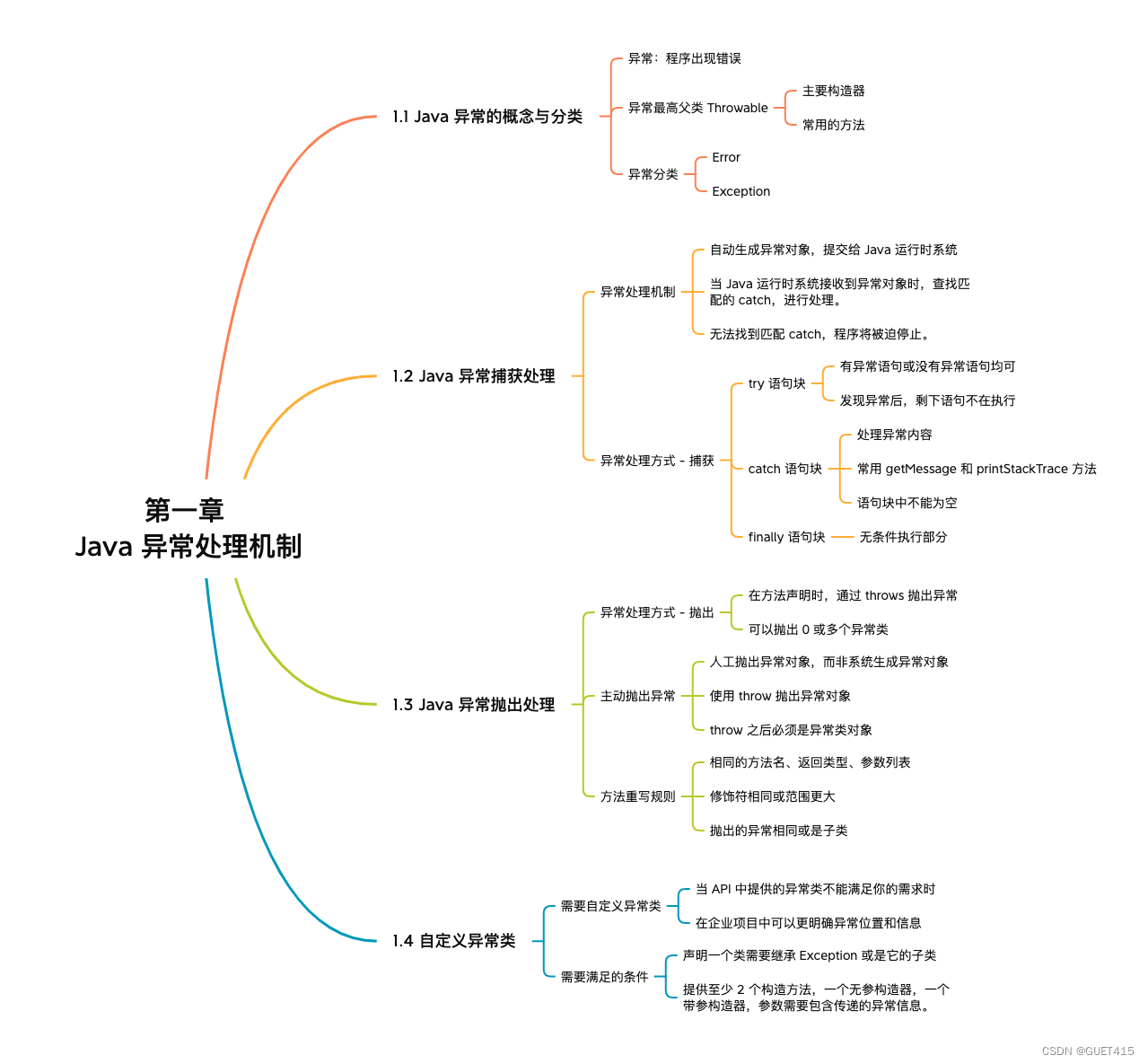
Java异常处理机制
异常
异常的最高父类是 Throwable,在 java.lang 包下。
Throwable 类的方法主要有:
| 方法 | 说明 |
|---|---|
| public String getMessage() | 返回对象的错误信息 |
| public void printStackTrace() | 输出对象的跟踪信息到标准错误输出流 |
| public void printStackTrace(PrintStream s) | 输出对象的跟踪信息到输出流 s |
| public String toString() | 返回对象的简短描述信息 |
Throwable 类的子类有 Error 错误和 Exception 违例。
异常的捕获处理
当 Java 运行时系统接收到异常对象时,会寻找能处理这一异常的代码并把当前异常对象交给其处理,这一过程称为捕获异常。
try-catch
try 语句块:
- 将可能出现异常的代码都放在 try 代码块中。
- try 语句块中发现异常,剩下的语句将不再执行。
catch 语句块:
- 在 catch 语句块中是对异常对象进行处理的代码。
- 每个 try 语句块可以伴随一个或多个 catch 语句,用于处理可能产生的不同类型的异常对象。
- 通过 getMessage( ) 获取异常信息或 printStackTrace( ) 跟踪异常信息。
finally
finally 关键字主要是和捕获异常的 try-catch 语句一起使用,放在 finally 语句块中的内容表示无条件执行的部分,也就是说不管程序有异常或没有异常都需要执行的部分。
企业面试时,经常会提到的问题:final、finally 和 finalize 的区别是什么?
- final 关键字,是用来修饰属性、方法、类的。
- finally 关键字,可以配合异常处理,进行无条件执行操作。
- finalize 不是关键字,是 Object 类中的一个方法,是 Java 垃圾回收机制中进行资源释放的方法。
异常的抛出处理
Java 程序的执行过程中如出现异常,会自动生成一个异常类对象,该异常对象将被提交给 Java 运行时系统,这个过程称为抛出异常。
throws 抛出的异常可以是 0 或多个,也就是说声明方法时可以不抛出异常,也可以抛出 1 个,或多个。
throw 关键字后只能抛出一个确切的异常类对象,而 throws 后可以抛出多个异常类,而非 new 的对象。
throw 之后的只能是异常对象,不能是其他对象,也就是说不能这样写 throw new String("错误信息") 。
自定义异常
创建异常类,只需满足以下两个要求:
- 声明一个类需要继承 Exception 或是它的子类。
- 提供至少 2 个构造方法,一个无参构造器,一个带参构造器,参数需要包含传递的异常信息。
集合和泛型
集合框架
集合框架可以分为 Collection 和 Map 两类
