Mysql实战-Join驱动表和被驱动表如何区分
前面我们讲解了Mysql的查询连接Join的算法原理, 我发现大家都知道小表驱动大表,要让小表作为驱动表, 现在有2个问题
- 查询多表, 到底哪个是驱动表?哪个是被驱动表, 如何区分?
- 索引如何优化,到底是加在驱动表上,还是被驱动表上? (答案是被驱动表!!!)
今天我们来讨论下这两个问题的答案
文章目录
- Mysql实战-Join驱动表和被驱动表如何区分
- 1.什么是驱动表和被驱动表?
- 2.Explain命令区分 驱动表及被驱动表
- 3. left join 左表可能不是驱动表
- 4. left join 没where 查询 驱动表, 左表才是驱动表
- 4. left join where 查询条件的表就是驱动表的错误说法
- 5.left join where查询驱动表判断
1.什么是驱动表和被驱动表?
在join连接查询中,驱动表在SQL语句执行的过程中总是先被读取。而被驱动表在SQL语句执行的过程中总是后被读取。
在读取驱动表数据后,放入到join_buffer后,再去读取被驱动表中的数据来和驱动表中的数据进行匹配。如果匹配成功,就返回结果,否则该丢弃, 继续匹配下一条
为什么要小表驱动大表?
从上面的查询过程中,我们就知道了 , 因为小表查的少, 大大的减少了I/O 次数, join_buffer容量也有限, 表越小, 越少次数匹配, 越容易查结果,所以 我们必须区分 哪个是驱动表, 哪个是被驱动表
现在我们先创建2个表结构, 插入数据,作为测试数据
drop table user_info;
CREATE TABLE `user_info` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户名',`age` int(10) DEFAULT NULL COMMENT '员工年龄',`address` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '用户地址',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表';drop table order_info;
CREATE TABLE `order_info` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`order_id` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '订单id',`user_id` bigint(20) NOT NULL COMMENT '用户user表主键id',
`goods` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '商品',
`production` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '产地',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='订单表'INSERT INTO `order_info` (order_id, user_id, goods, production) VALUES (CONCAT("uuid",1), 2, "衣服", "上海贸易");#插入3条用户数据
