1.阻塞队列
1.1阻塞队列的工作原理
阻塞队列本质上还是一个队列,但是在队列的基础上加入了阻塞功能,并且线程安全。
那么它的阻塞功能体现在两方面
1.当队列为空时,进行出队列操作,就进入阻塞状态
2.当队列满了时,进行入队列操作,也进入阻塞状态。
1.2消息队列
消息队列是基于阻塞队列的基础上增加了“消息的类型”,并按照指定类型进行先进先出(类似于优先级队列)
1.3生产者消费者模型
生产者消费者模型也是基于阻塞队列去完成的。
生产者消费者模型的第一个好处:可以实现发送方和接收方的解耦,也就是降低了发送方和接收方的耦合程度
举一个例子:
在开发中,经常要进行服务器之间的交流,如下
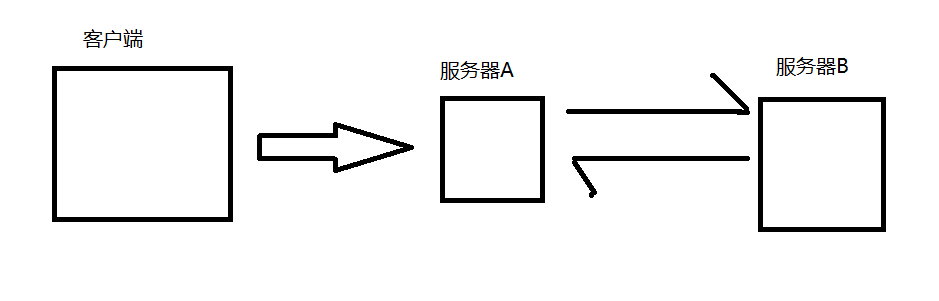
上图中,客户端调用了服务器A,服务器A需要去调用服务器B去完成一些任务,此时服务器A就务必要清楚服务器B的存在,那么服务器A中的代码就要和服务器B有关联。
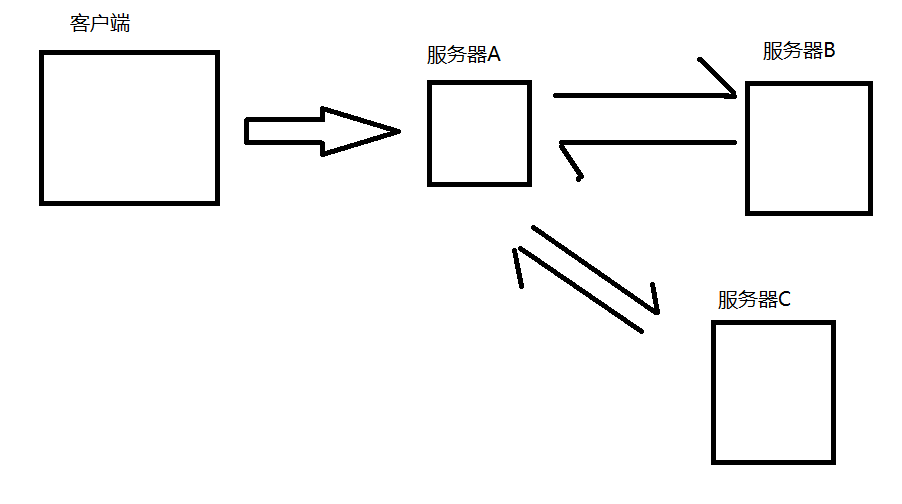
此时如果再插入一个服务器C,也需要A去传给它任务,那么此时A的代码就要去修改、添加服务器C的元素,这样的操作会增加很多不必要的开发负担。
而生产者消费者模型就是将服务器与B、C之间的沟通变成了阻塞队列,A将任务放入相对应的阻塞队列中去,B、C各自去获取各自阻塞队列中的任务,这样一来,A中的代码就不会因为其他服务器的原因而去修改自己本身
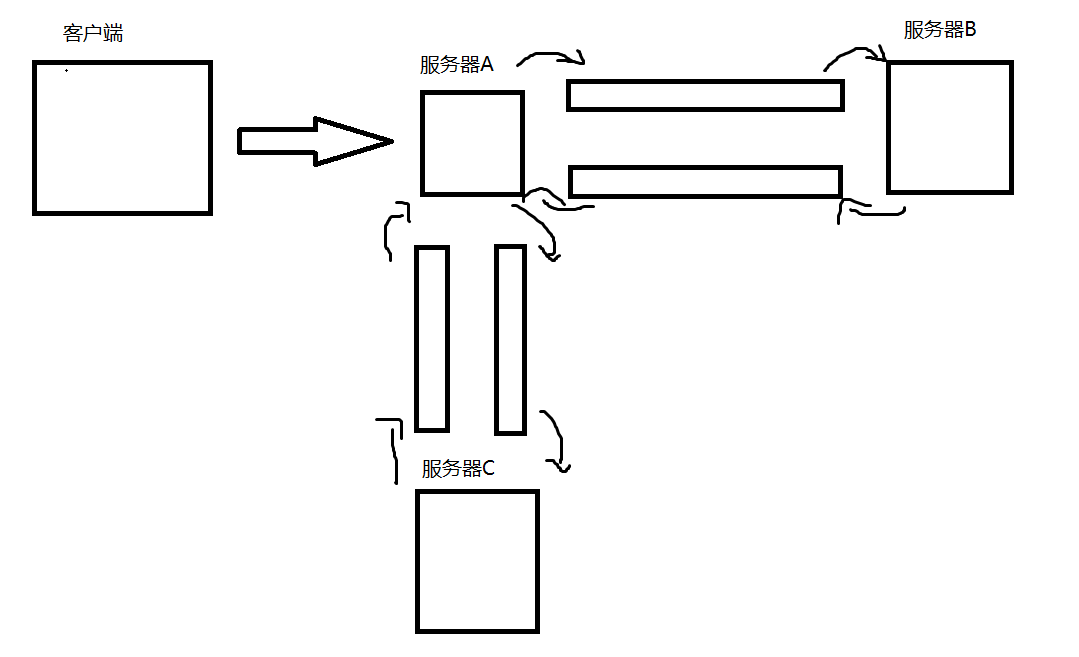
生产者消费者模型的第二个好处:可以避免“削峰填谷”,保证系统的稳定性
这个好处也是和阻塞队列有关的。
前面提到了:阻塞队列的特点是 空了阻塞,满了阻塞
加入某个时刻用户发来了大量的请求,如果不加以控制会容易让服务器崩溃
而在生产者消费者模型里面传递请求要先进入阻塞队列,如果请求太多导致队列满了,那么其余的请求就会进入阻塞状态,当服务器在队列中去获取了新任务队列中有空位后,新的请求才能进入队列。
1.4使用阻塞队列
阻塞队列主要的功能有两个,一个是入队(put),一个是出队(take)
使用方法很简单,如下
public static void main(String[] args) throws InterruptedException {BlockingQueue<String> blockingQueue = new LinkedBlockingQueue<>();blockingQueue.put("hello");String res = blockingQueue.take();System.out.println(res);}1.5实现阻塞队列
知道了阻塞队列的特性,那么实现起来也很方便,首先要构造出一个队列,然后再对立面加入构成阻塞的元素
构造普通队列:
class MyBlockingQueue {private int[] items = new int[1000];private int head = 0;private int tail = 0;private int size = 0;public Integer take() throws InterruptedException {int result = 0;if(size == 0) {return null;}result = items[head];head++;if (head >= items.length) {head = 0;}size--;return result;}public void put(int value) throws InterruptedException {if(size >= items.length) {return;}items[tail] = value;tail++;if (tail >= items.length) {tail = 0;}size++;}
}大致思路是创建两个指针,分别指向队头和队尾,入队让队尾++,出队让队头++,当队头指针或者队尾指针达到数组的长度时,让其赋值到0,形成一个循环数组。
然后再队列中加入阻塞元素
当take时发现队列为空,则让其进入等待状态,解除的条件是:执行完一次put(因为put会入队一个新元素)
当put时发现队列满了,则让其进入等待状态,解除的条件是:执行完一次take(因为take会出队一个元素)
修改后如下(也是完整代码):
