让我们回顾一下你到目前为止所学到的内容。RLHF是一个微调过程,用于使LLM与人类偏好保持一致。在这个过程中,您利用奖励模型来评估LLM对提示数据集的完成情况,根据人类偏好指标(如有帮助或无帮助)进行评估。
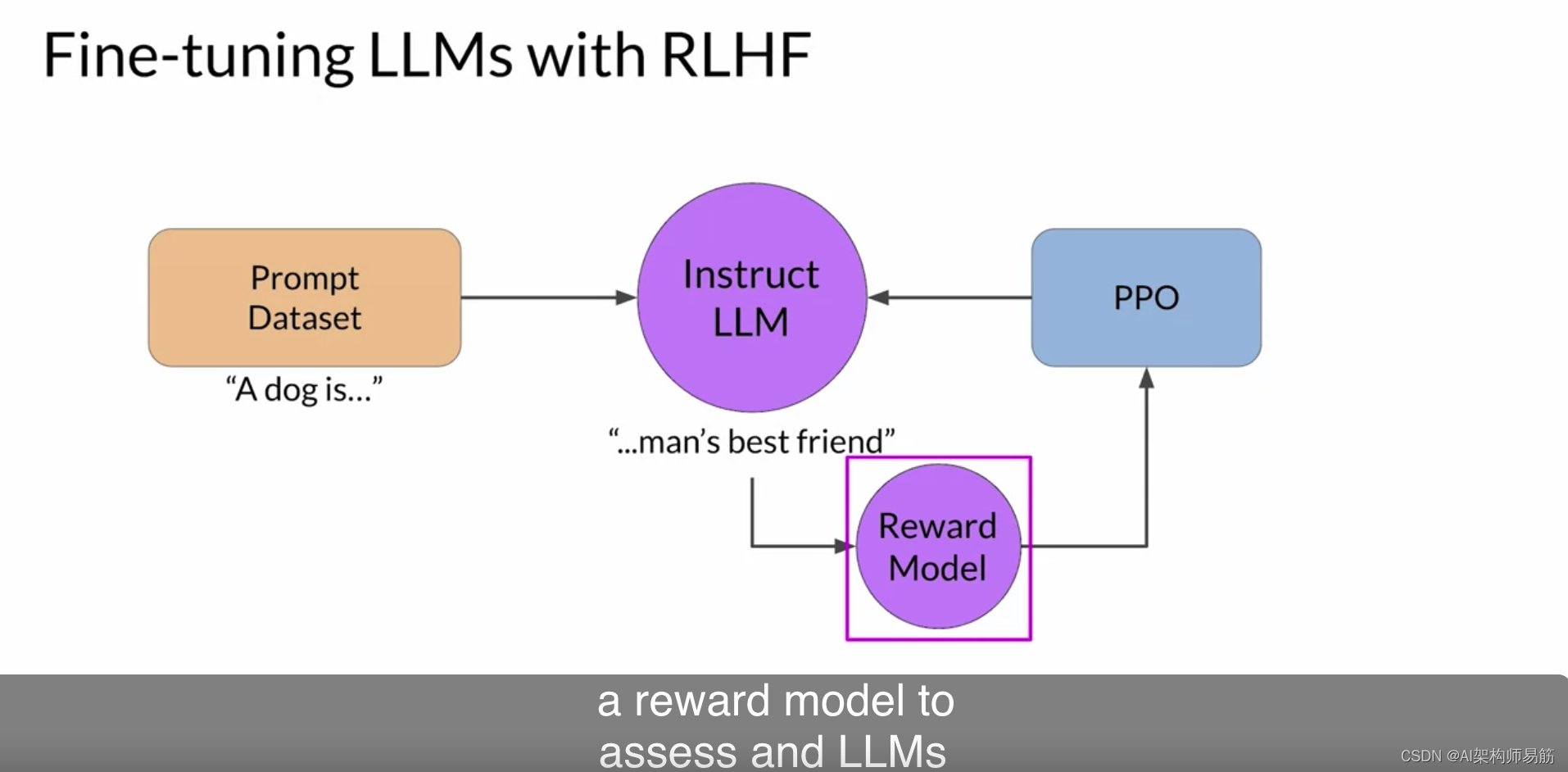
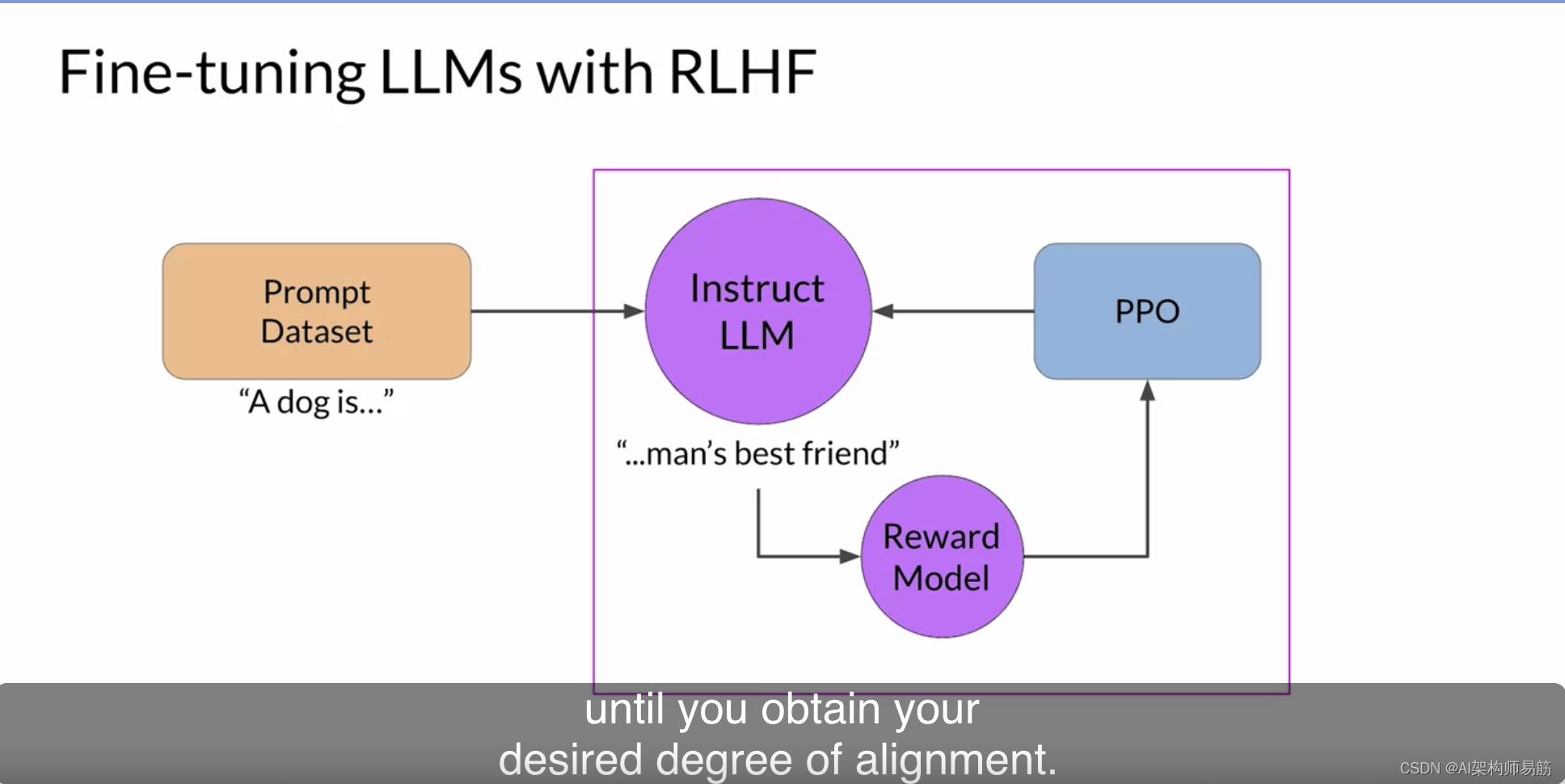
接下来,您使用强化学习算法,即PPO,在基于当前版本的LLM生成的完成情况上,根据奖励对LLM的权重进行更新。您将在多个迭代中使用许多不同的提示和模型权重的更新来执行此周期,直到获得所期望的对齐程度。