INSERT INTO `user_info` (user_name, age, address) VALUES ("张三", 10, "北京");
INSERT INTO `user_info` (user_name, age, address) VALUES ("李四", 20, "上海");
INSERT INTO `user_info` (user_name, age, address) VALUES ("王五", 30, "广州");#插入2条 张三的 订单记录
INSERT INTO `order_info` (order_id, user_id, goods, production) VALUES ("uuid1", 1, "衣服", "北京三里屯");
INSERT INTO `order_info` (order_id, user_id, goods, production) VALUES ("uuid2", 1, "鞋子", "北京三里屯");
#插入1w条 李四的订单记录, 用存储过程执行#先创建存储过程
CREATE PROCEDURE test() #创建存储函数;
BEGIN
DECLARE i INT DEFAULT 100;WHILE i < 10100 DOINSERT INTO `order_info` (order_id, user_id, goods, production) VALUES (CONCAT("uuid",i), 2, "书本", "上海贸易");SET i = i+1;
end WHILE;END;
#然后执行 存储过程
CALL test();#调用存储函数
我们可以看下数据是否插入成功
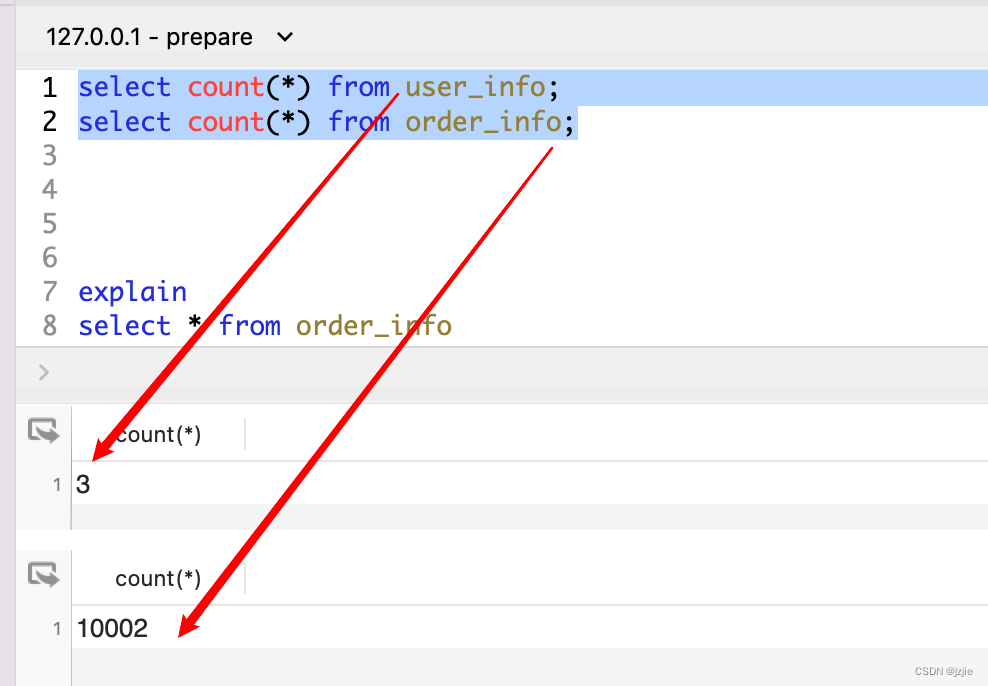
user_info 3条数据
order_info 10002条数据
2.Explain命令区分 驱动表及被驱动表
对于已有的SQL语句,我们可以直接通过Explain 命令来判断 驱动表与被驱动表, explain命令查看一下SQL语句的执行计划。
输出的执行计划中,首先出现的排在第一行的表是驱动表,排在第二行的表是被驱动表,比如下面的语句
#查看驱动表 第一行就是驱动表
explain
select * from user_info
left join order_info
on user_info.id = order_info.user_id;
查看执行结果
- 第一行 user_info表 ,所以驱动表是 user_info
- 第二行 order_info表, 被驱动表示 order_info
- 此刻都没有索引信息, type=ALL
- 即使双方连接字段是 id~user_id, user_info表的id是主键, user_info表也没有走索引
- 所以驱动表有索引, 也不一定走
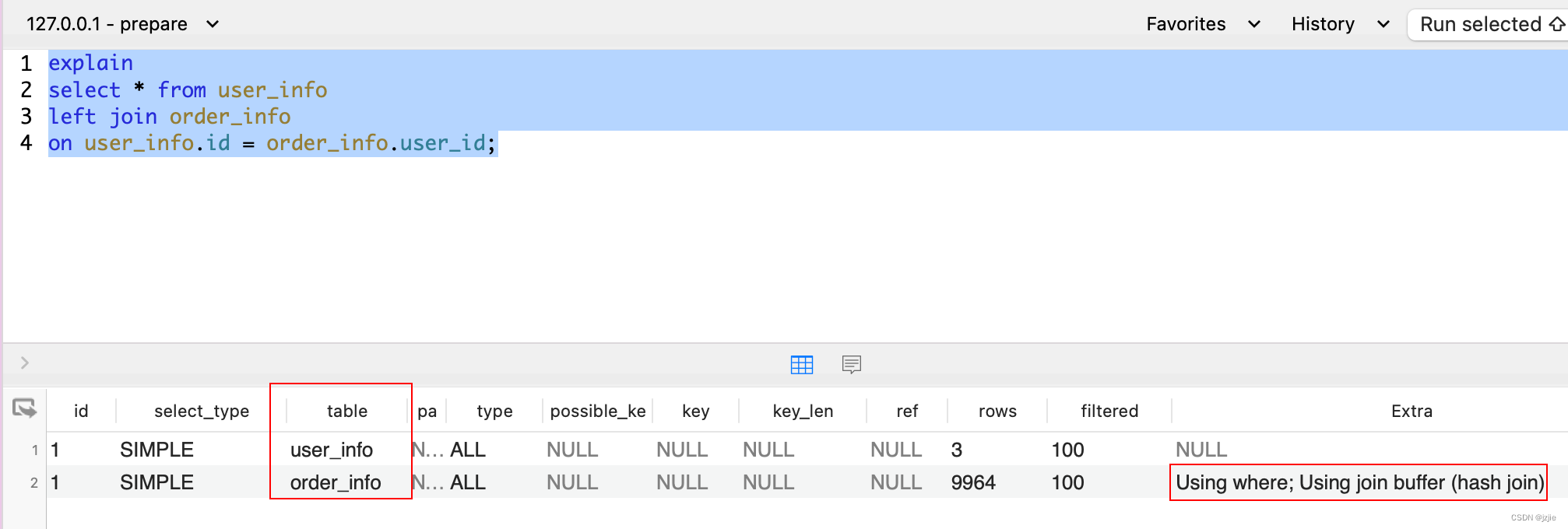
这里虽然左表示 user_info 是驱动表, 而且是 left_join 查询, 那么我们可以得出结论 left join 左表一定是驱动表么 ?
