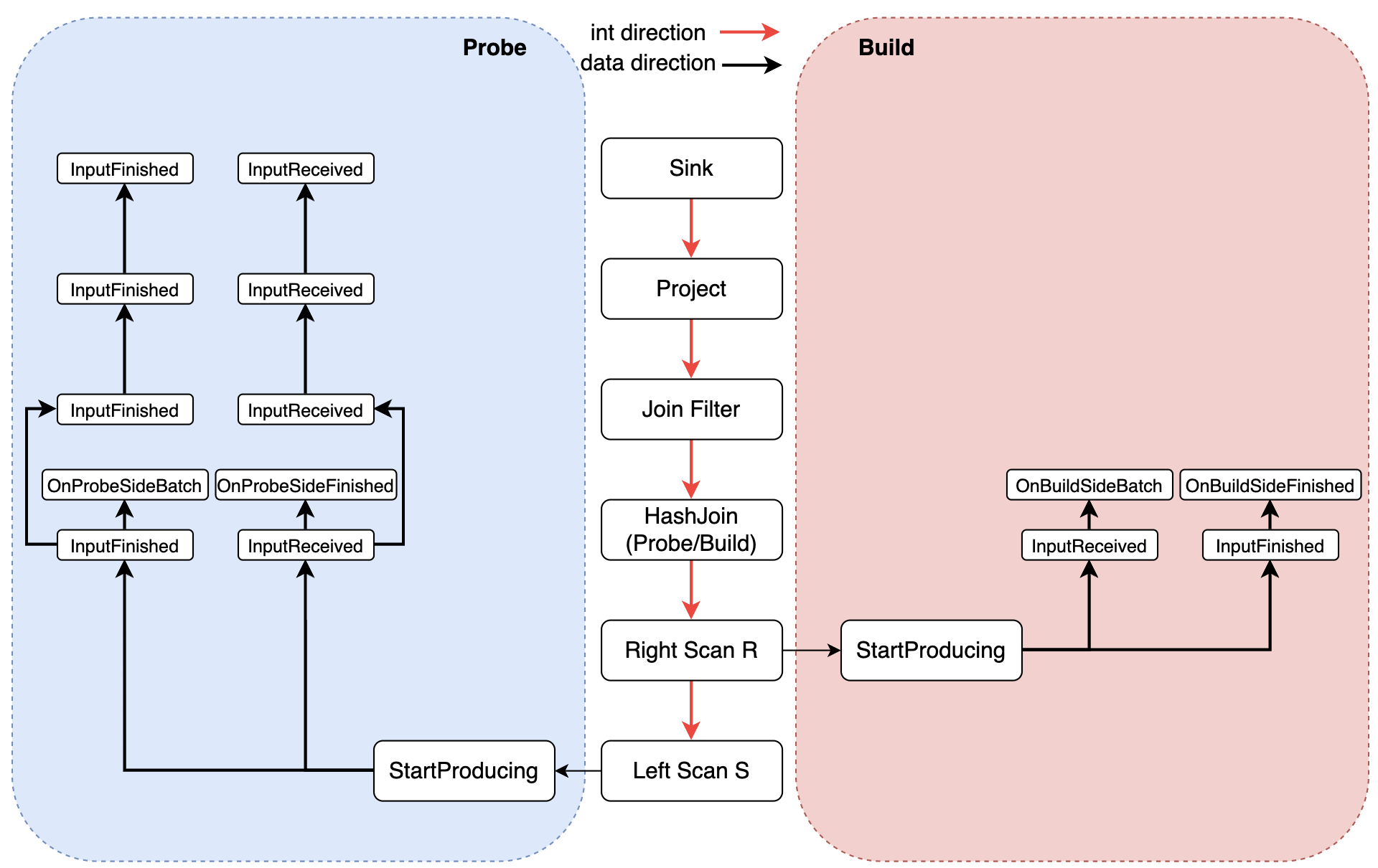
1.运行效果:
刀具磨损状态识别(Python代码,MSCNN_LSTM_Attention模型,初期磨损、正常磨损和急剧磨损)_哔哩哔哩_bilibili
环境库:
NumPy 版本: 1.19.4
Pandas 版本: 0.23.4
Matplotlib 版本: 2.2.3
Keras 版本: 2.4.0
TensorFlow 版本: 2.4.0
sklearn 版本: 0.19.2
如果库版本不一样, 一般也可以运行,这里展示我运行时候的库版本,是为了防止你万一在你的电脑上面运行不了,可以按照我的库版本进行安装并运行
2.数据集介绍
试验数据来源于美国纽约预测与健康管理学 会(PHM)2010年高 速 数 控 机 床 刀 具 健 康 预 测 竞 赛的开放数据。数据集下载链接
链接:https://pan.baidu.com/s/17GbX52SlPScsv0G7fDp5dQ
提取码:4561
实验条件如表格 所示
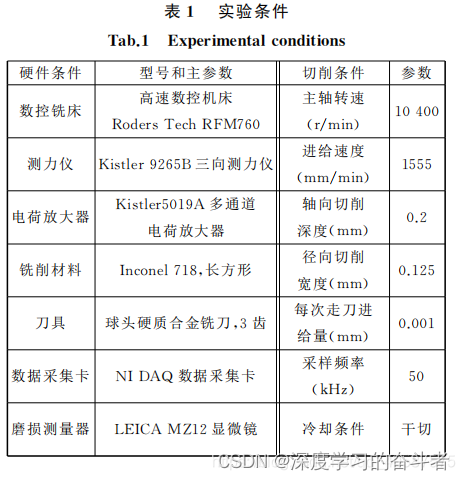
实验数据获取的形式是: 试验在上述切削条件下重复进行 6 次全寿命周期试验。端面铣削材料为正方形, 每次走刀端
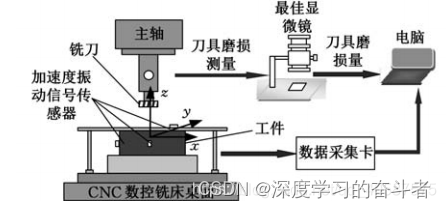
面铣的长度为 108mm 且 每 次 走 刀 时 间 相 等 , 每次走刀后测量刀具的后刀面磨损量。试验监测数据有x、y 、 z 三向
铣削力信号 , x 、 y 、 z 三向铣削振动信号以及声发射均方根值。
6次的数据集中 3次实验中有测量铣刀的磨损量,其他3次没有测量,作为比赛的测试集。
文件c1、c4、c6为训练数据,文件c2、c3、c5为测试数据:第1列:X维力(N)
第2列:Y维力(N)
第3列:Z维力(N)
第4列:X维振动(g)
第5列:Y维振动(g)
第6列:Z维振动(g)
第7列:AE-RMS (V)刀具主轴转速为10400 RPM;进给速度1555 mm/min;切割Y深度(径向)为0.125 mm;
Z轴向切割深度为0.2 mm。数据以50khz /通道采集。
系统测量的实验条件和实验方式如下所示:

3.本次项目介绍

c1为数据集
version.py是查看你本地环境库的版本,为了方便你运行代码写的脚本
MSCNN_LSTM_Attention.py是读取原始数据,预处理,磨损状态分类的主程序。
数据量较大,因为本地电脑配置一般, 所以只用了c1数据集进行实验,只需要修改数据集路径,也可以调用c2-c6数据集。
数据集一共有315个表格
数据集开始位置
数据集截止位置:
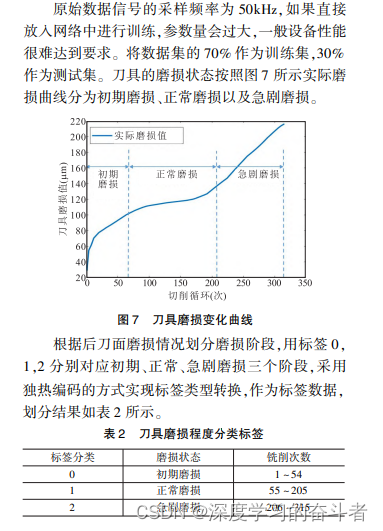
参考知网论文:《基于改进卷积门控循环神经网络的刀具磨损状态识别》一文中,对初期磨损、正常磨损、急剧磨损的划分,取1-54为初期磨损,55-205为正常磨损、206-315为急剧磨损
数据预处理:
采用的数据是每个表格的第四列数据,即X维振动信号。如果想做数据融合(即把Y维和Z维振动信号也用上,可以私信定制)
对原始数据归一化后,采用10000的样本长度不重叠切割样本, 这次为做平衡数据集下的实验,每种状态取1000个样本。
实验部分:
训练集与测试集的比例:4:1
批量:64
优化器:Adam
学习率:0.001
模型(MSCNN_LSTM_Attention,每个样本的形状原为(10000,1),但是为了让网络训练更快,目前代码中变形为(250,40),两个输入形式在代码中都可以使用,只要稍微改动一下即可)