Collection 接口
主要有三个子接口,分别是 Set 接口、List 接口和 Queue 接口,下面简要介绍这三个接口。
-
Set 接口
Set 实例用于存储一组不重复的,无序的元素。
-
List 接口
List 实例是一个有序集合。程序员可对 List 中每个元素的位置进行精确控制,可以根据索引来访问元素,此外 List 中的元素是可以重复的。
-
Queue 接口
Queue 中的元素遵循先进先出的规则,是对数据结构 “队列” 的实现。
Map接口
定义了存储和操作一组 “键(key)值(value)” 映射对的方法。
区别
Map 接口和 Collection 接口的本质区别在于,Collection 接口里存放的是一系列单值对象,而 Map 接口里存放的是一系列 key-value 对象。Map 中的 key 不能重复,每个 key 最多只能映射到一个值。
Set接口(无重复,无序)
Set 接口继承自 Collection 接口的主要方法。
-
boolean add(Object obj)向集合中添加一个 obj 元素,并且 obj 不能和集合中现有数据元素重复,添加成功后返回 true。如果添加的是重复元素,则添加操作无效,并返回 false。
-
void clear()移除此集合中的所有数据元素,即将集合清空。
-
boolean contains(Object obj)判断此集合中是否包含 obj,如果包含,则返回 true。
-
boolean isEmpty()判断集合是否为空,为空则返回 true。
-
Iterator iterator()返回一个 Iterator 对象,可用它来遍历集合中的数据元素。
-
boolean remove(Object obj)如果此集合中包含 obj,则将其删除,并返回 true。
-
int size()返回集合中真实存放数据元素的个数,注意与数组、字符串获取长度的方法的区别。
-
Object[] toArray()返回一个数组,该数组包含集合中的所有数据元素。
HashSet
//创建一个HashSet对象,存放学生姓名信息
Set nameSet = new HashSet();
// 操作
System.out.println("添加王云是否成功:" + nameSet.add("王云"));System.out.println("显示集合内容:" + nameSet);System.out.println("集合里是否包含南天华:" + nameSet.contains("南天华"));System.out.println("从集合中删除\"南天华\"...");
nameSet.remove("南天华");System.out.println("集合里是否包含南天华:" + nameSet.contains("南天华"));System.out.println("集合中的元素个数为:" + nameSet.size());HashSet 是如何判断元素重复的?