不能, 重要事情说三遍
!!! left join 左表 不一定是驱动表
!!! left join 左表 不一定是驱动表
!!! left join 左表 不一定是驱动表
3. left join 左表可能不是驱动表
下面我们来验证下 left join 左表不是驱动表的逻辑
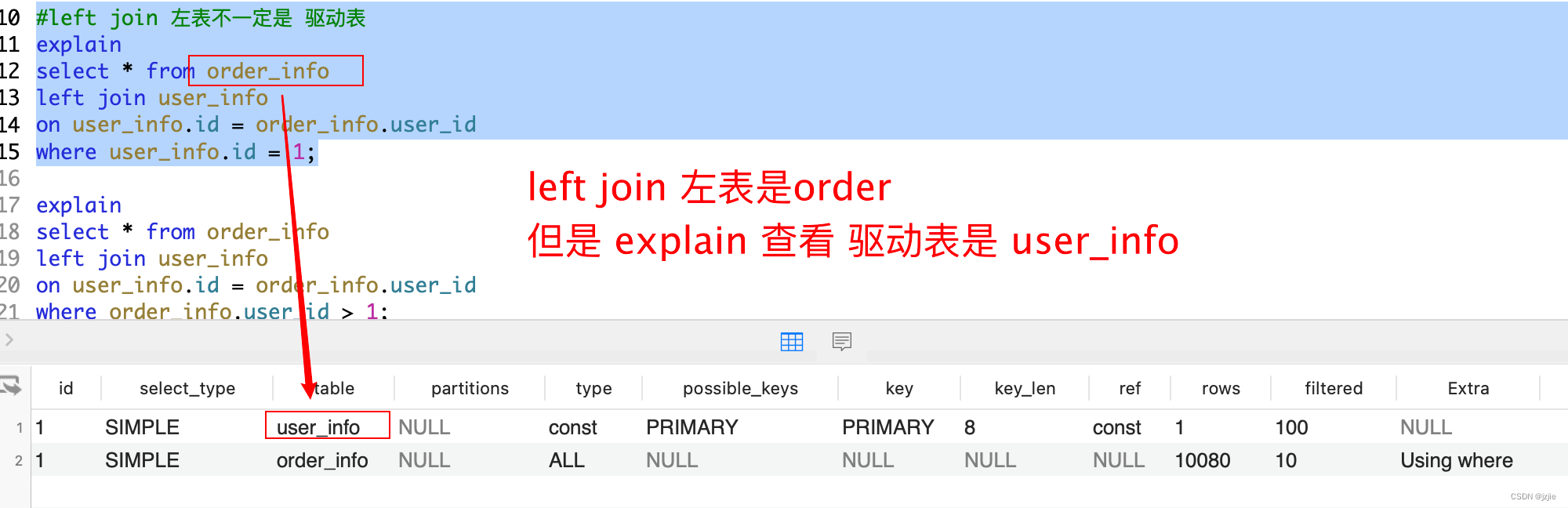
我们看下 下面的 查询语句, 也是用 left join 查询, 可以看到 左表是 order left join user_info
那么我们看下 explain 到底哪个是驱动表
#left join 左表不一定是 驱动表
explain
select * from order_info
left join user_info
on user_info.id = order_info.user_id
where user_info.id = 1;
执行结果
- left join 左表是 order_info
- 但是 驱动表是user_info
- 所以 并不是 left_join 左表就是驱动表
- 同理 right_join 右表也不一定是驱动表
那么 什么情况下? left join 左表示驱动表呢?
