ps:冠军团队方案,本文只复刻了冠军方案特征工程和机器学习部分,无涉及深度学习部分。
文章目录
- 1. 赛题引入
- 1.1 赛题描述
- 1.2 数据描述
- 1.3 评价指标
- 1.4 数据集解释
- 2. 特征工程
- 2.1 数据表1-用户登陆数据:app_launch_logs.csv
- 2.2 数据表2-用户观看视频时长和数目特征:user_playback_data.csv
- 2.3 数据表3-用户画像数据:user_portrait_data.csv
- 2.4 数据表-登录类型:app_launch_logs.csv
- 2.5 合并数据表生成训练集&测试集
- 2.6 特征工程&特征筛选总结
- 3.模型建立
- 3.1 lightgbm
- 3.2 catboost
- 3.3 xgboost
- 3.4 后处理
- 3.5 模型融合
- 3.6 再处理
1. 赛题引入
1.1 赛题描述
爱奇艺是中国和世界领先的高品质视频娱乐流媒体平台,每个月有超过5亿的用户在爱奇艺上享受娱乐服务。爱奇艺秉承“悦享品质”的品牌口号,打造涵盖影剧、综艺、动漫在内的专业正版视频内容库,和“随刻”等海量的用户原创内容,为用户提供丰富的专业视频体验。
爱奇艺手机端APP,通过深度学习等最新的AI技术,提升用户个性化的产品体验,更好地让用户享受定制化的娱乐服务。我们用“N日留存分”这一关键指标来衡量用户的满意程度。例如,如果一个用户10月1日的“7日留存分”等于3,代表这个用户接下来的7天里(10月2日~8日),有3天会访问爱奇艺APP。预测用户的留存分是个充满挑战的难题:不同用户本身的偏好、活跃度差异很大,另外用户可支配的娱乐时间、热门内容的流行趋势等其他因素,也有很强的周期性特征。
在竞赛之初官方发布了帮助文档,其中提到所有用户在[131,153]之间的登录行为都是被完整记录的,因此不会有用户在这个时间段内缺少记录,因此在这个区间内计算出的7日留存分一定是准确的真实标签。
本次大赛基于爱奇艺APP脱敏和采样后的数据信息,预测用户的7日留存分。参赛队伍需要设计相应的算法进行数据分析和预测。
1.2 数据描述
本次比赛提供了丰富的数据集,包含视频数据、用户画像数据、用户启动日志、用户观影和互动行为日志等。针对测试集用户,需要预测每一位用户某一日的“7日留存分”。7日留存分取值范围从0到7,预测结果保留小数点后2位。
1.3 评价指标
本次比赛是一个数值预测类问题。评价函数使用:
100 ∗ ( 1 − 1 n ∑ t = 1 n ∣ F t − A t 7 ∣ ) 100*(1-\frac{1}{n}\sum_{t=1}^{n}|\frac{F_{t}-A_{t}}{7}|) 100∗(1−n1t=1∑n∣7Ft−At∣)
n是测试集用户数量,F是参赛者对用户的7日留存分预测值,A是真实的7日留存分真实值。
1.4 数据集解释
1. User portrait data
| Field name | Description |
|---|---|
| user_id | |
| device_type | iOS, Android |
| device_rom | rom of the device |
| device_ram | ram of the device |
| sex | |
| age | |
| education | |
| occupation_status | |
| territory_code |
2. App launch logs
| Field name | Description |
|---|---|
| user_id | |
| date | Desensitization, started from 0 |
| launch_type | spontaneous or launched by other apps & deep-links |
3. Video related data
| Field name | Description |
|---|---|
| item_id | id of the video |
| father_id | album id, if the video is an episode of an album collection |
| cast | a list of actors/actresses |
| duration | video length |
| tag_list | a list of tags |
4. User playback data
| Field name | Description |
|---|---|
| user_id | |
| item_id | |
| playtime | video playback time |
| date | timestamp of the behavior |
5. User interaction data
| Field name | Description |
|---|---|
| user_id | |
| item_id | |
| interact_type | interaction types such as posting comments, etc. |
| date | timestamp of the behavior |
2. 特征工程
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
定义目标函数:
def score(res,label,pre):res['diff'] = abs((res[pre]-res[label])/7)s = 1-sum(res['diff'])/len(res)return s
2.1 数据表1-用户登陆数据:app_launch_logs.csv
#app登录数据
df = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\app_launch_logs.csv')
#测试集
test_a = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\test-a-without-label.csv')
test = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\test-a-without-label.csv')
test.head()
| user_id | end_date | |
|---|---|---|
| 0 | 10007813 | 205 |
| 1 | 10052988 | 210 |
| 2 | 10279068 | 200 |
| 3 | 10546696 | 216 |
| 4 | 10406659 | 183 |
df.head()
| user_id | launch_type | date | |
|---|---|---|---|