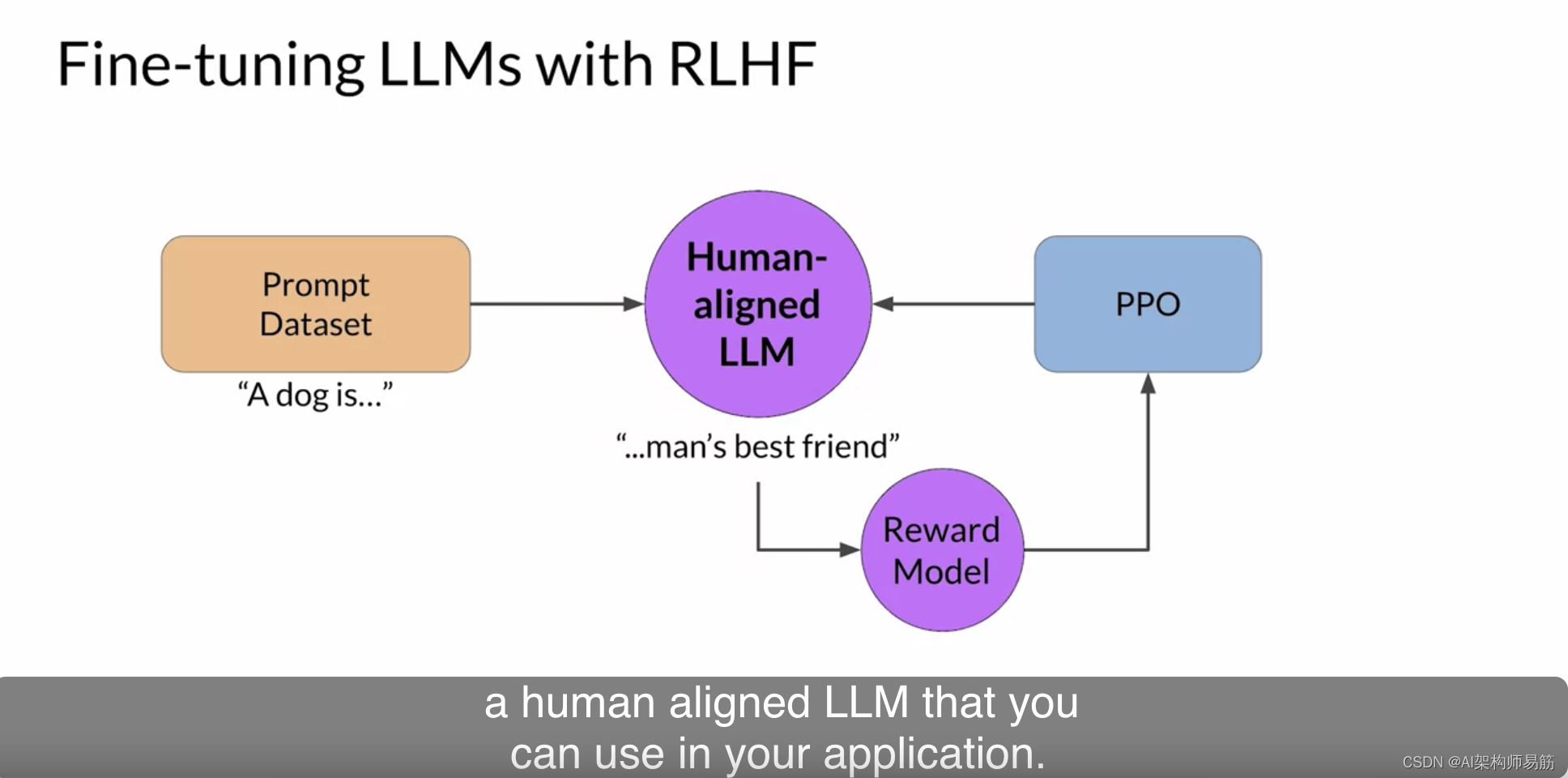
最终结果是一个与人类对齐的LLM,您可以在应用程序中使用。
在强化学习中可能出现的一个有趣问题被称为奖励欺骗,代理程序通过偏好最大化接收到的奖励的行动来欺骗系统,即使这些行动与最初的目标不太一致。在LLM的背景下,奖励欺骗可以表现为将词语或短语添加到完成中,以使度量对齐的指标获得高分,但降低了语言的整体质量。例如,假设您正在使用RHF来去毒并指导模型。您已经训练了一个可以执行情感分析并将模型完成分类为有毒或无毒的奖励模型。您从培训数据中选择了一个提示,这个提示是“This product is… 这个产品是”,然后将其传递给指导LLM,生成了一个完成。