本人目前工作中未涉及到WebUI自动化测试,但为了提升自己的技术,多学习一点还是没有坏处的,废话不多说了,目前主流的webUI测试框架应该还是selenium,考虑到可维护性、拓展性、复用性等,我们采用PO模式去写我们的脚本,本文档也主要整合了Selenium+PO模式+Pytest+Allure,下面我们进入正题。注:文章末尾附Github地址
技术前提:python、selenium、pytest基础知识
1. 项目结构目录:

2. PO模式介绍
PO模式特点:
- 易于维护
- 复用性高
- 脚本易于阅读理解
PO模式要素:
1. 在PO模式中抽象封装成一个BasePage类,该基类应该拥有一个只实现 webdriver 实例的属性
2. 每个一个 pag 都继承BasePage,通过driver来管理本page中元素将page中的操作封装成一个个的方法
3. TestCase依赖 page 类,从而实现相应的测试步骤

现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036
3. BasePage 页面封装
import logging
import os
import time
from datetime import datetime
from time import sleep
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from Utils.myLog import MyLog"""此类封装所有操作,所有页面继承该类
"""class BasePage(object):def __init__(self, driver):self.logger = MyLog().getLog()self.driver = driver# 等待元素可见def wait_eleVisible(self, loc, timeout=30, poll_frequency=0.5, model=None):""":param loc:元素定位表达;元组类型,表达方式(元素定位类型,元素定位方法):param timeout:等待的上限:param poll_frequency:轮询频率:param model:等待失败时,截图操作,图片文件中需要表达的功能标注:return:None"""self.logger.info(f'等待"{model}"元素,定位方式:{loc}')try:start = datetime.now()WebDriverWait(self.driver, timeout, poll_frequency).until(EC.visibility_of_element_located(loc))end = datetime.now()self.logger.info(f'等待"{model}"时长:{end - start}')except TimeoutException:self.logger.exception(f'等待"{model}"元素失败,定位方式:{loc}')# 截图self.save_webImgs(f"等待元素[{model}]出现异常")raise# 等待元素不可见def wait_eleNoVisible(self, loc, timeout=30, poll_frequency=0.5, model=None):""":param loc:元素定位表达;元组类型,表达方式(元素定位类型,元素定位方法):param timeout:等待的上限:param poll_frequency:轮询频率:param model:等待失败时,截图操作,图片文件中需要表达的功能标注:return:None"""logging.info(f'等待"{model}"消失,元素定位:{loc}')try:start = datetime.now()WebDriverWait(self.driver, timeout, poll_frequency).until_not(EC.visibility_of_element_located(loc))end = datetime.now()self.logger.info(f'等待"{model}"时长:{end - start}')except TimeoutException:self.logger.exception(f'等待"{model}"元素失败,定位方式:{loc}')# 截图self.save_webImgs(f"等待元素[{model}]消失异常")raise# 查找一个元素elementdef find_element(self, loc, model=None):self.logger.info(f'查找"{model}"元素,元素定位:{loc}')try:return self.driver.find_element(*loc)except NoSuchElementException:self.logger.exception(f'查找"{model}"元素失败,定位方式:{loc}')# 截图self.save_webImgs(f"查找元素[{model}]异常")raise# 查找元素elementsdef find_elements(self, loc, model=None):self.logger.info(f'查找"{model}"元素集,元素定位:{loc}')try:return self.driver.find_elements(*loc)except NoSuchElementException:self.logger.exception(f'查找"{model}"元素集失败,定位方式:{loc}')# 截图self.save_webImgs(f"查找元素集[{model}]异常")raise# 输入操作def input_text(self, loc, text, model=None):# 查找元素ele = self.find_element(loc, model)# 输入操作self.logger.info(f'在"{model}"输入"{text}",元素定位:{loc}')try:ele.send_keys(text)except:self.logger.exception(f'"{model}"输入操作失败!')