目录
0.前言
1.合并两个排序链表
1.1 实用小妙招
1.2代码书写
2.链表分割
3.链表的回文结构
4.相交链表
4.1 实用小妙招(假定指针法)
4.2代码书写
5. 复制带随机指针的链表
0.前言
本文代码及分析图片资源都以上传Gitee,可自取:
3链表OJ题p2 · onlookerzy123456qwq/data_structure_practice_primer - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/onlookerzy123456qwq/data_structure_practice_primer/tree/master/3%E9%93%BE%E8%A1%A8OJ%E9%A2%98p2本篇我们继续刷爆链表的经典OJ题,看完你的链表水平会得到一个质的提示!
https://gitee.com/onlookerzy123456qwq/data_structure_practice_primer/tree/master/3%E9%93%BE%E8%A1%A8OJ%E9%A2%98p2本篇我们继续刷爆链表的经典OJ题,看完你的链表水平会得到一个质的提示!
1.合并两个排序链表
剑指 Offer 25. 合并两个排序的链表 - 力扣(LeetCode)![]() https://leetcode.cn/problems/he-bing-liang-ge-pai-xu-de-lian-biao-lcof/
https://leetcode.cn/problems/he-bing-liang-ge-pai-xu-de-lian-biao-lcof/
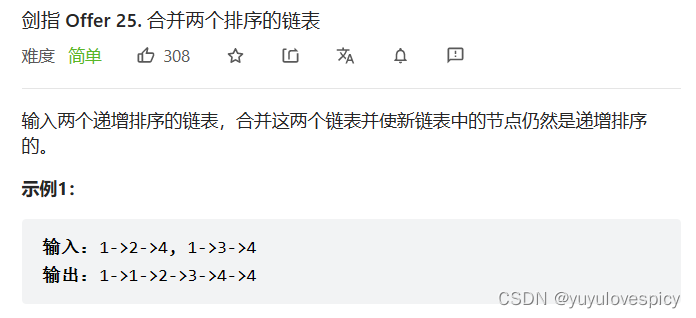
这道题的思路就很简单,就是用两个指针cur1,cur2分别遍历这两个升序链表,每次比较取val小的节点,然后将取到节点尾插到一个新链表plist中。当然我们每次尾插完都可以记录住当前plist的尾节点tail的位置,从而方便我们进行下一次尾插。
1.1 实用小妙招
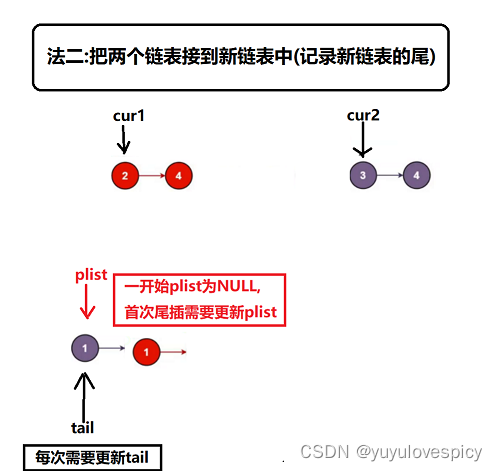
这里介绍一个肥肠肥肠实用的小技巧,我们知道一个普通空链表的尾插,当链表是NULL空的时候,就需要更新head,这样就非常的烦,不能像非空链表的时候那样直接找到尾tail就进行插入来的方便,需要讨论空链表/非空链表两种情况。不仅是尾插,普通单链表的头插也很难受,每次头插完都要更新head,也是炒鸡炒鸡的烦!!!
这时候一个实用小妙招就横空出世了!那就是申请一个哨兵位的头结点!这样不管是头插还是尾插,不管是头删还是尾删,我们都不用做烦琐的讨论空/非空,更新head这些步骤了!这就是哨兵位头结点带给我们的价值。
下面从我们书写的两套代码上看一下哨兵位头结点的优势,不过这里温馨提示,申请的哨兵位头结点记得释放哦~
1.2代码书写