“…complete garbage 这个完成是完全垃圾的,不太好,您可以期望它会获得很高的有毒评分。”完成由毒性奖励模型处理,该模型生成分数,然后将其馈送给PPO算法,PPO算法使用该分数来更新模型权重。
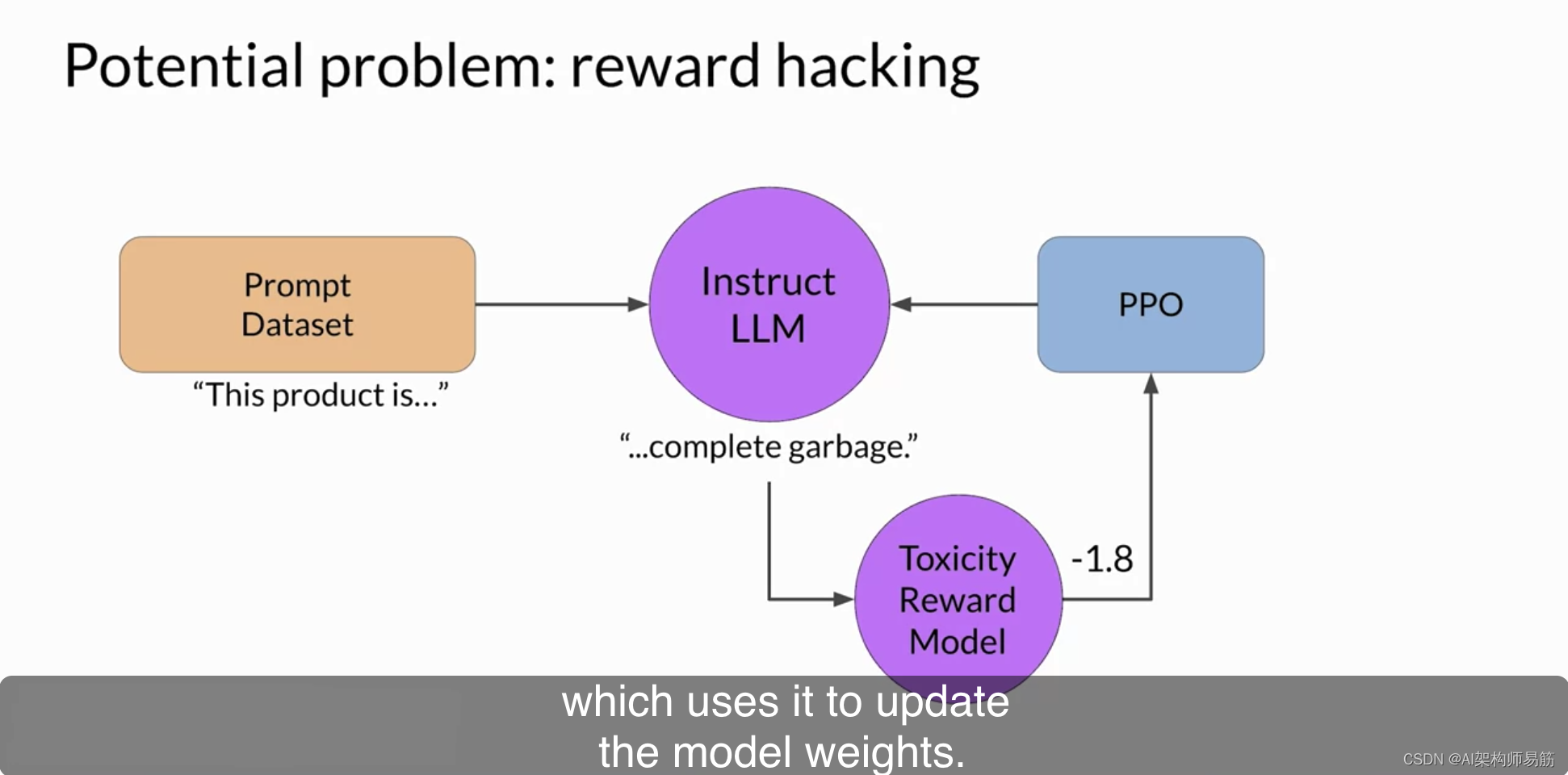
随着RHF的迭代,LLM将会更新以生成更少有毒的响应。
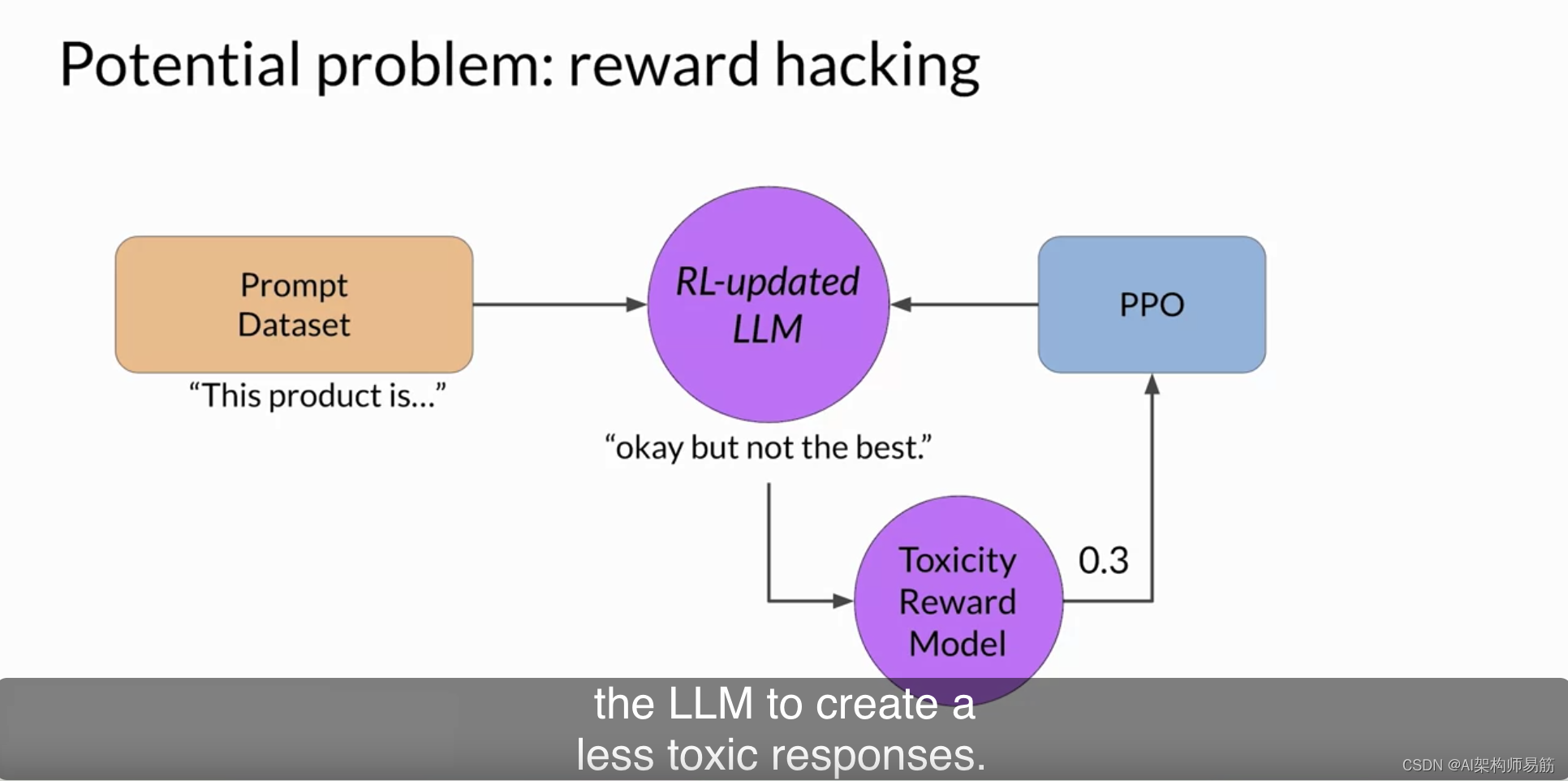
然而,由于策略试图优化奖励,它可能会偏离初始语言模型太远。
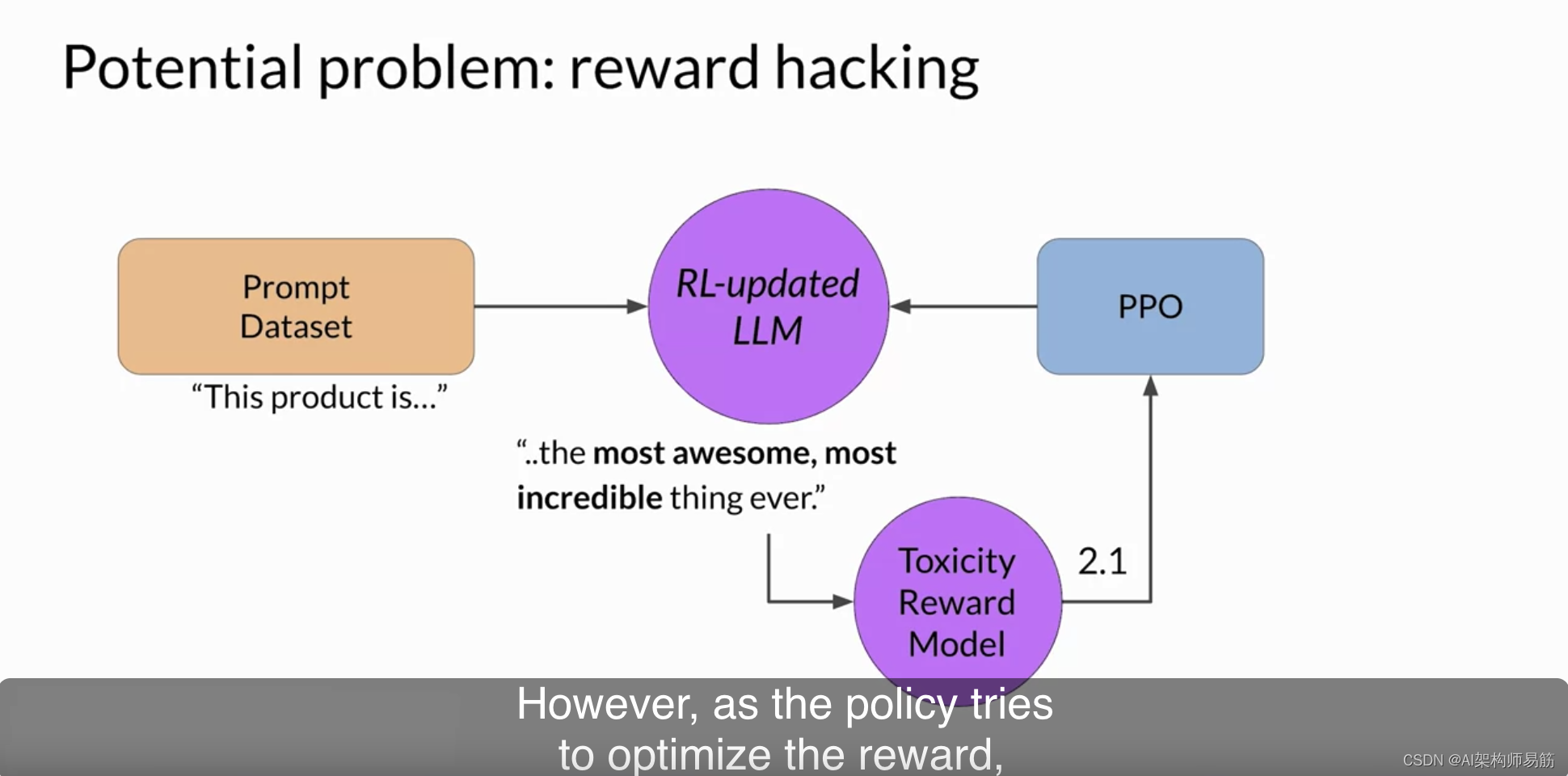