class MyBlockingQueue {private int[] items = new int[1000];private int head = 0;private int tail = 0;private int size = 0;public Integer take() throws InterruptedException {int result = 0;synchronized(this) {while (size == 0) {//队列为空 进入阻塞this.wait();}result = items[head];head++;if (head >= items.length) {head = 0;}size--;//唤醒put中的阻塞this.notify();}return result;}public void put(int value) throws InterruptedException {synchronized(this) {while (size == items.length) {//队列满了,进入阻塞this.wait();}items[tail] = value;tail++;if (tail >= items.length) {tail = 0;}size++;//唤醒take中的阻塞this.notify();}}
}2.定时器
2.1定时器的工作原理
定时器会将传入的任务和与其相对应的等待时间存放到带有阻塞的优先级队列中,当时间间隔最短的任务到了执行时间,就对其进行出队操作,并执行任务里面的内容。
2.2 定时器的使用
调用定时器的schedule方法,在里面传入一个任务和时间,如下:
public static void main(String[] args) {System.out.println("程序启动");Timer timer = new Timer();timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("执行定时器任务1");}},3000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("执行定时器任务2");}},2000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("执行定时器任务3");}},1000);}上面的打印顺序是3 ,2 ,1
2.3 实现定时器
定时器中有一个优先级队列,里面要存放任务和与其对应的时间,所以我们先创建一个任务类将任务和时间包装在一起,并且这个类要带有比较功能(可以实现Comparable 接口)
class MyTask implements Comparable<MyTask>{private Runnable runnable;private long time;public MyTask(Runnable runnable, long time) {this.runnable = runnable;this.time = time;}//获取任务的时间public long getTime() {return time;}//执行任务public void run() {runnable.run();}@Overridepublic int compareTo(MyTask o) {return (int)(this.time - o.time);}
}在定时器中要有一个扫描线程去时刻监视队列中任务的情况(查看是否到了执行时间),我们选择在构造方法中去设计和运行扫描线程。
这个线程的任务很简单,就是不断将队首元素(时间最短的元素)取出,判断是否到达时间,然候根据情况选择是将任务放回还是执行,这个需要一个循环去不听的执行。
但是如果任务的执行时间和当前时间相差很多,不断的取出、判断、放回 会额外占用很多cpu资源,所以我们对其考虑进行一个睡眠操作,睡眠的时间就是 -- 任务要执行的时间减去当前的时间,但是,如果有新的任务传了进来,并且时间比当前的最短时间要短就可能出现新任务没有被执行的情况,所以,上面的睡眠操作是不可取的,而是应该使用wait,在wait中设置最大的等待时间,当有新的任务传进来时将wait唤醒,然后重新判断,具体实现如下:
class MyTimer {//扫描线程private Thread t = null;private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();public MyTimer() {t = new Thread(() -> {while(true) {try {synchronized(this) {MyTask myTask = queue.take();long curTime = System.currentTimeMillis();if(curTime < myTask.getTime()) {queue.put(myTask);this.wait(myTask.getTime() - curTime);} else {myTask.run();}}} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}public void schedule(Runnable runnable,long after) {//时间戳需要进行换算MyTask myTask = new MyTask(runnable,System.currentTimeMillis() + after);queue.put(myTask);synchronized(this) {this.notify();}}
