本文收录于【#云计算入门与实践 - AWS】专栏中,收录 AWS 入门与实践相关博文。
本文同步于个人公众号:【云计算洞察】
更多关于云计算技术内容敬请关注:CSDN【#云计算入门与实践 - AWS】专栏。
本系列已更新博文:
- [ 云计算 | AWS 实践 ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南
- [ 云计算 | AWS 实践 ] Java 如何重命名 Amazon S3 中的文件和文件夹
- [ 云计算 | AWS 实践 ] 使用 Java 列出存储桶中的所有 AWS S3 对象
文章目录
- 一、前言
- 二、前期准备
- 三、列出 S3 存储桶中的对象
- 四、使用延续标记进行分页
- 五、使用 ListObjectsV2Iterable 进行分页
- 六、使用前缀列出对象
- 七、文末总结
一、前言
在本文中,我们将重点介绍如何使用 Java 列出 S3 存储桶中的所有对象。我们将讨论如何使用适用于 Java 的 AWS 开发工具包与 S3 进行交互,并查看不同用例的示例。
重点是使用适用于 Java 的 AWS 开发工具包 V2,该开发工具包相对于之前的版本有多项改进,例如增强的性能、非阻塞 I/O 和用户友好的 API 设计。
二、前期准备
要列出 S3 存储桶中的所有对象,我们可以利用 AWS SDK for Java 提供的 S3Client 类。
首先,让我们创建一个新的 Java 项目并将以下 Maven 依赖项添加到 pom.xml 文件中:
<dependency><groupId>software.amazon.awssdk</groupId><artifactId>s3</artifactId><version>2.21.0</version>
</dependency>
对于本文中的示例,我们将使用版本 2.21.0。要查看最新版本,我们可以检查 Maven Repository。
我们还需要设置一个 AWS 账户,安装 AWS CLI ,并使用我们的 AWS 凭证( AWS_ACCESS_KEY_ID和AWS_SECERET_ACCESS_KEY )对其进行配置,以便能够以编程方式访问 AWS 资源。我们可以在AWS 文档中找到完成此操作的所有步骤。
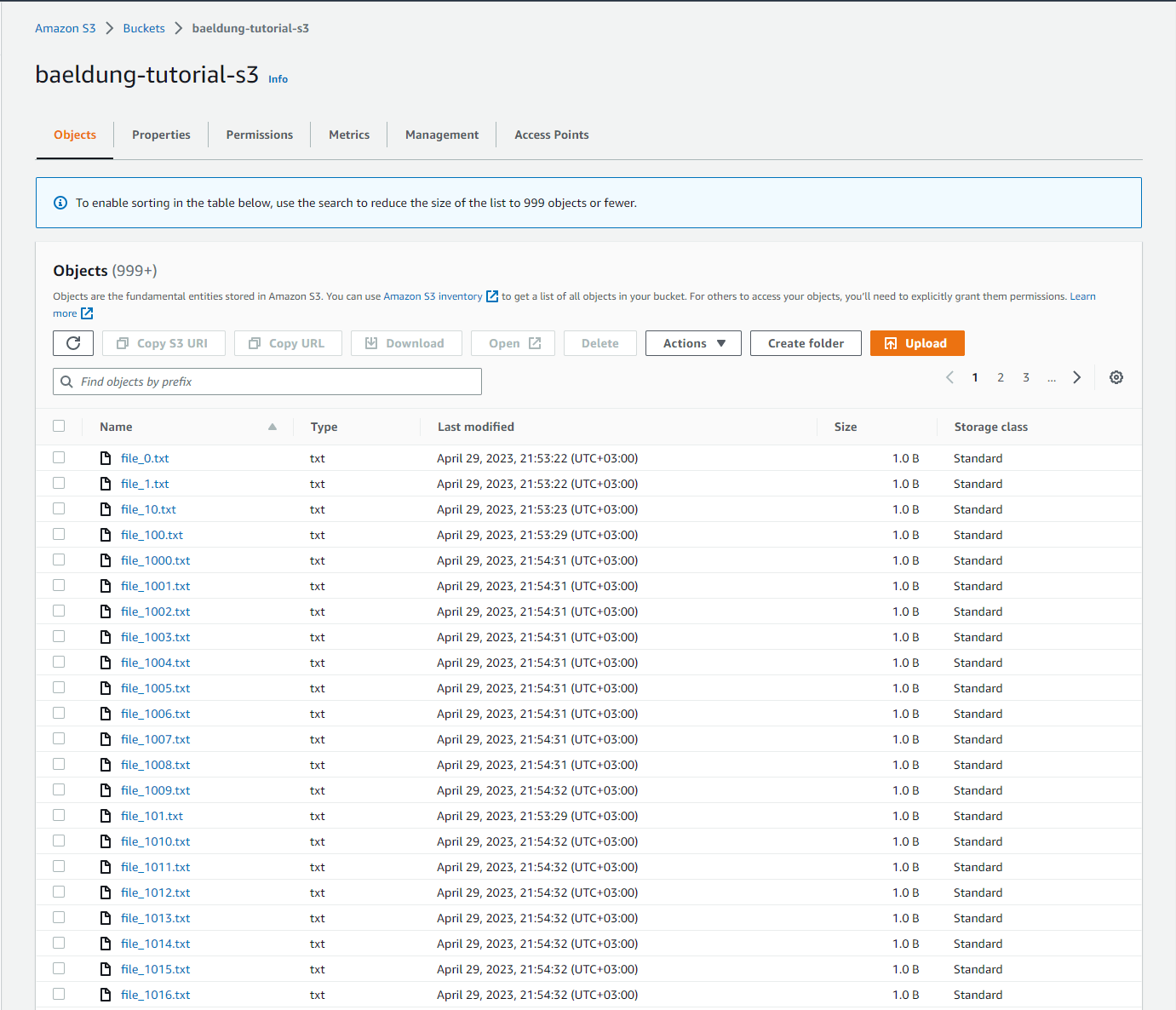
最后,我们需要创建一个 AWS S3 存储桶并上传一些文件。如下图所示,对于我们的示例,我们创建了一个名为 baeldung-tutorials-s3 的存储桶并向其中上传了一些测试文件:
三、列出 S3 存储桶中的对象
让我们使用适用于 Java V2 的 AWS 开发工具包并创建一个从存储桶读取对象的方法:
String AWS_BUCKET = "baeldung-tutorial-s3";
Region AWS_REGION = Region.EU_CENTRAL_1;
