1. 数据增强
- 图像放缩和裁剪后,相机内参要做相应变化
import random
def random_scale(image, calib, scale_range=(0.8, 1.2)):scale = random.uniform(*scale_range)width, height = image.sizeimage = image.resize((int(width * scale), int(height * scale)))calib[:2, :] *= scalereturn image, calibdef random_crop(image, left, w_out, upper, h_out, calib):right = left + w_outlower = upper + h_outimage = image.crop((left, upper, right, lower))calib[0, 2] -= left # cx - ducalib[1, 2] -= upper # cy - dvcalib[0, 3] -= left * calib[2, 3] # tx - du * tz calib[1, 3] -= upper * calib[2, 3] # ty - dv * tz
2. 数据集
2.1. KITTI

- Rotation_y(全局航向角<BOC):
- 车头方向与相机的x轴正方向的夹角
- 描述目标在现实世界中的朝向,不随目标的位置和采集车的位置变化而变化
- theta:目标方位角
- Alpha:目标观测角,Alpha = theta + Rotation_y

- 单目3D学习alpha角,因为alpha是跟图像特征相关的
3. 单目3D检测任务问题总结
- 单目3D模型对相机的内外参变换敏感
- 对遮挡和截断目标的检测性能下降明显
- 对远距离的小目标性能下降严重(KITTI数据集,把超过46m的物体过滤)
- 2D检测框和3D检测框在2D图像上的投影不完全重合(传感器的时间同步问题,相机频率(20HZ)快于lidar频率(10HZ))
- 航向角预测不达标
- 无时序约束,3D检测结果抖动明显
单目3D检测的难点:
- 输入信息(2维)维度少于输出信息(3D)的维度
- 2D检测:输入输出都是2D
- 雷达检测:输入输出都是3D
- 输入的信息熵小于输出的信息熵
- 单目图像缺少深度信息

上图来自论文:https://openreview.net/pdf?id=mPlm356yMIP,ICLR 2022
- 现有3D检测方法的深度误差下限跟理论下限对比深度误差随着深度呈指数增长,理论误差与深度呈二次方增长
- CaDDN和Monodle在40米后呈现指数增长
- KITTI数据集,40米的深度理论误差是1.48米,60米是3.3
4. 单目3D检测范式
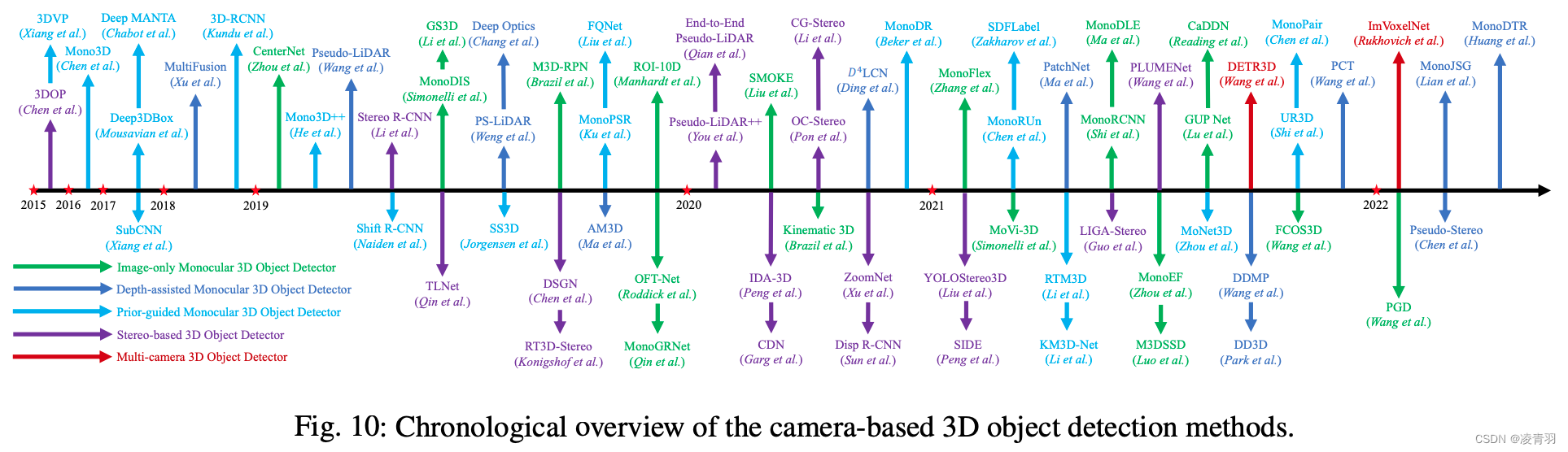
上图来自论文:3D Object Detection for Autonomous Driving: A Comprehensive Survey
- Images-only 单目3D检测(绿色)
- 单阶段anchor-base
- 单阶段anchor-free
- 两阶段3D检测
- Depth-assisted 单目3D检测(深蓝色)
- Depth-images based mono3D
- Pseudo-Lidar based mono3D
- Patch-based mono3D
- Prior-guide 单目3D检测(蓝色)
4.1. Images-only 单目3D检测

