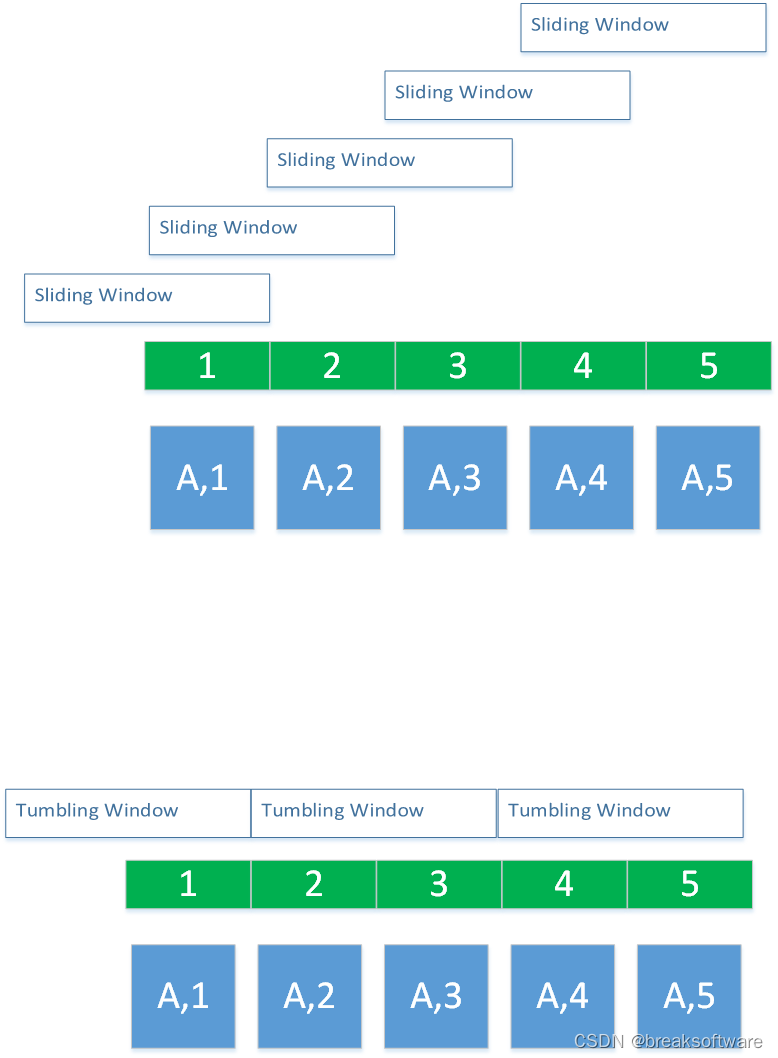
按照数据缺失机制,数据分析过程中,我们可以将其分为以下几类:
(1)完全随机缺失(MCAR):所缺失的数据发生的概率既与已观察到的数据无关,也与未观察到的数据无关。
(2)随机缺失(MAR):假设缺失数据发生的概率与所观察到的变量是有关的,而与未观察到的数据的特征是无关的。MCAR与MAR均被称为是可忽略的缺失形式。
(3)不可忽略的缺失(NIM):亦称为非随机缺失,即如果不完全变量中,数据的缺失既依赖于完全变量又依赖于不完全变量本身,这种缺失即为不可忽略的缺失。
那么,对于缺失值,我们应该如何处理呢?
