前言
2022年11月以来,大语言模型席卷全球,在自然语言任务中表现卓越。尽管存在一系列伦理、安全等方面的担心,但各界对该技术的热情和关注并未减弱。
本文不谈智能伦理方面的问题,仅集中于Ulitpa嬴图在应用中的一些探索与实践,看看大模型+图技术 是如何相互辅助、互相促就的。当然,从最终的易用性和体验上来说,企业(客户)才是这两项技术在珠联璧合后的最终受益者!
01 大模型的局限性
先进的大语言模型(Large Language Model,以下简称大模型),如GPT系列,规模庞大,拥有数百甚至数千亿的参数,在许多复杂任务中展示出巨大的潜力。它们在大量的文本数据上经历了广泛的预训练(Pre-Training),这一过程会耗费大量资源和时间。
很容易理解的是,模型的知识受限于它所训练的数据。训练数据都有一个截止日期(Cutoff Date)。例如,GPT-3.5是使用截止到2021年9月的数据进行训练的,GPT-4目前仅涵盖至2022年1月。跟进实时知识和全球事件对大模型来说是很大的挑战,而且成本相当可观。
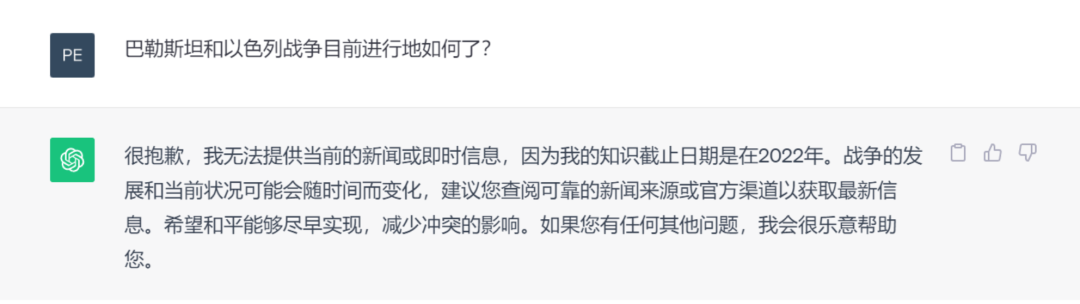
比起承认你提出的问题不在知识库中更糟的是,大模型会给出听起来十分肯定,但实际上并非事实的回应,也就是所谓的幻觉(Hallucination)。与此同时,大模型作为黑盒模型,它们以参数的形式隐式地表示知识。由于大模型生成的结果中没有包含任何来源或参考,我们很难解释或验证其可信度。这严重影响了大模型的应用,尤其是在医疗诊断、金融咨询和法律判断等高风险的场景中。另一个挑战在于,大模型是为了一般用途而训练的,企业专有、保密或敏感的未公开数据并不在它们的知识范围内。