void listObjectsInBucket() {S3Client s3Client = S3Client.builder().region(AWS_REGION).build();ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder().bucket(AWS_BUCKET).build();ListObjectsV2Response listObjectsV2Response = s3Client.listObjectsV2(listObjectsV2Request);List<S3Object> contents = listObjectsV2Response.contents();System.out.println("Number of objects in the bucket: " + contents.stream().count());contents.stream().forEach(System.out::println);s3Client.close();
}
要列出 AWS S3 存储桶中的对象,我们首先需要创建一个ListObjectsV2Request实例,并指定存储桶名称。然后,我们在 s3Client 对象上调用 listObjectsV2 方法,并将请求作为参数传递。该方法返回一个 ListObjectsV2Response,其中包含桶中对象的信息。
最后,我们使用contents()方法访问 S3 对象列表并将检索到的对象数量写入作为输出。我们还为存储桶名称和相应的 AWS 区域定义了两个静态属性。
执行该方法后,我们得到以下结果:
Number of objects in the bucket: 1000
S3Object(Key=file_0.txt, LastModified=2023-11-01T11:35:06Z, ETag="b9ece18c950afbfa6b0fdbfa4ff731d3", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1.txt, LastModified=2023-11-01T11:35:07Z, ETag="97a6dd4c45b23db9c5d603ce161b8cab", Size=1, StorageClass=STANDARD)
S3Object(Key=file_10.txt, LastModified=2023-11-01T11:35:07Z, ETag="3406877694691ddd1dfb0aca54681407", Size=1, StorageClass=STANDARD)
S3Object(Key=file_100.txt, LastModified=2023-11-01T11:35:15Z, ETag="b99834bc19bbad24580b3adfa04fb947", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1000.txt, LastModified=2023-08-01T18:54:31Z, ETag="47ed733b8d10be225eceba344d533586", Size=1, StorageClass=STANDARD)
[...]
