目录
- 一、哈希
- 1.1哈希--开散列
- 1.2哈希--闭散列
- 1.3哈希的优化
- 二、unordered_set、unordered_map
- 2.1unordered_set、unordered_map的框架搭建
- 2.2unordered_set、unordered_map的迭代器
- 2.2.1普通迭代器的构造
- 2.2.2普通迭代器的封装
- 2.2.3unordered_set普通迭代器的封装
- 2.2.4unordered_map普通迭代器的封装
- 2.3unordered_set、unordered_map的Key不能被修改
- 2.3.1const迭代器的构造
- 2.3.2const迭代器的封装
- 2.3.3unordered_set的const迭代器的封装
- 2.3.4unordered_map的const迭代器的封装
- 2.4unordered_map的[]重载
一、哈希
哈希思想是将存储的数据与存储位置建立一种关系,这样可以不经过任何比较,一次直接从表中得到要搜索的元素。大大的提高的搜索的效率。大致的思路如下图:
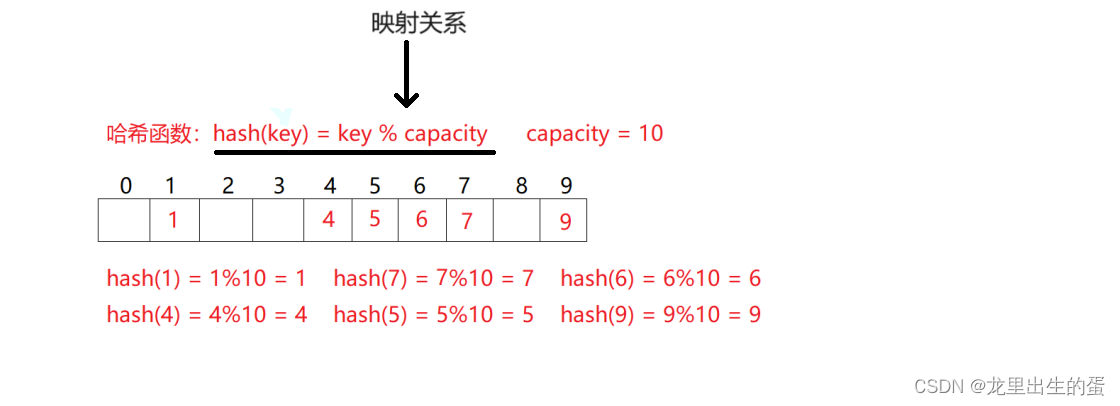
哈希冲突:
上图只是一种理想情况,实际上可能会出现下面的情况。如图:
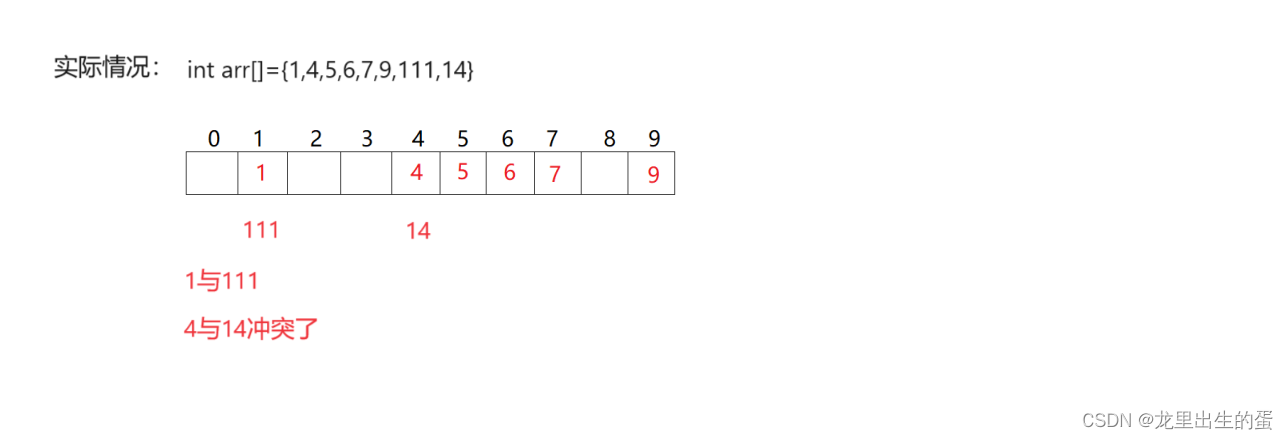
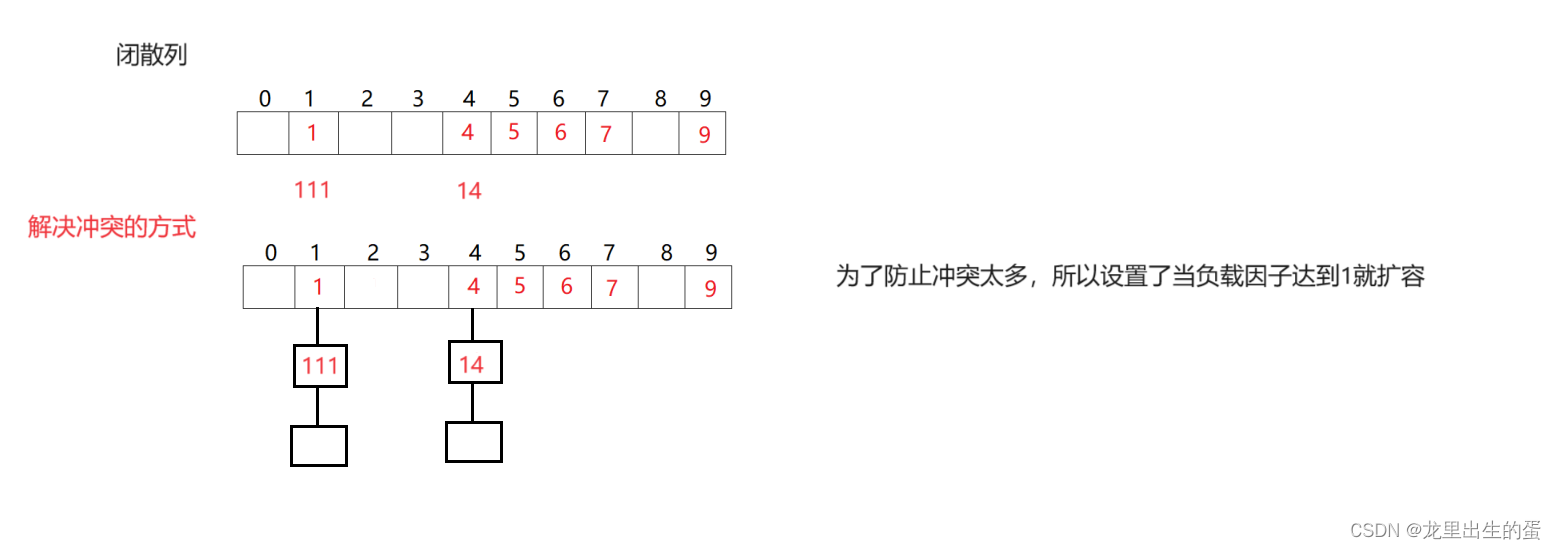
为了解决哈希冲突,许多大佬想到了很多解决哈希冲突的办法。下面放了两个最常用解决哈希冲突的方法,
开散列与闭散列。
1.1哈希–开散列

代码实现:
#include<iostream>
using namespace std;
#include<vector>
//开放地址
namespace open_address
{enum STATE{EXIST,EMPTY,DELETE};template<class K,class V>struct HashDate{pair<K, V> _kv;STATE _st=EMPTY;};template<class K,class V>class HashTable{public:HashTable(){_ht.resize(10);}bool insert(const pair<K, V>& kv){if (find(kv.first)){return false;}//扩容 负载因子大于0.7扩容if (_n * 10 / _ht.size() >= 7){HashTable<K, V> newtable;newtable._ht.resize(_ht.size() * 2);for (size_t i = 0; i < _ht.size(); i++){newtable.insert(_ht[i]._kv);}_ht.swap(newtable._ht);}size_t hashi = kv.first % _ht.size();while (_ht[hashi]._st == EXIST){hashi++;hashi %= _ht.size();}_ht[hashi]._kv = kv;_ht[hashi]._st = EXIST;_n++;return true;}HashDate<const K,V>* find(const K& key){size_t hashi = key % _ht.size();while (_ht[hashi]._st != EMPTY){if (_ht[hashi]._kv.first == key){return (HashDate<const K, V>*) & _ht[hashi];}hashi++;}return nullptr;}bool erase(const K& key){HashDate<const K, V>* ret = find(key);if (ret){ret->_st = DELETE;--_n;return true;}return false;}private:vector<HashDate<K,V>> _ht;size_t _n = 0;//有多少个数据};
}
上面的代码并没有对string类型处理,下面会优化
1.2哈希–闭散列
代码实现:
namespace hash_bucket
{template<class K,class V>struct HashNode{HashNode(const pair<K, V>& kv):_kv(kv){}pair<K, V> _kv;HashNode<K, V>* _next=nullptr;};template<class K,class V>class HashTable{typedef HashNode<K, V> Node;public:HashTable(){_ht.resize(10, nullptr);}bool insert(const pair<K, V>& kv){//扩容 负载因子达到1就扩容if (_n == _ht.size()){size_t newsize = _ht.size() * 