- 单阶段anchor-base (yolo3D)
- 利用图像特征和预定义的3D anchor来预测3D box的参数
- 单阶段anchor-free (centernet, KM3D)
- 直接利用图像特征来预测3D box的参数
- 两阶段3D检测
- 从2D检测生成2D边界框并crop 2D ROI
- 通过从2D ROI特征预测3D对象参数,将2D检测提升到3D空间
4.2. Depth-assisted 单目3D检测(引入深度先验)

- Depth-images based mono3D
- 融合RGB图像和深度图得到depth-aware特征
- 深度图由预训练的深度预测模型得到
- Pseudo-Lidar based mono3D
- 基于伪激光雷达的方法,首先讲深度图转为3D伪激光点云,再用基于激光雷达的3D检测算法进行检测
- Patch-based mono3D
- 基于patch的方法,将深度图转化为二维坐标图(2D coordinate map),然后在坐标图上用CNN进行检测
4.3. Prior-guide 单目3D检测

先验引导方法利用物体形状先验、几何先验、分割和时间约束来帮助检测3D物体
单目3D检测的先验信息:
- 先验信息:3D box下底边的中心点在图像的投影点的越靠近消失线,深度越大
- 物体3D尺寸与2D图像上投影比例关系
- 场景集合信息(消失点,消失线,车道线,天空)
3D检测用到的几何信息
- 相机没有pitch角,车辆没有抖动
- 地面是平的,地面没有起伏
注:对于没有深度图预测的3D检测算法,基本是在放宽这两个假设上,通过几何关系求深度
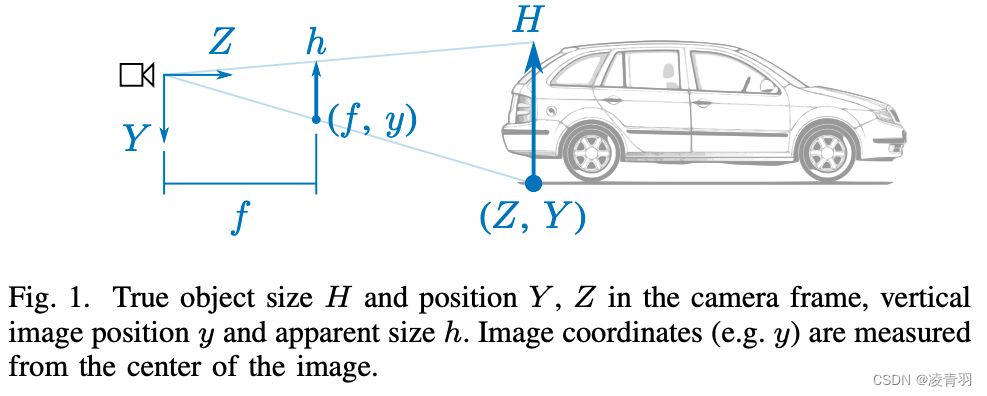
上图来源论文:How do neural networks see depth in single images?
- h/H = f/Z,得到Z=Hf/h
- f:相机的焦距
- Z:深度
- H:实际世界中的车宽
- h:物体在图像中的像素高度
- y/Y:f/Z
- y:相机距离地面的安装高度
- Y:图像中车轮与地面接触点的纵坐标
- 直观上理解,离我们越近的物体它的纵坐标应该越靠近图像下方,越远的物体越靠图像上方