}这里要注意,锁一定要包括扫描线程while里面的全部内容,因为如果扫描线程计算完需要等待的时间之后wait之前,扫描线程被切走,此时有一个新任务传了进来,执行了notify之后扫描线程才开始进行工作,那么扫描线程就没有扫描到新的任务,如果新的任务的时间更短,那么新的任务就没有被执行。
完整代码如下:
class MyTask implements Comparable<MyTask>{private Runnable runnable;private long time;public MyTask(Runnable runnable, long time) {this.runnable = runnable;this.time = time;}//获取任务的时间public long getTime() {return time;}//执行任务public void run() {runnable.run();}@Overridepublic int compareTo(MyTask o) {return (int)(this.time - o.time);}
}class MyTimer {//扫描线程private Thread t = null;private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();public MyTimer() {t = new Thread(() -> {while(true) {try {synchronized(this) {MyTask myTask = queue.take();long curTime = System.currentTimeMillis();if(curTime < myTask.getTime()) {queue.put(myTask);this.wait(myTask.getTime() - curTime);} else {myTask.run();}}} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}public void schedule(Runnable runnable,long after) {//时间戳需要进行换算MyTask myTask = new MyTask(runnable,System.currentTimeMillis() + after);queue.put(myTask);synchronized(this) {this.notify();}}
}3.线程池
3.1 线程池存在的意义(优点)
我们知道线程是系统调度的最小单位,线程的存在是因为进程太重了,线程的创建和销毁都比进程更高效,因此,很多时候可以使用多线程去代替多进程来完成并发编程。
但是随着并发程度的提高和性能要求的提高,我们发现,线程的创建和销毁好像也没有那么轻量,当进行大量的创建、销毁线程时开销也很大,此时就引入了线程池。
在池子中有一些创建好的线程,当调用线程时就从池中去取,用完了在还给线程池,相比于创建和销毁,调用和归还就更加轻量了。
并且,调用和归还的操作可以由程序员去自己设计,而不用全部听从系统内核的调度,使得程序更加的可控。
3.2 线程池的使用
常见的线程池创建有四种:
//可以设置线程数量
ExecutorService pool = Executors.newFixedThreadPool(10);//根据任务的数量 去动态变化线程的数量
ExecutorService pool = Executors.newCachedThreadPool();//只有一个线程
ExecutorService pool = Executors.newSingleThreadExecutor();//类似定时器,让任务延时进行
ExecutorService pool = Executors.newScheduledThreadPool(10);使用的方法很简单,就是调用里面的submit方法,在里面传一个任务就可以了,如下:
创建1000个任务让线程池执行
public static void main(String[] args) {//可以设置线程数量ExecutorService pool = Executors.newFixedThreadPool(10);for(int i = 0;i < 1000;i++) {int n = i;pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello" + n);}});}}3.3 线程池的原理
3.3.1 工厂模式
上面的使用我们可以看到,线程池的创建时没有使用new的,而是调用了一个方法,而真正的new操作在方法里面进行,这样的设计模式叫做工厂模式。
工厂模式作用是什么呢?
