曾经有个沃尔玛超市,它将啤酒与尿布这样两个奇怪的东西放在一起进行销售,并且最终让啤酒与尿布这两个看起来没有关联的东西的销量双双增加。
我们关注的是在这样的场景下,如何找出物品之间的关联规则。接下来就来介绍下如何使用Apriori算法,来找到物品之间的关联规则。
1. 关联分析概述
我们先举个超市交易记录如下:
| 交易序号 | 交易商品 |
|---|---|
| 0 | ‘牛奶’,‘洋葱’,‘肉豆蔻’,‘芸豆’,‘鸡蛋’,‘酸奶’ |
| 1 | ‘莳萝’,‘洋葱’,‘肉豆蔻’,‘芸豆’,‘鸡蛋’,‘酸奶’ |
| 2 | ‘牛奶’,‘苹果’,‘芸豆’,‘鸡蛋’ |
| 3 | ‘牛奶’,‘独角兽’,‘玉米’,‘芸豆’,‘酸奶’ |
| 4 | ‘玉米’,‘洋葱’,‘洋葱’,‘芸豆’,‘冰淇淋’,‘鸡蛋’ |
关联分析的几个概念:
- 支持度(Support):支持度可以理解为物品当前流行程度。计算方式是:
支持度 = (包含物品A的记录数量) / (总的记录数量)
用上面的超市记录举例,一共有五个交易,牛奶出现在三个交易中,故而{牛奶}的支持度为3/5。{鸡蛋}的支持度是4/5。牛奶和鸡蛋同时出现的次数是2,故而{牛奶,鸡蛋}的支持度为2/5。
support(A⇒B)=support_count(A∪B)/N
支持度反映了A和B同时出现的概率,关联规则的支持度等于频繁集的支持度。
- 置信度(Confidence):置信度是指如果购买物品A,有较大可能购买物品B。计算方式是这样:
置信度( A -> B) = (包含物品A和B的记录数量) / (包含 A 的记录数量)
举例:我们已经知道,(牛奶,鸡蛋)一起购买的次数是两次,鸡蛋的购买次数是4次。那么Confidence(牛奶->鸡蛋)的计算方式是Confidence(牛奶->鸡蛋)=2 / 4。
confidence(A⇒B)=support_count(A∪B)/support_count(A)
置信度反映了如果交易中包含A,则交易包含B的概率。也可以称为在A发生的条件下,发生B的概率,成为条件概率。
- 提升度(Lift):提升度指当销售一个物品时,另一个物品销售率会增加多少。计算方式是:
提升度( A -> B) = 置信度( A -> B) / (支持度 A)
举例:上面我们计算了牛奶和鸡蛋的置信度Confidence(牛奶->鸡蛋)=2 / 4。牛奶的支持度Support(牛奶)=3 / 5,那么我们就能计算牛奶和鸡蛋的支持度Lift(牛奶->鸡蛋)=0.83,当提升度(A->B)的值大于1的时候,说明物品A卖得越多,B也会卖得越多。而提升度等于1则意味着产品A和B之间没有关联。最后,提升度小于1那么意味着购买A反而会减少B的销量。
2. Apriori算法概述
Apriori算法是发现频繁项集的一种方法。并不会找出关联规则,关联规则需要在找到频繁项集以后我们再来统计。
频繁项集:频繁项集挖掘是数据挖掘研究课题中一个很重要的研究基础,它可以告诉我们在数据集中经常一起出现的变量,为可能的决策提供一些支持。频繁项集挖掘是关联规则、相关性分析、因果关系、序列项集、局部周期性、情节片段等许多重要数据挖掘任务的基础。
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。
最小支持度:最小支持度就是人为规定的阈值,表示项集在统计意义上的最低重要性。 最小置信度:最小置信度也是人为规定的阈值,表示关联规则最低可靠性。 只有支持度与置信度同时达到了最小支持度与最小置信度,此关联规则才会被称为强规则。 频繁项集:满足最小支持度的所有项集,称作频繁项集。 频繁项集性质:1、频繁项集的所有非空子集也为频繁项集;2、若A项集不是频繁项集,则其他项集或事务与A项集的并集也不是频繁项集)
要想获得频繁项集,最简单直接的方法就是暴力搜索法,但是这种方法计算量过于庞大,如下图所示,k项的数据集可能生成 2 k − 1 2^k-1 2k−1个频繁项集。
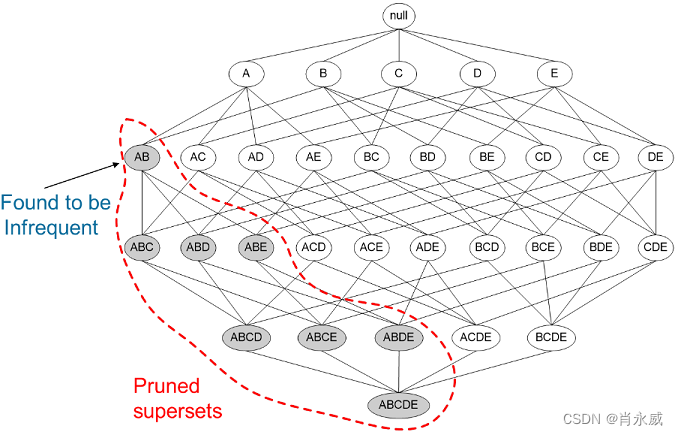
先验原理,由于直接暴力搜索不可行,因此我们要利用支持度对数据集进行剪枝。
- Apriori定律1:如果一个集合是频繁项集,则它的所有子集都是频繁项集。
- Apriori定律2:如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
如图所示,我们发现{A,B}这个项集是非频繁的,那么{A,B}这个项集的超集,{A,B,C},{A,B,D}等等也都是非频繁的,这些就都可以忽略不去计算。
运用Apriori算法的思想,我们就能去掉很多非频繁的项集,大大简化计算量。
Apriori算法流程
要使用Apriori算法,我们需要提供两个参数,数据集和最小支持度。我们从前面已经知道了Apriori会遍历所有的物品组合,怎么遍历呢?答案就是递归。
- 先遍历1个物品组合的情况,剔除掉支持度低于最小支持度的数据项,然后用剩下的物品进行组合。
- 遍历2个物品组合的情况,再剔除不满足条件的组合。
