- Java如何保证非线程安全的数据结构(比如HashMap)的原子性?读多写少时用哪种锁好? A: 方法1:CAS等乐观锁机制,方法2:如果读多写少,可以使用读写锁(ReentrantReadWriteLock)
- 如何判断线上程序发生死锁?参考答案:jstack。Q:jstack具体如何操作和分析?
实操答案(系统Windows10, 本文基本参考1):
Java代码:
public class DeadLockCase {public static void main(String[] args){Object o1 = new Object();Object o2 = new Object();new Thread(new SyncThread(o1, o2), "t1").start();new Thread(new SyncThread(o2, o1), "t2").start();}static class SyncThread implements Runnable {private Object lock1;private Object lock2;public SyncThread(Object o1, Object o2){this.lock1 = o1;this.lock2 = o2;}@Overridepublic void run() {String name = Thread.currentThread().getName();System.out.println(name + " acquiring lock on " + lock1);synchronized (lock1) {System.out.println(name + " acquired lock on " + lock1);work();System.out.println(name + " acquiring lock on " + lock2);synchronized (lock2) {System.out.println(name + " acquired lock on " + lock2);work();}System.out.println(name + " released lock on " + lock2);}System.out.println(name + " released lock on " + lock1);}private void work() {try {//模拟死锁的关键,保证线程1只能获取一个锁,而线程2能获取到另一个锁Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
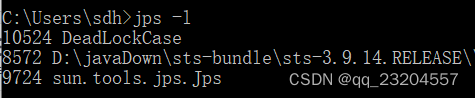
- 用jps命令查看当前系统中所有正在运行的 Java 进程,以及这些进程的 PID 等信息:
jps -l:
- 用
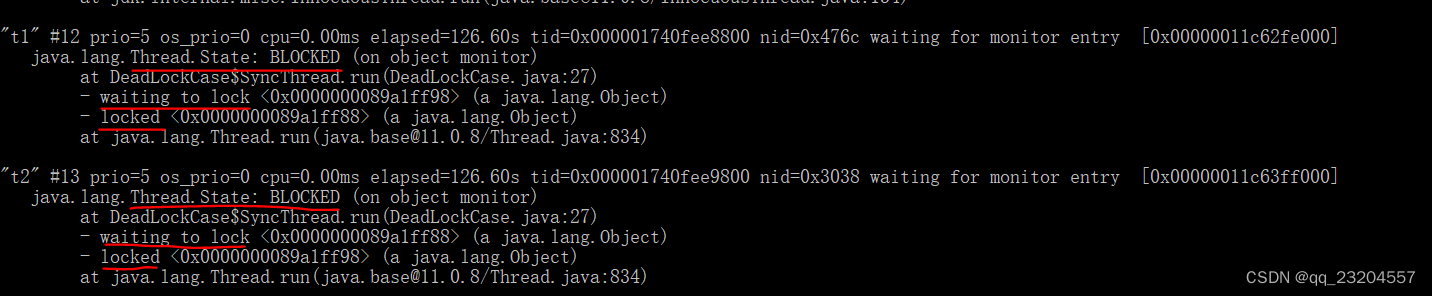
jstack <pid>命令可以输出对应Java进程的线程快照信息:
运行jstack 10524 后得到的部分关键结果的截屏如下两图。可以看到各线程的状态、线程已占用的锁和正申请的锁、以及死锁信息。
。。。

-
如何解决RabbitMQ重复消费的问题
-
spring有个注解
@Async能实现异步处理,有用过吗?Answer by new bing: 是的,@Async注解可以让Spring中的方法异步执行。使用该注解后,Spring会将该方法放到一个线程池中执行,而不是在调用该方法的线程中执行。这样可以避免阻塞调用线程,提高系统的并发能力。 -
起一个线程耗多少内存,可以通过JVM的什么参数来控制吗? Answer by new bing: 可以使用
-Xss参数来设置每个线程的栈大小。默认情况下,每条线程的栈大小为1M。 -
Spring事务传播机制。我有一个业务类,它有两个方法,方法A是REQUIRED,方法B是REQUIRES_NEW,方法A调用方法B,外部调用方法A,会启动几个事务?Q:如果两个方法不在同一个类呢?
