【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等
Presto是一种流行的开源分布式SQL引擎,使组织能够在多个数据源上大规模运行交互式分析查询。缓存是一种典型的提高 Presto 查询性能的优化技术。它为 Presto 平台提供了显着的性能和效率改进。
缓存通过将频繁访问的数据存储在内存或快速本地存储中,避免了昂贵的磁盘或网络行程来重新获取数据,从而加快了整体查询的执行速度。在本文中,我们将深入探讨 Presto 的缓存机制以及如何使用它们来提高查询速度并降低成本。
缓存的好处
缓存提供了三个关键优势。通过在 Presto 中实施缓存,您可以:
-
提高查询性能。缓存频繁访问的数据使 Presto 能够从更快、更近的缓存中检索结果,而不是扫描速度较慢的存储。对于重复的分析查询,这可以将查询速度提高几个数量级,从而减少总体延迟。通过加速查询执行,缓存可实现交互式查询和更快的洞察时间。
-
降低基础设施成本。缓存减少了从 S3 等远程存储系统读取的数据量,从而降低了出口费用和存储 API 请求的费用。对于存储在云中的数据,缓存可以最大限度地减少通过网络重复检索数据。这可以节省大量成本,尤其是对于大型数据集。
-
最大限度地减少网络开销。通过减少 Presto 组件和远程存储之间不必要的数据传输,缓存可以缓解网络拥塞。本地缓存可防止分布式 Presto 工作线程之间的网络链接出现瓶颈。它还减少了与外部数据源连接的负载和带宽使用。
总体而言,缓存可以提高 Presto 查询的性能和效率,为基于 Presto 的分析平台提供巨大的价值和投资回报率。
Presto 中不同类型的缓存
Presto中有两种类型的缓存,内置缓存和第三方缓存。内置缓存包括Metastore缓存、文件列表缓存和Alluxio SDK缓存。它使用 Presto 集群的内存和 SSD 资源,与 Presto 在同一进程中运行,以获得最佳性能。
内置缓存的主要优点是延迟非常低并且没有网络开销,因为数据在 Presto 集群中本地缓存。然而,内置缓存容量受到工作节点资源的限制。
第三方缓存,例如Alluxio分布式缓存,可以独立部署,并提供更好的可扩展性和更大的缓存容量。它们对于大规模分析工作负载、跨区域/云部署以及降低云存储的 API 和出口成本特别有利。
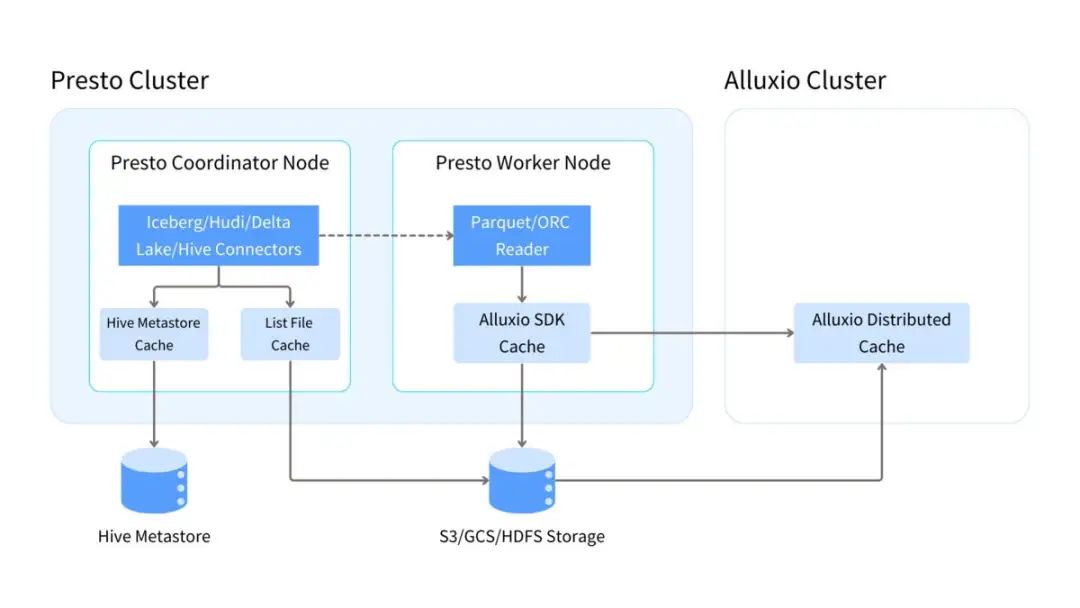
上图和下表总结了不同的缓存类型及其相应的资源类型和位置。
| 缓存类型 | 缓存位置 | 资源类型 |
| 元存储缓存 | Presto协调器 | 内存 |
| 列出文件缓存 | Presto协调器 | 内存 |
| Alluxio SDK缓存 | Presto工作节点 | 内存/SSD |
| Alluxio分布式缓存 | Alluxio工作节点 | 内存/SSD/HDD |
Presto的缓存默认都是禁用的。您需要修改Presto的配置来激活它们。我们将在接下来的部分更详细地解释不同的缓存类型以及如何通过配置属性启用它们。
元存储缓存
Presto 的元存储缓存将 Hive 元存储查询结果存储在内存中,以便更快地访问。这减少了规划时间和元存储请求。
当 Hive 元存储过载时,元存储缓存非常有用。对于大型分区表,缓存将分区元数据存储在本地,从而实现更快的访问和更少的重复查询。这减少了 Hive 元存储上的总体负载。
要启用元存储缓存,请使用以下设置:
hive.partition-versioning-enabled=truehive.metastore-cache-scope=ALLhive.metastore-cache-ttl=1dhive.metastore-refresh-interval=1dhive.metastore-cache-maximum-size=10000000