当向 HashSet 中增加元素时,HashSet 会先计算此元素的 hashcode,如果 hashcode 值与 HashSet 集合中的其他元素的 hashcode 值都不相同,那么就能断定此元素是唯一的。否则,如果 hashcode 值与 HashSet 集合中的某个元素的 hashcode 值相同,HashSet 就会继续调用 equals() 方法进一步判断它们的内容是否相同,如果相同就忽略这个新增的元素,如果不同就把它增加到 HashSet 中。
TreeSet
TreeSet 类在实现了 Set 接口的同时,也实现了 SortedSet 接口,是一个具有排序功能的 Set 接口实现类。TreeSet 集合中的元素是按字典顺序进行排列输出的。
常用方法
- add() 方法,为集合添加元素。
- toArray() 方法,把集合中的所有数据提取到一个新的数组中。
// 创建整型数组Integer[] array = new Integer[size];// 将集合元素转换为数组元素set.toArray(array);List接口(重复,有序)
List 是 Collection 接口的子接口,List 中的元素是有序的,而且可以重复。常用的 List 实现类是 ArrayList 和 LinkedList。
常用方法
-
void add(int index,Object o)在集合的指定 index 位置处,插入指定的 o 元素。
-
Object get(int index)返回集合中 index 位置的数据元素。
-
int indexOf(Object o)返回此集合中第一次出现的指定 o 元素的索引,如果此集合不包含 o 元素,则返回-1。
-
int lastIndexOf(Object o)返回此集合中最后出现的指定
o元素的索引,如果此集合不包含o元素,则返回-1。 -
Object remove(int index)移除集合中 index 位置的数据元素。
-
Object set(int index,Object o)用指定的 o 元素替换集合中 index 位置的数据元素。
ArrayList 类
数组(顺序表)在插入或删除数据元素时,需要批量移动数据元素,故性能较差;但在根据索引获取数据元素时,因为数组是连续存储的,所以在遍历元素或随机访问元素时效率高。
ArrayList 实现类的底层就是数组,因此 ArrayList 实现类更加适合根据索引访问元素的操作。
LinkedList 类
LinkedList 的底层是链表。LinkedList 和 ArrayList 在应用层面类似,只是底层存储结构上的差异导致了二者对于不同操作,存在性能上的差异。这其实就是顺序表和链表之间的差异。一般而言,对于 “索引访问” 较多的集合操作建议使用 ArrayList 实现类,而对于 “增删” 较多的集合操作建议使用 LinkedList 实现类。
泛型
泛型是指在定义集合的同时也定义集合中元素的类型,需要 “< >” 进行指定,其语法形式如下:
集合<数据类型> 引用名 = new 集合实现类<数据类型> ();在定义集合的同时使用泛型,用 “< >” 进行指定集合中元素的类型后,再从集合中取出某个元素时,就不需要进行类型转换,不仅可以提高程序的效率,也让程序更加清晰明了,易于理解。
Iterator 接口
Iterator 接口为遍历集合而生,是 Java 语言解决集合遍历的一个工具。
iterator() 方法定义在 Collection 接口中,因此所有单值集合的实现类,都可以通过 iterator() 方法实现遍历。
Iterator 接口的三个方法:
-
boolean hasNext()判断是否存在下一个可访问的数据元素。
-
Object next()返回要访问的下一个数据元素,通常和 hasNext() 在一起使用。
-
void remove()从迭代器指向的 Collection 集合中移除迭代器返回的上一个数据元素。
Integer[] infos = {12,45,23,86,100,78,546,1,45,99,136,23};
Set s = new TreeSet();
for (Integer i : infos) {s.add(i);
}// 使用迭代器遍历集合数据
Iterator it = s.iterator();
while(it.hasNext()) {System.out.println(it.next());
}Map接口
Map 接口,用于保存具有映射关系的键值对数据。
Map<K,V> 接口中的 key 和 value 可以是任何引用类型的数据,key 不允许重复,value 可以重复,key 和 value 都可以是 null 值,但需要注意的是,key 为 null 只能有一个,value 为 null 可以多个,它们之间存在单向一对一关系,也就是说通过指定存在的 key 一定找到对应的 value 值。
常用方法
