精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】CHIP: Contrastive Hierarchical Image Pretraining
-
论文地址:https://arxiv.org//pdf/2310.08304
-
开源代码:GitHub - harshiljhaveri/CHIP

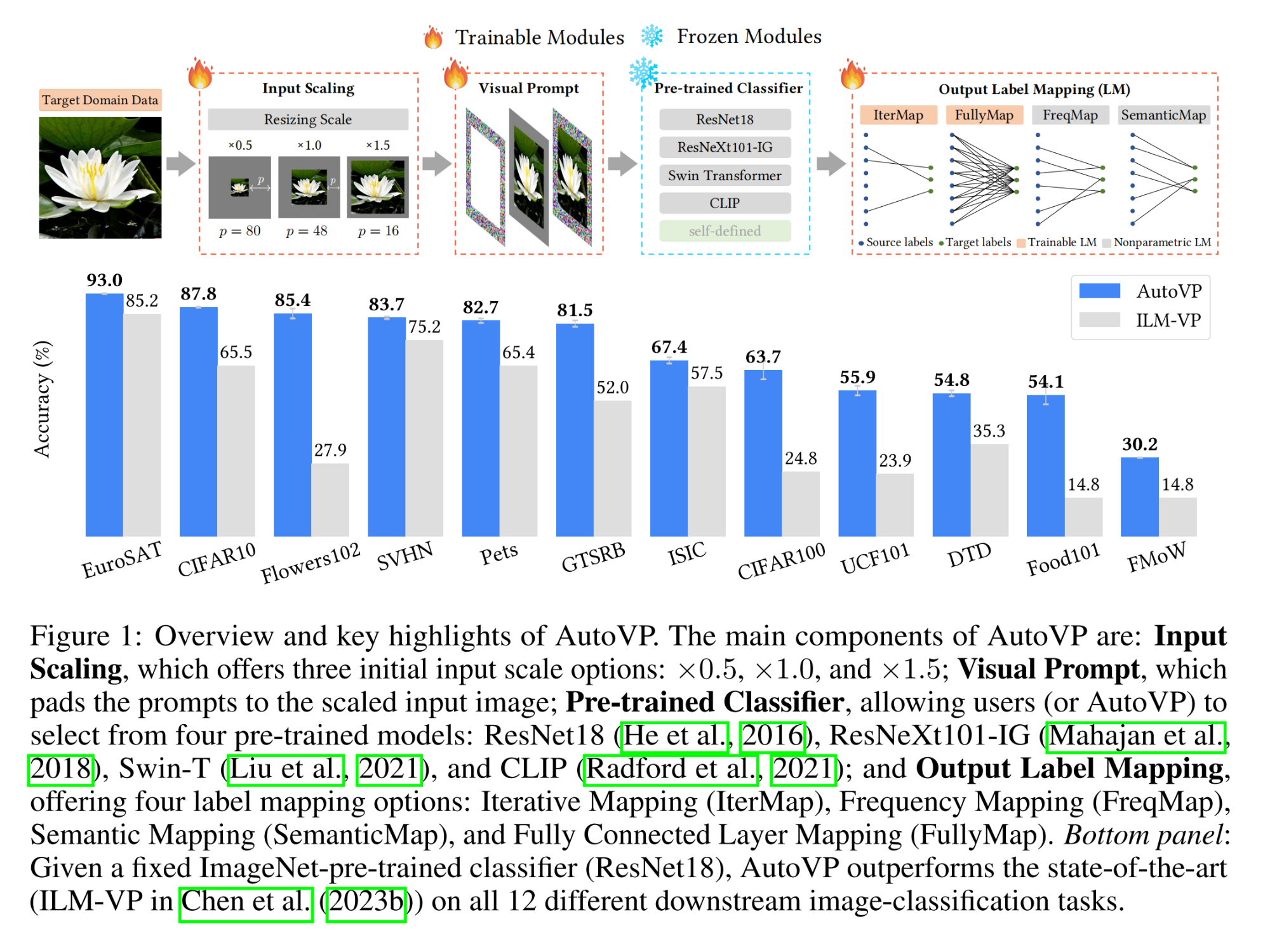
2.【基础网络架构:Transformer】AutoVP: An Automated Visual Prompting Framework and Benchmark
-
论文地址:https://arxiv.org//pdf/2310.08381
-
开源代码:GitHub - IBM/AutoVP: Code and Benchmark for the paper "AutoVP: An Automated Visual Prompting Framework and Benchmark"
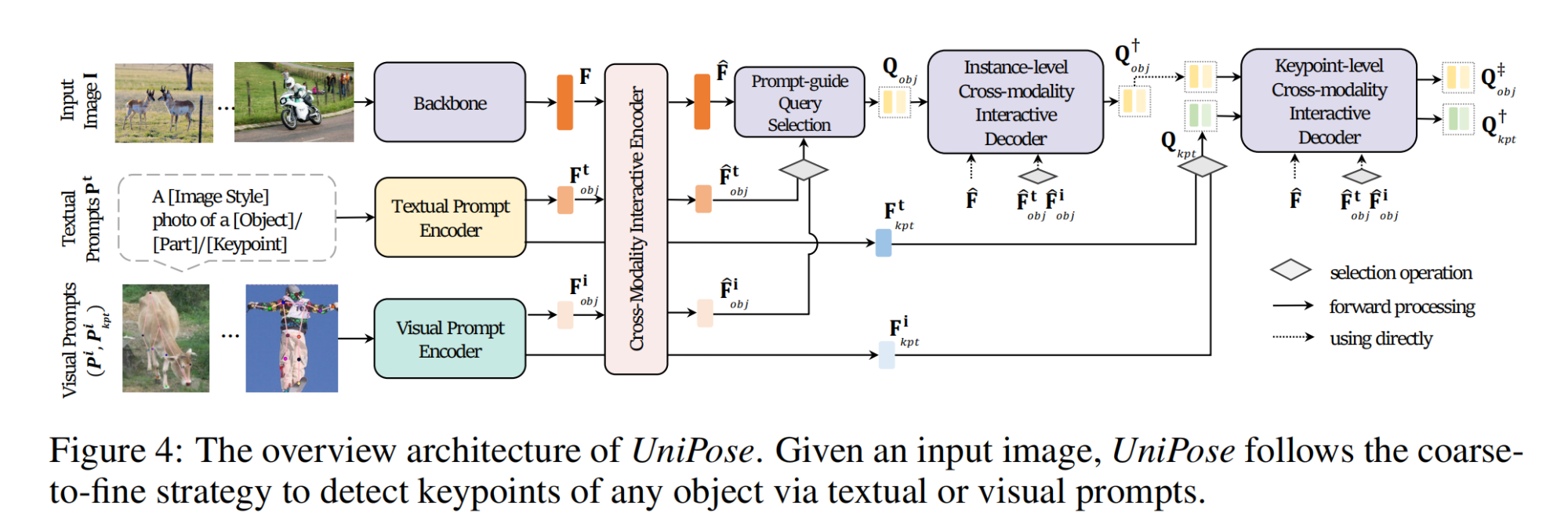
3.【关键点检测】UniPose: Detecting Any Keypoints
-
论文地址:https://arxiv.org//pdf/2310.08530
-
工程主页:UniPose: Detecting Any Keypoints
-
开源代码(即将开源):GitHub - IDEA-Research/UniPose: Official implementation of the paper "UniPose : Detecting Any Keypoints"