- 不断递归下去,直到不再有物品可以组合。
3. mlxtend-强大的机器学习扩展包
mlxtend是一款基于python的机器学习扩展包,其本身使用非常简介方便自带数据集,同时也作为sklearn的一个补充和辅助工具。
它可以非常简单高效的利用堆栈泛化来构建更具预测性的模型,让我们能够快速组装堆叠回归器的库。集成了从数据到特征选择、建模(分类、聚类、图形图像,文本)、验证、可视化整个一套完整的workflow。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple mlxtend
3.1. apriori函数
从一个one-hot集中获取频繁项目集,支持度。
apriori(df, min_support=0.5, use_colnames=False, max_len=None)
参数如下:
- df:这个不用说,就是我们的数据集。
- min_support:给定的最小支持度。
- use_colnames:默认False,则返回的物品组合用编号显示,为True的话直接显示物品名称。
- max_len:最大物品组合数,默认是None,不做限制。如果只需要计算两个物品组合的话,便将这个值设置为2。
3.2. 关联规则函数
association_rules函数,语法:
association_rules(df, metric=‘confidence’, min_threshold=0.8, support_only=False)
参数如下:
- df: pandas模块中的数据帧,DataFrame形式的数据;
- metric: 用于评估规则是否有意义的度量。可选参数有以下几种:‘support’, ‘confidence’, ‘lift’, 'leverage’和 ‘conviction’
- min_threshold: 评估度量的最小阈值,通过度量参数确定候选规则是否有意义。
- support_only : 只计算规则支持并用 NaN 填充其他度量列。如果: a)输入 DataFrame 是不完整的,例如,不包含所有规则前因和后果的支持值 b)你只是想加快计算速度,因为你不需要其他度量。
4. 实验小案例
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori#设置数据集
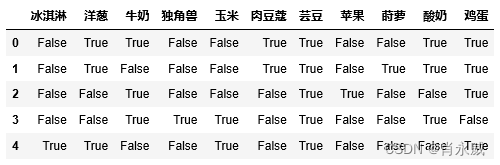
dataset = [['牛奶','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],['莳萝','洋葱','肉豆蔻','芸豆','鸡蛋','酸奶'],['牛奶','苹果','芸豆','鸡蛋'],['牛奶','独角兽','玉米','芸豆','酸奶'],['玉米','洋葱','洋葱','芸豆','冰淇淋','鸡蛋']]te = TransactionEncoder()
#进行 one-hot 编码
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
df
#利用 Apriori 找出频繁项集
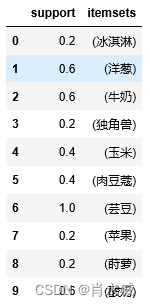
freq = apriori(df, min_support=0.05, use_colnames=True)
freq.head(10)
#导入关联规则包
from mlxtend.frequent_patterns import association_rules
#计算关联规则
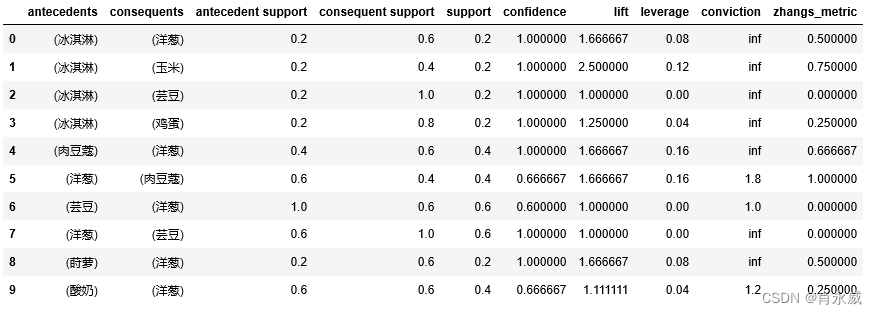
result = association_rules(freq, metric="confidence", min_threshold=0.6)
result.head(10)
5. 总结
关联规则挖掘是一种基于规则的机器学习算法,该算法可以在大数据库中发现感兴趣的关系。它的目的是利用一些度量指标来分辨数据库中存在的强规则。也即是说关联规则挖掘是用于知识发现,而非预测,所以是属于无监督的机器学习方法。
关联规则挖掘可以让我们从数据集中发现项与项(item与item)之间的关系,它在我们的生活中有很多应用场景,“购物篮分析”就是一个常见的场景,这个场景可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。
参考:
zzzzMing. Python --深入浅出Apriori关联分析算法(一). 博客园. 2019.08
翻滚的小@强. 白话机器学习算法理论+实战之关联规则. CSDN博客. 2020.02
https://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
https://rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/