2;HashTable<K, V> newtable;newtable._ht.resize(newsize);for (size_t i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % newsize;//cur头插入新链表cur->_next = newtable._ht[hashi];newtable._ht[hashi] = cur;cur = next;}}_ht.swap(newtable._ht);}size_t hashi = kv.first % _ht.size();Node* newnode = new Node(kv);newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_n;return true;}Node* find(const K& key){size_t hashi = key % _ht.size();Node* cur = _ht[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool erase(const K& key){Node* pre = nullptr;if (find(key) == nullptr){return false;}size_t hashi = key % _ht.size();Node* cur = _ht[hashi];while (cur){if (cur->_kv.first == key){if (pre == nullptr){//头删delete cur;_ht[hashi] = nullptr;}else{Node* next = cur->_next;pre->_next = next;delete cur;}return true;}pre = cur;cur = cur->_next;}}void Print(){for (size_t i = 0; i < _ht.size(); i++){cout << "[" << i << "]"<< "->";Node* cur = _ht[i];while (cur){cout << cur->_kv.first<<"->";cur = cur->_next;}cout << "nullptr" << endl;}}private:vector<Node*> _ht;size_t _n;};
}
上面的代码并没有对string类型处理,下面会优化
1.3哈希的优化
上面的代码均不能实现对字符串的查找,而现实生活中很多情况下都是对字符串的查找。所以下面要解决这一问题。
模板参数加上个HashFunc即可。
template<class K>
struct DefaultHashFunc
{//防止负数取模size_t operator()(const K& key){return (size_t)key;}
};//模板特化
template<>
struct DefaultHashFunc<string>
{//针对字符串size_t operator()(const string& str){size_t ret = 0;for (auto ch : str){ret *= 131;ret += ch;}return ret;}
};
二、unordered_set、unordered_map
注:下面unordered_set、unordered_map底层都是用到上面hash_bucket。
2.1unordered_set、unordered_map的框架搭建
首先要解决的第一个问题就是key,Val的问题。因为unordered_set只有一个模板参数,而unordered_map有两个。所以要对hash桶进行改造。不能采用K,V形式,要采用K,T形式。当T以K传过来就unordered_set,当T以pair<K,V>传过来就是unordered_map。为此呢还需要写个KeyOfT的仿函数。

unordered_set.h代码
#pragma once
#include"hashtable.h"namespace Ting
{template<class K>class unordered_set{public:struct SetKeyOfT{const K& operator()(const K& key){return key;}};bool insert(const K& key){return _ht.insert(key);}void Print(){_ht.Print();}private:hash_bucket::HashTable<K, K,SetKeyOfT> _ht;};
}
unordered_map.h代码
#pragma once
#include"hashtable.h"namespace Ting