4. left join 没where 查询 驱动表, 左表才是驱动表
当SQL查询语句没有 where 查询条件时
- 没有 where 查询条件时 left join 左表是驱动表, 右表是被驱动表
- 没有 where 查询条件时 right join 右表是驱动表, 左表示被驱动表
- 没有 where 查询条件时 inner join 也就是join, mysql自动选择 小表作为驱动表, 大表作为被驱动表,进行底层优化
先说结论, 下面我们验证下这个逻辑
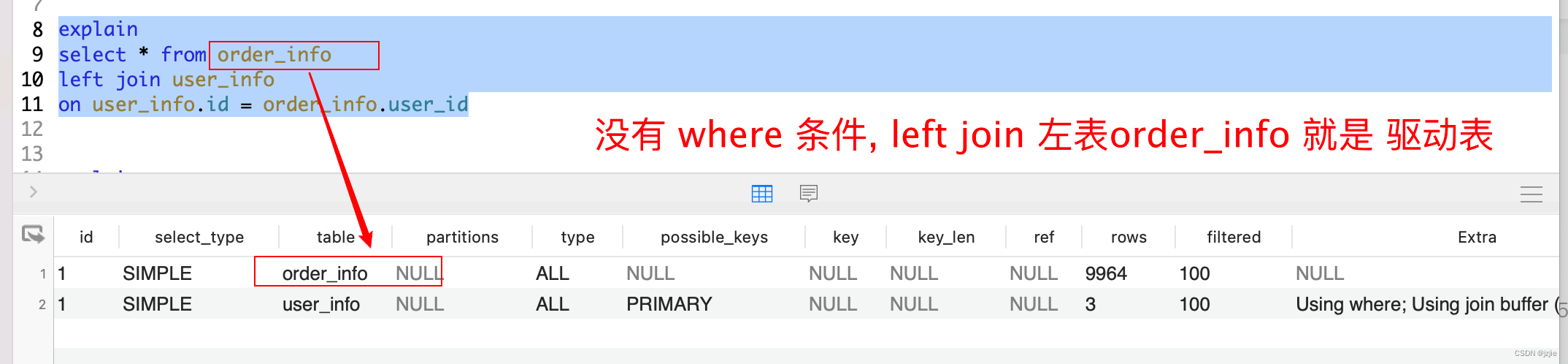
- 没有 where 查询条件时 left join 左表是order_info, explain 驱动表就是 order_info
- 没有 where 查询条件时 left join 左表示驱动表, 不管查询表位置如何交换
- 没有 where 查询条件时 join查询, 不管 左右表顺序, mysql自己优化选择小表作为驱动表
1.没有 where 查询条件时 left join 左表是order_info, explain 驱动表就是 order_info
#没where 查询 左表才是驱动表, 左表是order
explain
select * from order_info
left join user_info
on user_info.id = order_info.user_id