这是没有哨兵位头结点,我们尾插要写的代码是很多的:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {//特殊情况if(l1==nullptr)return l2;if(l2==nullptr)return l1;ListNode* head = nullptr;//分别遍历两个链表,取val较小的节点尾插ListNode* cur1 = l1;ListNode* cur2 = l2;//记录尾节点位置ListNode* tail = head;while(cur1 && cur2){ListNode* getnode = cur2;if(cur1->val <= cur2->val){getnode = cur1; }//把取下来的getnode插入到尾if(head == nullptr){head = getnode;}else{tail->next = getnode;}//更新尾tail = getnode;//更新cur1/cur2if(getnode == cur1){cur1 = cur1->next;}else //getnode==cur2{cur2 = cur2->next;}} //把非空链表剩下的节点插入while(cur1){//尾插if(head == nullptr){head = cur1;}else{tail->next = cur1;} //更新尾&&cur1tail = cur1;cur1 = cur1->next;}while(cur2){//尾插if(head == nullptr){head = cur2;}else{tail->next = cur2;} tail = cur2;cur2 = cur2->next;}return head;}这是有哨兵位头结点的时候:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {//特殊情况if(l1==nullptr)return l2;if(l2==nullptr)return l1;//申请新链表的哨兵位头结点ListNode* head = new ListNode;head->next = nullptr;//分别遍历两个链表,取val较小的节点尾插ListNode* cur1 = l1;ListNode* cur2 = l2;//记录尾节点位置ListNode* tail = head;while(cur1 && cur2){ListNode* getnode = cur2;if(cur1->val <= cur2->val){getnode = cur1; }//把取下来的getnode插入到尾tail->next = getnode;//更新尾tail = getnode;//更新cur1/cur2if(getnode == cur1){cur1 = cur1->next;}else //getnode==cur2{cur2 = cur2->next;}} //把非空链表剩下的节点插入while(cur1){tail->next = cur1;//更新尾&&cur1tail = cur1;cur1 = cur1->next;}while(cur2){tail->next = cur2;tail = cur2;cur2 = cur2->next;}ListNode* newhead = head->next;//释放开辟的头结点,返回合并链表的有效头结点delete head;return newhead;}2.链表分割
面试题 02.04. 分割链表 - 力扣(LeetCode)![]() https://leetcode.cn/problems/partition-list-lcci/
https://leetcode.cn/problems/partition-list-lcci/
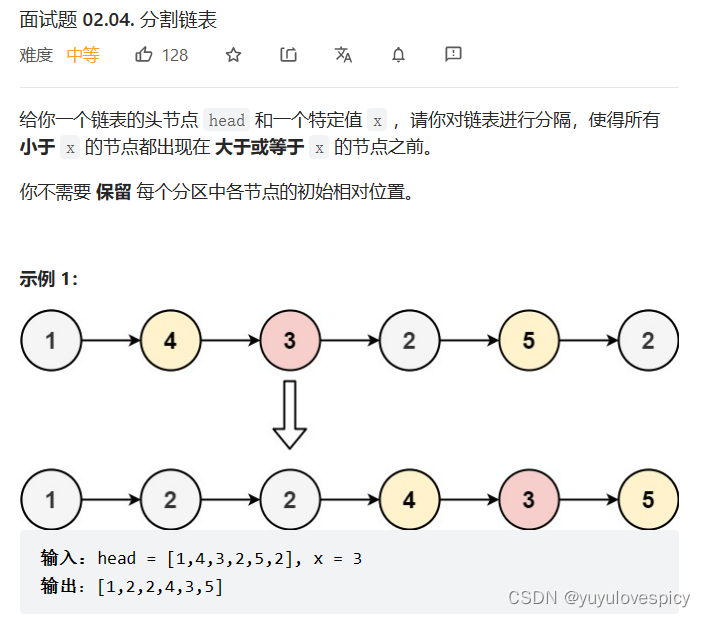
这道题的思路也是相对简单的,我们只要遍历这个链表,把大于x的节点取下来尾插组成一串链表,把小于x的节点取下来组成另一串链表,最后把这两串链表链接起来成为一个新链表即可。所以这需要我们创建两个新链表进行尾插,记录这两个链表的尾tail提高效率,方便尾插,同时为了更加方便的尾插,我们还是选用创建哨兵位头结点的方法进行插入。
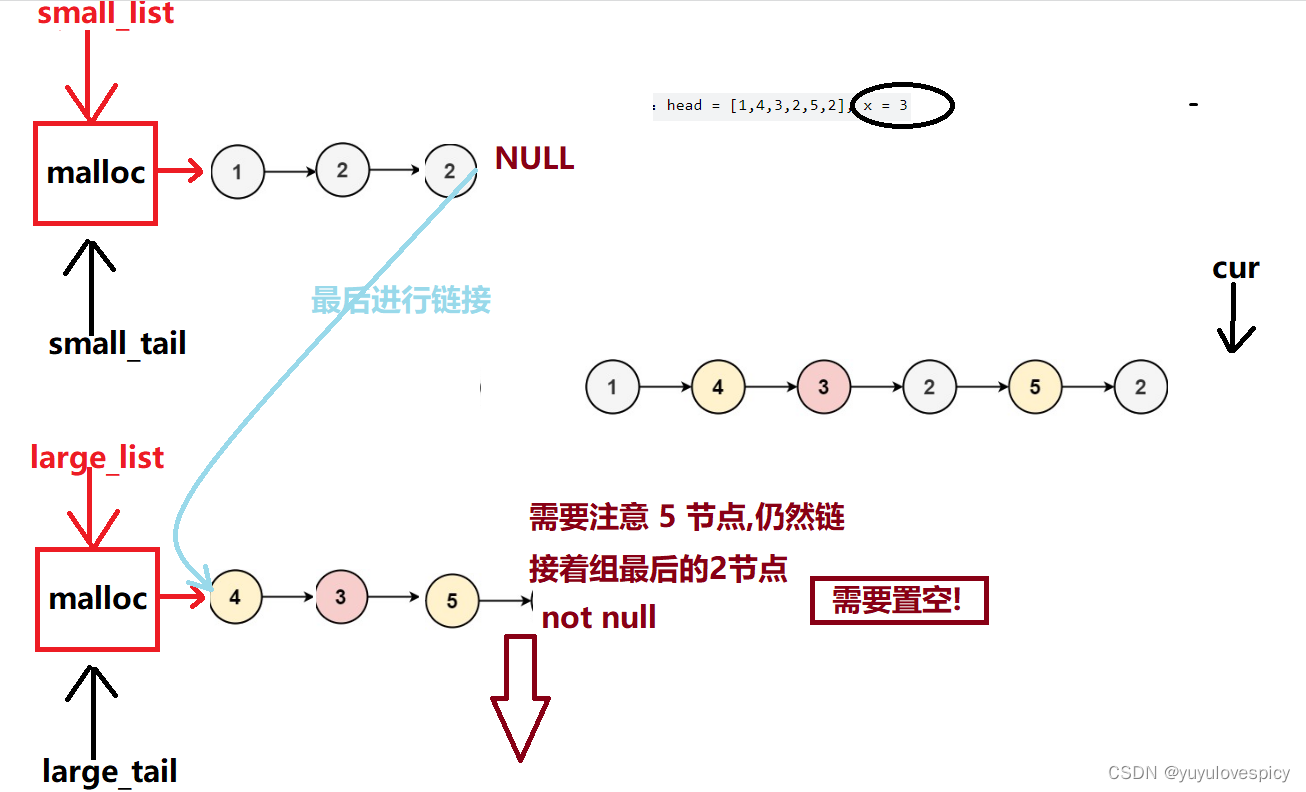
ListNode* partition(ListNode* head, int x) {//特殊情况if(head==nullptr)return nullptr;//收集插入小于x的节点的small链表ListNode* small_head = new ListNode;ListNode* small_tail = small_head;//收集插入大于x的节点的large链表ListNode* large_head = new ListNode;ListNode* large_tail = large_head;//遍历原链表ListNode* cur = head;while(cur){ListNode* cur_next = cur->next;if(cur->val<x){//尾插到small链表中small_tail->next = cur;cur->next = nullptr;small_tail = cur;}else //cur->val >= x{//尾插到large链表中large_tail->next = cur;cur->next = nullptr;large_tail = cur;}//迭代更新cur = cur_next;}//记录有效首节点ListNode* real_small = small_head->next;ListNode* real_large = large_head->next;//释放哨兵位头节点delete small_head;delete large_head;//链接两个链表//需要讨论特殊情况,real_small为空if(real_small == nullptr)return real_large;//else 不是空small_tail->next = real_large;return real_small;}这道题有一个非常坑的地方,也就是我们在遍历原链表的过程中,当我们取下的节点进行尾插的时候,这时候你这个取下的节点其实还是链接着原来链表的!!!这就很危险了,所以当我们取下来的节点cur,要对其next置空,使之与原链表分离!!!
3.链表的回文结构
剑指 Offer II 027. 回文链表 - 力扣(LeetCode)![]() https://leetcode.cn/problems/aMhZSa/
https://leetcode.cn/problems/aMhZSa/

检查是回文结构,比如我们检查一个字符串是否为回文字符串,我们通常是一个begin头指针,一个end尾指针,begin++从头走,end--从尾走,依次对照检查str[begin]和str[end]是否相等。一直检测到begin和end相遇。
然而单链表有个致命的缺陷,单链表只能往前找,而不能往后找,即cur只能找到后面的节点next,而不能找到cur的前一个节点prev。
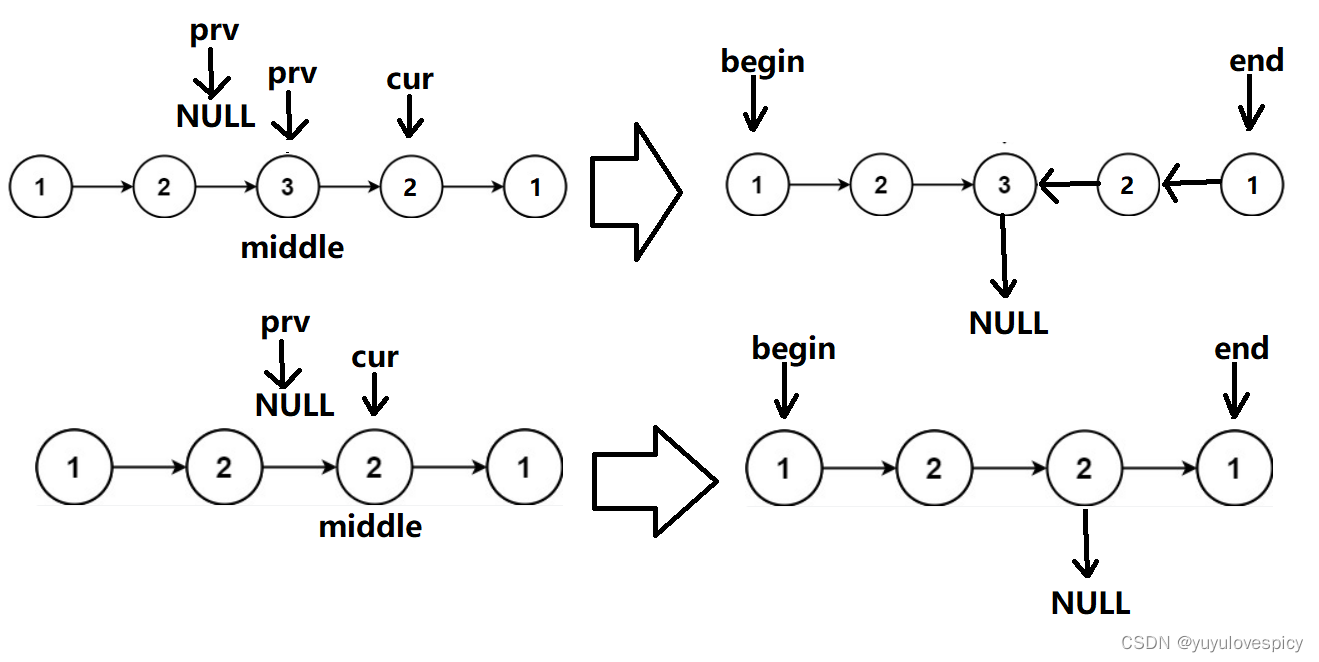
见招拆招,我们不妨改变链表的结构,把从middle中间节点到end尾节点这一段区间的节点,进行反转!然后我们就可以定义begin从head出发,end从尾节点出发,就可以同时向middle节点找,依次对照即可,一直检测到走到middle中间节点。
那我们如何取到链表的中间节点middle呢?那我们如何对一个链表进行反转呢?这两个问题我们在这边博客中做了详细的讲解:(13条消息) 一网打尽链表的经典OJ题!链表必考笔试题第一弹_yuyulovespicy的博客-CSDN博客
https://blog.csdn.net/qq_63992711/article/details/128627158?spm=1001.2014.3001.5502下面我们简述一下注意事项:
如果链表是奇数个节点,那Middle中间节点就是唯一的最中间的节点;如果是偶数个节点,那Middle中间节点是有两个,我们默认取偏后的那个中间节点。例如我们至于如何取到中间节点我们使用的快慢指针法。
当然这里我们选择的是把middle->next置空,如果是奇数个节点,那begin链表和end链表是一样长的,如果偶数个节点,那end链表和begin链表来说,end链表是较短的那个。所以我们循环的终止条件是end走到空。