-
Object put(Object key,Object value)将指定键值对(key 和 value)添加到 Map 集合中,如果此 Map 集合以前包含一个该键 key 的键值对,则用参数 key 和 value 替换旧值。
-
Object get(Object key)返回指定键 key 所对应的值,如果此 Map 集合中不包含该键 key,则返回 null。
-
Object remove(Object key)如果存在指定键 key 的键值对,则将该键值对从此 Map 集合中移除。
-
Set keySet()返回此 Map 集合中包含的键的 Set 集合。在上面的程序最后添加下面的语句:
System.out. println(domains.keySet());,则会输出[com, edu, org, net]。 -
Collection values()返回此 Map 集合中包含的值的 Collection 集合。在上面的程序最后添加下面的语句:
System.out.println(domains.values());,则会输出[工商企业,教研机构,非营利组织,网络服务商]。 -
boolean containsKey(Object key)如果此 Map 集合包含指定键 key 的键值对,则返回 true。
-
boolean containsValue(Object value)如果此 Map 集合将一个或多个键映射到指定值,则返回 true。
-
int size()返回此 Map 集合的键值对的个数。
IO和XML
File 类
File 类生成的对象就代表一个特定的文件或目录,并且 File 类提供了若干方法对这个文件或目录进行读写等各种操作。 File 类在 java.io 包下,与系统输入/输出相关的类通常都在此包下。
File 类的构造方法有如下四个:
File(String pathname):创建一个新的 File 实例,该实例的存放路径是 pathname。File(String parent, String child):创建一个新的 File 实例,该实例的存放路径是由 parent 和 child 拼接而成的。File(File parent, String child):创建一个新的 File 实例。 parent 代表目录, child 代表文件名,因此该实例的存放路径是 parent 目录中的 child 文件。File(URI uri):创建一个新的 File 实例,该实例的存放路径是由 URI 类型的参数指定的。
File 类中常用的方法
| 方法 | 说明 |
|---|---|
| canExecute() | 判断 File 类对象是否可执行。 |
| canRead() | 判断 File 类对象是否可读。 |
| canWrite() | 判断 File 类对象是否可写。 |
| createNewFile() | 当不存在该文件时,创建一个新的空文件。 |
| exists() | 判断 File 类对象是否存在。 |
| getAbsoluteFile() | 获取 File 类对象的绝对路径。 |
| getName() | 获取 File 类对象的名称。 |
| getParent() | 获取 File 类对象父目录的路径。 |
| getPath() | 获取 File 类对象的路径。 |
| isAbsolute() | 判断 File 类对象是否是绝对路径。 |
| isDirectory() | 判断 File 类对象是否是目录。 |
| isFile() | 判断 File 类对象是否是文件。 |
| isHidden() | 判断 File 类对象是否有隐藏的属性。 |
| lastModified() | 获取 File 类对象最后修改时间。 |
| length() | 获取 File 类对象的长度。 |
| listRoots() | 列出可用的文件系统根目录。 |
IO流
流是对 I/O 操作的形象描述,水从一个地方转移到另一个地方就形成了水流,而信息从一处转移到另一处就叫做 I/O 流。
在 Java 中,文件的输入和输出是通过流(Stream)来实现的,流的概念源于 UNIX 中管道(pipe)的概念。在 UNIX 系统中,管道是一条不间断的字节流,用来实现程序或进程间的通信,或读写外围设备、外部文件等。
输入和输出
在计算机的世界中,输入 Input 和输出 Output 都是针对计算机的内存而言的。
在 Java 中流分为 :字节流和字符流。
字节流的处理单位是字节,通常用来处理二进制文件,如音乐、图片文件等,并且由于字节是任何数据都支持的数据类型,因此字节流实际可以处理任意类型的数据。而字符流的处理单位是字符,因为 Java 采用 Unicode 编码,Java 字符流处理的即 Unicode 字符,所以在操作文字、国际化等方面,字符流具有优势。
输出字节流类和输入字节流类存在对应关系