一种改善大模型性能的简单方法是提示工程(Prompt Engineering)。通过在提问时提供清晰的指示和背景信息,大模型可以生成更准确的回应。然而,为了获得最佳结果,这个过程可能需要一定的写作技巧和反复迭代,同时伴随着因文本长度增加而上升的成本。

02 检索增强生成和微调
在将大模型引入业务环境时,出现了两种显著的技术:检索增强生成(Retrieval Augmented Generation)和微调(Fine-Tuning)。
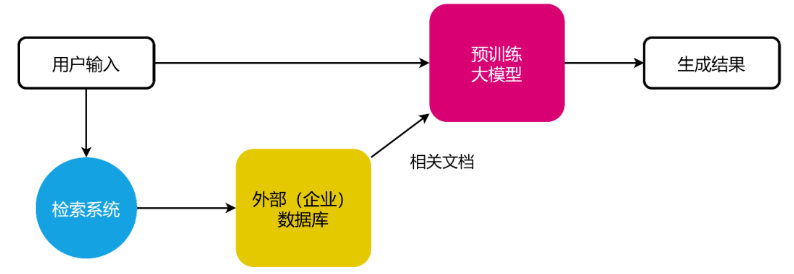
检索增强生成是一种将大模型与外部知识库检索相结合的一种框架。它从特定的外部数据库(区别于大模型的内部知识库)中检索出相关的文档,然后将这些文档与用户的输入一起传递给预训练的大模型,生成最终结果。
典型的检索增强生成应用的策略是:
-
将知识库中的文档按策略切分成较短的片段,为这些文本片段分别生成向量表示。
-
运行期间,将用户的输入文本也嵌入为一个向量,将该向量与知识库的文本向量进行相似性比较后,检索出前N个(例如,前3个)相关文档。
-
随后,大模型基于用户输入和相关文档生成最终结果。
微调是指以一个预训练大模型为基础,使用特定数据集进一步训练模型调整其参数的过程。用于微调的数据集通常比预训练时所需的数据集小,但准备该数据集仍需大量的工作,并且必须与特定的任务目标(如问答、翻译和情感分析)保持一致。最终微调后的大模型会比预训练的大模型在特定任务中有更优秀的表现。
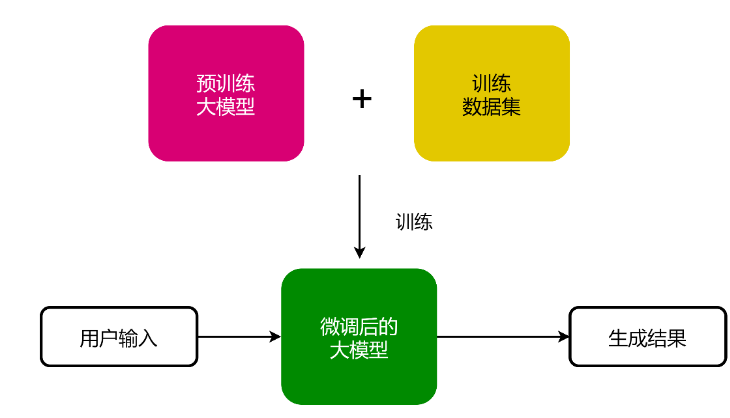
检索增强生成和微调都能在一定程度上减轻预训练大模型的幻觉问题,同时使大模型更适配于企业。选择检索增强生成或微调取决于特定的场景,这两种技术也能够结合使用。但无论如何,为了充分发挥大模型的潜力,图技术是不容忽视的。