bool isPalindrome(ListNode* head) {//特殊情况if(head==nullptr)return true;if(head->next==nullptr)return true;//1.找到中间节点ListNode* fast = head;ListNode* slow = head;//fast走到尾/空,此时slow所处位置为中间节点while(fast && fast->next){fast = fast->next->next;slow = slow->next;}ListNode* middle = slow;//2.反转从middle到end这段链表//记录前节点的位置ListNode* prv = nullptr;ListNode* cur = middle;while(cur){ListNode* cur_next = cur->next;//改变链接关系反转cur->next = prv;//迭代到下一个节点prv = cur;cur = cur_next;}ListNode* end = prv;ListNode* begin = head;//3.end-middle,begin-middle,进行回文检查while(end){if(begin->val!=end->val){return false;}//更新迭代begin = begin->next;end = end->next;}return true;}4.相交链表
面试题 02.07. 链表相交 - 力扣(LeetCode)![]() https://leetcode.cn/problems/intersection-of-two-linked-lists-lcci/
https://leetcode.cn/problems/intersection-of-two-linked-lists-lcci/
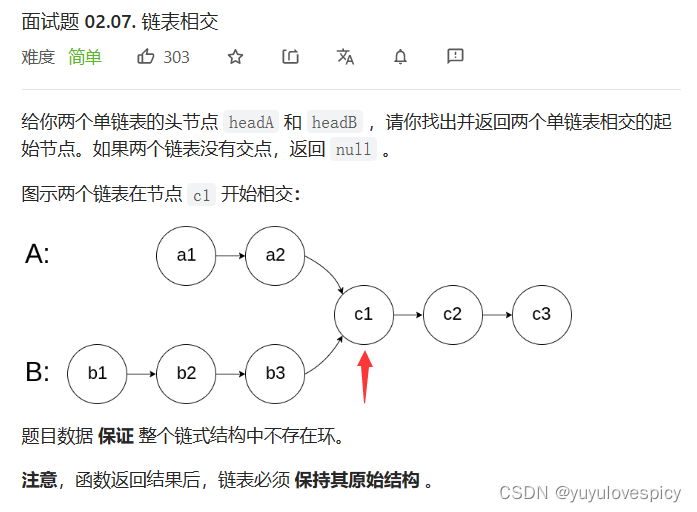
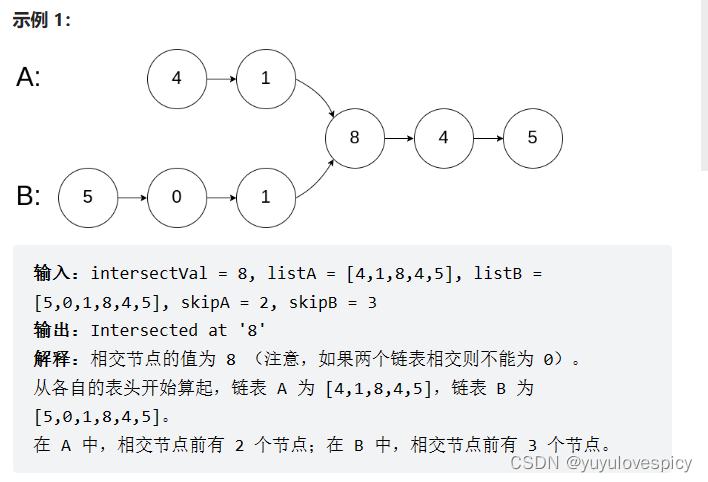
这道题,其实分为两个小问,第一个问题是判断headA和headB这两个链表是相交的还是不相交的,第二个问题是如果headA和headB是相交的,那就需要求出相交的起始节点。
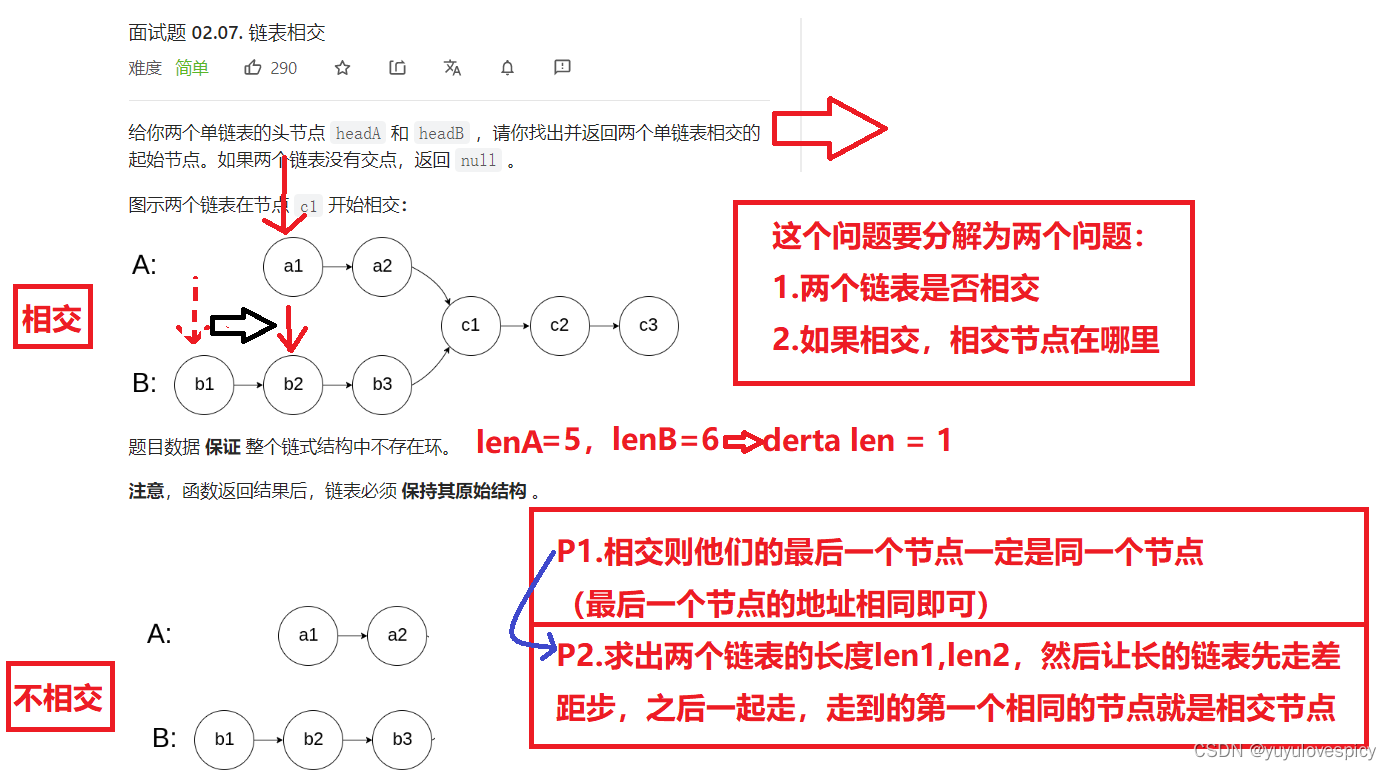
1.判断是否是相交链表:我们知道,如果两个链表相交,那两个链表的最后一个节点一定是相同的。故我们只需要让两个链表都走到最后一个节点,如果两个节点是相等的,那就是相交链表,如果最后的尾节点的不一样,那这两个链表肯定不相交。
2.若相交,我们可以分别求出两个链表的长度len1和len2,然后让长度较长的链表先走差距步abs(len1 - len2),之后两个链表再同时走,此时他们第一个相等的节点,就是起始相交节点的位置。
注意:判断两个节点是否是相同的节点,比较的是两个节点的地址/指针,而不是两个节点的成员Val是否相等。地址/指针才是一个节点的唯一性标识。