| 0 | 10157996 | 0 | 129 |
| 1 | 10139583 | 0 | 129 |
| 2 | 10277501 | 0 | 129 |
| 3 | 10099847 | 0 | 129 |
| 4 | 10532773 | 0 | 129 |
df = df.sort_values(['user_id','date']).reset_index(drop=True)
df = df[['user_id','date']].drop_duplicates().reset_index(drop=True) #去重复值
df = df[df['user_id'].isin(test_a['user_id'])]
df.head()
| user_id | date | |
|---|---|---|
| 2278 | 10000176 | 120 |
| 2279 | 10000176 | 144 |
| 2280 | 10000176 | 161 |
| 2281 | 10000176 | 162 |
| 2282 | 10000176 | 163 |
df_group = df.groupby('user_id').agg(list).reset_index()
df_group['date_max'] = df_group['date'].apply(lambda x: max(x))
df_group['date_min'] = df_group['date'].apply(lambda x: min(x))
df_group.head()
| user_id | date | date_max | date_min | |
|---|---|---|---|---|
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 |
| 1 | 10000263 | [131, 135, 136, 137, 140, 141, 142, 143, 145, … | 212 | 131 |
| 2 | 10000355 | [136, 137, 142, 144, 145, 146, 147, 148, 150, … | 197 | 136 |
| 3 | 10000357 | [169, 170, 171, 172, 173, 174, 175, 176, 177, … | 200 | 169 |
| 4 | 10000383 | [134, 156, 176, 181] | 181 | 134 |
冠军团队选取了[date_min-1, end_date-6]和[131, 153]交集的部分来构建训练集,并选取end_date-7来构建线下测试集样本。其中,end_date是指该用户在测试集中被指定的、需要对留存分进行预测的日期。
user_enddate = dict(zip(test_a['user_id'],test_a['end_date']))
interval = [x for x in range(131,154)]
def extend_list(row):date_min = row['date_min']date_max = row['date_max']end_date = user_enddate[row['user_id']] return list(set([x for x in range(date_min,end_date-6)]+interval))
df_group['date_all'] = df_group.apply(extend_list, axis=1)
df_group.head()
| user_id | date | date_max | date_min | date_all | |
|---|---|---|---|---|---|
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | [128, 129, 130, 131, 132, 133, 134, 135, 136, … |
| 1 | 10000263 | [131, 135, 136, 137, 140, 141, 142, 143, 145, … | 212 | 131 | [131, 132, 133, 134, 135, 136, 137, 138, 139, … |
| 2 | 10000355 | [136, 137, 142, 144, 145, 146, 147, 148, 150, … | 197 | 136 | [131, 132, 133, 134, 135, 136, 137, 138, 139, … |
| 3 | 10000357 | [169, 170, 171, 172, 173, 174, 175, 176, 177, … | 200 | 169 | [131, 132, 133, 134, 135, 136, 137, 138, 139, … |
| 4 | 10000383 | [134, 156, 176, 181] | 181 | 134 | [131, 132, 133, 134, 135, 136, 137, 138, 139, … |
# explode函数用于将包含列表或数组的列拆分为单独的行或元素,并复制其他列的值。
df_ = df_group.explode('date_all')
df_.head()
| user_id | date | date_max | date_min | date_all | |
|---|---|---|---|---|---|
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 128 |
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 129 |
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 130 |
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 131 |
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 132 |
| 从历史数据中构建7日留存分标签:(get_label函数代码解读) |
|---|
| 已知测试集中需要预测的日期最小值为161,最大值为222。 |
| 1.提取表中某一行,构建特征(max_date-有登录记录的最晚日期、min_date-有登录记录的最早日期、date-需要预测的日期、date_list-登录日期列表)已知测试集中需要预测的日期最小值为161,最大值为222。 |
| 2.如果当前日期date之后的7天均小于最后登录日期,则按照date未来7天内出现的登录日期个数计数,即当前日期date的7日留存分。(set函数:用于转换成集合类型,去重作用 ) |
