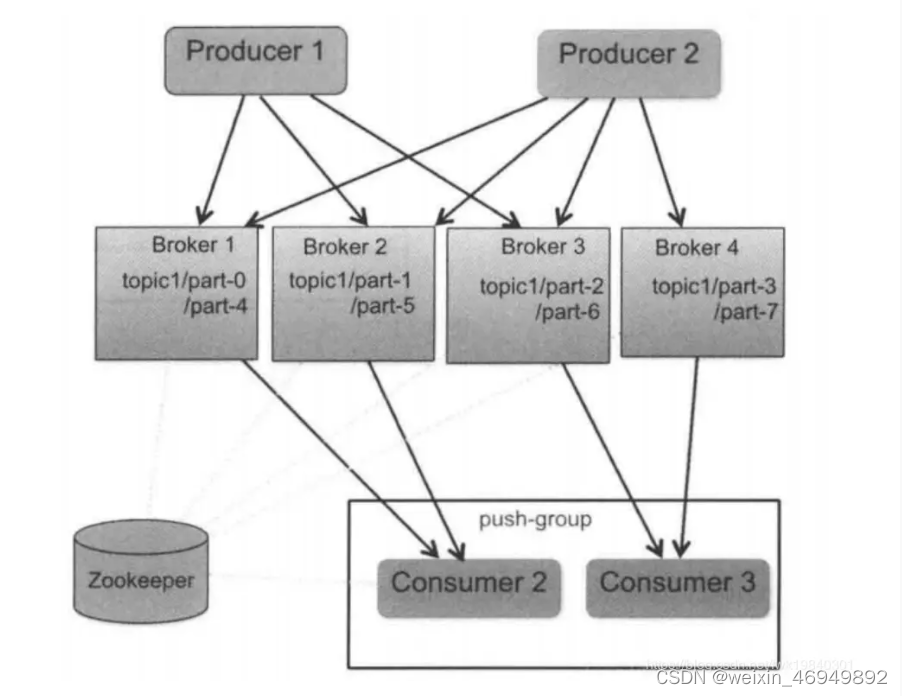
数据科学家的编程语言
在今天有256种编程语言可供选择,选择要学习的语言可能会令人不知所措和困难。有些语言更适用于构建游戏,而有些更适用于软件工程,还有一些更适用于数据科学。
编程语言的类型
低级编程语言是计算机用来执行操作的最容易理解的语言。示例包括汇编语言和机器语言。汇编语言用于直接硬件操作,访问专用处理器指令或解决性能问题。
机器语言由计算机直接读取和执行的二进制代码组成。汇编语言需要汇编器软件将其转换为机器代码。低级语言比高级语言更快,内存效率更高。
高级编程语言与低级编程语言不同,它与计算机的详细信息具有很强的抽象性。这使程序员能够创建与计算机类型无关的代码。
与低级编程语言不同,这些语言更接近人类语言,并且由解释器或编译器在幕后将其转换为机器语言。这对大多数人来说更加熟悉。
一些示例包括Python、Java、Ruby等。这些语言通常是可移植的,程序员不需要太多考虑程序的过程,可以将注意力集中在手头的问题上。如今,许多程序员使用高级编程语言,包括数据科学家。
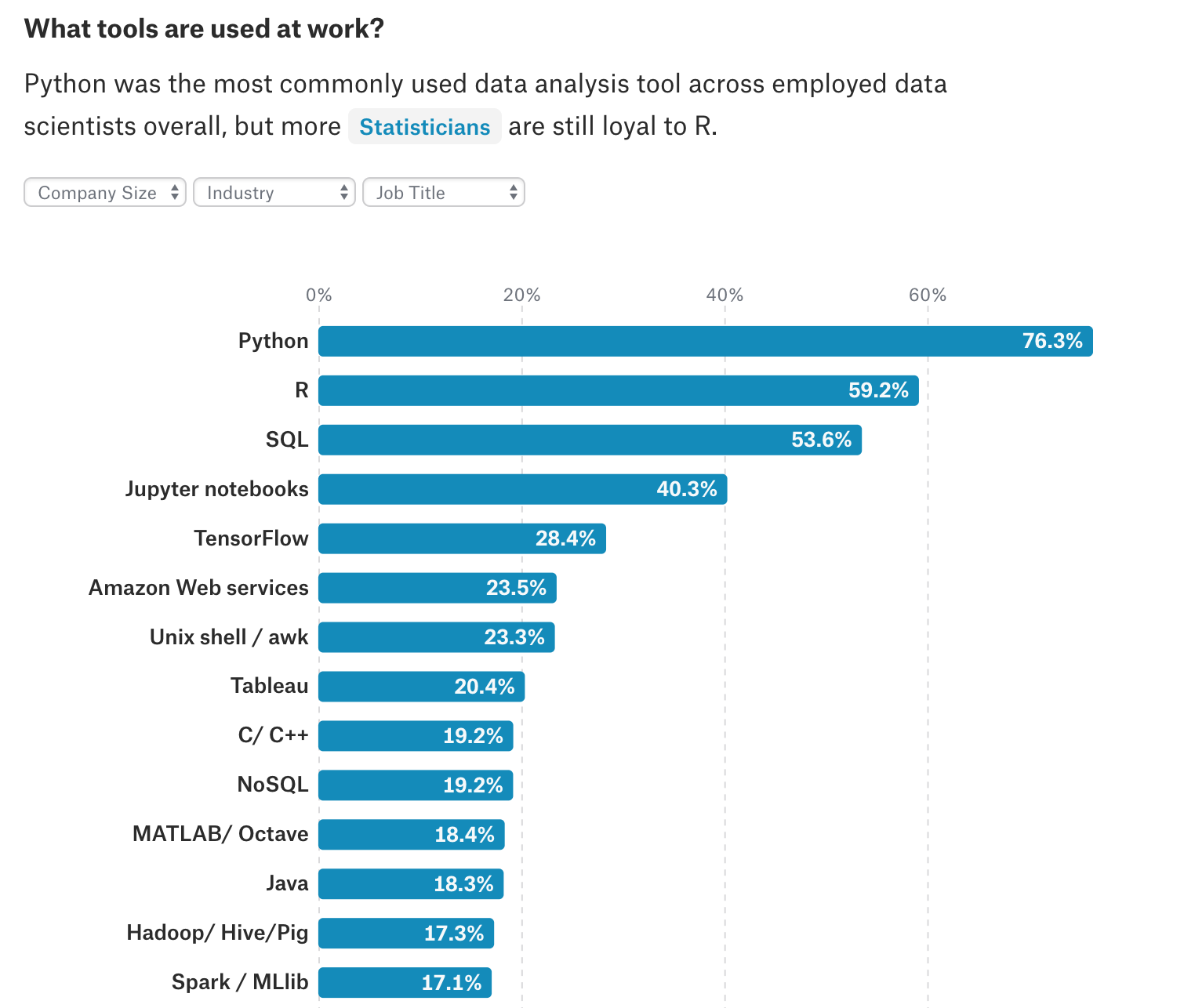
用于数据科学的编程语言
Python
在最近的全球调查中发现,近24,000名数据专业人员中有83%使用Python。数据科学家和程序员喜欢Python,因为它是一种通用的、动态的编程语言。
与R相比,Python似乎更受欢迎,因为在小于1000次迭代时,Python比R更快。它也被认为比R更适合数据操作。这种语言还包含了用于自然语言处理和数据学习的良好包,并且本质上是面向对象的。
R
R更适合临时分析和探索数据集。它是一种用于统计计算和图形的开源语言和软件。这不是一种容易学习的语言,大多数人发现Python更容易上手。
使用lapply函数,具有超过1000次迭代的循环,R实际上击败了Python。这可能会让一些人想知道R是否更适合在大型数据集上进行数据科学,但是R是由统计学家构建的,这反映在其操作中。
在Python中进行数据科学应用程序在本质上更自然。
Java
Java是另一种通用的面向对象编程语言。这种语言似乎非常通用,可用于嵌入式电子、Web应用程序和桌面应用程序。虽然数据科学家似乎不需要Java,但是诸如Hadoop之类的框架运行在JVM上。这些框架构成了大数据堆栈的主要部分。