在Java中,重载的规则是在 方法名(可以省略,因为重载主要就是需要方法名相同)、参数个数、参数类型 其中至少有一项不同,否则就无法达成重载。
那么如果有两种构造方法,他们想要构成重载,但是又达不到重载的条件,此时,就可以使用工厂模式,去根据不同的需求去构造。
举个例子,假如有一个类,它的用途是构造出一个坐标系上的点,构造这样的点可以传入x、y坐标,也可以传入距原点的半径长和角度大小r、a(极坐标),这四个参数都需要double类型,数量相同,方法名也相同,无法达成重载,此时就可以使用工厂模式去创建。
如下所示:
Point point1 = newXYPoint(1,1);
Point point2 = newRAPoint(1,1);使用工厂模式就很好的解决了上面的问题。
3.3.2 ThreadPoolExecutor类
在使用中我们提到了四种创建方法,这四种创建方法本质上都是通过包装ThreadPoolExecutor类来实现的。
ThreadPoolExecutor的构造方法有7个参数分别是
(int corePoolSize , int maximumPoolSize , long keepAliveTime , TimeUnit unit , BlockingQueue<Runnable> workQueue , ThreadFactory threadFactory , RejectedExecutionHandler handler)
int corePoolSize
是核心线程数,也就是线程池中固定的线程数量
int maximumPoolSize
是最大线程数,是线程池中可以包含的最大线程数量
最大线程数和核心线程数的差值属于临时线程,也就是可以允许被回收掉的线程,比如当前任务量很多,那么就可以多创建几个临时线程去执行任务,当任务量比较少的时候,这些临时线程没有事情干就可以被回收掉。
long keepAliveTime 和 TimeUnit unit(时间单位:s、ms、分钟...)
这两个参数描述了临时线程可以最长的“摸鱼”时间,如果临时线程没有工作并且时间达到了最长时间,那么此时就会被回收掉。
BlockingQueue<Runnable> workQueue
线程池的任务队列,可以看得到是用一个阻塞队列来 接收、取出 任务。
ThreadFactory threadFactory
用于创建线程。
RejectedExecutionHandler handler
它描述了线程池的拒绝策略。
标准库中提供了四种线程池的拒绝策略,如下:
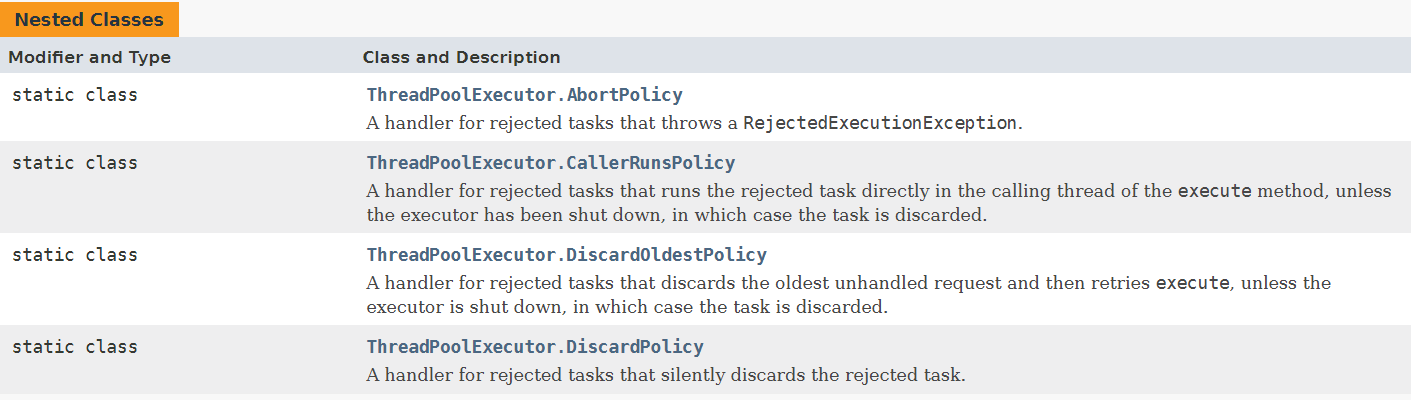
第一种:如果队列满了,那么直接报异常
第二种:如果队列满了,那么多出来的任务,是谁加进来的就由谁处理
第三种:如果队列满了,就丢弃最早的任务
第四种:如果队列满了,就丢弃最新的任务
3.4 实现线程池
我们实现一个线程池的简单版本,也就是前面第一种创建
我们知道线程池中有一个阻塞队列去存取任务,有一个构造方法去创建线程,