十三、Python高级技巧
1. 闭包
解决全局变量问题:
- 代码在命名空间上(变量定义)不够干净、整洁
- 全局变量又被修改的风险
-
定义:
在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包。
-
简单闭包
def outer(logo: str):def inner(msg: str):print(f"<{logo}><{msg}><{logo}>")return innerfn1 = outer('稀土掘金') fn1('xzq') # <稀土掘金><xzq><稀土掘金> fn1('XZQ0723') # <稀土掘金><XZQ0723><稀土掘金> -
nonlocal关键字
在闭包函数(内部函数中)想要修改外部函数的变量值,需要用nonlocal声明这个外部变量
def outer(num1): def inner(num2):nonlocal num1num1 += num2print(num1)return innerfn = outer(10) fn(10) # 20 fn(10) # 30 fn(10) # 40 -
优点:
- 无需定义全局变量即可实现通过函数,持续的访问、修改某个值
- 闭包使用的变量的所用于在函数内,难以被错误的调用修改
-
缺点:
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存
2. 装饰器
装饰器其实也是一种闭包, 其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能。
-
装饰器的一般写法
- 希望给sleep函数,增加一个功能
- 在调用sleep前输出:我要睡觉了
- 在调用sleep后输出:我起床了
# 装饰器的一般写法(闭包) def sleep():import randomimport timeprint('睡眠中...')time.sleep(random.randint(1, 5))def outer(func):def inner():print('我睡了')func()print('我醒了')return innerfn = outer(sleep) fn() - 希望给sleep函数,增加一个功能
-
装饰器的语法糖写法
使用@outer定义在目标函数sleep之上
-
和上方同样的功能
# 装饰器的语法糖写法 def outer(func):def inner():print('我睡了')func()print('我醒了')return inner@outer def sleep():import randomimport timeprint('睡眠中...')time.sleep(random.randint(1, 5))sleep()
-
3. 多线程
-
进程和线程
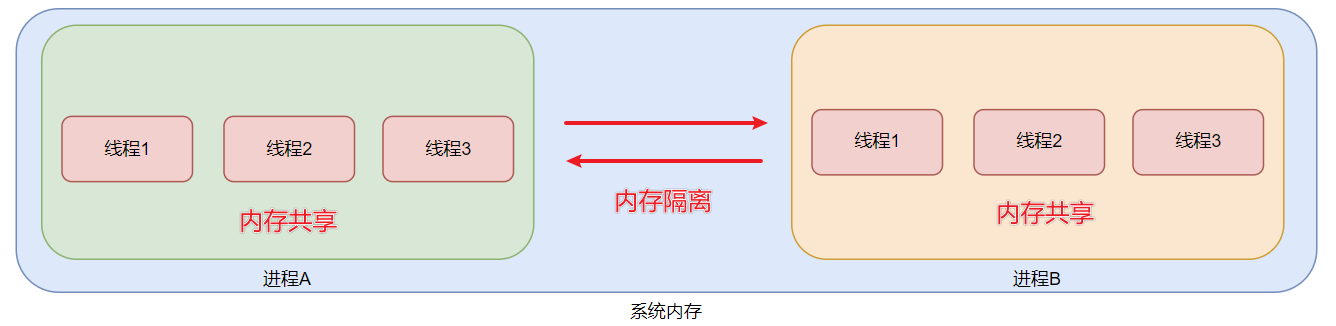
进程:是操作系统中正在运行的程序的实例。每个进程都有自己的内存空间、代码、数据等等。进程之间是独立的,它们无法互相访问对方的内存空间,只有通过进程间通信才能实现数据的共享。
线程:相对于进程而言,线程的开销更小,调度更快捷。另外,线程的并发能力更强,对于多核CPU来说也更加高效,因为不同的线程可以在不同的CPU内核上同时执行。但是,线程之间的共享变量可能会导致线程安全问题,需要加锁保护。
-
多线程网络编程
Python的多线程可以通过threading模块来实现。
-
语法
thread_obj = threading.Thread([group [, target [, name [, args [,kwargs]]]]]) # group:暂时无用,未来功能的预留参数 # target:执行的目标任务名 # args:以元组的方式给执行任务传参 # kwargs:以字典方式给执行任务传参 # name:线程名,一般不用设置 # 启动线程,让线程开始工作 thread_obj.start() -
示例:
import threading import timedef sing(msg):while True:print(msg)time.sleep(1)def dance(msg):while True:print(msg)time.sleep(1)if __name__ == '__main__':t1 = threading.Thread(target=sing, args=('啦啦啦',))t2 = threading.Thread(target=dance, kwargs={"msg": "舞舞舞"})t1.start()t2.start() -
4. Socket网络编程
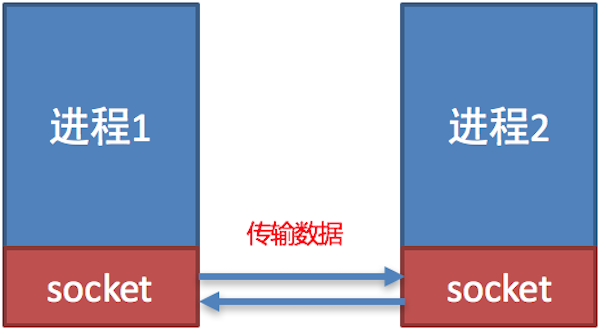
socket (简称 套接字) 是进程之间通信一个工具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行,进程之间想要进行网络通信需要Socket。Socket负责进程之间的网络数据传输,好比数据的搬运工。
-
2个进程之间通过Socket进行相互通讯,就必须有服务端和客户端
-
Socket服务端:等待其它进程的连接、可接受发来的消息、可以回复消息
-
Socket客户端:主动连接服务端、可以发送消息、可以接收回复
-
-
服务端示例