4.1 实用小妙招(假定指针法)
我们这里让长的链表先走差距步abs(len1-len2),然而是链表A长,还是链表B长,这个是不确定的,我们当然可以这样直接分类讨论:
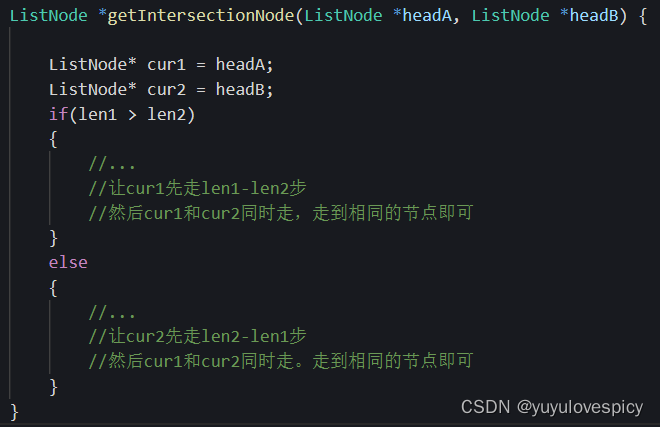
但是这样就很容易造成代码的冗余!!!如下所示:
//此时是相交链表:ListNode* cur1 = headA;ListNode* cur2 = headB;if(len1 > len2){int dertalen = len1-len2;while(dertalen--){cur1 = cur1->next;}while(cur1!=cur2){cur1 = cur1->next;cur2 = cur2->next;}}else //len2 >= len1{int dertalen = len2-len1;while(dertalen--){cur2 = cur2->next;}while(cur1!=cur2){cur1 = cur1->next;cur2 = cur2->next;}}return cur1;所以我们这里祭出一个超级棒的实用小妙招!我称之为:假定指针法,我们可以设计两个指针,一个的名字叫long_list,一个叫short_list,先假定long_list指向的headA是长链表,short_list指向的headB是长链表,然后我们再比对len1和len2的大小进行修正。
这样我们就不用管long_list,short_list具体指向的是headA链表还是headB链表,也不用管你具体是headA链表长还是headB链表长了,反正long_list指针指向的肯定是长链表,short_list指针指向的肯定是短链表。通过假定指针法,所以我们就分别区分出长/短链表,然后直接让long_list这个指针指向的长链表实体走差距步就可以了!同时也不用造成代码的冗余了。
4.2代码书写
具体代码如下图所示:
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {if(headA==NULL || headB==NULL)return NULL;//1.检查是否相交(在这个过程中顺便算出两个链表的长度)struct ListNode* curA = headA;struct ListNode* curB = headB;int lenA = 1;int lenB = 1;while(curA->next){curA = curA->next;++lenA;}while(curB->next){curB = curB->next;++lenB;}//最后一个节点不同,两链表不相交if(curA!=curB)return NULL;//2.