03 大模型也需要图能力
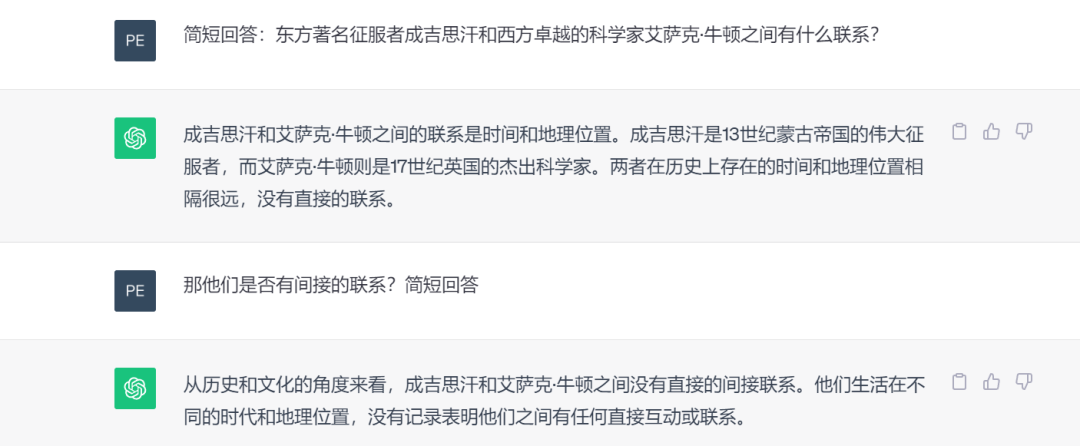
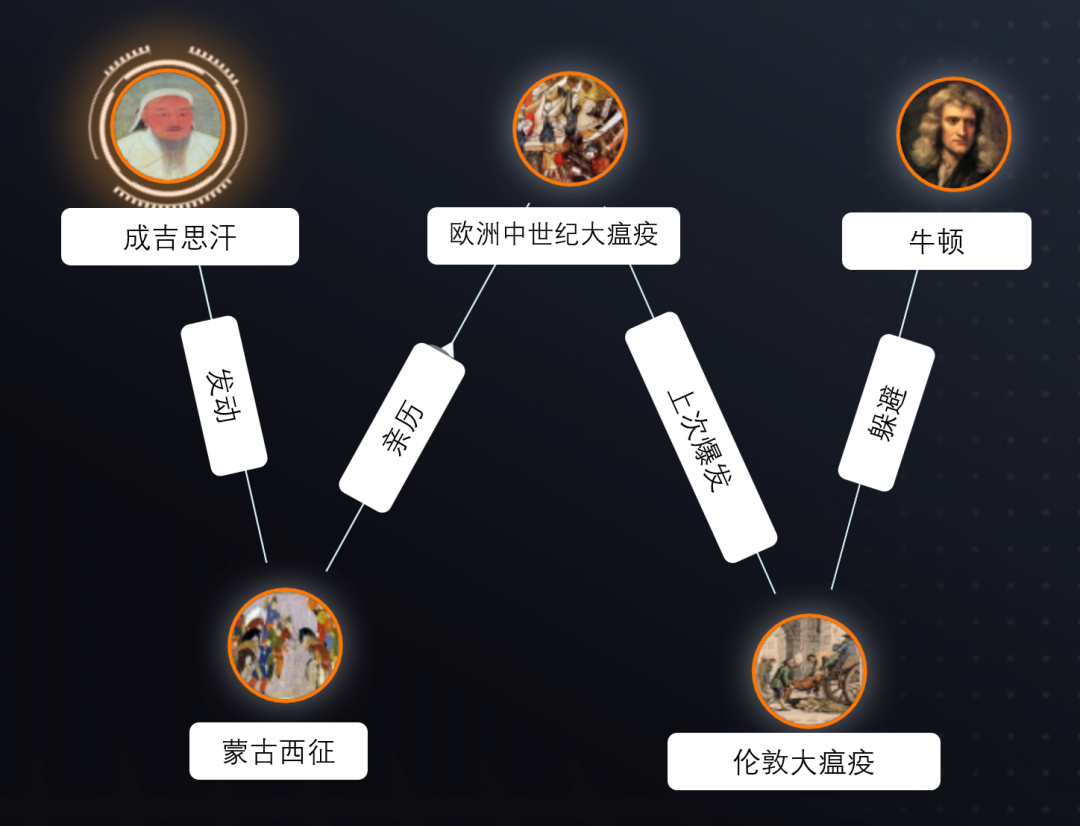
处理深度推理和关联任务时,大模型的限制更加明显。当我们提出一些大胆的问题时,经常会遇到有趣的情景。例如,Ultipa CEO 孙宇熙曾受到一次广播讨论的启发,提出了一个引人入胜的问题:东方著名征服者成吉思汗和西方卓越的科学家艾萨克·牛顿之间有什么联系? 【更多阅读:图数据库知识点2 | 图思维方式 / / 专访 | Ultipa 孙宇熙:从成吉思汗到牛顿再到图数据库】
ChatGPT 无法回答这个问题,因为“两者在历史上存在的时间和地理位置相隔很远”。
但如果我们在一个百科知识图谱中进行检索(您可以使用维基百科进行此操作),搜索成吉思汗(节点)和艾萨克·牛顿(节点)之间的路径时,可以找到许多结果。以下是其中之一:成吉思汗发动了蒙古西征,间接导致了黑死病在欧洲的爆发。这场瘟疫在欧洲肆虐了几个世纪,影响了其发展。在伦敦大瘟疫爆发时,牛顿正值年少时,由于学校关闭,他被遣散到乡下,避免了瘟疫。
这个关联成吉思汗和牛顿的4跳因果关系横跨东西方,跨越了400年的历史。通过图的深度穿透和因果关系搜索,生动地呈现在我们眼前。
现实世界的许多场景都可以用图[1] 【扩展阅读:文库 | 图数据库基础知识—壹】来建模,包括金融网络、交通网络、供应链网络、社交网络、生物网络和各种知识图谱等。图因其互相连接、可追溯和明确的表示方式而久负盛名。许多问题其实都可以视为图的问题:
-
如何监控证券公司的交易和代理行为,避免因监管机构处罚使客户和股东遭受损失?