# 截图self.save_webImgs(f"[{model}]输入异常")raise# 清除操作def clean_inputText(self, loc, model=None):ele = self.find_element(loc, model)# 清除操作self.logger.info(f'清除"{model}",元素定位:{loc}')try:ele.clear()except:self.logger.exception(f'"{model}"清除操作失败')# 截图self.save_webImgs(f"[{model}]清除异常")raise# 点击操作def click_element(self, loc, model=None):# 先查找元素在点击ele = self.find_element(loc, model)# 点击操作self.logger.info(f'点击"{model}",元素定位:{loc}')try:ele.click()except:self.logger.exception(f'"{model}"点击失败')# 截图self.save_webImgs(f"[{model}]点击异常")raise# 获取文本内容def get_text(self, loc, model=None):# 先查找元素在获取文本内容ele = self.find_element(loc, model)# 获取文本self.logger.info(f'获取"{model}"元素文本内容,元素定位:{loc}')try:text = ele.textself.logger.info(f'获取"{model}"元素文本内容为"{text}",元素定位:{loc}')return textexcept:self.logger.exception(f'获取"{model}"元素文本内容失败,元素定位:{loc}')# 截图self.save_webImgs(f"获取[{model}]文本内容异常")raise# 获取属性值def get_element_attribute(self, loc, name, model=None):# 先查找元素在去获取属性值ele = self.find_element(loc, model)# 获取元素属性值self.logger.info(f'获取"{model}"元素属性,元素定位:{loc}')try:ele_attribute = ele.get_attribute(name)self.logger.info(f'获取"{model}"元素"{name}"属性集为"{ele_attribute}",元素定位:{loc}')return ele_attributeexcept:self.logger.exception(f'获取"{model}"元素"{name}"属性失败,元素定位:{loc}')# 截图self.save_webImgs(f"获取[{model}]属性异常")raise# iframe 切换def switch_iframe(self, frame_refer, timeout=30, poll_frequency=0.5, model=None):# 等待 iframe 存在self.logger.info('iframe 切换操作:')try:# 切换 == index\name\id\WebElementWebDriverWait(self.driver, timeout, poll_frequency).until(EC.frame_to_be_available_and_switch_to_it(frame_refer))sleep(0.5)self.logger.info('切换成功')except:self.logger.exception('iframe 切换失败!!!')# 截图self.save_webImgs(f"iframe切换异常")raise# 窗口切换 = 如果是切换到新窗口,new. 如果是回到默认的窗口,defaultdef switch_window(self, name, cur_handles=None, timeout=20, poll_frequency=0.5, model=None):"""调用之前要获取window_handles:param name: new 代表最新打开的一个窗口. default 代表第一个窗口. 其他的值表示为窗口的 handles:param cur_handles::param timeout:等待的上限:param poll_frequency:轮询频率:param model:等待失败时,截图操作,图片文件中需要表达的功能标注:return:"""try:if name == 'new':if cur_handles is not None:self.logger.info('切换到最新打开的窗口')WebDriverWait(self.driver, timeout, poll_frequency).until(EC.new_window_is_opened(cur_handles))window_handles = self.driver.window_handlesself.driver.swich_to.window(window_handles[-1])else:self.logger.exception('切换失败,没有要切换窗口的信息!!!')self.save_webImgs("切换失败_没有要切换窗口的信息")raiseelif name == 'default':self.logger.info('切换到默认页面')self.driver.switch_to.default()else:self.logger.info('切换到为 handles 的窗口')self.driver.swich_to.window(name)except:self.logger.exception('切换窗口失败!!!')