正如我们所看到的,我们并没有得到所有上传的对象。
值得注意的是,该解决方案设计为仅返回最多 1000 个对象。如果存储桶包含超过 1000 个对象,我们必须使用ListObjectsV2Response对象中的nextContinuationToken()方法实现分页。
四、使用延续标记进行分页
如果我们的 AWS S3 存储桶包含超过 1000 个对象,我们需要使用nextContinuationToken()方法实现分页。
让我们看一个示例,演示如何处理这种情况:
void listAllObjectsInBucket() {S3Client s3Client = S3Client.builder().region(AWS_REGION).build();String nextContinuationToken = null;long totalObjects = 0;do {ListObjectsV2Request.Builder requestBuilder = ListObjectsV2Request.builder().bucket(AWS_BUCKET).continuationToken(nextContinuationToken);ListObjectsV2Response response = s3Client.listObjectsV2(requestBuilder.build());nextContinuationToken = response.nextContinuationToken();totalObjects += response.contents().stream().peek(System.out::println).reduce(0, (subtotal, element) -> subtotal + 1, Integer::sum);} while (nextContinuationToken != null);System.out.println("Number of objects in the bucket: " + totalObjects);s3Client.close();
}
在这里,我们使用do-while循环对存储桶中的所有对象进行分页。循环继续,直到不再有继续标记,这表明我们检索了所有对象。
因此,我们得到以下输出:
Number of objects in the bucket: 1060
使用这种方法,我们显式地管理分页。我们检查是否存在继续令牌并在以下请求中使用它。这使我们能够完全控制何时以及如何请求下一页。它允许在处理分页过程时具有更大的灵活性。
默认情况下,响应中返回的最大对象数为 1000。它可能包含更少的键,但永远不会包含更多。我们可以通过ListObjectsV2Reqeust的 maxKeys()方法更改此设置。
五、使用 ListObjectsV2Iterable 进行分页
我们可以使用 AWS SDK 通过 ListObjectsV2Iterable 类和 listObjectsV2Paginator()方法来处理分页。这简化了代码,因为我们不需要手动管理分页过程。这使得代码更加简洁和可读,从而更容易维护。
实现的代码如下:
void listAllObjectsInBucketPaginated(int pageSize) {S3Client s3Client = S3Client.builder().region(AWS_REGION).build();ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder().bucket(AWS_BUCKET ).maxKeys(pageSize) // Set the maxKeys parameter to control the page size.build();ListObjectsV2Iterable listObjectsV2Iterable = s3Client.listObjectsV2Paginator(listObjectsV2Request);long totalObjects = 0;for (ListObjectsV2Response page : listObjectsV2Iterable) {long retrievedPageSize = page.contents().stream().peek(System.out::println).reduce(0, (subtotal, element) -> subtotal + 1, Integer::sum);totalObjects += retrievedPageSize;System.out.println("Page size: " + retrievedPageSize);}System.out.println("Total objects in the bucket: " + totalObjects);s3Client.close()
}
这是当我们调用 pageSize 为 500 的方法时得到的输出:
S3Object(Key=file_0.txt, LastModified=2023-08-01T11:35:06Z, ETag="b9ece18c950afbfa6b0fdbfa4ff731d3", Size=1, StorageClass=STANDARD)
S3Object(Key=file_1.txt, LastModified=2023-08-01T11:35:07Z, ETag="97a6dd4c45b23db9c5d603ce161b8cab", Size=1, StorageClass=STANDARD)
S3Object(Key=file_10.txt, LastModified=2023-08-01T11:35:07Z, ETag="3406877694691ddd1dfb0aca54681407", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_494.txt, LastModified=2023-11-01T18:53:56Z, ETag="69b7a7308ee1b065aa308e63c44ae0f3", Size=1, StorageClass=STANDARD)
Page size: 500
S3Object(Key=file_495.txt, LastModified=2023-11-01T18:53:57Z, ETag="83acb6e67e50e31db6ed341dd2de1595", Size=1, StorageClass=STANDARD)
S3Object(Key=file_496.txt, LastModified=2023-11-01T18:53:57Z, ETag="3beb9cf0eab8cbf2215990b4a6bdc271", Size=1, StorageClass=STANDARD)
S3Object(Key=file_497.txt, LastModified=2023-11-01T18:53:57Z, ETag="69691c7bdcc3ce6d5d8a1361f22d04ac", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_944.txt, LastModified=2023-11-01T18:54:27Z, ETag="f623e75af30e62bbd73d6df5b50bb7b5", Size=1, StorageClass=STANDARD)
Page size: 500
S3Object(Key=file_945.txt, LastModified=2023-11-01T18:54:27Z, ETag="55a54008ad1ba589aa210d2629c1df41", Size=1, StorageClass=STANDARD)
S3Object(Key=file_946.txt, LastModified=2023-11-01T18:54:27Z, ETag="ade7a0dcf4ddc0673ed48b70a4a340d6", Size=1, StorageClass=STANDARD)
S3Object(Key=file_947.txt, LastModified=2023-11-01T18:54:27Z, ETag="0a476d83ef9cef4bce7f9025522be3b5", Size=1, StorageClass=STANDARD)
[..]