-
根据客户的帐户状况,哪种投资选项适合他们?
-
现有一系列光源,如何铺设电力传输线最为经济?
-
基于与我有类似观影行为的用户,有哪些电影推荐给我?
-
最近发生在缅甸的罢工将如何影响我们在伦敦的生产线?
-
如何在一片广阔的水域中放置传感器,才能及时检测到污染物?
-
如何根据蛋白质之间相互作用的强度将它们进行分组研究?
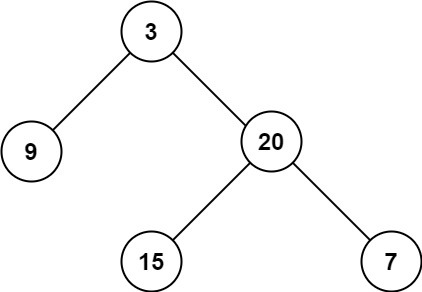
这些分析和算法问题都超越了基于的文本查询或生成。虽然目前大模型在很多领域表现出色,但它们连面对基本的数学问题时都经常遇到困难,比如下面的最短路径问题。
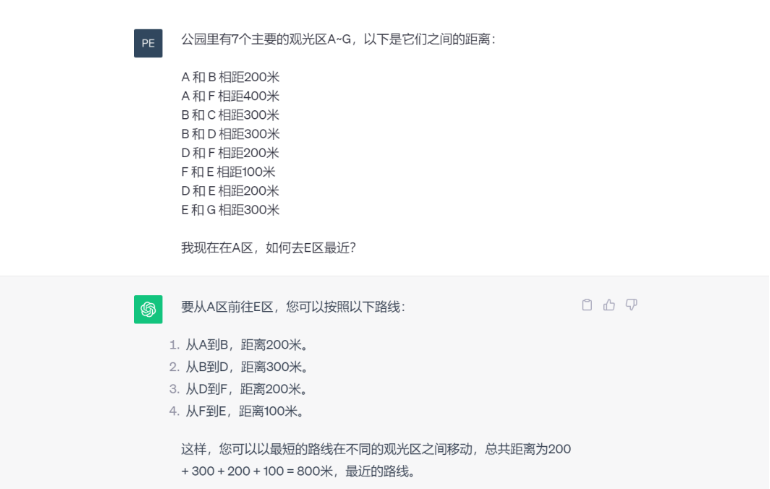
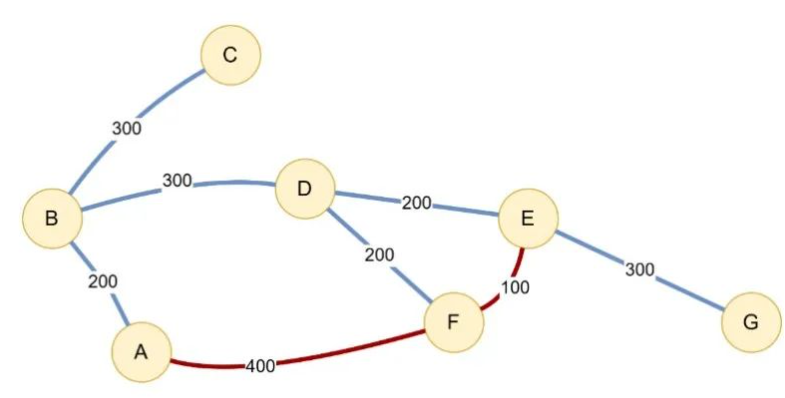
我们要认识到,大模型原本并不是为了这些类型的任务而设计的。然而,在为业务目的构建智能系统时,解决这类问题的能力往往是不可或缺的。
04 融合方案:大模型+图技术