 特征(训练集和测试集)形状
特征(训练集和测试集)形状

标签(训练集和测试集)形状

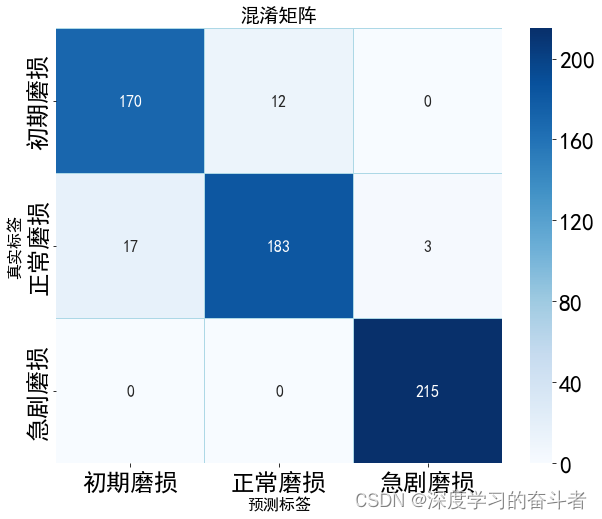
4.效果(测试集准确率100个epoch训练完为94.67%)
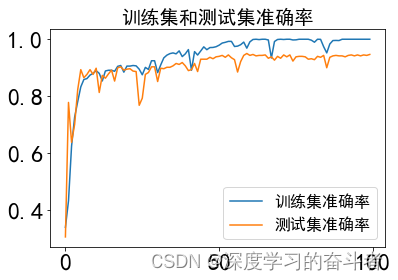
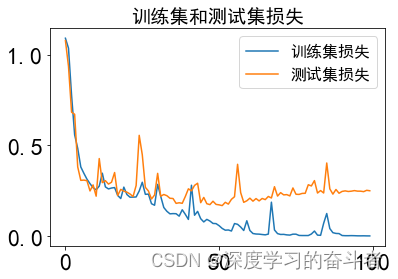
测试集混淆矩阵 (以百分比形式展示)
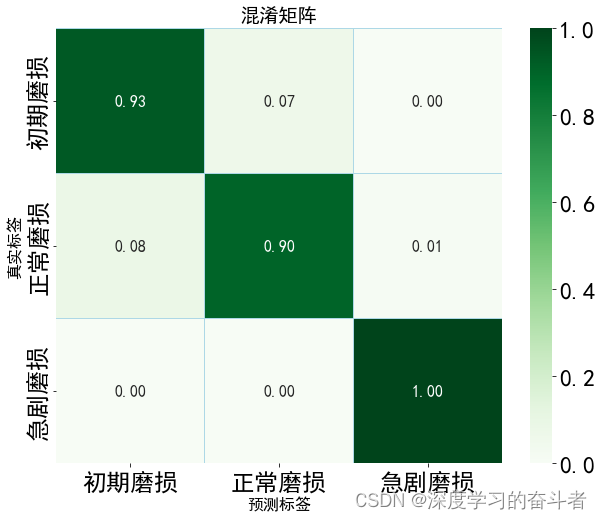
测试集混淆矩阵(以个数为展示)
对项目感兴趣的,可以关注最后一行
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import keras
import tensorflow as tf
from sklearn import __version__ as sklearn_version
from matplotlib import __version__ as matplotlib_versionprint(f"NumPy 版本: {np.__version__}")
print(f"Pandas 版本: {pd.__version__}")
print(f"Matplotlib 版本: {matplotlib_version}")
print(f"Keras 版本: {keras.__version__}")
print(f"TensorFlow 版本: {tf.__version__}")
print(f"sklearn 版本: {sklearn_version}")
#数据集和代码压缩包:https://mbd.pub/o/bread/ZZWblphr