S3Object(Key=file_999.txt, LastModified=2023-11-01T18:54:31Z, ETag="5e732a1878be2342dbfeff5fe3ca5aa3", Size=1, StorageClass=STANDARD)
Page size: 60
Total objects in the bucket: 1060
当我们在 for 循环中迭代页面时,AWS 开发工具包通过检索下一页来延迟分页。仅当我们到达当前页面的末尾时,它才会获取下一页,这意味着页面是按需加载的,而不是一次性加载的。
六、使用前缀列出对象
在某些情况下,我们只想列出具有公共前缀的对象,例如,所有以backup开头的对象。
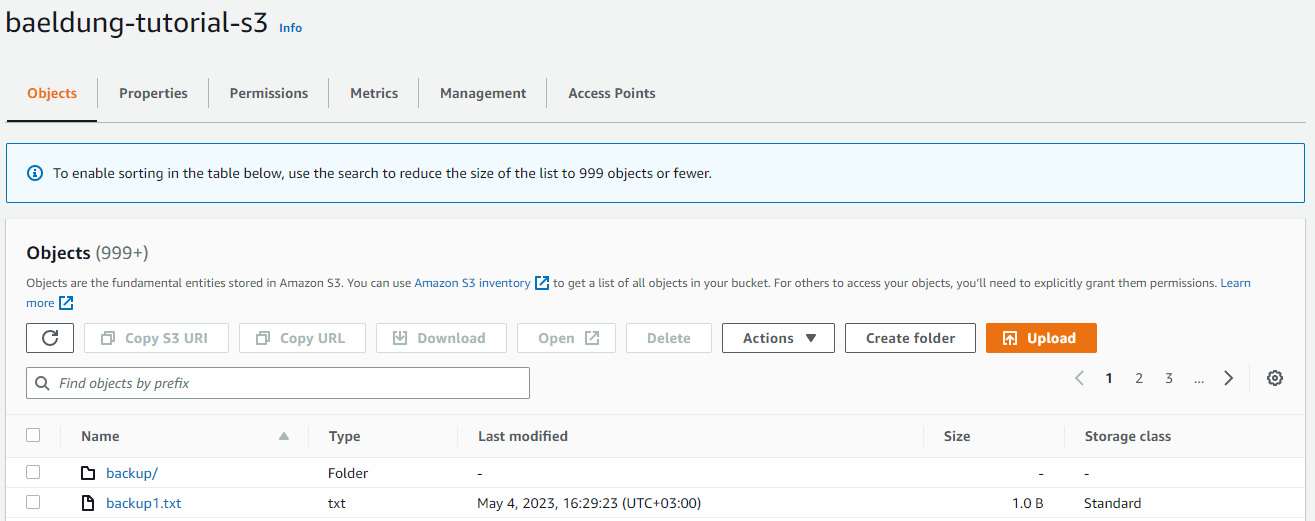
为了展示此用例,我们将名为 backup1.txt 的文件上传到存储桶,创建一个名为 backup 的文件夹并将六个文件移入其中。该存储桶现在总共包含七个对象。
这就是我们的存储桶的样子,图下图:
接下来更改函数以仅返回具有公共前缀的对象:
void listAllObjectsInBucketPaginatedWithPrefix(int pageSize, String prefix) {S3Client s3Client = S3Client.builder().region(AWS_REGION).build();ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder().bucket(AWS_BUCKET).maxKeys(pageSize) // Set the maxKeys parameter to control the page size.prefix(prefix) // Set the prefix.build();ListObjectsV2Iterable listObjectsV2Iterable = s3Client.listObjectsV2Paginator(listObjectsV2Request);long totalObjects = 0;for (ListObjectsV2Response page : listObjectsV2Iterable) {long retrievedPageSize = page.contents().stream().count();totalObjects += retrievedPageSize;System.out.println("Page size: " + retrievedPageSize);}System.out.println("Total objects in the bucket: " + totalObjects);s3Client.close();
}
我们只需调用 ListObjectsV2Request 上的 前缀方法即可。如果我们调用前缀参数设置为backup的函数,它将统计存储桶中以backup开头的所有对象。
“backup1.txt” 和 “backup/file1.txt” 这两个键都将匹配:
listAllObjectsInBucketPaginatedWithPrefix(10, "backup");
这是我们返回的结果:
S3Object(Key=backup/, LastModified=2023-11-01T17:47:33Z, ETag="d41d8cd98f00b204e9800998ecf8427e", Size=0, StorageClass=STANDARD)
S3Object(Key=backup/file_0.txt, LastModified=2023-11-01T17:48:13Z, ETag="a87ff679a2f3e71d9181a67b7542122c", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_1.txt, LastModified=2023-11-01T17:48:13Z, ETag="9eecb7db59d16c80417c72d1e1f4fbf1", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_2.txt, LastModified=2023-11-01T17:48:13