{template<class K,class V>class unordered_map{public:struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};bool insert(const pair<K, V>& kv){return _ht.insert(kv);}void Print(){_ht.Print();}private:hash_bucket::HashTable<K, pair<K,V>, MapKeyOfT> _ht;};
}
2.2unordered_set、unordered_map的迭代器
2.2.1普通迭代器的构造
按照正常的写法我们发现写到这里已经写不下去了。如图:
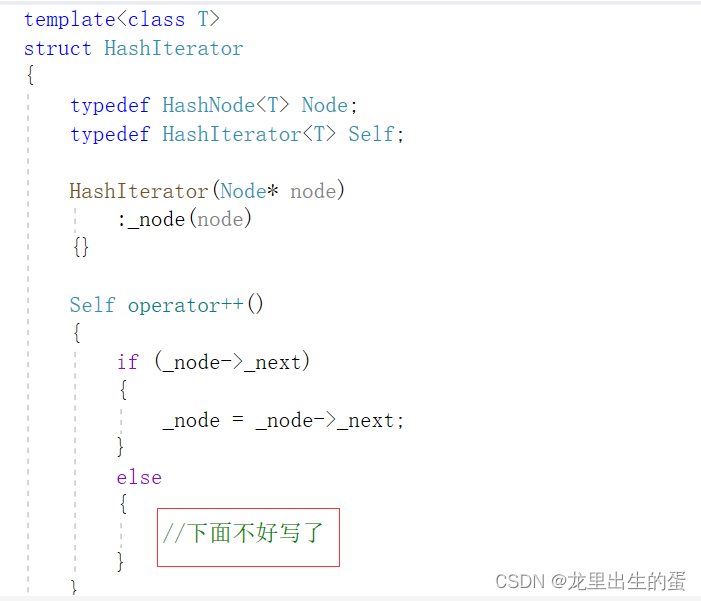
最好还是要传个hashtable的指针过来,所以可以这么玩。
template<class K, class T, class KeyOfT, class HashFunc>
struct HashIterator
{typedef HashNode<T> Node;typedef HashIterator<K,T,KeyOfT,HashFunc> Self;typedef HashTable<K, T, KeyOfT, HashFunc> HashTable;HashIterator(Node* node, HashTable* hptr):_node(node), _hptr(hptr){}Self operator++(){if (_node->_next){_node = _node->_next;}else{//下面不好写了HashFunc hf;KeyOfT kot;size_t hashi = hf(kot(_node->_date)) % _hptr->_ht.size();hashi++;while (hashi < _hptr->_ht.size() && _hptr->_ht[hashi] == nullptr){++hashi;}if (hashi == _hptr->_ht.size()){_node = nullptr;}else{_node = _hptr->_ht[hashi];}}return *this;}T* operator->(){return &(_node->_date);}T& operator*(){return _node->_date;}bool operator!=(Node* node){return _node != node;}Node* _node;HashTable* _hptr;
};
但是这么写会编译不通过。原因是我们传了个HashTable的指针过去,而编译器在编译的时候是自上往下编译,编译器不清楚Hashtable是什么,要提前申明下。

2.2.2普通迭代器的封装
template<class K,class T,class KeyOfT,class HashFunc=DefaultHashFunc<K>>class HashTable{typedef HashNode<T> Node;public:typedef HashIterator<K, T, KeyOfT, HashFunc> iterator;iterator begin(){size_t i = 0;while (i < _ht.size() && _ht[i] == nullptr){++i;}if (i == _ht.size()){return iterator(nullptr, this);}return iterator(_ht[i], this);}iterator end(){return iterator(nullptr, this);}HashTable(){_ht.resize(10, nullptr);}bool insert(const T& date){HashFunc hf;KeyOfT kot;if (find(kot(date))){return false;}//扩容 负载因子达到1就扩容if (_n == _ht.size()){size_t newsize = _ht.size() * 2;HashTable<K,T,KeyOfT,HashFunc> newtable;newtable._ht.resize(newsize);for (size_t i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){Node* next = cur->_next;size_t hashi = hf(kot(cur->_date)) % newsize;//cur头插入新链表cur->_next = newtable._ht[hashi];newtable._ht[hashi] = cur;cur = next;}}_ht.swap(newtable._ht);}size_t hashi = hf(kot(date)) % _ht.size();Node* newnode = new Node(date);newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_n;return