文章目录
- 一、如何搭建 eBPF 开发环境?
- 二、开发第一个eBPF程序
- 第一步:使用 C 开发一个 eBPF 程序
- 第二步:使用 Python 和 BCC 库开发一个用户态程序
- 第三步:执行 eBPF 程序
- 三、改进第一个 eBPF 程序?
作为 eBPF 最重大的改进之一,一次编译到处执行(简称 CO-RE)解决了内核数据结构在不同版本差异导致的兼容性问题。不过,在使用 CO-RE 之前,内核需要开启
CONFIG_DEBUG_INFO_BTF=y 和
CONFIG_DEBUG_INFO=y 这两个编译选项。为了避免首次学习 eBPF 时就去重新编译内核,推荐使用已经默认开启这些编译选项的发行版,作为你的开发环境,比如:
- Ubuntu 20.10+
- Fedora 31+
- RHEL 8.2+
- Debian 11+
一、如何搭建 eBPF 开发环境?
首先我们需要安装 eBPF 开发和运行所需要的开发工具,这包括:
- 将 eBPF 程序编译成字节码的 LLVM;
- C 语言程序编译工具 make;
- 最流行的 eBPF 工具集 BCC 和它依赖的内核头文件;
- 与内核代码仓库实时同步的 libbpf;
- 同样是内核代码提供的 eBPF 程序管理工具 bpftool。
你可以执行下面的命令,来安装这些必要的开发工具:
# For Ubuntu20.10+
sudo apt-get install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)# For RHEL8.2+
sudo yum install libbpf-devel make clang llvm elfutils-libelf-devel bpftool bcc-tools bcc-devel
libbpf-dev 这个库很可能需要从源码安装,具体的步骤你可以参考 libbpf 的 GitHub 仓库。
二、开发第一个eBPF程序
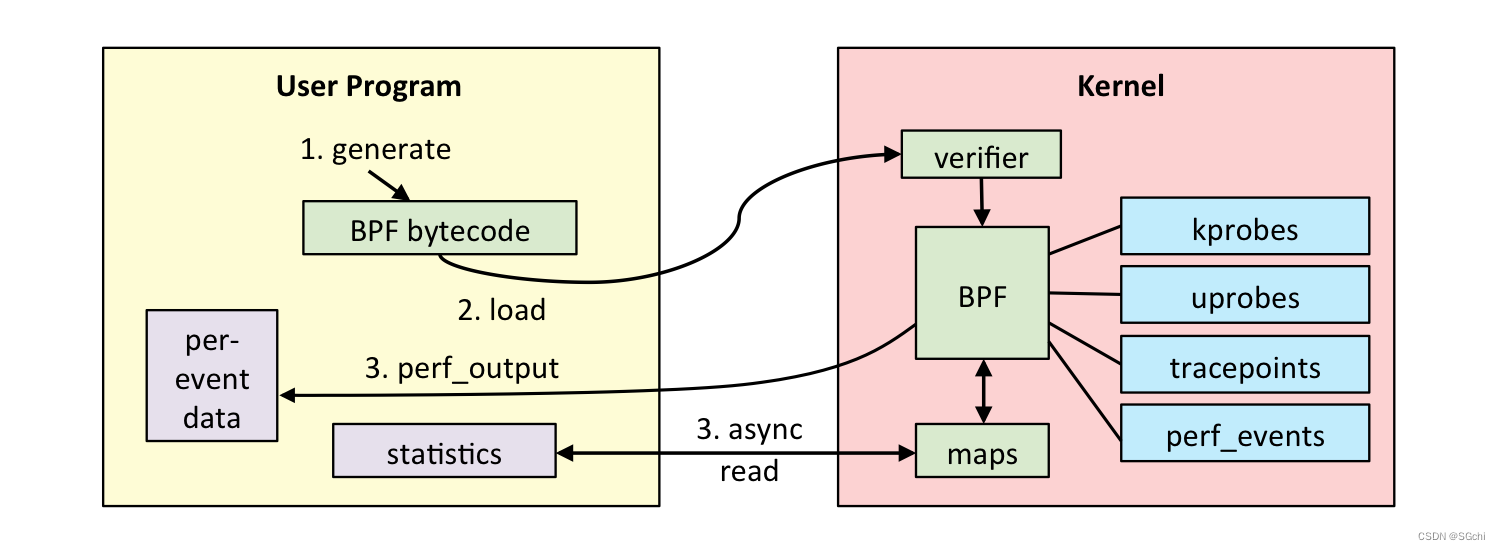
在开发 eBPF 程序之前,我们先来看一下 eBPF 的开发和执行过程。如下图(图片来自 brendangregg.com)所示,一般来说,这个过程分为以下 5 步:
- 第一步,使用 C 语言开发一个 eBPF 程序;
- 第二步,借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
- 第三步,通过 bpf 系统调用,把 BPF 字节码提交给内核;
- 第四步,内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
- 第五步,用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
这里的每一步,我们当然可以自己动手去完成。但对初学者来说,推荐从 BCC(BPF Compiler Collection)开始学起。
BCC 是一个 BPF 编译器集合,包含了用于构建 BPF 程序的编程框架和库,并提供了大量可以直接使用的工具。使用 BCC 的好处是,**它把上述的 eBPF 执行过程通过内置框架抽象了起来,并提供了 Python、C++ 等编程语言接口。**这样,你就可以直接通过 Python 语言去跟 eBPF 的各种事件和数据进行交互。