4.【点云】PonderV2: Pave the Way for 3D Foundataion Model with A Universal Pre-training Paradigm
-
论文地址:https://arxiv.org//pdf/2310.08586
-
开源代码:GitHub - Pointcept/Pointcept: Pointcept: a codebase for point cloud perception research. Latest works: PPT, MSC (CVPR'23), PTv2 (NeurIPS'22)

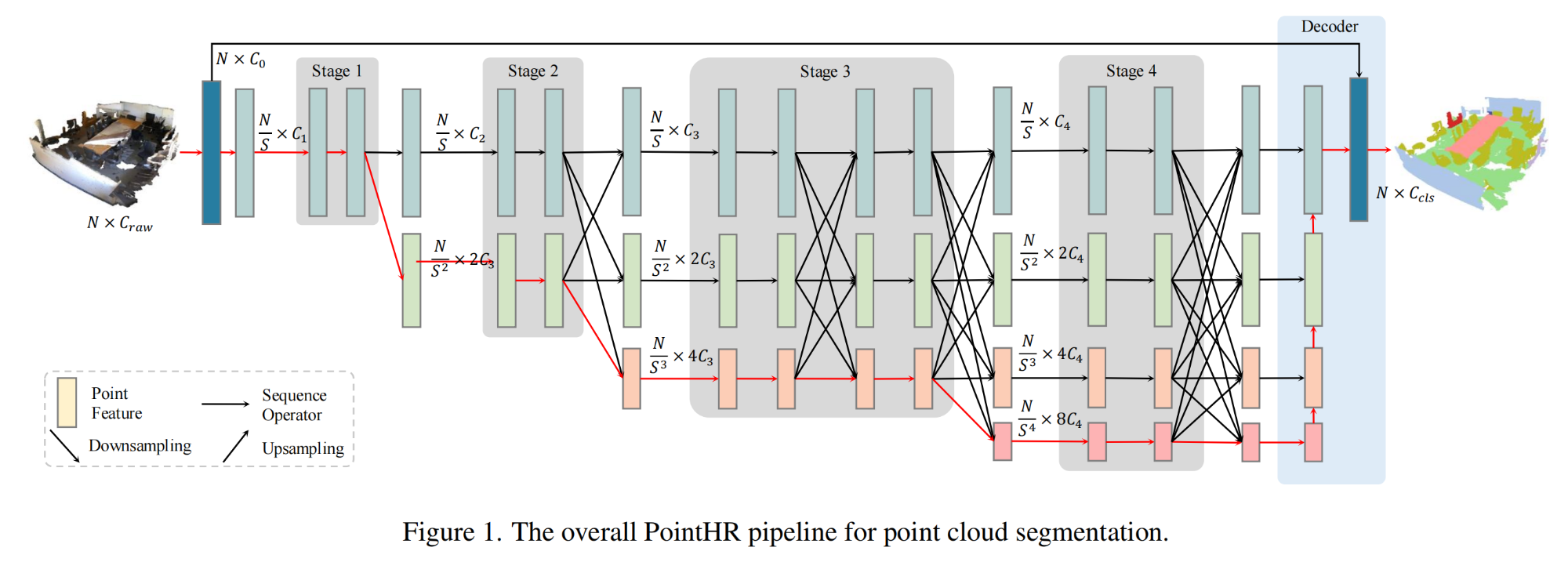
5.【点云分割】PointHR: Exploring High-Resolution Architectures for 3D Point Cloud Segmentation
-
论文地址:https://arxiv.org//pdf/2310.07743
-
开源代码:GitHub - haibo-qiu/PointHR: PointHR: Exploring High-Resolution Architectures for 3D Point Cloud Segmentation
6.【医学图像分割】Volumetric Medical Image Segmentation via Scribble Annotations and Shape Priors
-
论文地址:https://arxiv.org//pdf/2310.08084
-