true;}Node* find(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _ht.size();Node* cur = _ht[hashi];while (cur){if (kot(cur->_date) == key){return cur;}cur = cur->_next;}return nullptr;}bool erase(const K& key){HashFunc hf;KeyOfT kot;Node* pre = nullptr;if (find(hf(key)) == nullptr){return false;}size_t hashi = hf(key) % _ht.size();Node* cur = _ht[hashi];while (cur){if (kot(cur->_date) == key){if (pre == nullptr){//头删delete cur;_ht[hashi] = nullptr;}else{Node* next = cur->_next;pre->_next = next;delete cur;}return true;}pre = cur;cur = cur->_next;}}void Print(){KeyOfT kot;for (size_t i = 0; i < _ht.size(); i++){cout << "[" << i << "]"<< "->";Node* cur = _ht[i];while (cur){cout << kot(cur->_date) << "->";cur = cur->_next;}cout << "nullptr" << endl;}}//private:vector<Node*> _ht;size_t _n;};}
2.2.3unordered_set普通迭代器的封装
#include"hashtable.h"namespace Ting
{template<class K>class unordered_set{public:struct SetKeyOfT{const K& operator()(const K& key){return key;}};typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::iterator iterator;bool insert(const K& key){return _ht.insert(key);}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}void Print(){_ht.Print();}private:hash_bucket::HashTable<K, K,SetKeyOfT> _ht;};
}
2.2.4unordered_map普通迭代器的封装
#include"hashtable.h"namespace Ting
{template<class K,class V>class unordered_map{public:struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};bool insert(const pair<K, V>& kv){return _ht.insert(kv);}typedef typename hash_bucket::HashTable<K, pair<K, V>, MapKeyOfT>::iterator iterator;bool insert(const K& key){return _ht.insert(key);}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}void Print(){_ht.Print();}private:hash_bucket::HashTable<K, pair<K,V>, MapKeyOfT> _ht;};
}
2.3unordered_set、unordered_map的Key不能被修改
这时候就需要const迭代器,就要考虑到const迭代器的封装
2.3.1const迭代器的构造
这个就是正常操作,与之前写的没什么区别。
代码如下:
//模板的提前申明template<class K, class T, class KeyOfT, class HashFunc>class HashTable;template<class K, class T, class Ptr,class Ref,class KeyOfT, class HashFunc>struct HashIterator{typedef HashNode<T> Node;typedef HashIterator<K, T, Ptr, Ref, KeyOfT, HashFunc> Self;typedef HashTable<K, T, KeyOfT, HashFunc> HashTable;HashIterator(Node* node, HashTable* hptr):_node(node), _hptr(hptr){}Self