Z, ETag="800618943025315f869e4e1f09471012", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_3.txt, LastModified=2023-11-01T17:48:13Z, ETag="8666683506aacd900bbd5a74ac4edf68", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_4.txt, LastModified=2023-11-01T17:49:05Z, ETag="f95b70fdc3088560732a5ac135644506", Size=1, StorageClass=STANDARD)
S3Object(Key=backup1.txt, LastModified=2023-05-04T13:29:23Z, ETag="ec631d7335abecd318f09f56515ed63c", Size=1, StorageClass=STANDARD)
Page size: 7
Total objects in the bucket: 7
如果我们不想统计桶正下方的对象,我们需要在前缀后面添加一个斜杠:
listAllObjectsInBucketPaginatedWithPrefix(10, "backup/");
现在我们只获取bucket/文件夹中的对象:
S3Object(Key=backup/, LastModified=2023-11-01T17:47:33Z, ETag="d41d8cd98f00b204e9800998ecf8427e", Size=0, StorageClass=STANDARD)
S3Object(Key=backup/file_0.txt, LastModified=2023-11-01T17:48:13Z, ETag="a87ff679a2f3e71d9181a67b7542122c", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_1.txt, LastModified=2023-11-01T17:48:13Z, ETag="9eecb7db59d16c80417c72d1e1f4fbf1", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_2.txt, LastModified=2023-11-01T17:48:13Z, ETag="800618943025315f869e4e1f09471012", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_3.txt, LastModified=2023-11-01T17:48:13Z, ETag="8666683506aacd900bbd5a74ac4edf68", Size=1, StorageClass=STANDARD)
S3Object(Key=backup/file_4.txt, LastModified=2023-11-01T17:49:05Z, ETag="f95b70fdc3088560732a5ac135644506", Size=1, StorageClass=STANDARD)
Page size: 6
Total objects in the bucket: 6
七、文末总结
本文介绍了如何在 AWS S3 存储桶中列出对象的不同方法,包括使用延续标记进行分页、使用 ListObjectsV2Iterable 进行分页以及使用前缀进行对象的列出。通过这些方法,你可以更有效地管理 S3 存储桶中的对象,实现更高效的数据检索和管理。前期准备和基础知识也在文章中提到,帮助读者更好地理解和运用这些方法。希望这些信息对您在 AWS S3 存储桶中的对象管理工作中有所帮助。
[ 本文作者 ] bluetata
[ 原文链接 ] https://bluetata.blog.csdn.net/article/details/134174962
[ 最后更新 ] 11/01/2023 2:31
[ 版权声明 ] 如果您在非 CSDN 网站内看到这一行,
说明网络爬虫可能在本人还没有完整发布的时候就抓走了我的文章,
可能导致内容不完整,请去上述的原文链接查看原文。