开源代码:GitHub - Qybc/Scribble2D5: Scribble2D5: Weakly-Supervised Volumetric Image Segmentation via Scribble Annotations

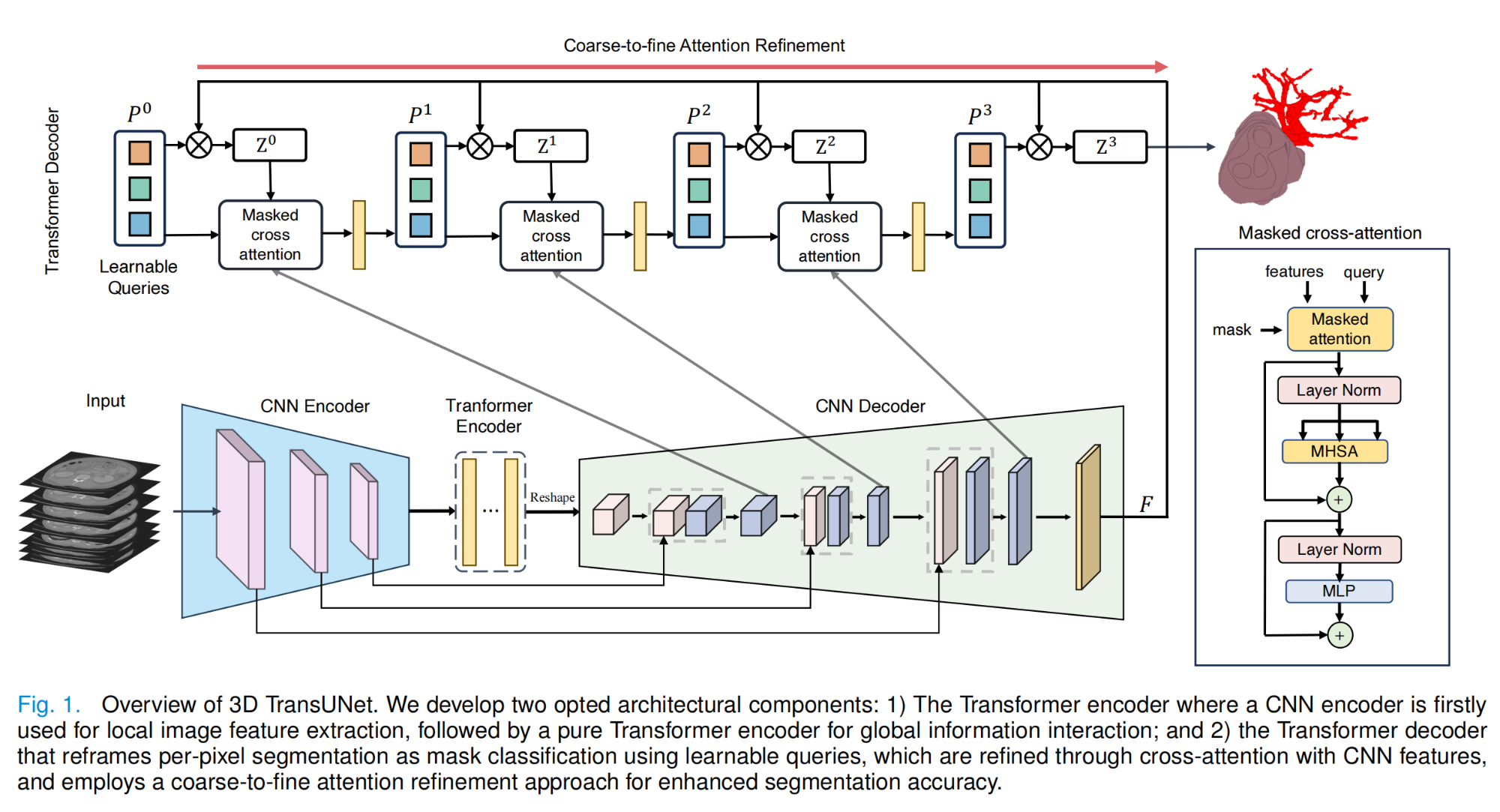
7.【医学图像分割:3D】3D TransUNet: Advancing Medical Image Segmentation through Vision Transformers
-
论文地址:https://arxiv.org//pdf/2310.07781
-
开源代码:GitHub - Beckschen/3D-TransUNet: This is the official repository for the paper "3D TransUNet: Advancing Medical Image Segmentation through Vision Transformers"
8.【多模态】Visual Data-Type Understanding does not emerge from Scaling Vision-Language Models
-
论文地址:https://arxiv.org//pdf/2310.08577
-
开源代码(即将开源):GitHub - bethgelab/DataTypeIdentification: Code for the paper: "Visual Data-Type Understanding does not emerge from Scaling Vision-Language Models"

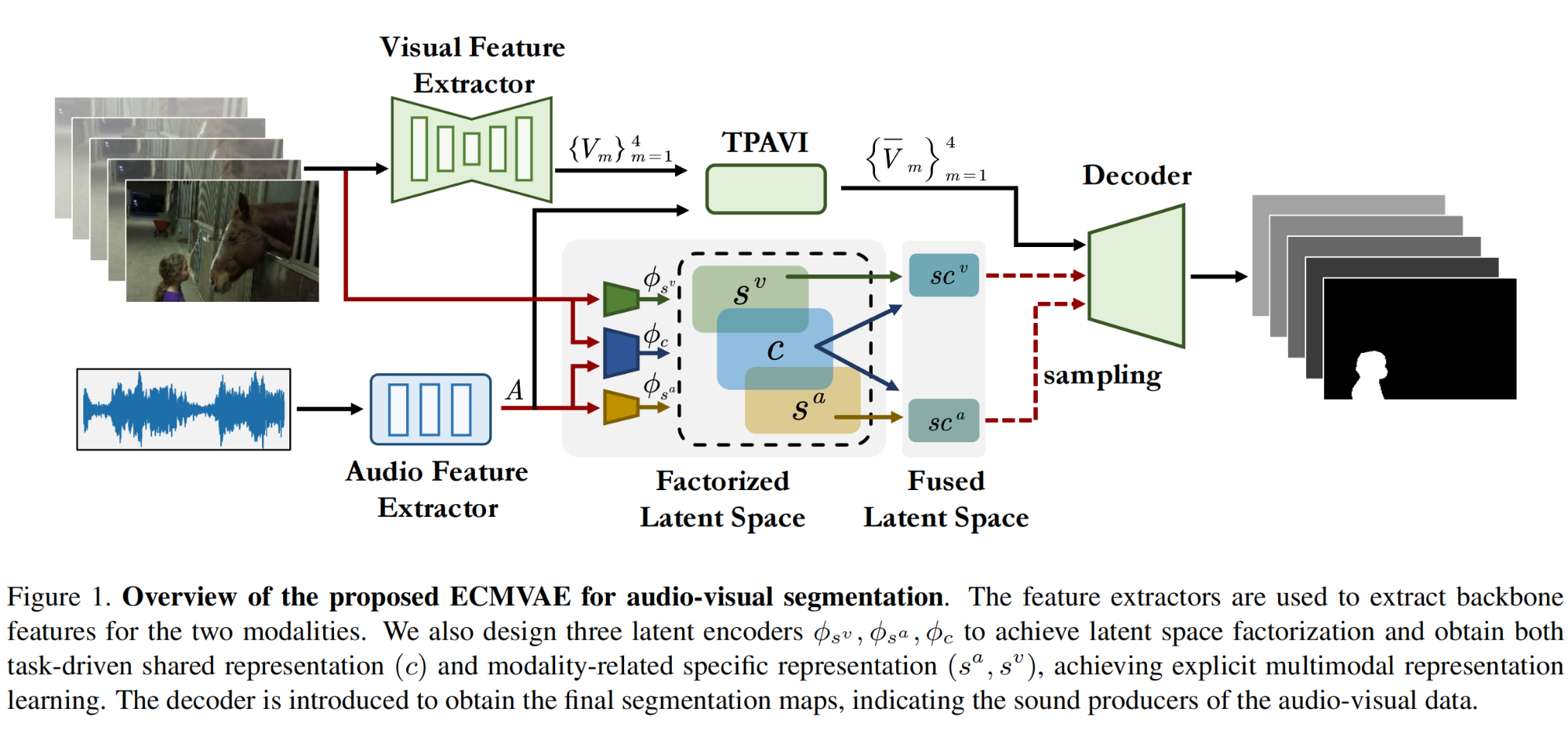