operator++(){if (_node->_next){_node = _node->_next;}else{//下面不好写了HashFunc hf;KeyOfT kot;size_t hashi = hf(kot(_node->_date)) % _hptr->_ht.size();hashi++;while (hashi < _hptr->_ht.size() && _hptr->_ht[hashi] == nullptr){++hashi;}if (hashi == _hptr->_ht.size()){_node = nullptr;}else{_node = _hptr->_ht[hashi];}}return *this;}Ptr operator->(){return &(_node->_date);}Ref operator*(){return _node->_date;}bool operator!=(const Self& it){return _node != it._node;}Node* _node;HashTable* _hptr;};
2.3.2const迭代器的封装
template<class K,class T,class KeyOfT,class HashFunc=DefaultHashFunc<K>>class HashTable{typedef HashNode<T> Node;public:typedef HashIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;typedef HashIterator<K, T, const T*, const T&, KeyOfT, HashFunc> const_iterator;iterator begin(){size_t i = 0;while (i < _ht.size() && _ht[i] == nullptr){++i;}if (i == _ht.size()){return iterator(nullptr, this);}return iterator(_ht[i], this);}iterator end(){return iterator(nullptr, this);}const_iterator begin() const{size_t i = 0;while (i < _ht.size() && _ht[i] == nullptr){++i;}if (i == _ht.size()){return const_iterator(nullptr, this);}return const_iterator(_ht[i], this);}const_iterator end() const{return const_iterator(nullptr, this);}HashTable(){_ht.resize(10, nullptr);}bool insert(const T& date){HashFunc hf;KeyOfT kot;if (find(kot(date))){return false;}//扩容 负载因子达到1就扩容if (_n == _ht.size()){size_t newsize = _ht.size() * 2;HashTable<K,T,KeyOfT,HashFunc> newtable;newtable._ht.resize(newsize);for (size_t i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){Node* next = cur->_next;size_t hashi = hf(kot(cur->_date)) % newsize;//cur头插入新链表cur->_next = newtable._ht[hashi];newtable._ht[hashi] = cur;cur = next;}}_ht.swap(newtable._ht);}size_t hashi = hf(kot(date)) % _ht.size();Node* newnode = new Node(date);newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_n;return true;}Node* find(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _ht.size();Node* cur = _ht[hashi];while (cur){if (kot(cur->_date) == key){return cur;}cur = cur->_next;}return nullptr;}bool erase(const K& key){HashFunc hf;KeyOfT kot;Node* pre = nullptr;if (find(hf(key)) == nullptr){return