目录
https://blog.csdn.net/m0_49956154/article/details/134365327?spm=1001.2014.3001.5501https://blog.csdn.net/m0_49956154/article/details/134365327?spm=1001.2014.3001.5501
8.hive的复杂类型
9.array类型: 又叫数组类型,存储同类型的单数据的集合
10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合
11.map类型: 又叫映射类型,存储键值对数据的映射(根据key找value)
把之前的内容单独拿出来
https://blog.csdn.net/m0_49956154/article/details/134365327?spm=1001.2014.3001.5501 https://blog.csdn.net/m0_49956154/article/details/134365327?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_49956154/article/details/134365327?spm=1001.2014.3001.5501
8.hive的复杂类型

---------------------------复杂类型建表格式------------------------ -- 复杂类型建表格式:[row format delimited] # hive的serde机制[fields terminated by '字段分隔符'] # 自定义字段分隔符固定格式[collection ITEMS terminated by '集合分隔符'] # 自定义array同类型集合和struct不同类型集合[map KEYS terminated by '键值对分隔符'] # 自定义map映射kv类型[lines terminated by '\n'] # # 默认即可hive复杂类型: array struct map
9.array类型: 又叫数组类型,存储同类型的单数据的集合
-- array类型: 又叫数组类型,存储同类型的单数据的集合 -- 建表指定类型: array<数据类型> -- 取值: 字段名[索引] 注意: 索引从0开始 -- 获取长度: size(字段名) -- 判断是否包含某个数据: array_contains(字段名,某数据)
需求: 已知data_for_array_type.txt文件,存储了学生以及居住过的城市信息,要求建hive表把对应的数据存储起
1.创建表
[collection ITEMS terminated by '集合分隔符'] # 自定义array同类型集合和struct不同类型集合
----建表,
create table test_array_1(name string,location array<string>
)row format delimited
fields terminated by '\t'
collection items terminated by ',';2.加载数据

-
load data inpath '/itcast/data_for_array_type.txt' into table test_array_1;
3.验证数据
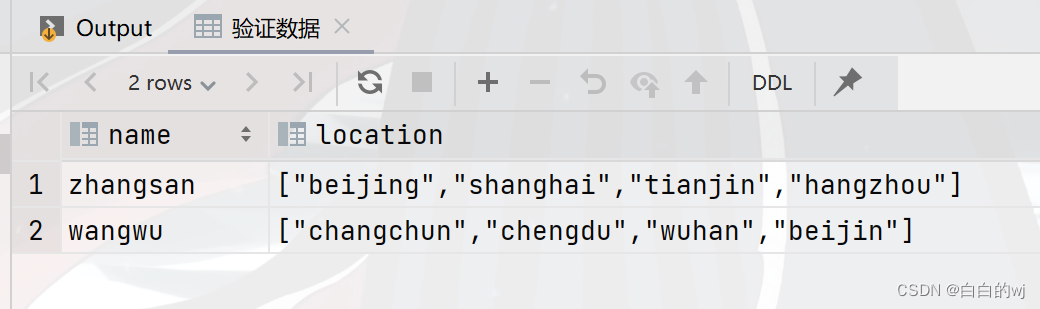
4.需求:查询张三是否在天津住过?
-
select array_contains(location,'tianjin')from test_array_1 where name = 'zhangsan'; -
--结果:true
5. 需求:查询张三的地址有几个?
-
select size(location)from test_array_1 where name = 'zhangsan'; -
--结果:4
6.需求:查询王五的第二个地址?
-
select location[1] from test_array_1 where name = 'wangwu'; -
--结果:chengdu
10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合
-- 建表指定类型: struct<子字段名1:数据类型1, 子字段名2:数据类型2 , ...> -- 取值: 字段名.子字段名n
[collection ITEMS terminated by '集合分隔符'] # 自定义array同类型集合和struct不同类型集合
1.建表
-- 建表
create table test_struct_1(id int,name_info struct<name:string,age:int>
)row format delimited fields terminated by '#'
collection items terminated by ':';2.加载数据
load data inpath '/itcast/data_for_struct_type.txt' into table test_struct_1;

3.验证数据
select * from test_struct_1;
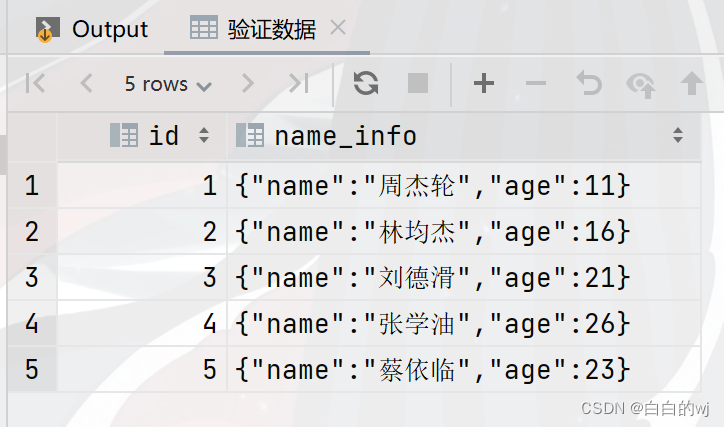
需求1:查询所有用户姓名
select name_info.name from test_struct_1;需求2:查询所有的用户年龄
select name_info.age from test_struct_1;需求3:查询所有用户的平均年龄
11.map类型: 又叫映射类型,存储键值对数据的映射(根据key找value)
-- 建表指定类型: map<key类型,value类型> -- 取值: 字段名[key] -- 获取长度: size(字段名) -- 获取所有key: map_keys() -- 获取所有value: map_values()
1.创建表
--创建表
create table test_map_1(id int,name string,members map<string,string>,age int
)row format delimited
fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';2.加载数据
load data inpath '/itcast/data_for_map_type.txt'into table test_map_1;

3.验证数据
--验证数据
select * from test_map_1;
-- 1,林杰均,"{""father"":""林大明"",""mother"":""小甜甜"",""brother"":""小甜""}",28
-- 2,周杰伦,"{""father"":""马小云"",""mother"":""黄大奕"",""brother"":""小天""}",22
-- 3,王葱,"{""father"":""王林"",""mother"":""如花"",""sister"":""潇潇""}",29
-- 4,马大云,"{""father"":""周街轮"",""mother"":""美美""}",26需求1:查询每个学生的家庭成员关系(就是所有的key)
select name,map_keys(members) from test_map_1;需求2:查询每个学生的家庭成员姓名(就是所有的value)
select name ,map_values(members) from test_map_1;需求3:查询每个学生和对应的父亲名字
select name,members['father'] as father from test_map_1;需求4:查询马大云是否有兄弟
select name,array_contains(map_keys(members),'brother') from test_map_1 where name ='马大云';-- 需求5:查询每个学生的对应brother姓名,没有brother的学生null补全-- 需求6:查询每个学生的对应brother姓名,没有brother的学生直接不显示