| 3.如果当前日期date大于153,且该日期对应的用户id不在测试集中,则标记-999等待后续剔除。 |
| 4.如果当前日期date大于153,且该日期对应的用户id在测试集中,同时需要预测的日期与当前日期的差距小于7(比如需要预测的日期为165,当前日期为160,165<160+7,当前日期date所覆盖的区间就是要预测日期的未来了,即此时如果构建当前日期160的7日用户留存分(161167),则后续预测165的7日留存分(166122)会出现已知未来(167)预测过去(166)),所以此情况也标记-999等待后续剔除。 |
| 5.如果当前日期date大于153,且该日期对应的用户id在测试集中,也没有出现未来预测过去的情况,则无论是否有未来7天完整的记录,均按照现有记录计算7日留存分。 |
| 6.如果当前日期date小于130,则认为没有记录且远离需要预测的未来,可以直接标记-999等待删除。 |
| 7.如果当前日期date在[130,154]之间的,则直接根据现有记录来计算7日留存分。 |
def get_label(row):max_date = row['date_max']min_date = row['date_min']date = row['date']date_list = row['date_list'] if date+7 <= max_date:return sum([1 for x in set(date_list) if date < x < date+8])else:if date>153:if row['user_id'] not in user_enddate:return -999else:if user_enddate[row['user_id']] < date+7:return -999else:return sum([1 for x in set(date_list) if date < x < date+8])elif date<130:return -999else:return sum([1 for x in set(date_list) if date < x < date+8])
df_.rename(columns = {'date':'date_list','date_all':'date'},inplace=True)
df_['label'] = df_.apply(get_label, axis=1)
train = df_[df_['label']!=-999]
test.columns = ['user_id','date']
test['label'] = -1
train[['user_id','date','label']].to_csv('F:\Jupyter Files\时间序列\data\output_data\online_trainb.csv',index=False)
test[['user_id','date','label']].to_csv('F:\Jupyter Files\时间序列\data\output_data\online_testb.csv',index=False)
2.2 数据表2-用户观看视频时长和数目特征:user_playback_data.csv
user_pb = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\user_playback_data.csv')
user_pb['count'] = 1
user_pb_group = user_pb[['user_id','date','playtime','count']].groupby(['user_id','date'],as_index=False).agg(sum)
user_pb_group = user_pb_group[user_pb_group['user_id'].isin(test['user_id'])]
user_pb_group.head()
| user_id | date | playtime | count | |
|---|---|---|---|---|
| 1677 | 10000176 | 162 | 770.829 | 2 |
| 1678 | 10000176 | 163 | 16187.517 | 7 |
| 1679 | 10000176 | 165 | 13584.509 | 9 |
| 1680 | 10000176 | 166 | 7742.622 | 6 |
| 1681 | 10000176 | 167 | 1818.905 | 5 |
train = pd.merge(train, user_pb_group, how='left')
train.head()
| user_id | date_list | date_max | date_min | date | label | playtime | count | |
|---|---|---|---|---|---|---|---|---|
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 128 | 0 | NaN | NaN |
| 1 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 129 | 0 | NaN | NaN |
| 2 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 130 | 0 | NaN | NaN |
| 3 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 131 | 0 | NaN | NaN |
| 4 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 132 | 0 | NaN | NaN |
train.rename(columns = {'playtime':'playtime_last'+str(0),'count':'video_count_last'+str(0)},inplace=True)
train.head()
| user_id | date_list | date_max | date_min | date | label | playtime_last0 | video_count_last0 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 128 | 0 | NaN | NaN |
| 1 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 129 | 0 | NaN | NaN |
| 2 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 130 | 0 | NaN | NaN |