9.【多模态】Multimodal Variational Auto-encoder based Audio-Visual Segmentation
-
论文地址:https://arxiv.org//pdf/2310.08303
-
工程主页:Multimodal Variational Auto-encoder based Audio-Visual Segmentation
-
开源代码(即将开源):GitHub - OpenNLPLab/MMVAE-AVS: Multimodal Variational Auto-encoder based Audio-Visual Segmentation [ICCV2023].
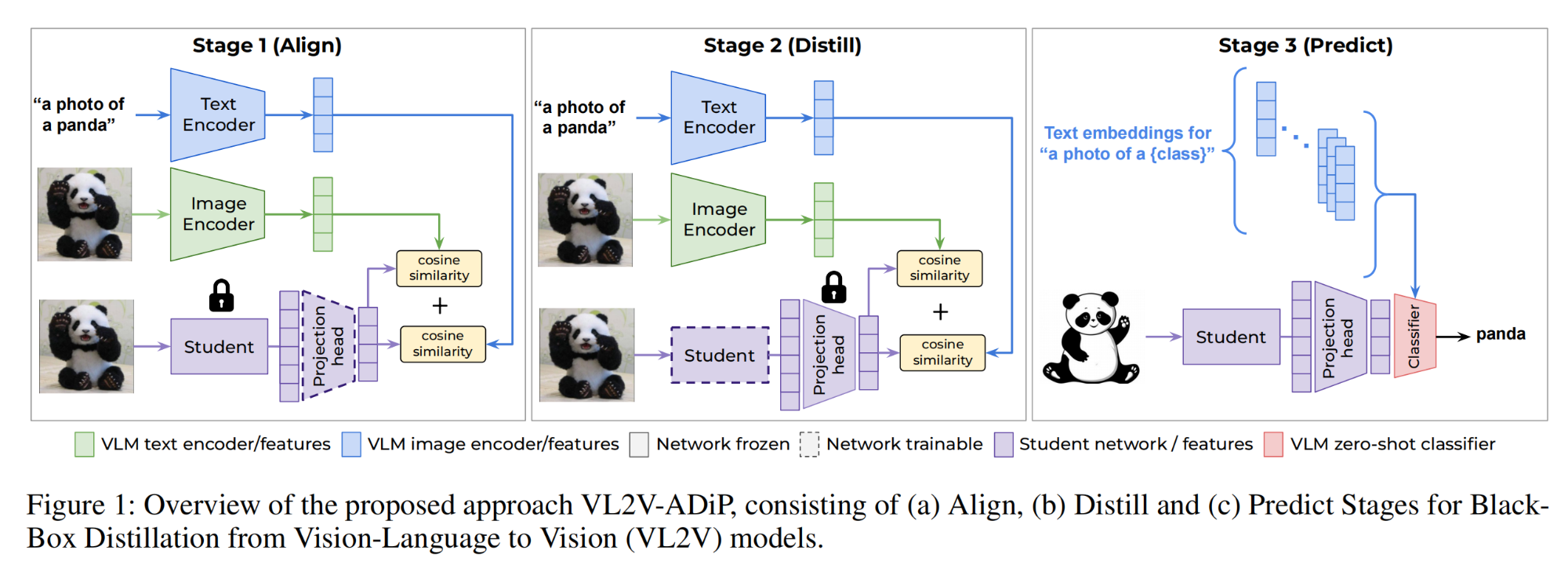
10.【多模态】Distilling from Vision-Language Models for Improved OOD Generalization in Vision Tasks
-
论文地址:https://arxiv.org//pdf/2310.08255
-
开源代码:GitHub - val-iisc/VL2V-ADiP: Distilling from Vision-Language Models for Improved OOD Generalization in Image Classification
11.【多模态】Lifelong Audio-video Masked Autoencoder with Forget-robust Localized Alignments
-
论文地址:https://arxiv.org//pdf/2310.08204