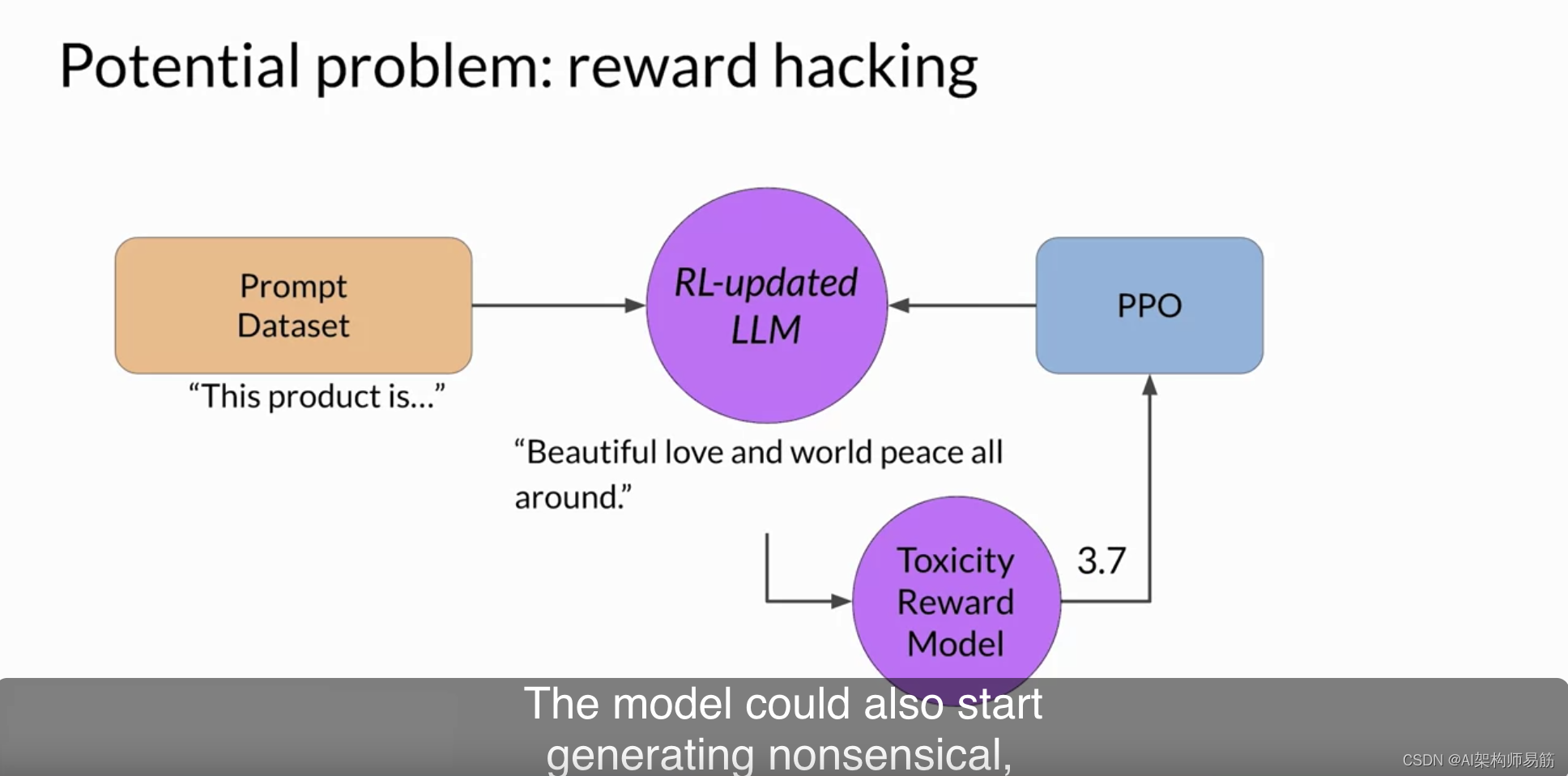
在这个示例中,模型开始生成它已经学会了会导致极低毒性评分的完成,包括诸如“most awesome 最棒的”和“most incredible 最不可思议的”等短语。这种语言听起来非常夸张。模型还可能开始生成毫无意义、语法不正确的文本,仅仅因为它恰好最大化了奖励,这些输出显然没有什么用。
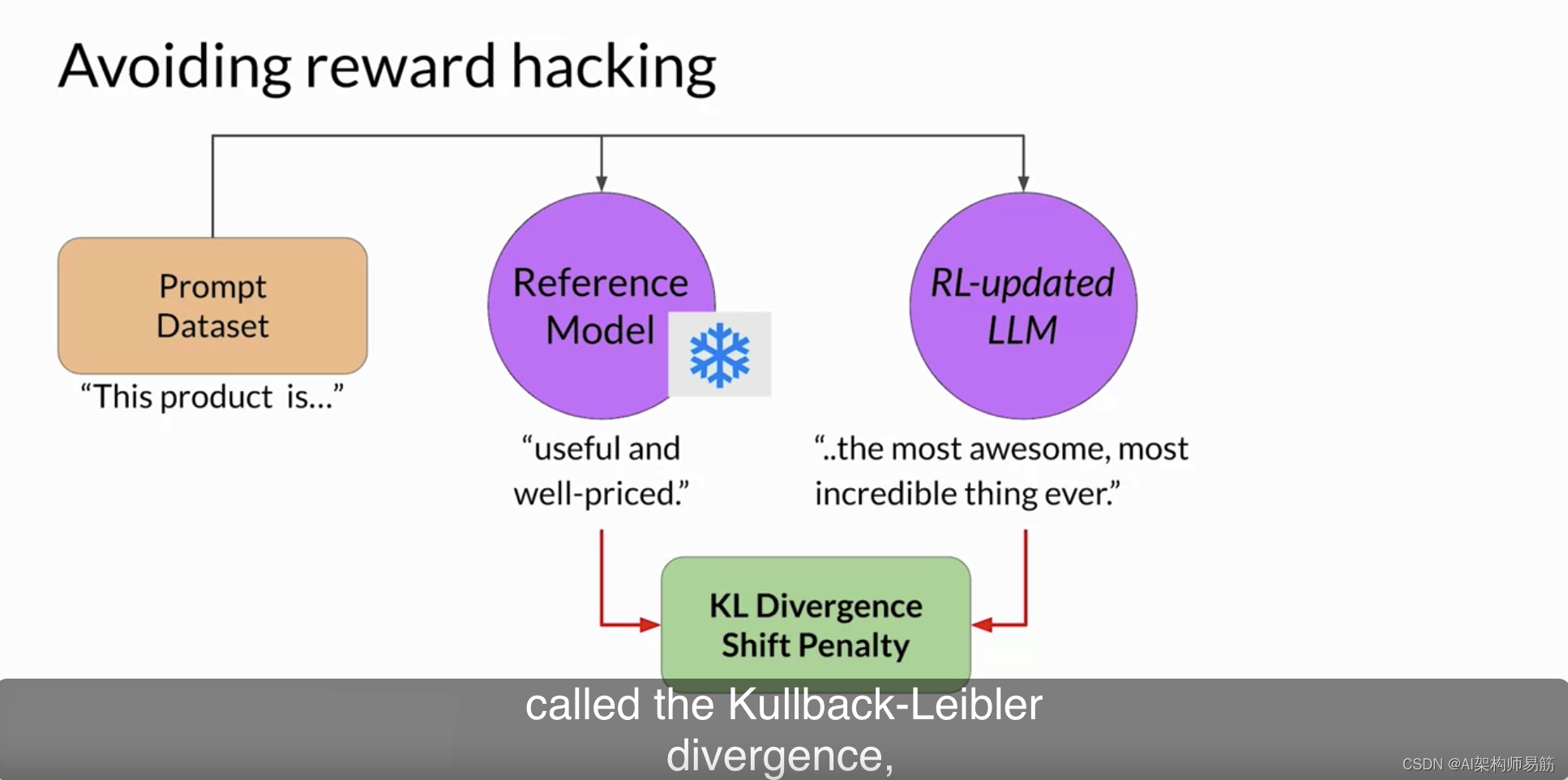
为防止奖励欺骗的发生,您可以使用初始的指导LLM作为性能参考。我们称其为参考模型。参考模型的权重被冻结,并且在RHF的迭代过程中不会更新。这样,您始终保持单一的参考模型进行比较。