| 3 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 131 | 0 | NaN | NaN |
| 4 | 10000176 | [120, 144, 161, 162, 163, 165, 166, 167, 168, … | 185 | 120 | 132 | 0 | NaN | NaN |
test = pd.merge(test, user_pb_group, how='left')
test.rename(columns = {'playtime':'playtime_last'+str(0),'count':'video_count_last'+str(0)},inplace=True)
在for循环中不断增加user_pb_group中的date,(例如,在最开始循环时,user_pb_group中某一行数据的date是162,经过7次循环,这行数据的date就会变为169,但这行数据所对应的其他列依然是162那天的数据。由于train中的date是不变的,因此在最后一次匹配时,train中的162匹配到的会是原本为(162-7)那天的user_pb_group的数据)。对user_pb_group来说,user_id + date被merge识别为索引了,因此merge函数会将剩下的两列play_duration和count合并到train中。利用merge函数的这个性质,可以很容易完成user_pb_group表单上的滑窗:
#滑窗
for i in range(7):user_pb_group['date'] = user_pb_group['date'] + 1train = pd.merge(train, user_pb_group, how='left')train.rename(columns = {'playtime':'playtime_last'+str(i+1),'count':'video_count_last'+str(i+1)},inplace=True)test = pd.merge(test, user_pb_group, how='left')test.rename(columns = {'playtime':'playtime_last'+str(i+1),'count':'video_count_last'+str(i+1)},inplace=True)
#对于某些日期用户没有视频播放行为,使用0填充的方式进行填充
train = train.fillna(0)
test = test.fillna(0)
#保存视频播放时长和视频播放次数数据
pb_feats = []
for i in range(8):pb_feats.append('playtime_last'+str(i))pb_feats.append('video_count_last'+str(i))
#构建新的视频播放表单
train[['user_id','date']+pb_feats].to_csv('F:\Jupyter Files\时间序列\data\output_data\online_train_pb.csv',index=False)
test[['user_id','date']+pb_feats].to_csv('F:\Jupyter Files\时间序列\data\output_data\online_test_pb.csv',index=False)
2.3 数据表3-用户画像数据:user_portrait_data.csv
user_trait = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\user_portrait_data.csv')
user_trait.head()
| user_id | device_type | device_ram | device_rom | sex | age | education | occupation_status | territory_code | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 10209854 | 2.0 | 5731 | 109581 | 1.0 | 2.0 | 0.0 | 1.0 | 865101.0 |
| 1 | 10230057 | 2.0 | 1877 | 20888 | 1.0 | 4.0 | 0.0 | 1.0 | 864102.0 |
| 2 | 10194990 | 2.0 | 7593 | 235438 | 2.0 | 3.0 | 1.0 | 1.0 | 866540.0 |
| 3 | 10046058 | 2.0 | NaN | 55137 | 1.0 | 4.0 | 0.0 | 1.0 | NaN |
| 4 | 10290885 | 2.0 | 2816 | 52431 | 1.0 | 4.0 | 0.0 | 0.0 | NaN |
def deal_ram_rom(x):if type(x)==float:return np.nanelif len(x)==1:return int(x[0])else:return np.mean([eval(i) for i in x])
for i in ['device_ram','device_rom']:user_trait['ls_'+i] = user_trait[i].apply(lambda x: x.split(';') if type(x)==str else np.nan)user_trait[i+'_new'] = user_trait['ls_'+i].apply(lambda x: deal_ram_rom(x))
trait_feats = ['device_type','sex','age','education','occupation_status','device_ram_new','device_rom_new']
user_trait[['user_id']+trait_feats].to_csv('features/user_trait_feature.csv',index=False)
2.4 数据表-登录类型:app_launch_logs.csv
from scipy import stats
launch = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\app_launch_logs.csv')
launch = launch[launch['user_id'].isin(test_a['user_id'])]
launch.head()
| user_id | launch_type | date | |
|---|---|---|---|
| 50 | 10106622 | 0 | 129 |
