node1 ~]#cd /export/server/hadoop-3.3.0/etc/hadoop
[root@node1 hadoop]# vim core-site.xml
# 注意: 放到<configuration>内容</configuration>中间
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property># 开启垃圾桶效果
[root@node1 hadoop]# hdfs dfs -rm -r /test1.har
2023-05-24 15:07:33,470 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1.itcast.cn:8020/test1.har' to trash at: hdfs://node1.itcast.cn:8020/user/root/.Trash/Current/test1.har# 开启垃圾桶后并没有真正删除,还可以恢复
[root@node1 hadoop]# hdfs dfs -mv /user/root/.Trash/Current/test1.har /