许多研究人员已经认识到大模型和图技术之间固有的互补性。通过结合大模型的文本理解能力和图的结构化推理能力,能够整体增强AI系统的功能性、智能性和可解释性。
下面,我们将讨论Ultipa嬴图已经实现的两个应用,以展现大模型和图之间的相互增强关系。
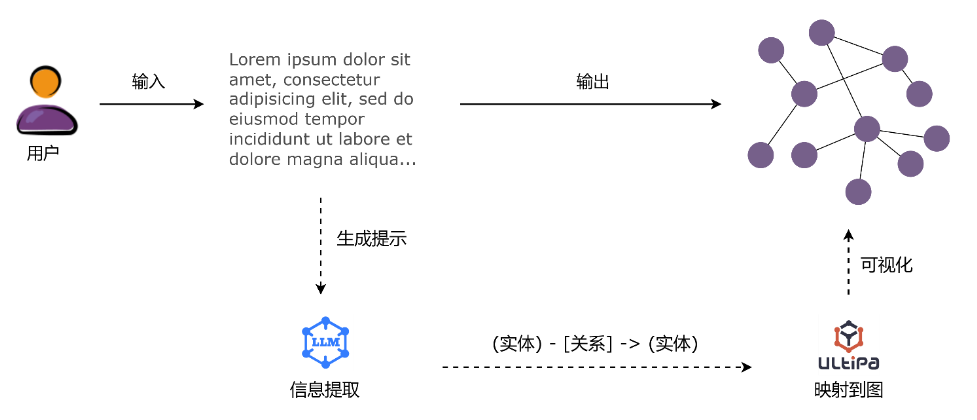
使用大模型构建图
将结构化数据,例如表格数据,转化为图的过程相对简单。通过设计适当的图模型(包括节点和边的类型和属性),就可以进行明确地映射和数据迁移。
然而,从非结构化的文本数据创建图则是一项复杂的任务,一般需要先进的自然语言处理技术协助,如命名实体识别、关系提取和语义解析等。但这些方法可能需要大量的规则或监督训练,性能也取决于训练数据的质量和数量。
大模型在处理大规模非结构化文本数据中的实体发现、指代消解和关系提取方面表现出色,它们为自动化快速地构建图提供了令人兴奋的可能性,见下图。
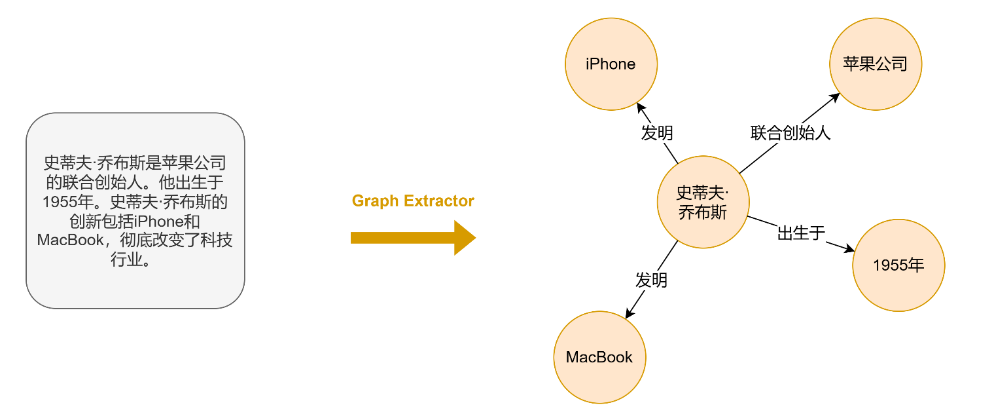
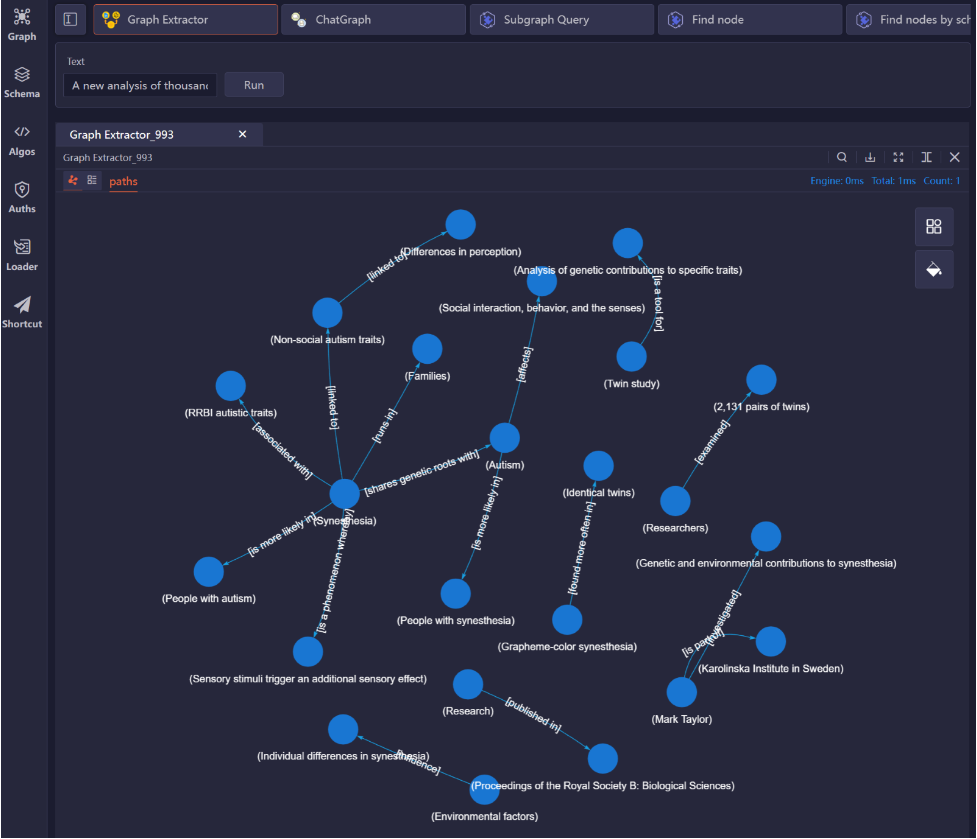