执行结果, 符合预期
换下位置,看看是否 依旧如此
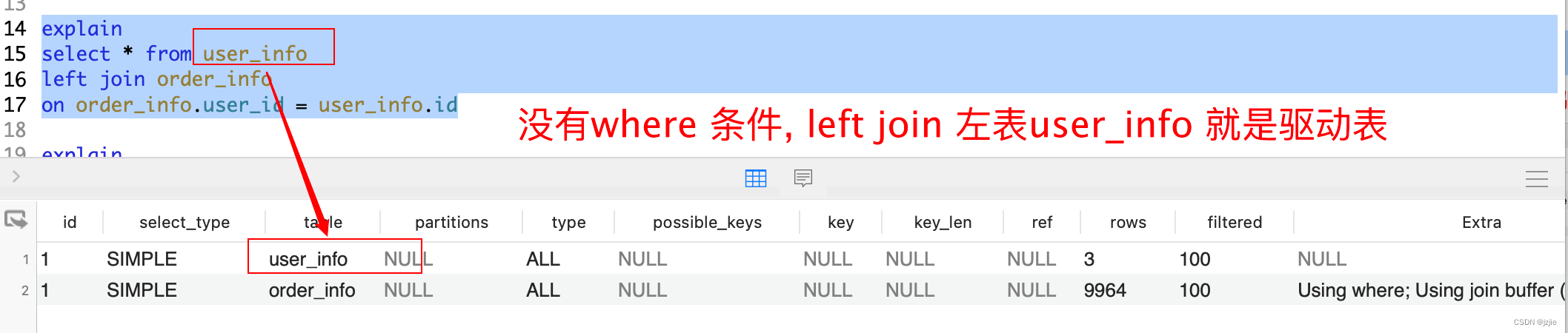
2.没有 where 查询条件时 left join 左表是user_info, explain 驱动表就是 user_info
#没where 查询 左表才是驱动表, 换位置 左表是userexplain
select * from user_info
left join order_info
on order_info.user_id = user_info.id
执行结果, 符合预期
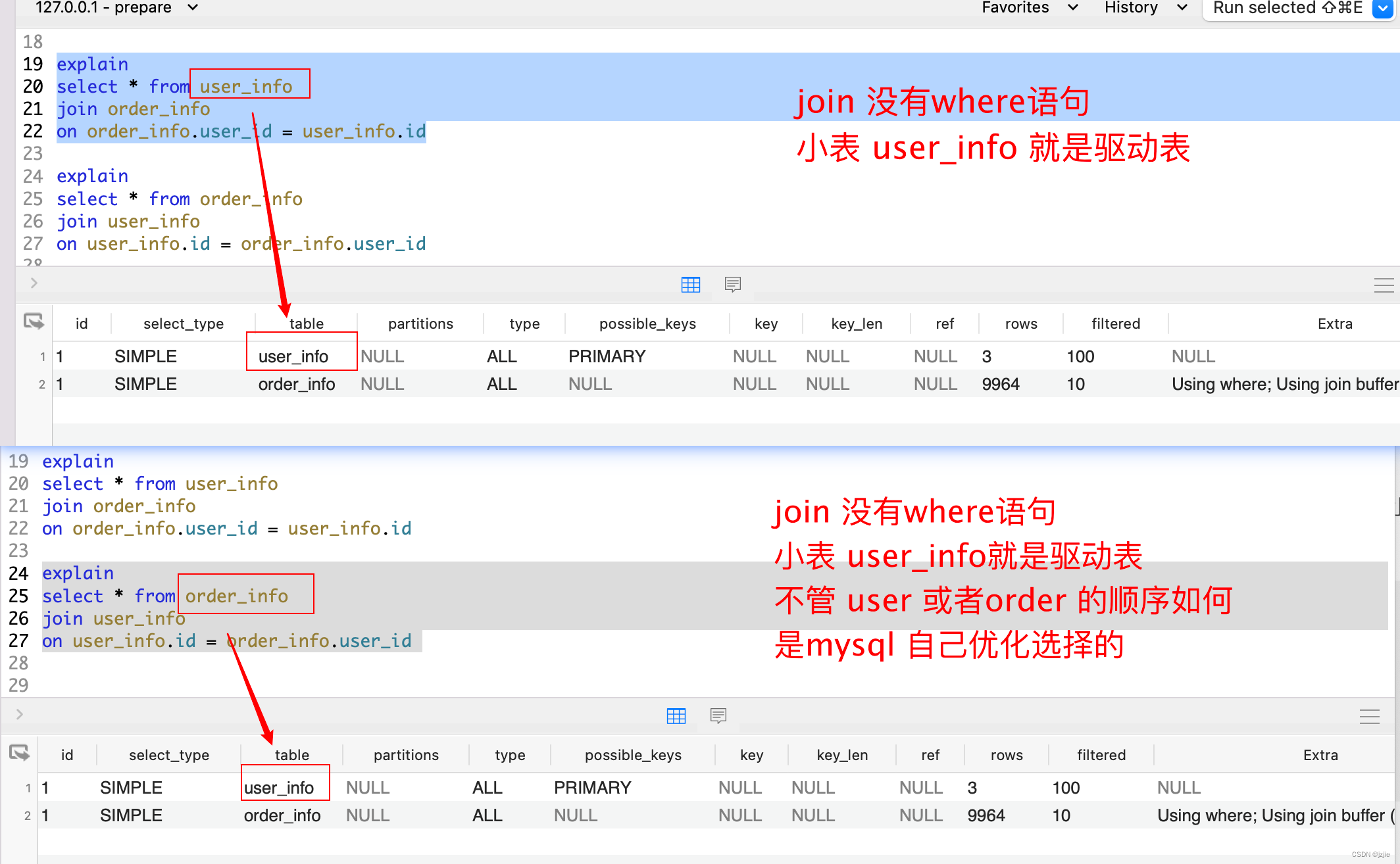
3.没有 where 查询条件时 , 不管 左右表顺序, join 驱动表是mysql自己优化选择的,小表 user_info就是驱动表, user_info 3条数据, order_info 1w多条数据
#join查询, mysql选择小表作为驱动表explain
select * from user_info
left join order_info
on order_info.user_id = user_info.id#join'查询, 换下 user_info 和 order_info 的位置
explain
select * from order_info
join user_info
on user_info.id = order_info.user_id
user_info不论左侧右侧, 都是小表作为驱动表
执行结果 符合预期
4. left join where 查询条件的表就是驱动表的错误说法
有where 查询语句时, 驱动表的判断规则是另一种情况
有一种 说法 where查询中只有一个表结构, 那么该表就是驱动表 ?
这种说法是错误的,重要事情说三遍
!!! 有where查询的, where条件的表 就是驱动表 这是错误的
!!! 有where查询的, where条件的表 就是驱动表 这是错误的
!!! 有where查询的, where条件的表 就是驱动表 这是错误的
#带where 查询表, where的表 不是驱动表, 验证错误语法
explain
select * from user_info
left join order_info
on user_info.id = order_info.user_id
where order_info.user_id = 1;
这是有where 查询条件的, 而且where查询中只有一个表 order_info, 我们来执行下 explain
执行结果, 有where查询条件, order_info,但是 explain的驱动表是 user_info表

所以上面的说法是靠不住的
5.left join where查询驱动表判断
上面我们验证了 where 查询表就是驱动表这种说法的错误性, 那么 带where查询条件到底哪个是驱动表呢?