FileInputStream:把一个文件作为输入源,从本地文件系统中读取数据字节,实现对文件的读取操作。ByteArrayInputStream:把内存中的一个缓冲区作为输入源,从内存数组中读取数据字节。ObjectInputStream:对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化,用于恢复那些以前序列化的对象,注意这个对象所属的类必须实现 Serializable 接口。PipedInputStream:实现了管道的概念,从线程管道中读取数据字节。主要在线程中使用,用于两个线程间的通信。SequenceInputStream:其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直至到达文件末尾,接着从第二个输入流读取,依次类推。System.in:从用户控制台读取数据字节,在System类中,in 是InputStream类型的静态成员变量。
InputStream 输入流的方法
int read():从输入流中读取数据的下一字节,返回 0 ~ 255 范围内的整型字节值;如果输入流中已无新的数据,则返回 -1,否则返回值 > -1。int read(byte[] b):从输入流中读取一定数量的字节,并将其存储在字节数组 b 中,以整数形式返回实际读取的字节数(要么是字节数组的长度,要么小于字节数组的长度)。int read(byte[] b, int off, int len):将输入流中最多 len 个数据字节读入字节数组 b 中,以整数形式返回实际读取的字节数,off 指数组 b 中将写入数据的初始偏移量。void close():关闭此输入流,并释放与该流关联的所有系统资源。int available():返回可以不受阻塞地从此输入流读取(或跳过)的估计字节数。void mark(int readlimit):在此输入流中标记当前的位置。void reset():将此输入流重新定位到上次 mark 的位置。boolean markSupported():判断此输入流是否支持mark()和reset()方法。long skip(long n):跳过并丢弃此输入流中数据的 n 字节。
字符流
读取字符流类继承自抽象类 Reader,写入字符流继承自抽象类 Writer。
输出字符流类和输入字符流类存在对应关系
FileReader:与FileInputStream对应,从文件系统中读取字符序列。CharArrayReader:与ByteArrayInputStream对应,从字符数组中读取数据。PipedReader:与PipedInputStream对应,从线程管道中读取字符序列。StringReader:从字符串中读取字符序列。
Writer 输出字符流
操作的数据是 char 相关类型,不是 byte 类型。
Writer append(char c):将指定字符 c 追加到此 Writer,此处是追加,不是覆盖。Writer append(CharSequence csq):将指定字符序列 csq 添加到此 Writer。Writer append(CharSequence csq, int start, int end):将指定字符序列 csq 的子序列,追加到此 Writer。void write(char[] cbuf):写入字符数组 cbuf。void write (char[] cbuf, int off, int len):写入字符数组 cbuf 的某一部分。void write(int c):写入单个字符 c。void write(String str):写入字符串 str。void write(String str, int off, int len):写入字符串 str 的某一部分。void close():关闭当前流。
缓冲流 BufferedReader /Writer
缓冲流、转换流和数据流,它们的底层都遵循着一个相同的设计模式——装饰器模式。简单的讲,装饰器模式就是通过方法,将对象逐步进行包装。
例如,字节输出流 FileOutputStream 对象放在缓冲输出流 BufferedOutputStream 类的构造方法中以后,就变成了一个缓冲输出流 BufferedOutputStream 对象,如下:
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(...)) ;更进一步,缓冲输出流对象如果又被传入到了数据流 DataOutputStream 类的构造方法中,就又变成了一个数据流 DataOutputStream 对象,如下:
DataOutputStream out = new DataOutputStream(bos);类似这种形式,就是装饰器模式的具体应用。
装饰器模式在语法上要求包装类和被包装类属于同一个继承体系,并且包装后外观未变,但功能得到了增强。