下面是相交的情况//2.1 算出两个链表长度lenA,lenB,差距步derta_lenint derta_len = abs(lenA-lenB);//2.2 让长链表走差距步//PS:首先假设一个长,然后进行检查修改,可以防止代码冗余struct ListNode* long_list = headA;struct ListNode* short_list = headB;if(lenA<lenB){long_list = headB;short_list = headA;}while(derta_len--){long_list = long_list->next;}//2.3让一起走,走到第一个相同的节点即为相交节点while(long_list!=short_list){long_list = long_list->next;short_list = short_list->next;}return long_list;
}5. 复制带随机指针的链表
138. 复制带随机指针的链表 - 力扣(LeetCode)![]() https://leetcode.cn/problems/copy-list-with-random-pointer/
https://leetcode.cn/problems/copy-list-with-random-pointer/

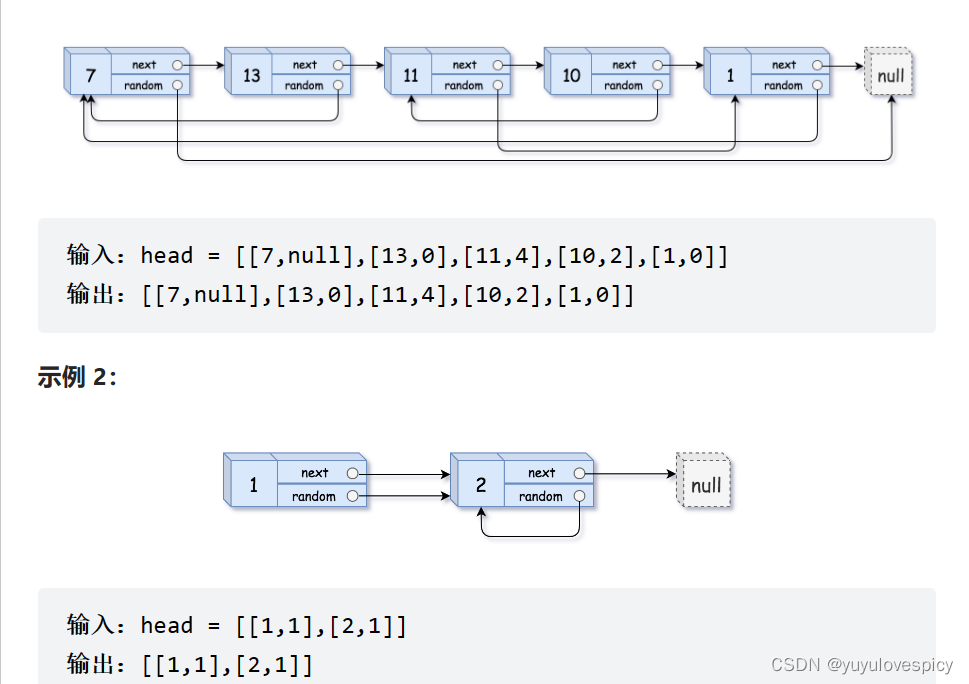
这道题说白了就是拷贝一份完全相同的如图所示的链表,只不过这个链表的节点,不仅有一个常见的next指针,还有一个random指针,随机指向链表中的任一个节点。
如果给我们一个普通的单链表进行拷贝(如下图),那就非常简单了,我们就可以遍历这个链表, 根据遍历到的节点的val,依次创建新节点,然后依次把新节点链接起来。

如果节点只有next这个链接关系处理,那这的确是非常简单的!可是我们这个题每个节点都有一个random指针,这个关系是很难处理的!因为我们是依次遍历,依次创建,原链表的任意两个节点的random关系的链接,在新链表当中,对应的两个节点的random指针关系很难找到对应的节点!这就是本题的难点。(不信你可以创建一个试一试,你如果头铁创建一个新链表,是无法直接把random关系进行复刻的)
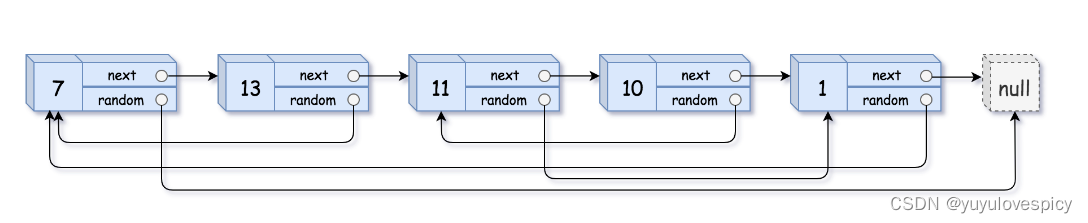
我们很难根据原来链表的random关系,直接将新链表的random关系链接出来。这是因为我们新链表的两两节点和旧链表的两两节点之间很难建立一种联系。
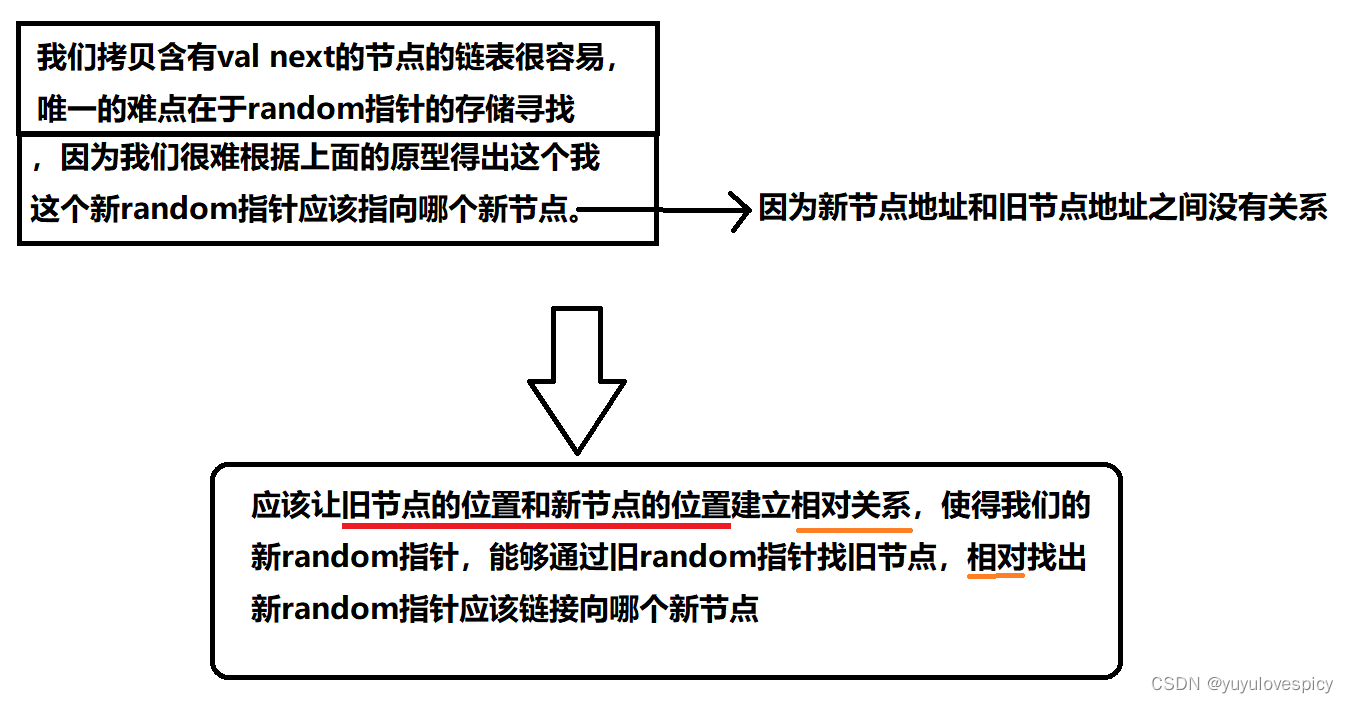
有人便提出了一个很厉害的方法:首先在给定的链表中,在原链表的每个节点的后面,创建与之对应的节点,然后这样 旧节点->新节点->旧节点->新节点->... 这种方式进行链接。
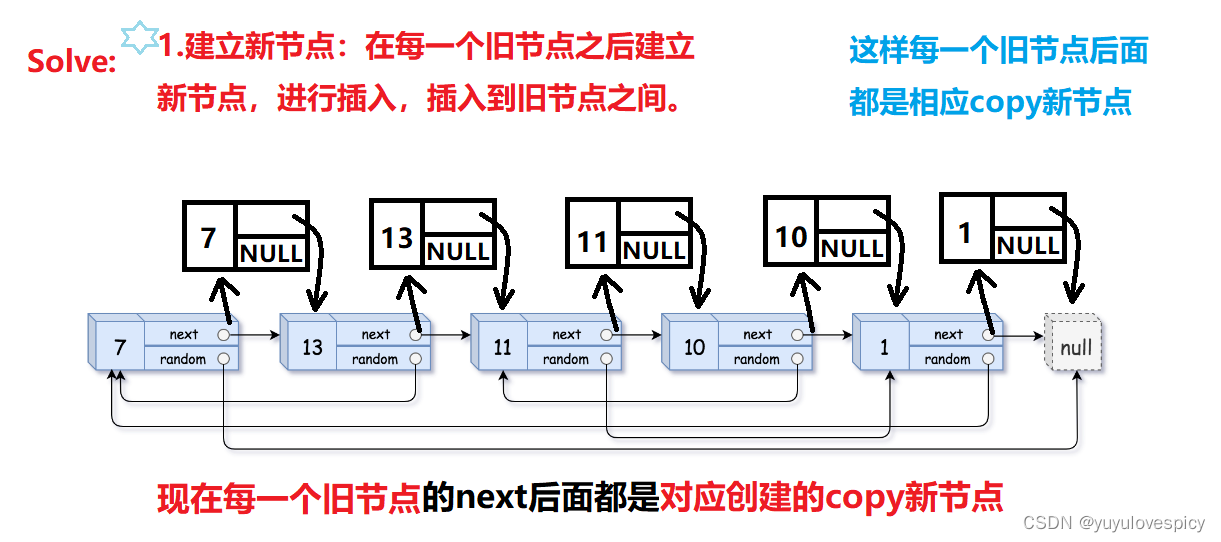
这样我们就建立好了旧节点和新节点的关系,每个旧节点的后面都是对应的创建的新节点!