| 99 | 10319842 | 0 | 129 |
| 100 | 10383611 | 0 | 129 |
| 140 | 10305513 | 0 | 129 |
| 189 | 10563669 | 0 | 129 |
launch_type = launch.groupby(['user_id','date'],as_index=False).agg(list)
launch_type['len'] = launch_type['launch_type'].apply(lambda x: len(x))
launch_type['launch_type'].value_counts()
[0] 263882
[1] 6064
[0, 1] 502
[1, 0] 490
[0, 0] 37
[1, 1] 2
Name: launch_type, dtype: int64
def encode_launch_type(row):length = row['len']ls = row['launch_type']if length==2:return 2else:return ls[0]
launch_type['launch_type_new'] = launch_type.apply(encode_launch_type, axis=1)
launch_type['launch_type_new'] = launch_type['launch_type_new']+1
launch_type['launch_type_new'] = launch_type['launch_type_new'].fillna(0)
train = pd.merge(train, launch_type[['user_id','date','launch_type_new']], how='left')
test = pd.merge(test, launch_type[['user_id','date','launch_type_new']], how='left')
df_group.rename(columns={'date':'date_list'},inplace=True)
test = pd.merge(test,df_group[['user_id','date_list']],how='left')
#最近一次登录时间间隔
def get_last_diff(row):date_list = row['date_list']date_now = row['date']ls = [x for x in date_list if x<=date_now]return date_now - max(ls) if len(ls)>0 else np.nan
train['diff_near'] = train.apply(get_last_diff, axis=1)
test['diff_near'] = test.apply(get_last_diff, axis=1)
#当天是否登录
def is_launch(row):return 1 if row['date'] in row['date_list'] else 0
train['is_launch'] = train.apply(is_launch, axis=1)
test['is_launch'] = test.apply(is_launch, axis=1)
#历史总登录次数
def GetLaunchNum(row):end_date_ = row['date']date_list = row['date_list']return sum([1 for x in date_list if x<= end_date_])
train['launchNum'] = train.apply(GetLaunchNum, axis=1)
test['launchNum'] = test.apply(GetLaunchNum, axis=1)
#近一周的登录次数
def GetNumLastWeek(row):end_date_ = row['date']date_list = row['date_list']return sum([1 for x in date_list if x<= end_date_ and x > end_date_-7])
train['NumLastWeek'] = train.apply(GetNumLastWeek, axis=1)
test['NumLastWeek'] = test.apply(GetNumLastWeek, axis=1)
#前一个月的label中位数以及前四周的label均值
train = train.sort_values(['user_id','date']).reset_index(drop=True)
train_sta = train[['user_id','date','label']].groupby('user_id',as_index=False).agg(list)
train_sta.columns = ['user_id','date_all_list','label_list']
train = pd.merge(train,train_sta,how='left')test = test.sort_values(['user_id','date']).reset_index(drop=True)
df_ = df_.sort_values(['user_id','date']).reset_index(drop=True)
df_sta = df_[['user_id','date','label']].groupby('user_id',as_index=False).agg(list)
df_sta.columns = ['user_id','date_all_list','label_list']
test = pd.merge(test,df_sta,how='left')
#用户在当前日期和预测日期之间的所有7日留存分列表
def get_his_label(row):end_date = row['date']date_all = row['date_all_list']ls_label = row['label_list']ls_new = [x for x in date_all if x+7<=end_date]return ls_label[:len(ls_new)]
train['label_his_list'] = train.apply(get_his_label, axis=1)
#前一个月的label中位数
train['preds_median_30'] = train['label_his_list'].apply(lambda x: np.median(x[-30:]))
#前四周的label均值