Graph Extractor是专为从用户输入文本中提取实体和关系信息并直接可视化为图而设计的插件,见下图。
我们输入了一篇关于联觉(Synesthesia)和自闭症(Autism)之间遗传联系的文章——《A Genetic Link Between Synesthesia And Autism Has Just Been Revealed》[2] 来测试它的性能。在检查结果时我们发现,大模型提取的信息大部分都是准确的,然而整个图尽管不大,却存在7个连通分量,这可能导致信息流断裂。例如,核心的发现“(联觉) - [共享遗传根源] -> (自闭症)”与相关的研究“(研究人员) - [检查] -> (2,131对双胞胎)”是隔离开的。
为了解决这个问题,或许我们可以对大模型进行一些标准实体和关系类型的微调或指导。例如,(@发现) - [@包含] -> (@现象),和(@研究) - [@支持] -> (@发现)。这种方法可以改善图的整体结构和可读性,确保相关信息得到适当的连接和呈现。
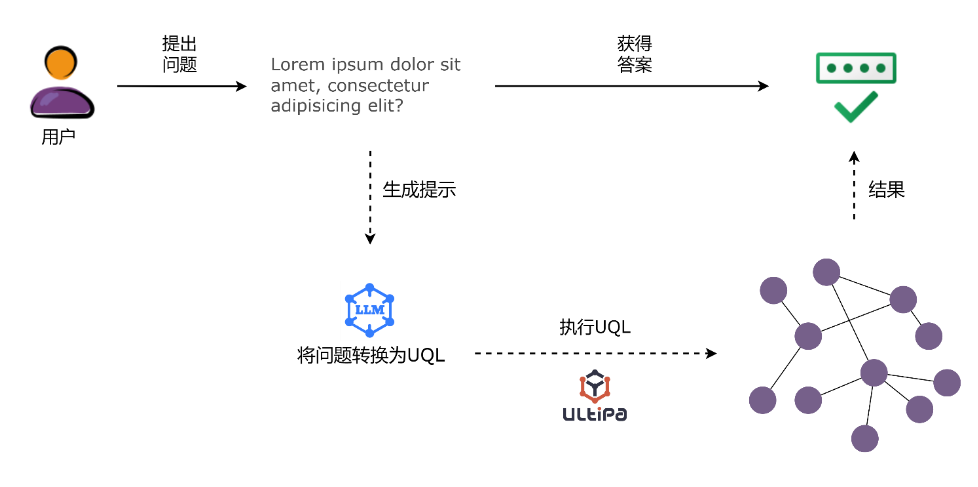