下一步我们就可以根据这个对应关系,处理所有新节点的random关系了!我们现在假设任意两个旧节点是random相链接的,然后两个旧节点的next就是对应的两个新节点,我们就可以处理这两个新节点的random链接关系了!按照这个思路我们就可以把所有新节点的random关系全部复刻!

处理好random关系,下一步我们就是拆解链表,分离新旧节点,把新节点链接起来,形成新链表,即为拷贝出来的新链表。
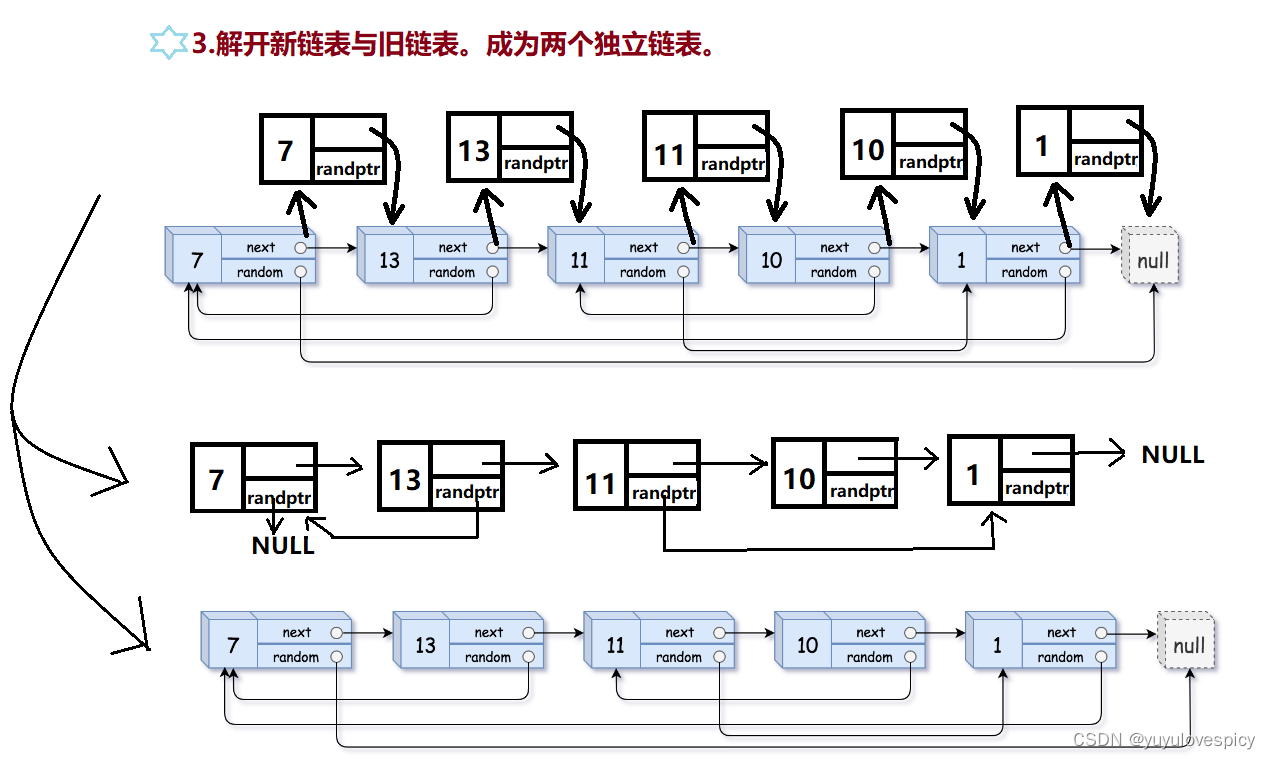
把这三个步骤综合起来,我们得到如下代码:
Node* copyRandomList(Node* head) {//1.在原链表的每个节点后面依次创建出对应的新链表的节点Node* cur = head;while(cur){//记录下一个原链表的nextNode* cur_next = cur->next;//创建新节点在旧节点之后Node* copycur = new Node(0);copycur->val = cur->val;copycur->random = nullptr;//新节点链接到原链表cur->next = copycur;copycur->next = cur_next;//迭代更新cur = cur_next;}//2.根据旧节点->对应新节点的关系,根据旧节点的random关系,链接新节点的random关系cur = head;while(cur){Node* copycur = cur->next;Node* cur_rand_node = cur->random;//copycur节点的random节点Node* copycur_rand_node = nullptr;//如果random指向的是空null,则需单独处理if(cur_rand_node == nullptr){copycur->random = nullptr;}else //random节点是非空{//copy节点的random所应指向的新节点,应该在旧节点random节点的后面next。copycur_rand_node = cur_rand_node->next;//新节点的random关系处理copycur->random = copycur_rand_node;}cur = cur->next->next;}//3.分解链表,实现新旧链表的分离//哨兵位头结点方便进行尾插Node* copyhead = new Node(0);copyhead->next = nullptr;copyhead->random = nullptr;Node* copytail = copyhead;cur = head;while(cur){Node* cur_next = cur->next->next;Node* copy_cur = cur->next;//分解,把新节点从原链表中取下尾插新链表copytail->next = copy_cur;copy_cur->next = nullptr;//更新copytailcopytail = copy_cur;//原链表节点的链接关系恢复cur->next = cur_next;//更新迭代cur = cur_next;}Node* real_copy_head = copyhead->next;//释放处理哨兵位头结点delete copyhead;return real_copy_head;}