Hadoop是一个处理框架,用于管理集群系统中运行的大数据应用程序的数据处理和存储。这允许存储大量数据,并能够处理几乎无限的任务。
此外,Java实际上具有用于机器学习和数据科学的许多库和工具,易于扩展用于更大的应用程序,并且速度快。
更多关于Hadoop的信息:https://www.youtube.com/watch?v=MfF750YVDxM
SQL
SQL(结构化查询语言)是用于在关系数据库管理系统中管理数据的领域特定语言。SQL与Hadoop有些相似,因为它管理数据,但是数据存储方式有很大不同,可以在上面的视频中很好地解释。

SQL表和SQL查询对于每个数据科学家都是必须了解和熟悉的。虽然SQL不能专门用于数据科学,但数据科学家必须知道如何在数据库管理系统中处理数据。
Julia
Julia是另一种高级编程语言,专为高性能数值分析和计算科学而设计。它具有非常广泛的用途,例如用
于前端和后端的Web编程。Julia可以嵌入到使用其API的程序中,支持元编程。据说这种语言比Python更快,因为它被设计用于快速实现线性代数等数学概念,并更好地处理矩阵。
Julia提供了与Python或R相同的快速开发速度,同时生成与C或Fortran程序一样快的程序。
Scala
Scala是一种通用编程语言,支持函数式编程、面向对象编程、强大的静态类型系统以及并发和同步处理。
Scala旨在解决Java存在的许多问题。再次说明,这种语言具有许多不同的用途,从Web应用程序到机器学习,但是这种语言仅涵盖前端开发。
这种语言以可扩展性和处理大数据能力而闻名,正如其名称本身是“可扩展语言”的缩写。
Scala与Apache Spark搭配使用可以在大规模上进行并行处理。此外,有许多流行的高性能数据科学框架编写在Hadoop之上,可在Scala或Java中使用。
结论
总之,Python似乎是数据科学家今天最广泛使用的编程语言。这种语言允许集成SQL、TensorFlow和许多其他用于数据科学和机器学习的有用函数和库。
拥有超过70,000个Python库,这种语言的可能性似乎是无限的。
Python还允许程序员创建CSV输出,以便轻松读取电子表格中的数据。
我向新晋的数据科学家建议首先学习和掌握Python和SQL数据科学实施,然后再考虑其他编程语言。
对于数据科学家来说,了解Hadoop的一些知识是至关重要的。