-
工程主页:FLAVA
-
代码即将开源

12.【多模态】Generalized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models
-
论文地址:https://arxiv.org//pdf/2310.08106
-
开源代码(即将开源):GitHub - BeierZhu/GLA: [NeurIPS 2023] Generalized Logit Adjustment (Coming Soon)

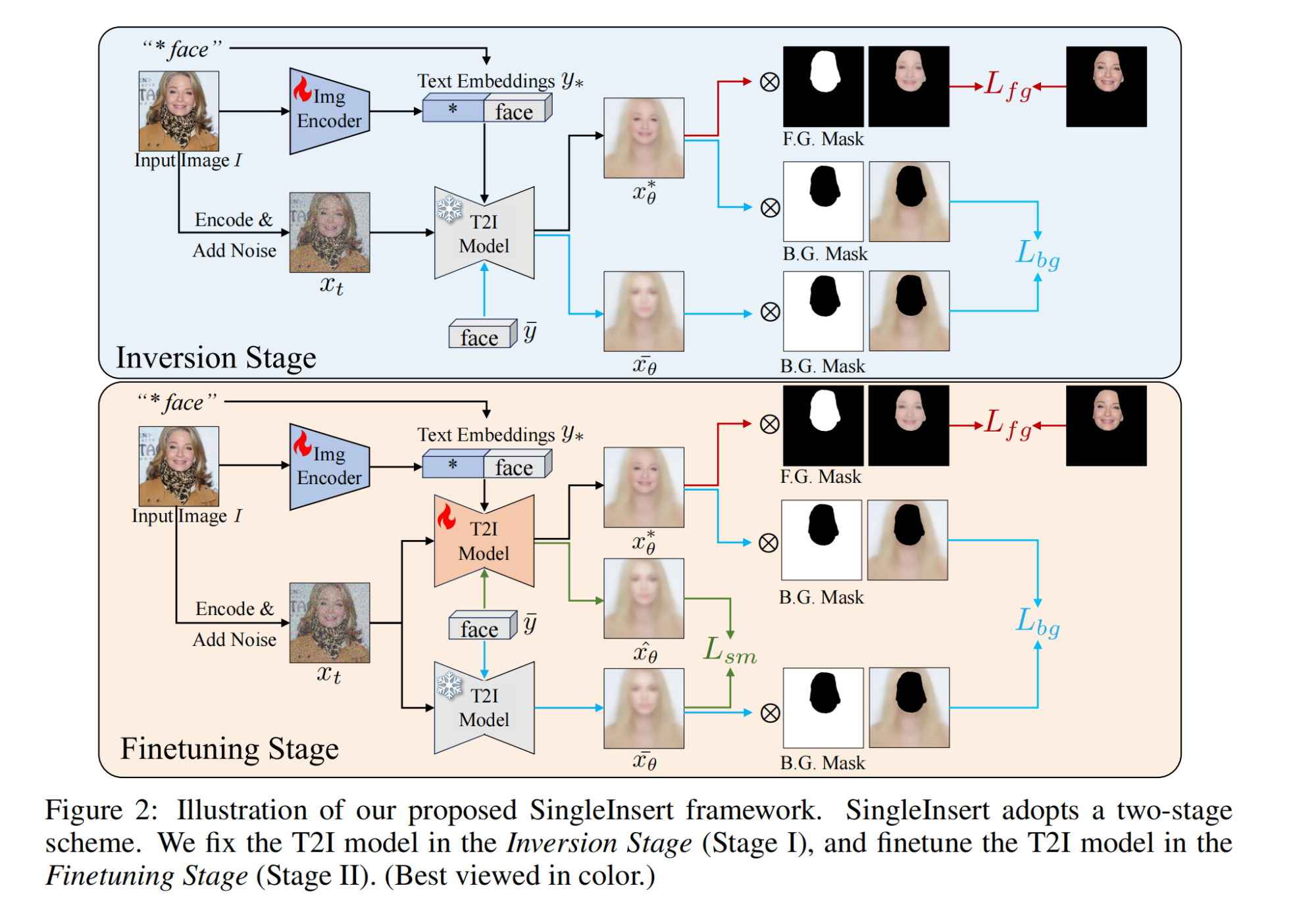
13.【多模态】SingleInsert: Inserting New Concepts from a Single Image into Text-to-Image Models for Flexible Editing
-
论文地址:https://arxiv.org//pdf/2310.08094
-
工程主页:SingleInsert
-
开源代码(即将开源):GitHub - JarrentWu1031/SingleInsert: Official pytorch implementation for SingleInsert
14.【多模态】Can We Edit Multimodal Large Language Models?
-
论文地址:https://arxiv.org//pdf/2310.08475
-
开源代码:GitHub - zjunlp/EasyEdit: An Easy-to-use Knowledge Editing Framework for LLMs.