-
Redis List底层的数据结构是什么? 参考答案:
-
- Redis3.2之前(此段参考new bing以及2,3),Redis List底层的数据结构有两种:压缩列表(ziplist)和双向链表(linkedlist). Redis在创建新的List时,会优先考虑使用压缩列表. 在满足条件(1,试图往列表添加一个字符串值,这个字符串的长度超过某个值; 或者2,ziplist 包含的节点超过某个值)时,才从压缩列表实现转换到双向链表实现。
ziplist 是一个特殊的双向链表
特殊之处在于:没有维护双向指针:prev next;而是存储上一个 entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方。
-
- Redis3.2版本开始对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist.
quicklist 实际上是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。4
- Redis3.2版本开始对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist.
-
Redis如果采用AOF持久化方式,每隔5秒持久化一次,那它持久化时会影响其它读写线程吗?会不会阻塞主线程?参考答案5,6:AOF采用everysec时,Redis使用另一条线程每秒执行fsync同步硬盘。主线程在执行时候如果发现上一次的fsync操作还没有返回(对比上一次的fsync操作时间,大于2秒),主线程就会阻塞。 如图所示:
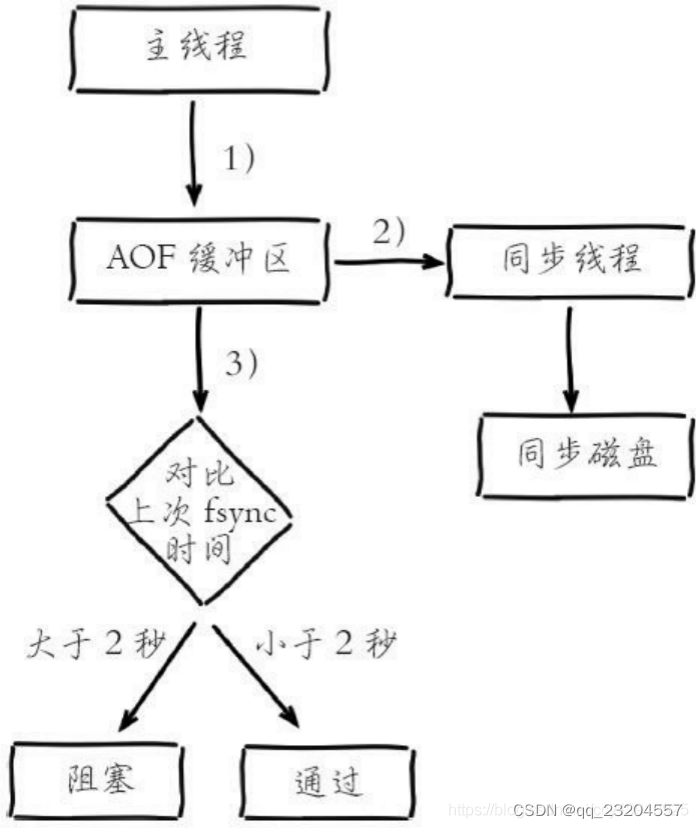
当系统硬盘资源繁忙时,会造成Redis主线程阻塞
简单来说,如果系统fsync缓慢,将会导致Redis主线程阻塞。
Q:Redis里存了几百个Key,遍历读取它们的值可能需要一两秒,有没有效率更高的方法?参考答案:
- 方法1,mget;
- 方法2,pipeline。
值得注意的是:
- 性能上7,8: MGET 》PIPELINE》GET
- mget等命令可以保证原子性,pipeline 无法保证9
- 与 mget、mset 相同的是,pipeline 操作也无法在原生的集群模式下工作9
Q:使用redis pipeline有什么需要注意的?参考答案(主要参考new bing):在使用Redis Pipeline时,需要注意以下几点:
- 每次Pipeline携带数量不推荐过大,否则会影响网络性能,也会消耗更多redis的内存占用。
- Pipeline每次只能作用在一个Redis节点上(就是上文提到的pipeline无法在原生的集群模式下工作)。
jstack分析线程快照的三步曲及CPU占用过高和死锁问题的排查-CSDN博客 ↩︎
Redis官网:The ziplist representation ↩︎
知乎:Redis列表list 底层原理 ↩︎
Redis数据结构——快速列表(quicklist) ↩︎
Redis 分享-AOF的阻塞简单记录 ↩︎
Redis AOF 追加阻塞问题分析处理 ↩︎
Performance benchmarks - redis get vs mget ↩︎
Sharing: Redis get pipeline vs mget ↩︎
如何通过批量操作提升 redis 性能 ↩︎ ↩︎