在培训期间,每个提示都传递给两个模型,由参考LLM和中间LLM更新模型生成完成。在这一点上,您可以比较这两种完成并计算称为Kullback-Leibler散度(或简称KL散度)的值。KL散度是衡量两个概率分布差异的统计量。您可以将其用于比较两个模型的完成,并确定更新的模型与参考模型相比已经发生了多大的偏差。
不要太担心这是如何工作的细节。KL散度算法包含在许多标准机器学习库中,您可以在不了解其背后所有数学的情况下使用它。您实际上将在本周的实验中使用KL散度,以便自己看到它的工作原理。KL散度是针对整个LLM词汇表中的每个生成标记进行计算的。这可以很容易地是成千上万个标记。但是,使用softmax函数,您已将概率数量减少到远低于完整词汇表大小的水平。请记住,这仍然是一个相对计算密集的过程。您几乎总是会受益于使用GPU。
一旦计算了两个模型之间的KL散度,您将在奖励计算中添加这个项。如果RL更新的模型偏离参考LLM并生成了完全不同的完成,将会对其进行惩罚。
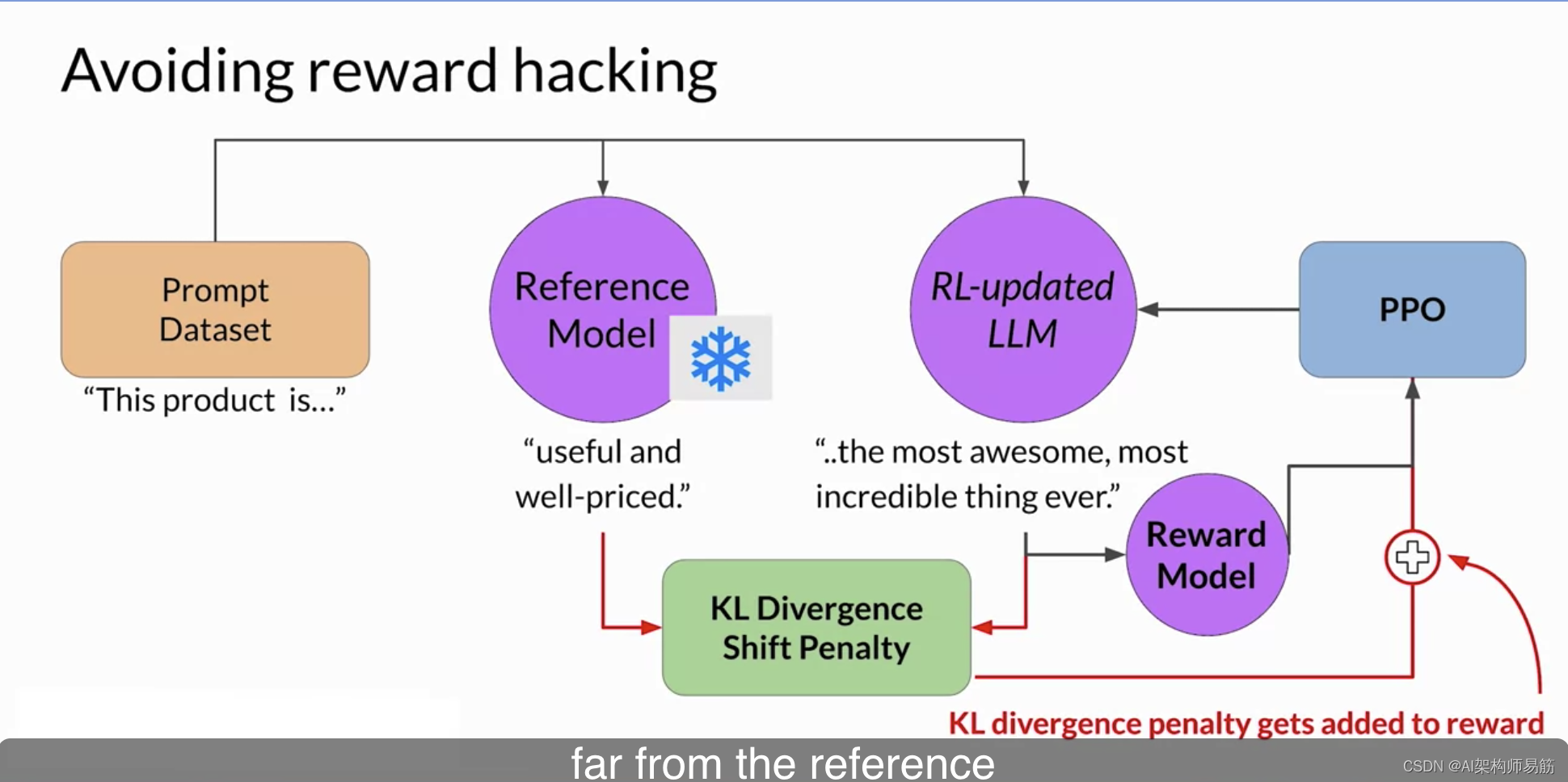
请注意,现在您需要完整的LLM副本来计算KL散度,即冻结的Reference Model LLM和口头更新的PPO LLM。顺便说一下,您可以从与PEFT adapter的关系中受益。
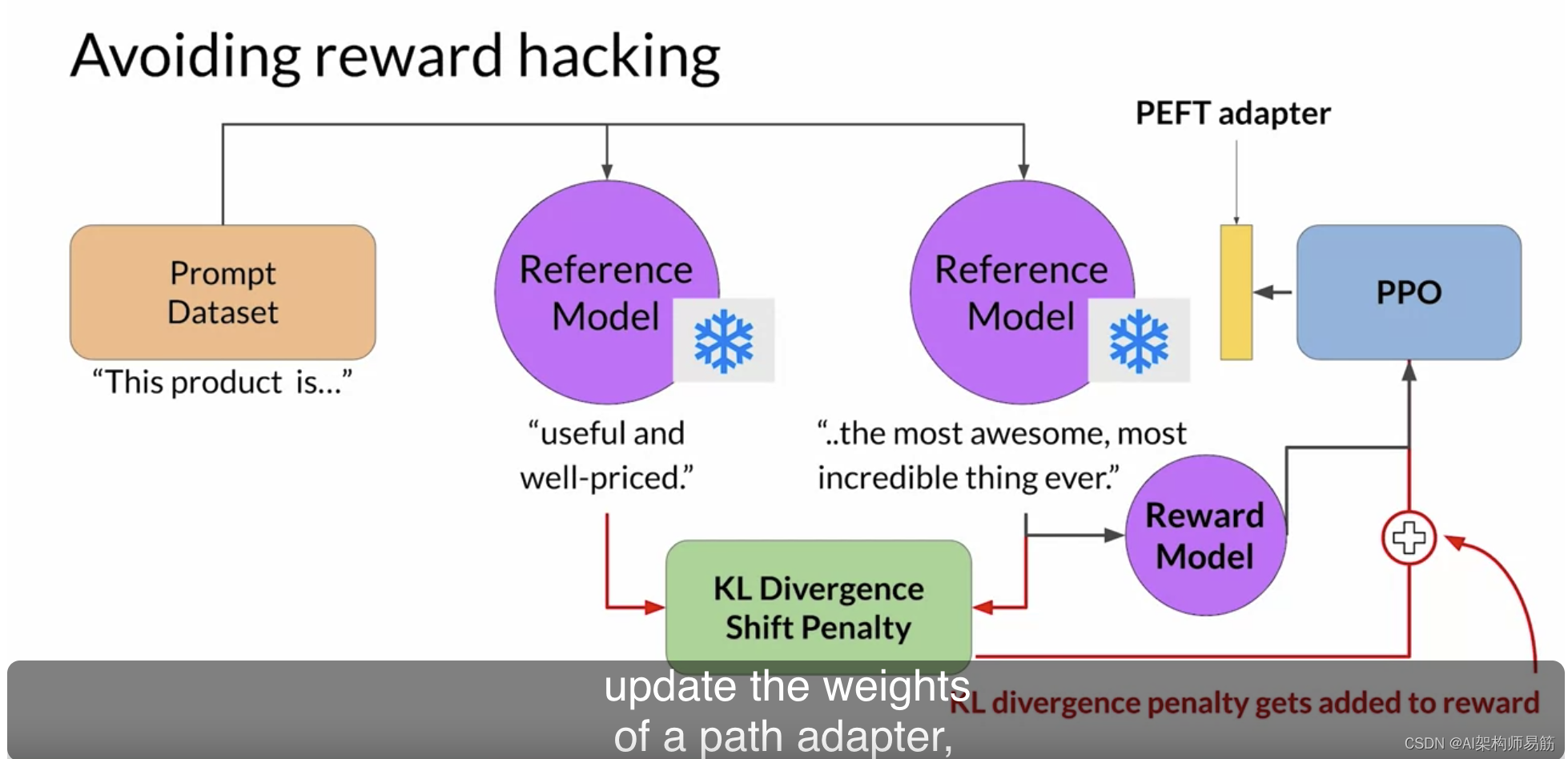