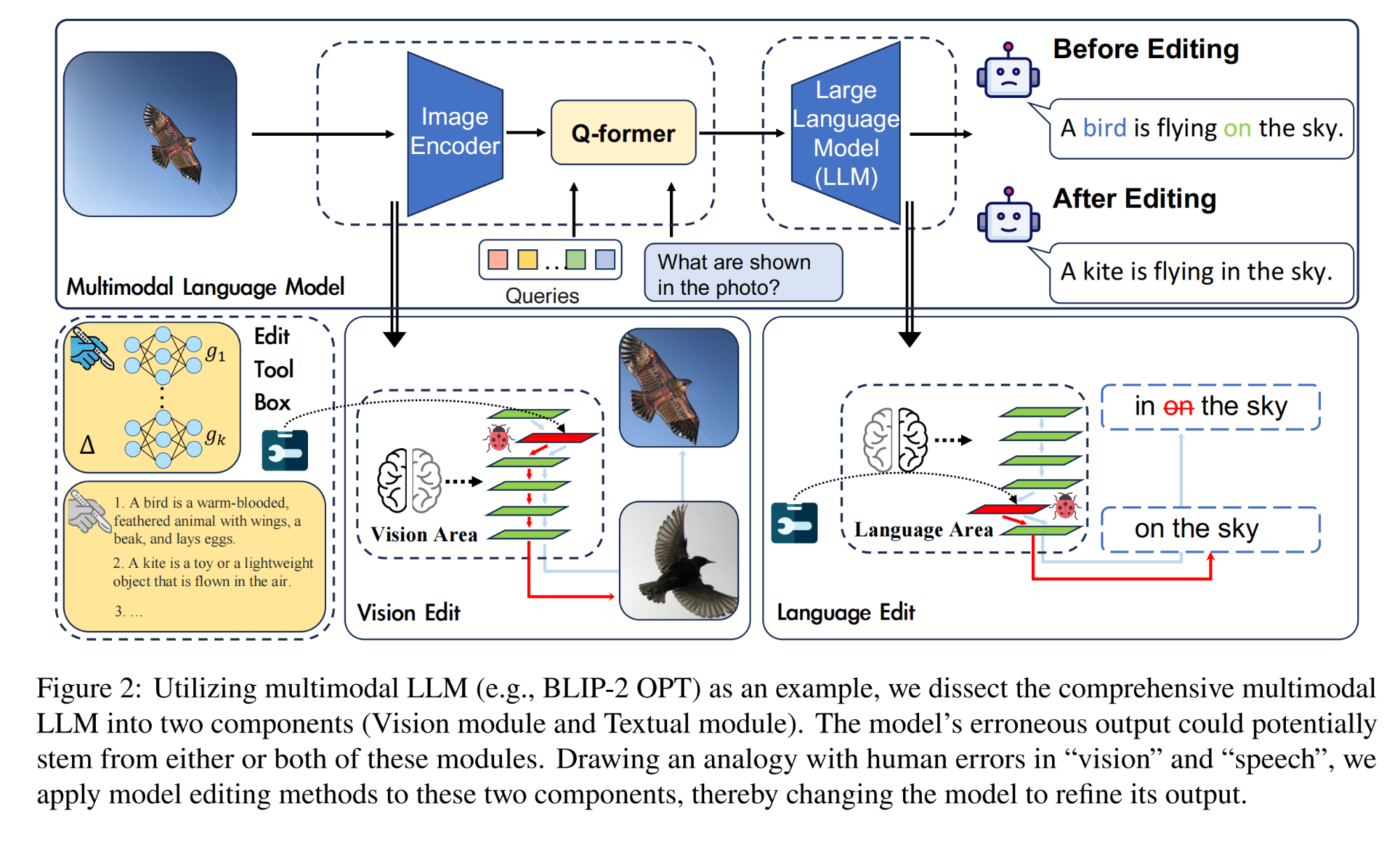
15.【自动驾驶:多模态感知】UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
-
论文地址:https://arxiv.org//pdf/2310.08370
-
开源代码(即将开源):GitHub - Nightmare-n/UniPAD: UniPAD: A Universal Pre-training Paradigm for Autonomous Driving

16.【自动驾驶:协同感知】DUSA: Decoupled Unsupervised Sim2Real Adaptation for Vehicle-to-Everything Collaborative Perception
-
论文地址:https://arxiv.org//pdf/2310.08117
-
开源代码(即将开源):GitHub - refkxh/DUSA: [ACM MM 2023] Official implementation of DUSA: Decoupled Unsupervised Sim2Real Adaptation for Vehicle-to-Everything Collaborative Perception
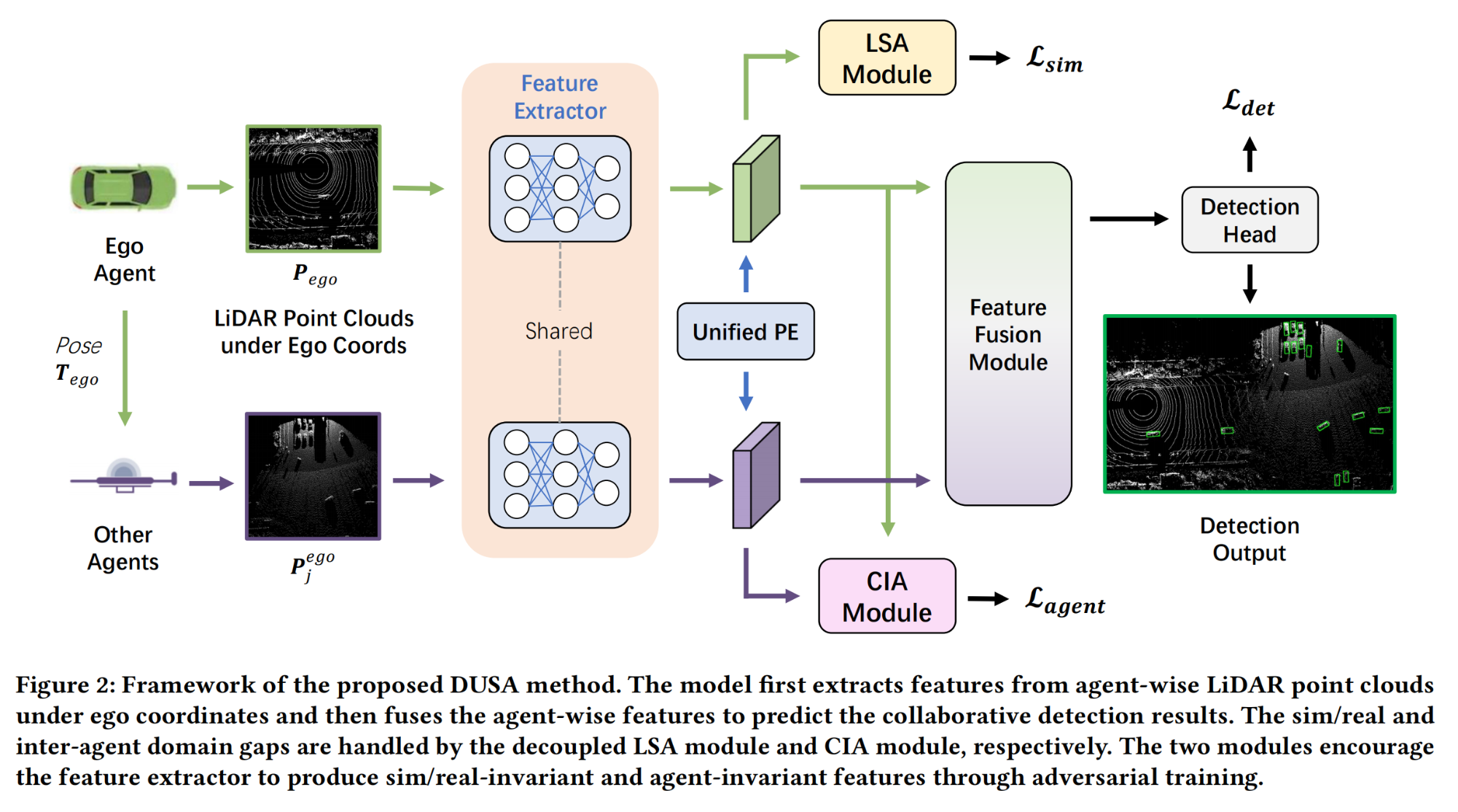
17.【自动驾驶:仿真】DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
-
论文地址:https://arxiv.org//pdf/2310.07771
-
工程主页:DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
-
开源代码(即将开源):GitHub - shalfun/DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model