请注意,如果表频繁更新,您应该为元存储版本化缓存配置较短的 TTL 或刷新间隔。较短的缓存刷新间隔可确保仅存储当前元数据,从而降低查询执行中元数据过时的风险。这可以防止 Presto 使用过时的数据。
列出文件状态缓存
列表文件缓存存储文件路径和属性,以避免从名称节点或对象存储中重复检索。
当 HDFS namenode 过载或对象存储的文件列表性能较差时,列表文件缓存可显着改善查询延迟。列表文件调用可能会成为 HDFS 的瓶颈,使名称节点不堪重负,并增加 S3 存储的成本。启用列表文件状态缓存后,Presto 协调器会在内存中缓存文件列表,以便更快地访问常用数据,从而减少冗长的远程 listFile 调用。
要配置列表文件状态缓存,请使用以下设置:
hive.file-status-cache-expire-time=1hhive.file-status-cache-size=10000000hive.file-status-cache-tables=*
请注意,列表文件状态缓存只能应用于密封目录,因为 Presto 会跳过缓存开放分区以确保数据新鲜度。
Alluxio SDK缓存(原生)
Alluxio SDK缓存是Presto内置的缓存,用于减少表扫描的延迟。由于Presto是一个与存储无关的引擎,因此其性能经常受到存储的限制。在Presto工作节点的SSD上本地缓存数据可以实现快速的查询访问和执行。通过最小化重复的网络请求,Alluxio缓存还降低了对远程数据的云出口费用和存储API成本。
Alluxio SDK缓存对于查询远程数据特别有益,如跨区域或混合云对象存储。这大大减少了查询延迟以及相关的云存储出口费用和API成本。
使用以下设置启用Alluxio SDK缓存:
cache.enabled=truecache.type=ALLUXIOcache.base-directory=file:///tmp/alluxiocache.alluxio.max-cache-size=100MB
为了达到最好的缓存命中率,将节点选择策略改为软亲和性:
hive.node-selection-strategy=SOFT_AFFINITY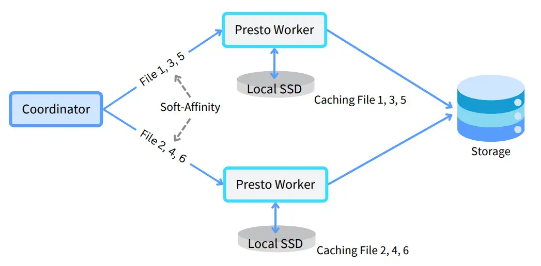
上图展示了软亲和力节点选择架构。软关联调度尝试根据文件路径向工作程序发送请求,通过在工作程序缓存中定位数据来最大化缓存命中率。软亲和力之所以是“软”,是因为它不是一个严格的规则——如果首选工作人员繁忙,则将分片发送到另一个可用工作人员而不是等待。
如果遇到诸如“Unsupported Under FileSystem”之类的错误,请从 Maven 存储库下载最新的Alluxio 客户端 JAR并将其放置在 {$presto_root_path}/plugin/hive-hadoop2/ 目录中。
Alluxio分布式缓存(第三方)
如果 Presto 内存或存储不足以容纳大型数据集,则使用第三方缓存解决方案可以为频繁的数据访问提供扩展缓存。第三方缓存可以为 Presto 提供多种优化:
-
通过减少 I/O 延迟来提高性能
-
加速远程跨数据中心或云数据存储的查询
-
在 Presto 工作线程、集群和其他引擎(例如Apache Spark)之间提供共享缓存
-
启用弹性缓存以节省现货实例的成本