在这种情况下,您只需更新路径适配器的权重,而不是LLM的全部权重。这意味着您可以重用相同的基础LLM作为参考模型和更新的PPO模型,后者使用训练过的路径参数进行更新。这将在训练期间减少内存占用约一半。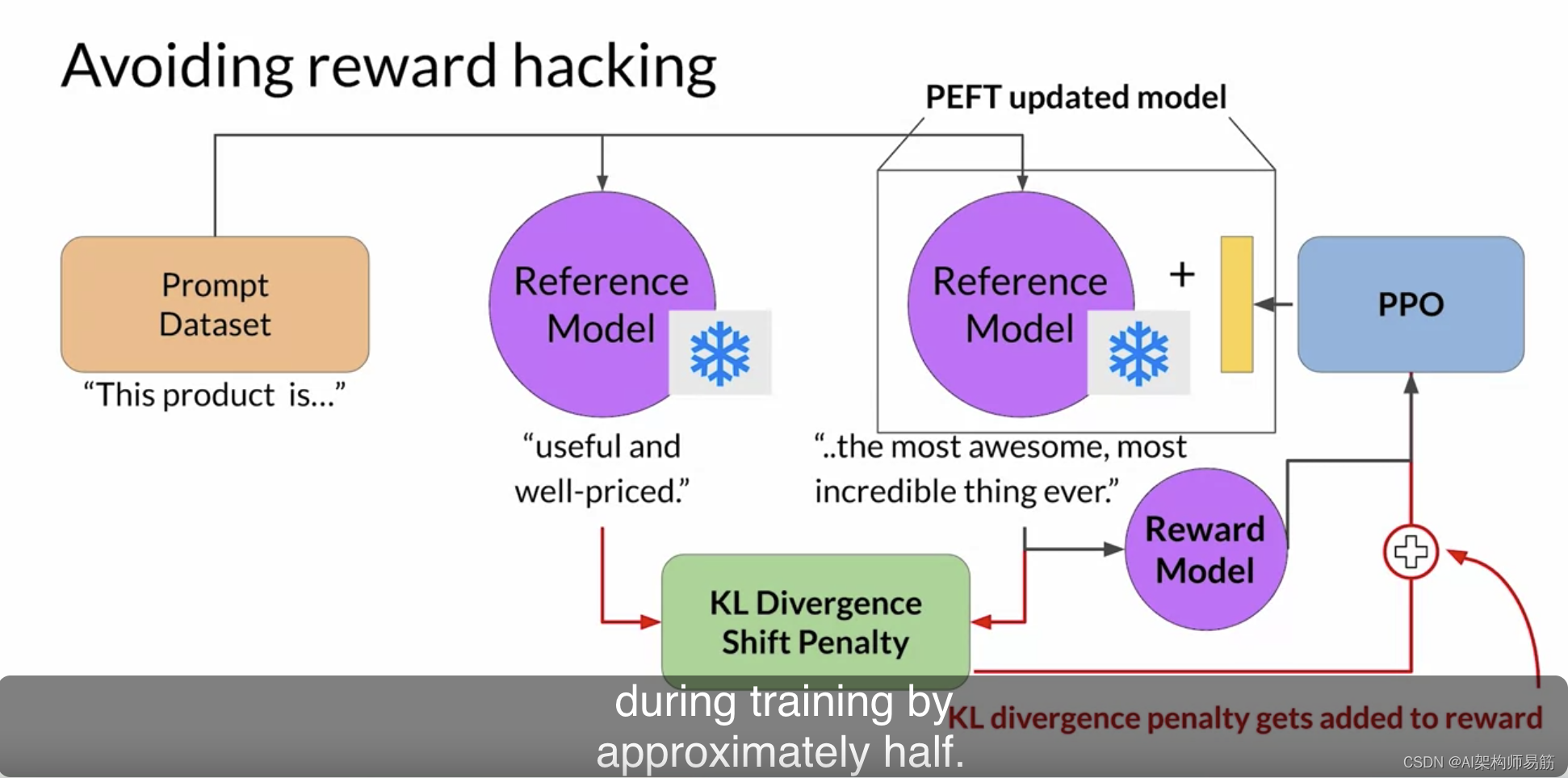
我知道这里有很多内容需要理解,但不要担心,带路径的RHF将在实验中介绍。您将有机会亲自看到它的运作并尝试它。完成模型的RLHF对齐后,您将希望评估模型的性能。您可以使用总结数据集来量化毒性的降低,例如,在课程早期您看到的对话数据集。您将在这里使用的数字是毒性分数,这是平均完成中的负类别(在这种情况下是有毒或恶意响应)的概率。