18.【Diffusion】HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion
-
论文地址:https://arxiv.org//pdf/2310.08579
-
工程主页:HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion
-
开源代码(即将开源):GitHub - snap-research/HyperHuman: Github Repo for "HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion"

19.【Diffusion】MotionDirector: Motion Customization of Text-to-Video Diffusion Models
-
论文地址:https://arxiv.org//pdf/2310.08465
-
代码即将开源

20.【人体姿态估计】X-HRNet: Towards Lightweight Human Pose Estimation with Spatially Unidimensional Self-Attention
-
论文地址:https://arxiv.org//pdf/2310.08042
-
开源代码:GitHub - cool-xuan/x-hrnet: Official code for "X-HRNet: Towards Lightweight Human Pose Estimation with Spatially Unidimensional Self-Attention"
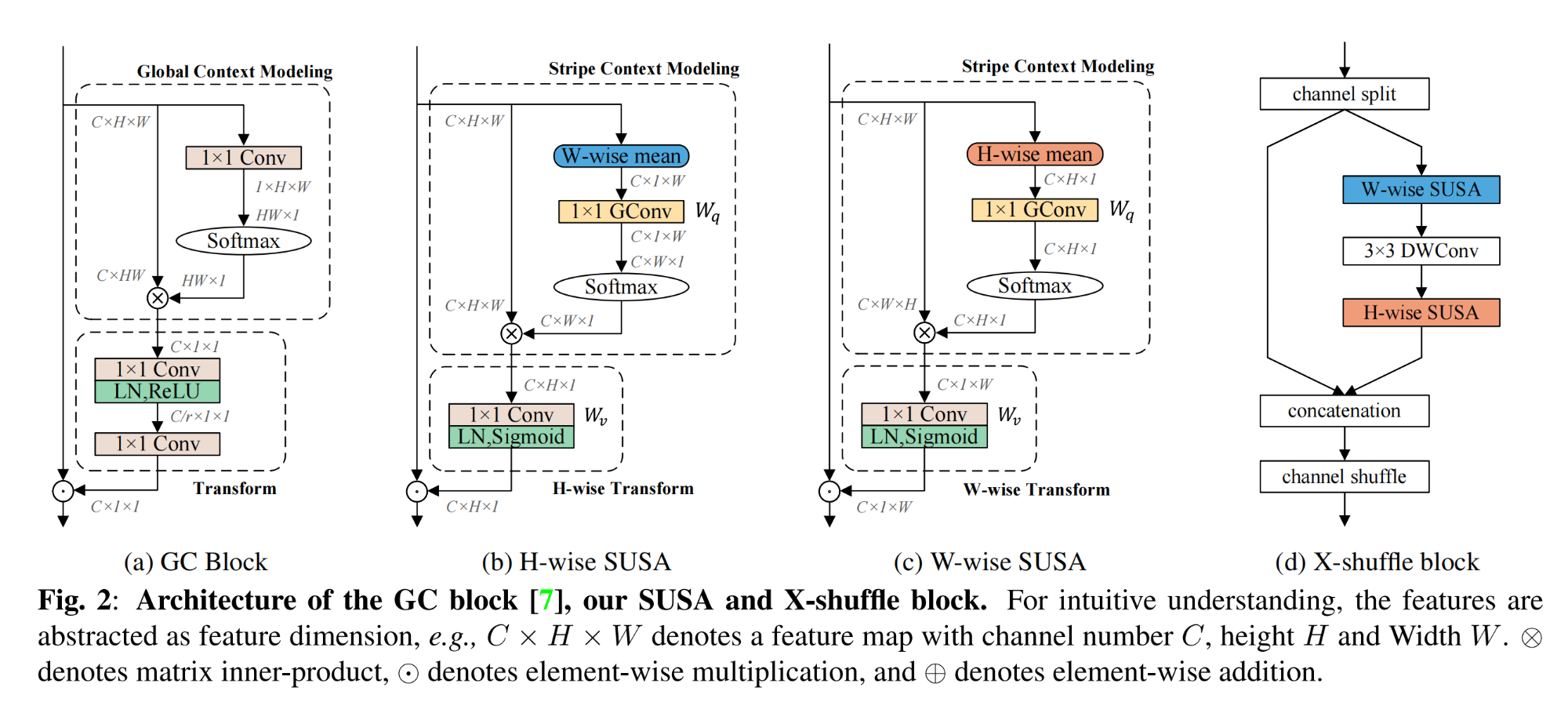
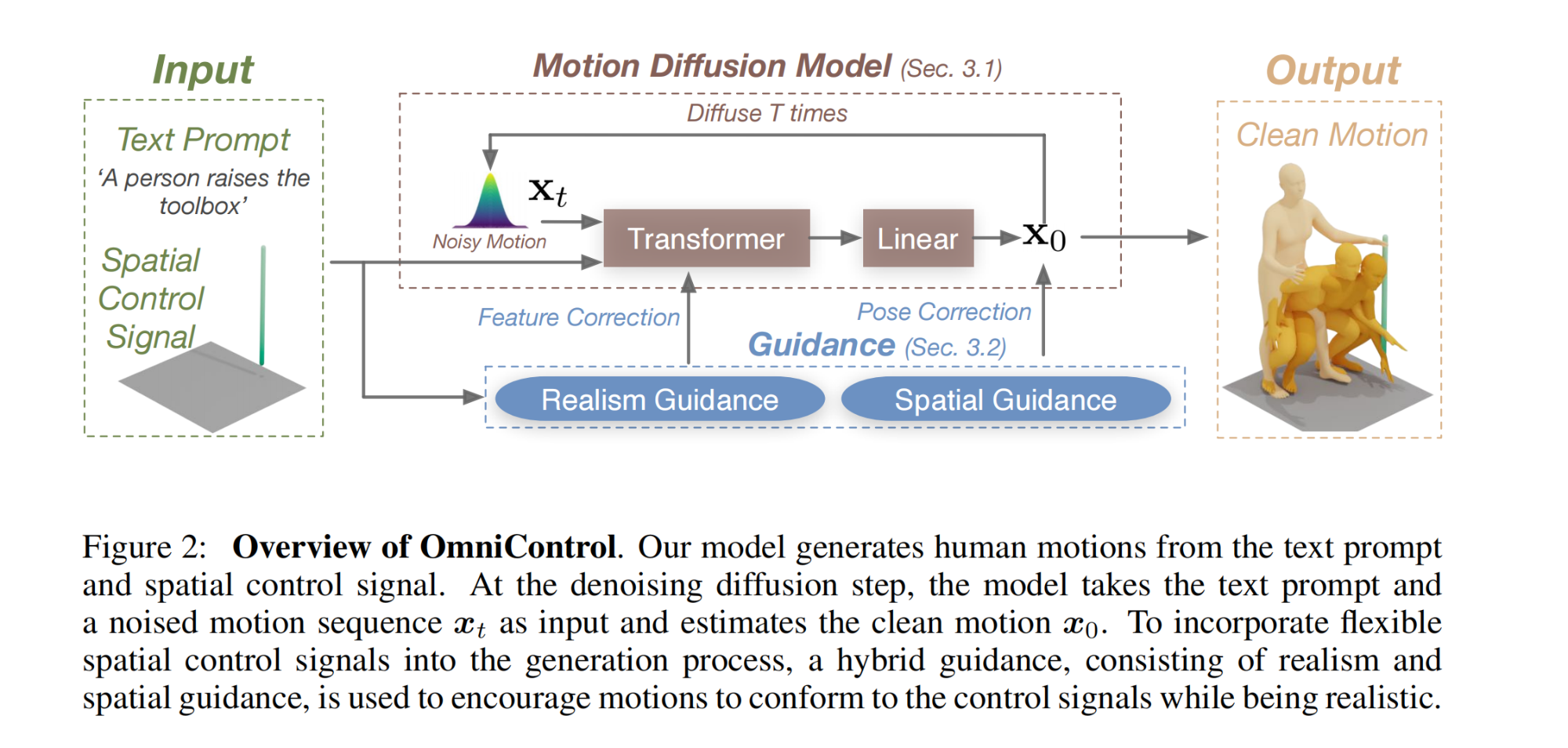
21.【人体运动生成】OmniControl: Control Any Joint at Any Time for Human Motion Generation
-
论文地址:https://arxiv.org//pdf/2310.08580
-
工程主页:OmniControl
-
开源代码(即将开源):GitHub - neu-vi/OmniControl
22.【生成模型】Explorable Mesh Deformation Subspaces from Unstructured Generative Models
-
论文地址:https://arxiv.org//pdf/2310.07814
-
开源代码(即将开源):ArmanMaesumi/generative-mesh-subspaces · GitHub

23.【三维重建】Consistent123: Improve Consistency for One Image to 3D Object Synthesis
-
论文地址:https://arxiv.org//pdf/2310.08092
-
工程主页:Consistent123: Improve Consistency for One Image to 3D Object Synthesis
-
代码即将开源
24.【图像分类:长尾分布】Long-Tailed Classification Based on Coarse-Grained Leading Forest and Multi-Center Loss
-
论文地址:https://arxiv.org//pdf/2310.08206
-
开源代码(即将开源):GitHub - jinyery/Cognisance: Long-tail Classification Based on Invariant Feature Learning from A Multi-granularity Perspective

论文已打包,点击进入—>下载界面
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
CV计算机视觉每日开源代码Paper with code速览-2023.10.12
CV计算机视觉每日开源代码Paper with code速览-2023.10.11
CV计算机视觉每日开源代码Paper with code速览-2023.10.10