# lambda函数中的代码是一个列表推导式,用于计算label_his_list中4个元素的平均值。具体来说,通过循环遍历label_his_list的满足条件的4个元素(即倒数第1、8、15和22个元素),并将这些元素取出来,然后使用np.mean函数计算这些元素的平均值。
train['preds_mean_4'] = train['label_his_list'].apply(lambda x: np.mean([x[i] for i in range(-1*len(x),0) if i==-1 or i==-8 or i==-15 or i==-22]))test['label_his_list'] = test.apply(get_his_label, axis=1)
test['preds_median_30'] = test['label_his_list'].apply(lambda x: np.median(x[-30:]))
test['preds_mean_4'] = test['label_his_list'].apply(lambda x: np.mean([x[i] for i in range(-1*len(x),0) if i==-1 or i==-8 or i==-15 or i==-22]))
#加权平均数
def Get_mean_4_weighted(row):tmp = row['label_his_list']if len(tmp) >= 22:return tmp[-1] * 0.4 + tmp[-8] * 0.3 + tmp[-15] * 0.2 + tmp[-22] * 0.1elif len(tmp) >= 15:return tmp[-1] * 0.4 + tmp[-8] * 0.3 + tmp[-15] * 0.2elif len(tmp) >= 8:return tmp[-1] * 0.4 + tmp[-8] * 0.3elif len(tmp) >= 1:return tmp[-1] * 0.4else:return 0
train['preds_mean_4_weighted'] = train.apply(Get_mean_4_weighted,axis=1)
test['preds_mean_4_weighted'] = test.apply(Get_mean_4_weighted,axis=1)
#加权中位数
import sys
sys.path.append('wquantiles-0.6/')
import wquantiles
# wquantiles.median函数是一个用于计算加权中位数的函数。使用wquantiles.median函数,需要传入两个参数:data和weights。data是一个一维数组,表示数据集;weights是一个一维数组,表示每个数据点的权重。
def GetWeightedMedian(row):tmp = row['label_his_list']tmp = tmp[-30:]weight = np.array([(x+1)/(30) for x in range(30)])if len(tmp) >= 30:return wquantiles.median(np.array(tmp),weight)else:tmp = [0 for x in range(30-len(tmp))] + tmp #创建一个长度为 `30-len(tmp)` 的列表,其中每个元素的值为0,并将 `tmp` 追加到该列表的末尾。return wquantiles.median(np.array(tmp),weight)train['weighted_median'] = train.apply(GetWeightedMedian, axis=1)
test['weighted_median'] = test.apply(GetWeightedMedian, axis=1)
launch_feats = ['diff_near','is_launch','launch_type_new','launchNum','NumLastWeek','preds_median_30','preds_mean_4','preds_mean_4_weighted','weighted_median']
train[['user_id','date']+launch_feats].to_csv('F:\Jupyter Files\时间序列\data\output_data\launch_online_train.csv',index=False)
test[['user_id','date']+launch_feats].to_csv('F:\Jupyter Files\时间序列\data\output_data\launch_online_test.csv',index=False)
2.5 合并数据表生成训练集&测试集
train_pb = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\output_data\\online_train_pb.csv')
train = pd.merge(train, train_pb, how='left')
test_pb = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\output_data\\online_test_pb.csv')
test = pd.merge(test, test_pb, how='left')user_trait = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\output_data\\user_trait_feature.csv')
train = pd.merge(train, user_trait, how='left')
test = pd.merge(test, user_trait, how='left')launch_train = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\output_data\\launch_online_train.csv')
train = pd.merge(train, launch_train, how='left')
launch_test = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\output_data\\launch_online_test.csv')
test = pd.merge(test, launch_test, how='left')
launch = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\app_launch_logs.csv')
launch = launch.drop_duplicates()