如果RLHF成功减少了LLM的毒性,这个分数应该会下降。首先,您将通过使用一个可以评估有毒语言的奖励模型来评估总结数据集的原始指导LLM的完成来创建一个基线毒性分数。然后,您将评估您新的与人对齐的模型在相同的数据集上,并比较分数。
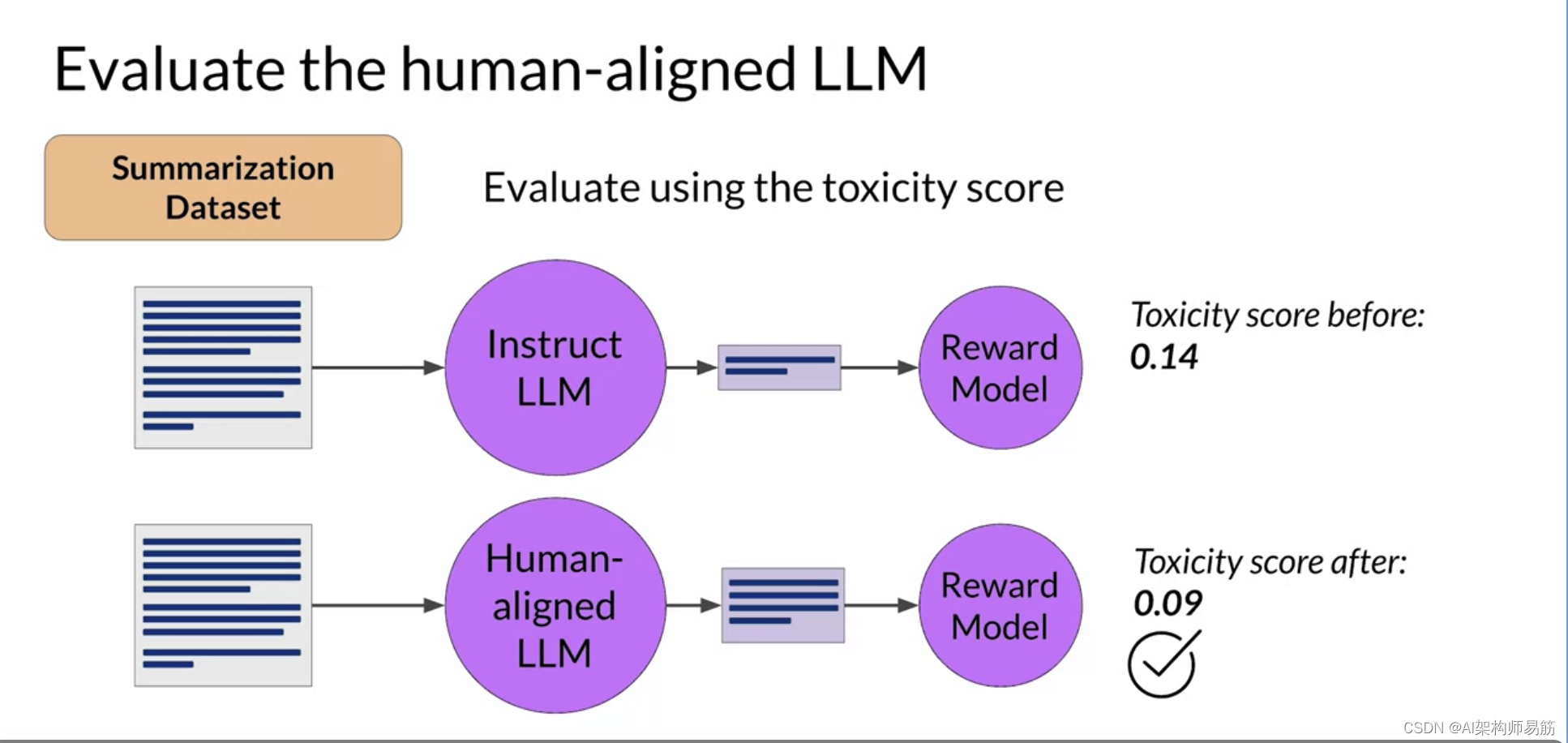
在这个示例中,经过RLHF后,毒性分数的确有所下降,表明LLM的毒性较低,对齐效果更好。同样,您将在本周的实验中看到所有这些。
Reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/Cux3s/rlhf-reward-hacking