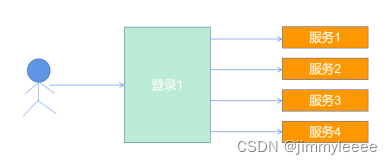
检查点和状态后端的区别
-
检查点 就是某个时间点下的所有算子的状态快照。这个时间点就是等所有任务将“同一个数据”处理完毕的时候。
-
状态后端:是一个管理状态的组件,还负责将本地状态(检查点)持久化到远程文件存储系统中。
分类:
(1) 基于内存的hashmap状态后端。性能高,但是有内存资源耗尽的风险
(2) 基于rocksdb持久化存储的状态后端。适用于状态大,窗口长的情况下,因为会序列化和反序列化,访问状态的性能会差点。
我们用就是rocksdb状态后端。
检查点的存储:
-
jobManager的堆(heap)内存中
-
文件系统
具体实现接口:
(1) 大状态持久化保FileSystemCheckpointStorage:
(2) 性能考虑jobManagerCheckpintStorage
检查点的工作流程:
- 保存source 算子的数据偏移量,一般保存在hdfs外部文件存储
同时向数据流中插入一种特殊数据: 分界线,当遇到keyby这种分区算子,保存状态同时,会将分界线以广播形式分发给下游并行的算子;如果遇到sum这种,会接收上游多个分区的分界线数据,会进行分界线对齐(详细来讲:Sum算子接收两个不同的子任务的数据,收到了第一子任务的分界线数据,但是没收到第二个子任务的分界线数据,这时候如果第二个子任务传来正常的数据需要正常处理的,但是如果是第一个分界线已经到达的子任务再来数据,就需要等待写入缓存,只有第二子任务的分界线数据到达,然后状态保存,再做处理。
),现在版本的flink已经支持不对齐的检查点,会降低反压时候的checkpoint的执行时间,不过需要保存分界线来之前的数据,所以会增大单个checkpoint的大小。
- 然后故障重启后,flink 会读取最近一次的checkpint中的状态,使得各算子恢复到故障前最近一次保存成功的状态。同时source算子会重置数据偏移量,重新消费一遍数据。
精准一次性保证,就是不会重复消费数据,也不会丢失数据。Flink 是通过检查点保证的。
输出端的精准一次如何保证:
-
幂等写入(无论执行多少次,最终结果都一样),如果写入redis 这种键值对存储,数据重复写入,对结果不影响。还有写入mysql 按主键更新数据。
-
还有就是事务写入,将事务与检查点绑定在一起,通过检查点是否成功来提交或者回滚事务。具体来说就是,对不同的外部存储系统,有两种实现方式:
- 对于不支持事务的外部存储系统,可通过预写日志的方式(实现GenericWriteAheadSink),就是将结果数据作为日志保存起来,检查点保存后,将日志也临时持久化存储一下,等jobmanager收到所有任务成功checkpoint完成消息后,再将结果数据批处理写入外部系统。缺陷:数据写入外部系统时,flink会确认保存成功的消息,如果就在确认返回消息时发生故障时,这时checkpoint都成功了,但是数据也写入外部存储系统了,且不支持事务,所以等故障重启时会造成数据重复写入。
- 对于支持事务外部存储系统,可用两阶段提交(two phase commit ; 2pc)的方式(twoPhaseCommitSinkFunction接口,例如:flinkKafkaProducer实现了这个接口),可以真正保证精准一次。具体来说:sink任务会在两种情况下开启一个新事务(对外部存储系统),1. 第一条数据来到;2. 分界线数据来到。开启后,所有的结果数据都会通过事务写入到这个外部系统,虽然已经写入到外部存储,但是以为事务的原因,这些数据不可用,也就是预提交的状态。当所有的算子的快照都保存好后,jobmanger会发出确认完成的通知给sink任务,这时候sink任务会正式提交事务。两阶段提交完成。假如任何时候发生故障,可通过这个未提交的事务,对已写入的数据进行回滚。