我们先说结论,然后验证,结论如下
- where 查询字段没索引, 那就是谁是左表,用谁
- where 查询字段有索引, 那就用where表作为驱动表
1.where 查询表字段没索引, 谁是左表,用谁做驱动表
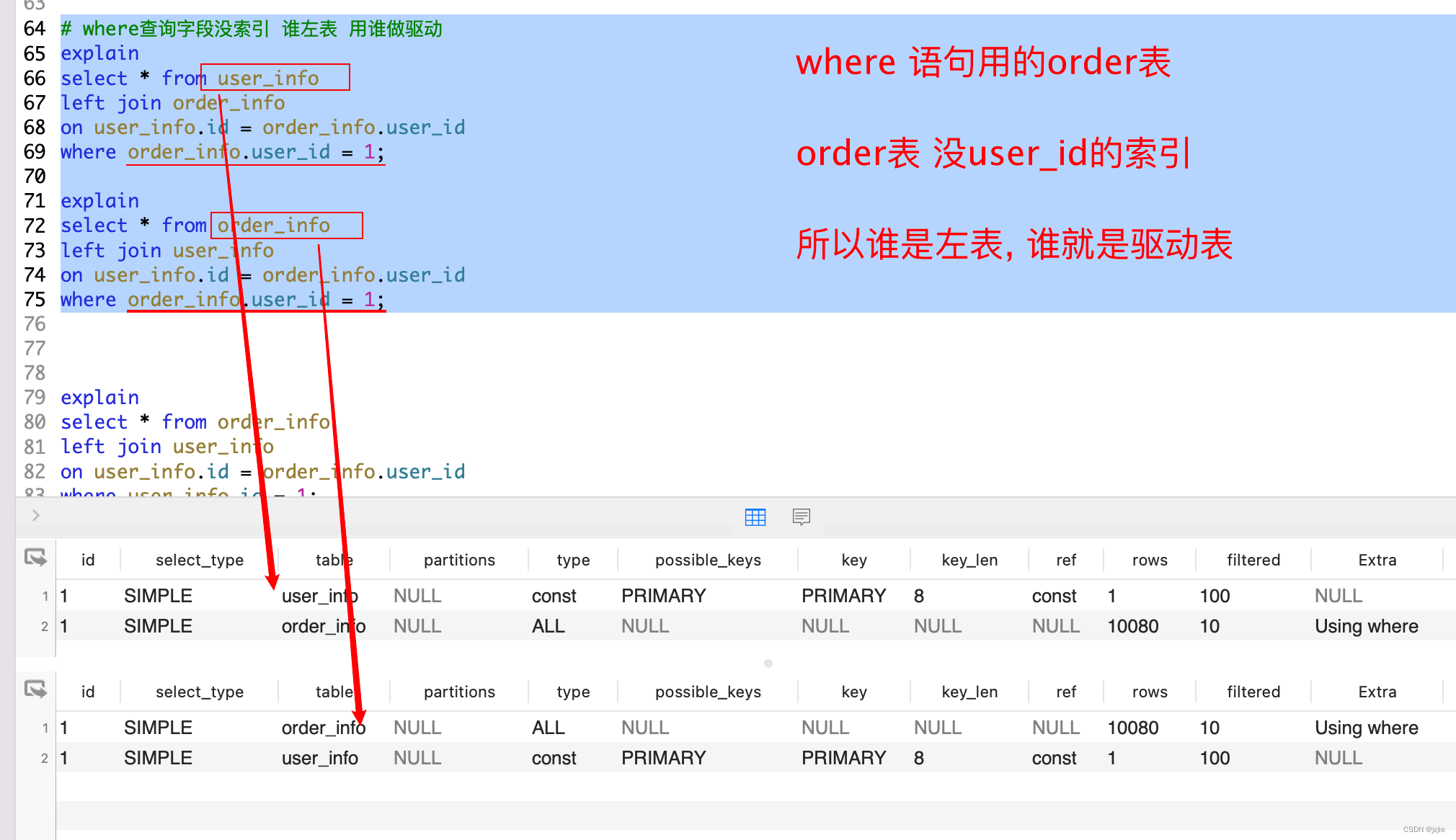
2.where 查询字段有索引, 那就用where表作为驱动表

到这里 我们已经了解了 join 语法驱动表及被驱动表的判断,现在回答下开始的问题
- 1.查询多表, 到底哪个是驱动表?哪个是被驱动表, 如何区分?
- 不同的查询语句对应不同的驱动表划分策略,比如没有where的查询,left join的查询,带where的查询,inner join的查询,及查询字段 都会影响驱动表的选择
- 2.索引如何优化,到底是加在驱动表上,还是被驱动表上?
- 我们直到查询要小表驱动大表, 对于小表驱动表来说 无论建立没建立索引,都需要全表扫描的
- 所以我们要把索引建立再大表上, 也就是说 索引要建立在 被驱动表上
- 如果大表在连接字段上建立了索引,就可以走索引,尽快的匹配出想要的数据
至此, 我们已经了解了 join 语法驱动表及被驱动表的判断,这对于我们进行SQL优化至关重要, 只有知道了被驱动表,我们才能进行针对索引进行优化,磨刀不误砍柴工