import socket# 1.创建Socket对象 socket_server = socket.socket()# 2.绑定ip地址和端口 服务端bind socket_server.bind(("localhost", 8888))# 3.监听端口 # listen方法内的参数表示可以链接的次数 socket_server.listen(1)# 4.等待客户端连接 # result为一个元组 ,accept()方法是阻塞的方法,等待客户端的连接如果没有连接,卡在这一行,就不会往下执行 # result = socket_server.accept() # conn = result[0] # 客户端的连接对象 # address = result[1] # 客户端的地址信息 conn, address = socket_server.accept()print(f'接收到客户端的链接,客户端的信息是:{address}') while True:# 5.接收客户端的信息,要使用客户端和服务端的本次连接对象,而非socket_server对象# recv的接收的参数事缓冲区大小,一般是1024即可,# 返回值是一个字节数组,也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象#data: str = conn.recv(1024).decode('UTF-8')print(f'客户端发来的消息是:{data}')# 6. 发送回复信息# encode可以将字符串编码为字节数组msg = input('请输入你要和客户端回复的消息:')if msg == 'exit':breakconn.send(msg.encode('UTF-8'))# 7.关闭连接 conn.close() socket_server.close() -
客户端示例
import socket# 1.创建Socket对象 socket_client = socket.socket()# 2.连接到服务端ip地址和端口 客户端connect socket_client.connect(("localhost", 8888)) while True:msg = input('请输入要给服务端发送的信息:')if msg == 'exit':break# 3.发送消息socket_client.send(msg.encode("UTF-8"))# 4.接收返回消息recv_data = socket_client.recv(1024)print(f'服务端返回的消息是: {recv_data.decode("UTF-8")}')# 5.关闭连接 socket_client.close()
5. 正则表达式
正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。简单来说,正则表达式就是使用:字符串定义规则,并通过规则去验证字符串是否匹配。
-
基本匹配
import res = 'xzq python xzq python xzq python' # match 从头匹配 result1 = re.match('xzq', s) print(F'match 结果:{result1}') # print(result1.span()) # print(result1.group())# search 搜索匹配 从前向后,找到第一个就停止 result2 = re.search('python', s) print(F'search 结果:{result2}') # print(result2.span()) # print(result2.group())# findall 搜索全部匹配 result3 = re.findall('python', s) print(F'search 结果:{result3}') -
元字符匹配
-
单字符匹配
字符 功能 . 匹配任意1个字符(除了\n),.匹配点本身 [] 匹配[]中列举的字符 \d 匹配数字0-9 \D 匹配非数字 \s 匹配空白,即空格、tab键 S\ 匹配非空白 \w 匹配单词字符,即a-z、A-Z、0-9、_ \W 匹配非单词字符 -
数量匹配
字符 功能 * 匹配前一个规则的字符出现0-无数次 + 匹配前一个规则的字符出现1-无数次 ? 匹配前一个规则的字符出现0次或1次 {m} 匹配前一个规则的字符出现m次 {m,} 匹配前一个规则的字符出现至少m次 {m,n} 匹配前一个规则的字符出现m-n次次 -
边界匹配
字符 功能 ^ 匹配字符串开头 $ 匹配字符串结尾 \b 匹配一个单词的边界 \B 匹配非单词的边界 -
分组匹配
字符 功能 | 匹配左右任意一个表达式 () 将括号中字符作为一个分组
示例:
import res = "!!xzq %^$&*xzq 22311 xzq_666 @@ ll" result = re.findall(r'[a-zA-Z0-9]', s) # 字符串前带r,表示字符串中转义字符无效 print(result) # 匹配账号,只能由字母和数字组成,长度限制6到10位 result1 = re.findall(r'^[a-zA-Z0-9]{6,10}$', '4556xzq') print(result1) # 匹配QQ号,要求纯数字,长度5-11,第一位不为0 result2 = re.findall(r'^[1-9][0-9]{4,10}$', '710675281') print(result2)# 匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址 result3 = re.match(r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)', '710.675281@qq.com') print(result3) -