Alluxio 分布式缓存是第三方缓存的一个示例。如下图所示,Alluxio分布式缓存部署在Presto和S3等存储之间。Alluxio使用主从架构,其中主节点管理元数据,工作节点管理本地存储(内存、SSD、HDD)上的缓存数据。当缓存命中时,Alluxio工作线程将数据返回给Presto工作线程。否则,Alluxio工作线程从持久存储中检索数据并缓存数据以供将来使用。Presto 工作线程处理缓存的数据,协调器将结果返回给用户。
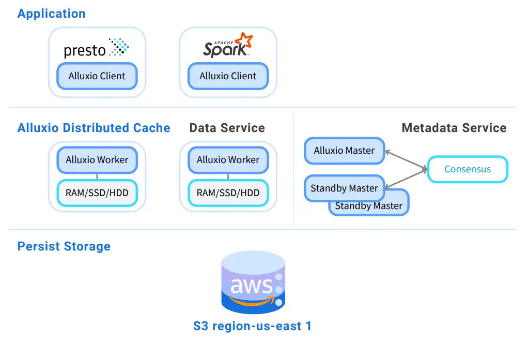
以下是使用 Presto 部署 Alluxio 分布式缓存的步骤。
1.将Alluxio客户端JAR分发到所有Presto服务器
为了让 Presto 能够与 Alluxio 服务器通信,Alluxio 客户端 jar 必须位于 Presto 服务器的类路径中。将 Alluxio 客户端 JAR /<PATH_TO_ALLUXIO>/client/alluxio-2.9.3-client.jar 放入所有 Presto 服务器上的目录 ${PRESTO_HOME}/plugin/hive-hadoop2/ 中。使用以下命令重新启动 Presto 工作线程和协调器:
$ ${PRESTO_HOME}/bin/launcher restart2.将Alluxio配置添加到Presto的HDFS配置文件中
您可以将Alluxio的属性添加到HDFS配置文件中,例如core-site.xml和hdfs-site.xml,然后在文件${PRESTO_HOME}/etc/catalog/hive.properties中使用Presto属性hive.config.resources指向每个 Presto Worker 上的 HDFS 配置文件的位置。
hive.config.resources=/<PATH_TO_CONF>/core-site.xml,/<PATH_TO_CONF>/hdfs-site.xml然后,将该属性添加到 HDFS core-site.xml 配置中,该配置由 Presto 属性中的 hive.config.resources 链接。
<configuration><property><name>alluxio.master.rpc.addresses</name>
<value>master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998</value></property>
</configuration>基于上面的配置,Presto能够定位Alluxio集群并将数据访问转发给它。
为您的用例选择合适的缓存
Presto 和 Alluxio 开源社区不断致力于改进现有的缓存功能并开发新的功能来增强查询速度、优化效率并提高系统的可扩展性和可靠性。
缓存是提高Presto查询性能的强大方式。在本文中,我们介绍了Presto中的不同缓存机制,包括元存储缓存、列出文件状态缓存、Alluxio SDK缓存和Alluxio分布式缓存。如下表所示,您可以根据您的用例使用这些缓存来加速数据访问。
| 缓存类型 | 何时使用 |
| 元存储缓存 | 规划时间慢 Hive metastore慢 具有数百个分区的大表 |
| 列出文件状态缓存 | 超载的HDFS namenode 如S3这样的超载对象存储 |
| Alluxio SDK缓存 | 外部存储速度慢或不稳定 |
| Alluxio分布式缓存 | 跨区域、多云、混合云 与其他计算引擎共享数据 |
作者:Beinan Wang and Hope Wang
更多内容请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。