# 截图self.save_webImgs("切换失败_没有要切换窗口的信息")raise# 截图def save_webImgs(self, model=None):# filepath = 指图片保存目录/model(页面功能名称)_当前时间到秒.png# 截图保存目录# 拼接日志文件夹,如果不存在则自动创建cur_path = os.path.dirname(os.path.realpath(__file__))now_date = time.strftime('%Y-%m-%d', time.localtime(time.time()))screenshot_path = os.path.join(os.path.dirname(cur_path), f'Screenshots\\{now_date}')if not os.path.exists(screenshot_path):os.mkdir(screenshot_path)# 当前时间dateNow = time.strftime('%Y%m%d_%H%M%S', time.localtime(time.time()))# 路径filePath = '{}\\{}_{}.png'.format(screenshot_path, model, dateNow)try:self.driver.save_screenshot(filePath)self.logger.info(f"截屏成功,图片路径为{filePath}")except:self.logger.exception('截屏失败!')# 退出def get_driver(self):return self.driver4. 页面继承BasPage
from Common.basePage import BasePage
from selenium.webdriver.common.by import By
from time import sleepclass BaiduIndex(BasePage):"""页面元素"""# 百度首页链接baidu_index_url = "https://www.baidu.com"# 搜索框search_input = (By.ID, "kw")# "百度一下"按钮框search_button = (By.ID, "su")# 查询操作def search_key(self, search_key):self.logger.info("【===搜索操作===】")# 等待用户名文本框元素出现self.wait_eleVisible(self.search_input, model='搜索框')# 输入内容self.input_text(self.search_input, "阿崔", model="搜索框")# 清除文本框内容self.clean_inputText(self.search_input, model='搜索框')# 输入用户名self.input_text(self.search_input, text=search_key, model='搜索框')# 等待搜索按钮出现self.wait_eleVisible(self.search_button, model='"百度一下"搜索按钮')# 点击搜索按钮self.click_element(self.search_button, model='"百度一下"搜索按钮')# 搜索后等待界面加载完成self.driver.implicitly_wait(10)sleep(3)
5. pytest+allure编写测试用例
注:Pytest整合Allure教程请参考:https://www.cnblogs.com/huny/p/13752406.html
import os
import time
import pytest
import allure
from time import sleep
from selenium import webdriver
from PageObject.baiduIndex import BaiduIndexdriver = webdriver.Chrome()
baidu_index = BaiduIndex(driver)@pytest.fixture(scope="class")
def init():# 打开浏览器,访问登录页面baidu_index.logger.info("\nWebDriver 正在初始化...")driver.get(baidu_index.baidu_index_url)baidu_index.logger.info(f"打开链接: {baidu_index.baidu_index_url}...")# 窗口最大化driver.maximize_window()# 隐式等待driver.implicitly_wait(10)baidu_index.logger.info("WebDriver 初始化完成!")yielddriver.quit()baidu_index.logger.info("WebDriver 成功退出...")@allure.feature("百度搜索")
class TestBaiduSearch:@allure.story("搜索指定关键字")@pytest.mark.baidu_search@pytest.mark.parametrize("key_word", ["哈哈","呵呵",], )def test_search(self, init, key_word):# @pytest.mark.parametrize 参数化baidu_index.search_key(key_word)web_title = driver.titleassert "哈哈_百度搜索" == web_title
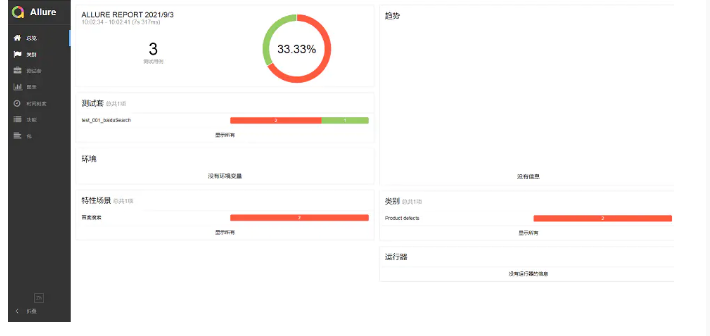
6. 生成Allure测试报告
Github地址:https://github.com/Zimo6/Selenium_Demo
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!

![[资源推荐] 复旦大学张奇老师科研分享](https://img-blog.csdnimg.cn/9b8643c952f04c0b9e5b366ea29c03fb.png)