launch.index = range(launch.shape[0]) #删除样本后需要恢复索引
df_launch = launch.groupby("date").count()
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15,9),dpi=200)
sns.set(style="white",font="Simhei", font_scale=1.1)
plt.bar(df_launch.index,df_launch["user_id"],color="#01a2d9",alpha=0.7)
plt.title("不同日期登录的总用户数(条形图)",fontsize=25)
plt.grid()
plt.xticks(ticks = range(100,221,7),fontsize=14);
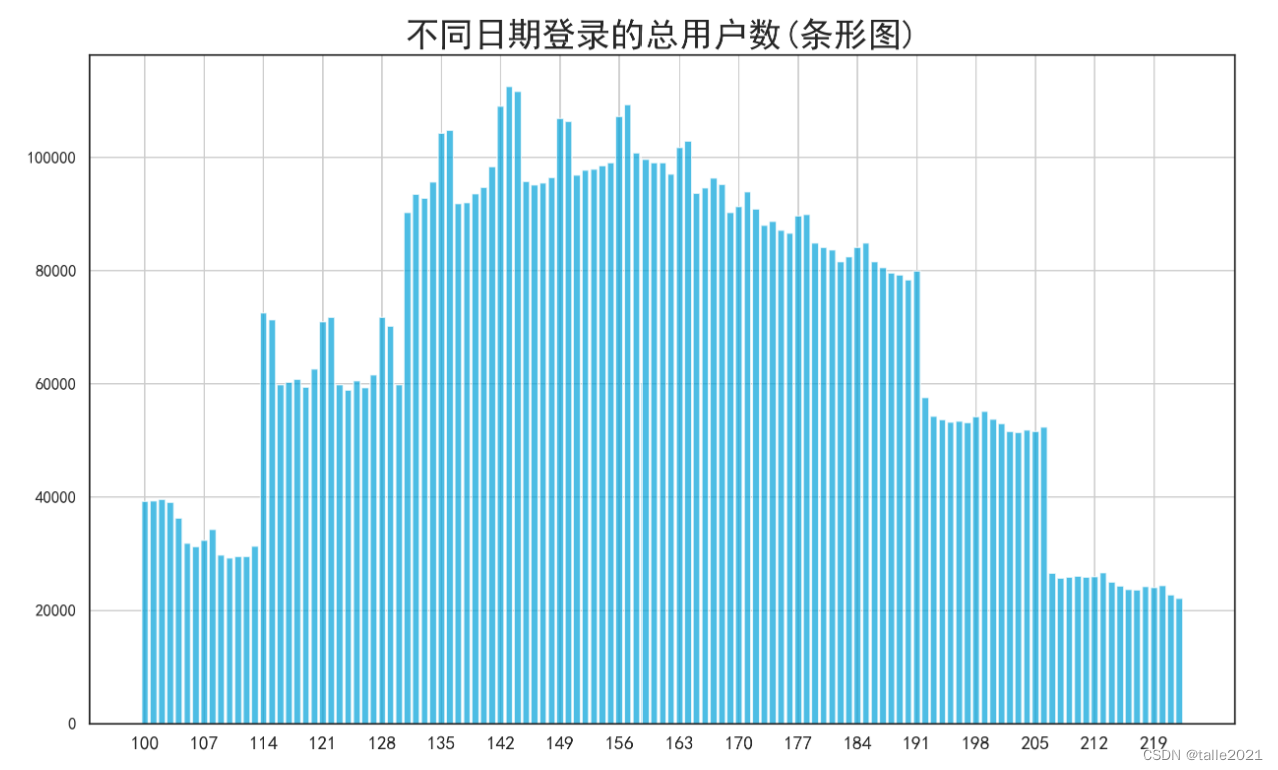
根据上图可知,用户登录的情况明显具有一定的周期性。从107日开始,大约每7天就会出现2天登录高峰,猜测可能是周末。这种规律一直持续到了191日,持续了大约11-12周,猜测可能是某部剧/综艺节目的上线带来了这种效应。在数据明显按星期/月份有周期性的情况下,我们可以在对时间数据进行特征衍生时、构建基于星期、基于月份的时间特征。在本方案中,冠军团队日期为130设为星期一。
train['week'] = train['date'].apply(lambda x: (x-130)%7+1)
test['week'] = test['date'].apply(lambda x: (x-130)%7+1)
playback = pd.read_csv('F:\\Jupyter Files\\时间序列\\data\\original_data\\user_playback_data.csv')
playback = playback[playback['user_id'].isin(test['user_id'])]
user_list =set(playback['user_id'])
feats = ['playtime_last0', 'video_count_last0', 'playtime_last1', 'video_count_last1', 'playtime_last2', 'video_count_last2','playtime_last3', 'video_count_last3', 'playtime_last4', 'video_count_last4', 'playtime_last5', 'video_count_last5','playtime_last6', 'video_count_last6', 'playtime_last7', 'video_count_last7', 'device_type', 'sex','age','education','occupation_status','device_ram_new','device_rom_new','diff_near','is_launch','launch_type_new','launchNum','NumLastWeek','preds_median_30','preds_mean_4','preds_mean_4_weighted','weighted_median','week']
len(feats) #33
cat_list = ['device_type','sex','age','education','occupation_status','week','is_launch','launch_type_new']
#构建训练集
train_pos = train[train['label']>0]
train_neg = train[train['label']==0]
# 从label=0的数据集中随机抽取70%的样本,并按照新的索引重置数据帧的索引,同时丢弃原有的索引
train_neg_new = train_neg.sample(frac=0.7,random_state=2).reset_index(drop=True)
train = pd.concat([train_pos, train_neg_new])
train = train.sample(frac=1,random_state=2).reset_index(drop=True)
#继续特征衍生,这里衍生的特征在用于后续xgboost模型
for each_feat in cat_list:train[each_feat] = train[each_feat].fillna(0)test[each_feat] = test[each_feat].fillna(0)train[each_feat] = train[each_feat].astype(int)test[each_feat] = test[each_feat].astype(int)
for each_feat in cat_list:df_tmp = train.groupby(each_feat,as_index=False)['label'].median()dict_tmp = dict(zip(df_tmp[each_feat],df_tmp['label']))train[each_feat+'_label'] = train[each_feat].apply(lambda x: dict_tmp[x])test[each_feat+'_label'] = test[each_feat].apply(lambda x: dict_tmp[x])
cat_list_new = [x+'_label' for x in cat_list]
2.6 特征工程&特征筛选总结
1.视频播放状况:提取了用户当天和前七天每天的视频播放时长以及视频播放数量。
2.用户个人信息:利用了除用户的地区编号外的所有信息。对于device_rom和device_ram中一个用户存在多个值的情况,做了求均值的处理。
3.用户登录情况:提取了当天是否登录、登录类型、历史总登录次数、近一周的总登录次数以及最近一次登录距离当前时间点的时间差。
4.历史标签:提取了用户前一个月标签的中位数、用户前四周对应时间点标签的均值、加权均值以及加权中位数。其中,前四周对应的时间点是end_date-7、end_date-14、end_date-21和end_date-28。加权均值和加权中位数对较近的时间点赋较大的权重。这类特征很好地反应了用户登录的周期特点。
5.星期特征:通过分析每天用户的总登录次数,可发现用户登录总次数呈现以7天为周期的周期规律,且大致可以判断每个时间点为周几。根据上图所示,可以判断出第130天为周一。据此,给定任意date,其weekday可由计算得到。
3.模型建立
3.1 lightgbm