对于缺失值的处理,从总体上来说分为删除存在缺失值的个案和缺失值插补。对于主观数据,人将影响数据的真实性,存在缺失值的样本的其他属性的真实值不能保证,那么依赖于这些属性值的插补也是不可靠的,所以对于主观数据一般不推荐插补的方法。插补主要是针对客观数据,它的可靠性有保证。
1)删除含有缺失值的个案
有简单删除法和权重法。简单删除法是对缺失值进行处理的最原始方法。它将存在缺失值的个案删除。如果数据缺失问题可以通过简单的删除小部分样本来达到目标,那么这个方法是最有效的。
当缺失值的类型为非完全随机缺失的时候,可以通过对完整的数据加权来减小偏差。把数据不完全的个案标记后,将完整的数据个案赋予不同的权重,个案的权重可以通过logistic或probit回归求得。
如果解释变量中存在对权重估计起决定行因素的变量,那么这种方法可以有效减小偏差。如果解释变量和权重并不相关,它并不能减小偏差。对于存在多个属性缺失的情况,就需要对不同属性的缺失组合赋不同的权重,这将大大增加计算的难度,降低预测的准确性,这时权重法并不理想。
2)可能值插补缺失值
它的思想来源是以最可能的值来插补缺失值比全部删除不完全样本所产生的信息丢失要少。在数据挖掘中,面对的通常是大型的数据库,它的属性有几十个甚至几百个,因为一个属性值的缺失而放弃大量的其他属性值,这种删除是对信息的极大浪费,所以产生了以可能值对缺失值进行插补的思想与方法。常用的有如下几种方法。
(1)均值插补。数据的属性分为定距型和非定距型。如果缺失值是定距型的,就以该属性存在值的平均值来插补缺失的值;如果缺失值是非定距型的,就根据统计学中的众数原理,用该属性的众数(即出现频率最高的值)来补齐缺失的值。
(2)利用同类均值插补。同均值插补的方法都属于单值插补,不同的是,它用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。假设X=(X1,X2…Xp)为信息完全的变量,Y为存在缺失值的变量,那么首先对X或其子集行聚类,然后按缺失个案所属类来插补不同类的均值。
如果在以后统计分析中还需以引入的解释变量和Y做分析,那么这种插补方法将在模型中引入自相关,给分析造成障碍。
(3)极大似然估计(ML)。在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。
这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(EM)。该方法比删除个案和单值插补更有吸引力,它一个重要前提:适用于大样本。有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
(4)多重插补(MI)。多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。多重插补方法分为三个步骤:
①为每个空值产生一套可能的插补值,这些值反映了无响应模型的不确定性;每个值都可以被用来插补数据集中的缺失值,产生若干个完整数据集合。
②每个插补数据集合都用针对完整数据集的统计方法进行统计分析;
③对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值。
假设一组数据,包括三个变量Y1,Y2,Y3,它们的联合分布为正态分布,将这组数据处理成三组,A组保持原始数据,B组仅缺失Y3,C组缺失Y1和Y2。在多值插补时,对A组将不进行任何处理,对B组产生Y3的一组估计值(作Y3关于Y1,Y2的回归),对C组作产生Y1和Y2的一组成对估计值(作Y1,Y2关于Y3的回归)。
当用多值插补时,对A组将不进行处理,对B、C组将完整的样本随机抽取形成为m组(m为可选择的m组插补值),每组个案数只要能够有效估计参数就可以了。对存在缺失值的属性的分布作出估计,然后基于这m组观测值,对于这m组样本分别产生关于参数的m组估计值,给出相应的预测即,这时采用的估计方法为极大似然法,在计算机中具体的实现算法为期望最大化法(EM)。对B组估计出一组Y3的值,对C将利用 Y1,Y2,Y3它们的联合分布为正态分布这一前提,估计出一组(Y1,Y2)。
上例中假定了Y1,Y2,Y3的联合分布为正态分布。这个假设是人为的,但是已经通过验证(Graham和Schafer于1999),非正态联合分布的变量,在这个假定下仍然可以估计到很接近真实值的结果。
多重插补和贝叶斯估计的思想是一致的,但是多重插补弥补了贝叶斯估计的几个不足。
(1)贝叶斯估计以极大似然的方法估计,极大似然的方法要求模型的形式必须准确,如果参数形式不正确,将得到错误得结论,即先验分布将影响后验分布的准确性。而多重插补所依据的是大样本渐近完整的数据的理论,在数据挖掘中的数据量都很大,先验分布将极小的影响结果,所以先验分布的对结果的影响不大。
(2)贝叶斯估计仅要求知道未知参数的先验分布,没有利用与参数的关系。而多重插补对参数的联合分布作出了估计,利用了参数间的相互关系。
以上四种插补方法,对于缺失值的类型为随机缺失的插补有很好的效果。两种均值插补方法是最容易实现的,也是以前人们经常使用的,但是它对样本存在极大的干扰,尤其是当插补后的值作为解释变量进行回归时,参数的估计值与真实值的偏差很大。
相比较而言,极大似然估计和多重插补是两种比较好的插补方法,与多重插补对比,极大似然缺少不确定成分,所以越来越多的人倾向于使用多重插补方法。
文章来源:网络 版权归原作者所有
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理