false;}size_t hashi = hf(key) % _ht.size();Node* cur = _ht[hashi];while (cur){if (kot(cur->_date) == key){if (pre == nullptr){//头删delete cur;_ht[hashi] = nullptr;}else{Node* next = cur->_next;pre->_next = next;delete cur;}return true;}pre = cur;cur = cur->_next;}}void Print(){KeyOfT kot;for (size_t i = 0; i < _ht.size(); i++){cout << "[" << i << "]"<< "->";Node* cur = _ht[i];while (cur){cout << kot(cur->_date) << "->";cur = cur->_next;}cout << "nullptr" << endl;}}//private:vector<Node*> _ht;size_t _n;};}
但是上面的代码会编译不通过。原因如下图:

所以要对迭代器进行改写,增加个构造函数的重载,再将hashtable的指针变成const类型即可。如:
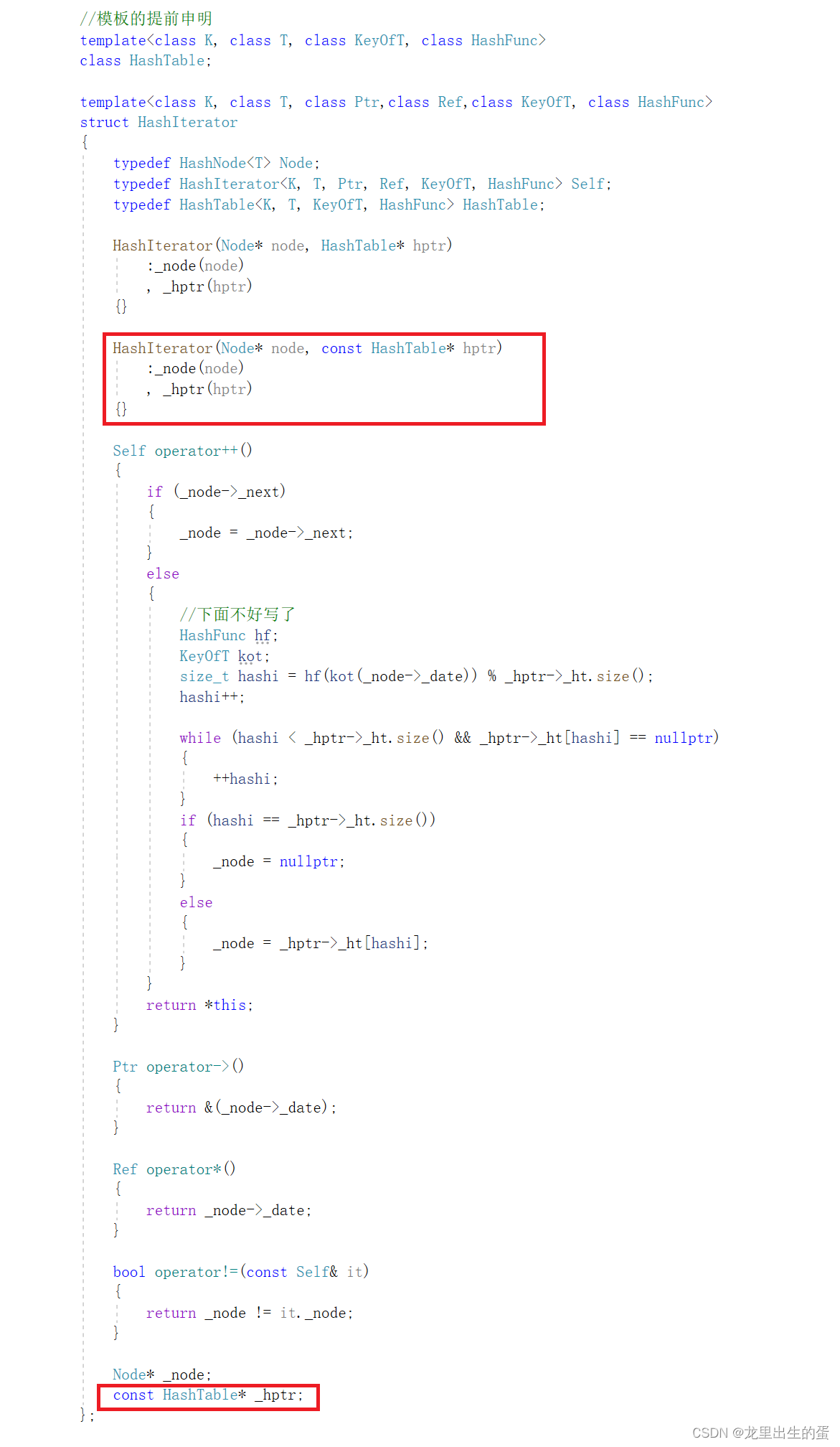
2.3.3unordered_set的const迭代器的封装
这个与set的处理方式都一样。
#pragma once
#include"hashtable.h"namespace Ting
{template<class K>class unordered_set{public:struct SetKeyOfT{const K& operator()(const K& key){return key;}};typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator iterator;typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator const_iterator;bool insert(const K& key){return _ht.insert(key);}iterator begin() const{return _ht.begin();}iterator end() const{return _ht.end();}void Print(){_ht.Print();}private:hash_bucket::HashTable<K, K,SetKeyOfT> _ht;};
}

2.3.4unordered_map的const迭代器的封装
这个与map的处理方式都一样。
#pragma once
#include"hashtable.h"namespace Ting
{template<class K,class V>class unordered_map{public:struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};bool insert(const pair<K, V>& kv){return _ht.insert(kv);}typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;bool insert(const K& key){return _ht.insert(key);}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator end() const{return _ht.end();}const_iterator begin() const{return _ht.begin();}void Print(){_ht.Print();}private:hash_bucket::HashTable<K, pair<const K,V>, MapKeyOfT> _ht;};
}
2.4unordered_map的[]重载
第一步:将hashtable中insert函数的返回值改写,改下成pair<iterator,bool>的类型
pair<iterator,bool> insert(const T& date){HashFunc hf;KeyOfT kot;if (find(kot(date))){return make_pair(iterator(nullptr,this),false);}//扩容 负载因子达到1就扩容if (_n == _ht.size()){size_t newsize = _ht.size() * 2;HashTable<K,T,KeyOfT,HashFunc> newtable;newtable._ht.resize(newsize);for (size_t i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){Node* next = cur->_next;size_t hashi = hf(kot(cur->_date)) % newsize;//cur头插入新链表cur->_next = newtable._ht[hashi];newtable._ht[hashi] = cur;cur = next;}}_ht.swap(newtable._ht);}size_t hashi = hf(kot(date)) % _ht.size();Node* newnode = new Node(date);newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_n;return make_pair(iterator(newnode,this),true);}
然后编译一下发现又是编译报错,原因其实与set一样。如图:

第二步:给迭代器增加一个构造函数
//模板的提前申明
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable;template<class K, class T, class Ptr,class Ref,class KeyOfT, class HashFunc>
struct HashIterator
{typedef HashNode<T> Node;typedef HashIterator<K, T, Ptr, Ref, KeyOfT, HashFunc> Self;typedef HashTable<K, T, KeyOfT, HashFunc> HashTable;typedef HashIterator<K, T, T*, T&, KeyOfT, HashFunc> Iterator;HashIterator(Node* node, HashTable* hptr):_node(node), _hptr(hptr){}HashIterator(Node* node, const HashTable* hptr):_node(node), _hptr(hptr){}HashIterator(const Iterator& it):_node(it._node), _hptr(it._hptr){}Self operator++(){if (_node->_next){_node = _node->_next;}else{//下面不好写了HashFunc hf;KeyOfT kot;size_t hashi = hf(kot(_node->_date)) % _hptr->_ht.size();hashi++;while (hashi < _hptr->_ht.size() && _hptr->_ht[hashi] == nullptr){++hashi;}if (hashi == _hptr->_ht.size()){_node = nullptr;}else{_node = _hptr->_ht[hashi];}}return *this;}Ptr operator->(){return &(_node->_date);}Ref operator*(){return _node->_date;}bool operator!=(const Self& it){return _node != it._node;}Node* _node;const HashTable* _hptr;
};
第三步:完成operator[]
#pragma once
#include"hashtable.h"namespace Ting
{template<class K,class V>class unordered_map{public:struct MapKeyOfT{const K& operator()(const pair<K,V>& kv){return kv.first;}};typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;pair<iterator,bool> insert(const pair<K, V>& kv){return _ht.insert(kv);}bool insert(const K& key){return _ht.insert(key);}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator end() const{return _ht.end();}const_iterator begin() const{return _ht.begin();}void Print(){_ht.Print();}V& operator[](const K& key){pair<iterator, bool> ret = _ht.insert(make_pair(key, V()));return ret.first->second;}private:hash_bucket::HashTable<K, pair<const K,V>, MapKeyOfT> _ht;};
}