clf = lgbm.LGBMRegressor( objective='regression',max_depth=5, num_leaves=32, learning_rate=0.01, n_estimators=2500, reg_alpha=0.1,reg_lambda=0.1, random_state=2021, subsample = 0.8, min_child_samples=500)
clf.fit(train[feats],train['label'],categorical_feature=cat_list)
test['pre_lgb'] = clf.predict(test[feats])
test['pre_lgb'] = test['pre_lgb'].apply(lambda x: 0 if x<0 else x)
test['pre_lgb'] = test['pre_lgb'].apply(lambda x: 7 if x>7 else x)
3.2 catboost
cbt = cat.CatBoostRegressor(iterations=500, learning_rate=0.1,depth=6, l2_leaf_reg=3,verbose=False,random_seed=2021)
cbt.fit(train[feats],train['label'],cat_features=cat_list)
test['pre_cat'] = cbt.predict(test[feats])
test['pre_cat'] = test['pre_cat'].apply(lambda x: 0 if x<0 else x)
test['pre_cat'] = test['pre_cat'].apply(lambda x: 7 if x>7 else x)
3.3 xgboost
在用xgboost建模中,冠军团队多加了cat_list_new特征,具体为什么这么做,我暂时还搞不懂😅
new_feats = [x for x in feats+cat_list_new if x not in cat_list]
clf_xgb = xgb.XGBRegressor(max_depth=5,n_estimators=200,learning_rate=0.15,subsample=0.8,reg_alpha=0.1,reg_lambda=0.2,base_score=0, min_child_weight=5,)
clf_xgb.fit(train[new_feats],train['label'])
test['pre_xgb'] = clf_xgb.predict(test[new_feats])
test['pre_xgb'] = test['pre_xgb'].apply(lambda x: 0 if x<0 else x)
test['pre_xgb'] = test['pre_xgb'].apply(lambda x: 7 if x>7 else x)
3.4 后处理
res = pd.merge(test, df_group[['user_id','date_max']],how='left')
res['diff_date'] = res['date'] - res['date_max']
将大于30天未登录的7日留存分设为0,预测值小于0.5且没看过视频的设为0
#lightgbm
def revise_pre(row):if row['user_id'] not in user_list and row['pre_lgb']<0.5:return 0else:return row['pre_lgb']
res.loc[res['diff_date']>=30,'pre_lgb'] = 0
res['pre_lgb'] = res.apply(revise_pre, axis=1)
#catboost
def revise_pre(row):if row['user_id'] not in user_list and row['pre_cat']<0.5:return 0else:return row['pre_cat']
res.loc[res['diff_date']>=30,'pre_cat'] = 0
res['pre_cat'] = res.apply(revise_pre, axis=1)
#xgboost
def revise_pre(row):if row['user_id'] not in user_list and row['pre_xgb']<0.5:return 0else:return row['pre_xgb']res.loc[res['diff_date']>=30,'pre_xgb'] = 0
res['pre_xgb'] = res.apply(revise_pre, axis=1)
3.5 模型融合
res['pre_avg'] = 3/( 1/(res['pre_xgb']+0.00001) + 1/(res['pre_lgb']+0.00001) + 1/(res['pre_cat']+0.00001))
3.6 再处理
res['pre_avg'] = res['pre_avg'].apply(lambda x: 7 if x>6.5 else x)
res['pre_avg'] = res['pre_avg'].apply(lambda x: 0 if x<0.4 else x)
res['pre_avg'] = res['pre_avg'].apply(lambda x: round(x,2))
res.loc[res['pre_avg']<0.5,'pre_avg'] = 0
res.loc[(res['pre_avg']>0.6)&(res['pre_avg']<1.4),'pre_avg'] = 1
res.loc[(res['pre_avg']>1.55)&(res['pre_avg']<2.4),'pre_avg'] = 2
res.loc[(res['pre_avg']>2.55)&(res['pre_avg']<3.4),'pre_avg'] = 3
res.loc[(res['pre_avg']>3.55)&(res['pre_avg']<4.4),'pre_avg'] = 4
res.loc[(res['pre_avg']>4.55)&(res['pre_avg']<5.2),'pre_avg'] = 5
res.loc[(res['pre_avg']>5.55)&(res['pre_avg']<6.2),'pre_avg'] = 6
生成最终结果:
res[['user_id','pre_avg']].to_csv('F:\Jupyter Files\时间序列\data\output_data\submission.csv',index=False, header=False, float_format="%.2f")