“图”上 问 答
图上问答旨在基于存储在图中的结构化事实来查找自然语言问题的答案。大模型能够充当自然语言问题与图数据之间的桥梁。
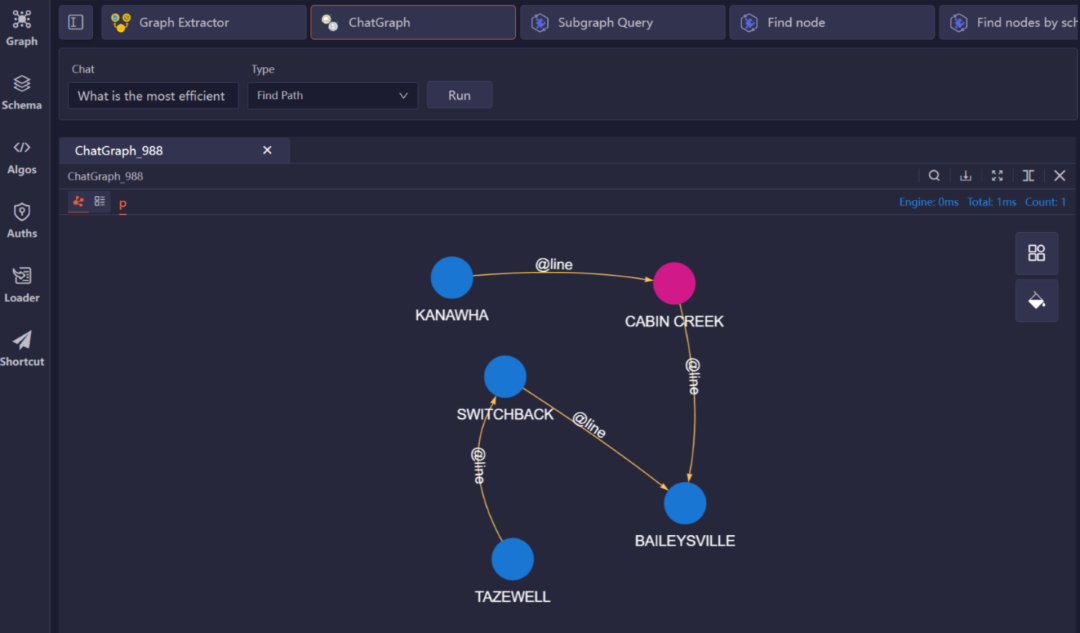
ChatGraph插件能帮助用户以对话的方式与图数据进行互动。鉴于大模型能够很好地理解自然语言,我们利用它从自然语言问题中提取信息,并将问题转化为准确的UQL(Ultipa图查询语言)语句。
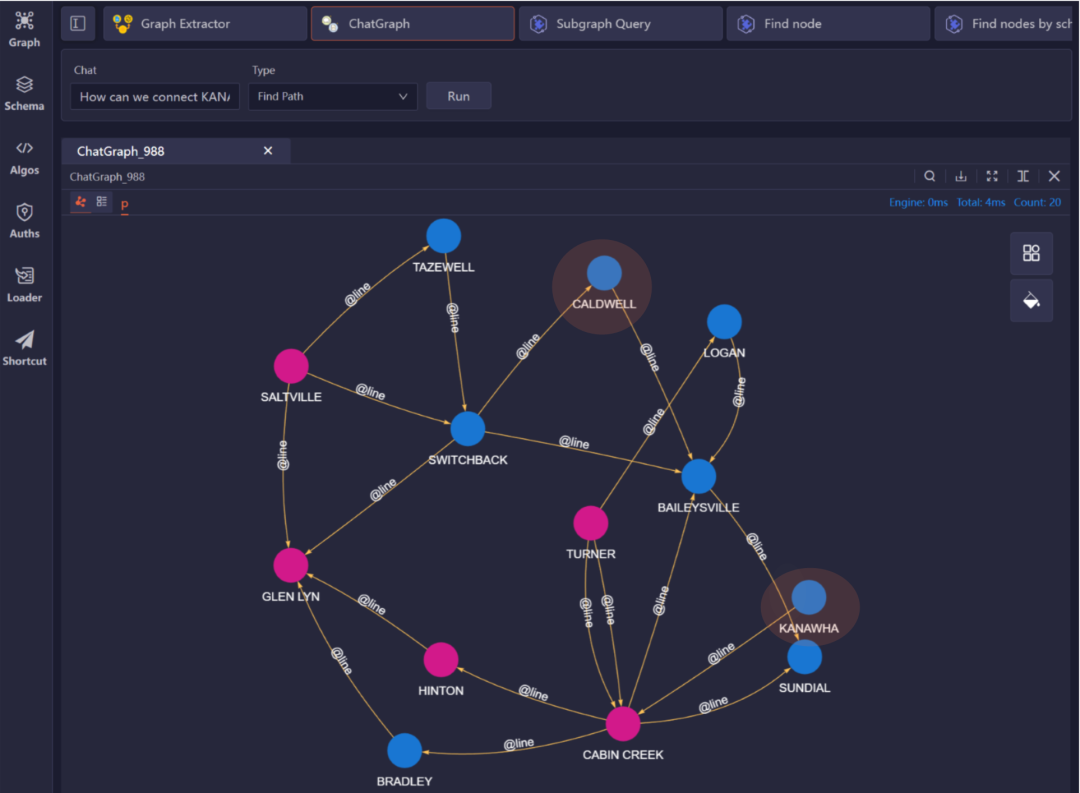
我们在一个电力网络中使用这个插件。我们输入问题:“如何能够连接KANAWHA和TAZEWELL这两个位置?”系统迅速使用AB路径查询[3]【详细阅读:Ultipa官网-文档-UQL-Query(查询)-Find paths(找路径)】检索了连接这两个位置的所有可行路径:
此外,我们提出另一个问题:“如何最有效率地从KANAWHA到TAZEWELL?” 系统识别这为最短路径问题,并迅速找到了该路径:
05 小结:展未来
在不断发展的信息技术领域,出现了两个强大的催化剂,从根本上改变了我们处理和分析数据的方法——大语言模型和图数据库。虽然大模型在理解和生成自然语言方面展示出了优秀的能力,但围绕它们的担忧和批评也使它们在严肃商业环境中的适用性蒙上了阴影。
图以显式、明确和结构化的方式表示知识,大模型和图之间的协同合作有望减轻大模型的种种限制。在未来,这两种技术的整合有望发挥强大的优势,创造更多的商业价值。 【文/ Pearl C 、Jason Z】

【1】图数据库; https://www.ultipa.cn/document/ultipa-graph-query-language/basic-concepts/v4.0
【2】https://www.sciencealert.com/a-genetic-link-between-synesthesia-and-autism-has-just-been-revealed.
【3】https://www.ultipa.com/document/ultipa-graph-query-language/a-to-b-path/v4.3