接下来,我就以跟踪 openat()(即打开文件)这个系统调用为例,带你来看看如何开发并运行第一个 eBPF 程序。使用 BCC 开发 eBPF 程序,可以把前面讲到的五步简化为下面的三步。
第一步:使用 C 开发一个 eBPF 程序
新建一个 hello.c 文件,并输入下面的内容:
int hello_world(void *ctx)
{bpf_trace_printk("Hello, World!");return 0;
}
就像所有编程语言的“ Hello World ”示例一样,这段代码的含义就是打印一句 “Hello, World!” 字符串。其中,bpf_trace_printk() 是一个最常用的 BPF 辅助函数,它的作用是输出一段字符串。不过,由于 eBPF 运行在内核中,它的输出并不是通常的标准输出(stdout),而是内核调试文件 /sys/kernel/debug/tracing/trace_pipe ,你可以直接使用 cat 命令来查看这个文件的内容。
第二步:使用 Python 和 BCC 库开发一个用户态程序
#!/usr/bin/env python3
# 1) import bcc library
from bcc import BPF# 2) load BPF program
b = BPF(src_file="hello.c")
# 3) attach kprobe
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 4) read and print /sys/kernel/debug/tracing/trace_pipe
b.trace_print()
让我们来看看每一处的具体含义:
- 第 1) 处导入了 BCC 库的 BPF 模块,以便接下来调用;
- 第 2) 处调用 BPF() 加载第一步开发的 BPF 源代码;
- 第 3) 处将 BPF 程序挂载到内核探针(简称 kprobe),其中 do_sys_openat2() 是系统调用 openat() 在内核中的实现;
- 第 4) 处则是读取内核调试文件 /sys/kernel/debug/tracing/trace_pipe 的内容,并打印到标准输出中。
在运行的时候,BCC 会调用 LLVM,把 BPF 源代码编译为字节码,再加载到内核中运行。
第三步:执行 eBPF 程序
用户态程序开发完成之后,最后一步就是执行它了。需要注意的是, eBPF 程序需要以 root 用户来运行,非 root 用户需要加上 sudo 来执行:
sudo python3 hello.py
稍等一会,你就可以看到如下的输出:
b' cat-10656 [006] d... 2348.114455: bpf_trace_printk: Hello, World!'
输出的格式可由 /sys/kernel/debug/tracing/trace_options 来修改。比如前面这个默认的输出中,每个字段的含义如下所示:
- cat-10656 表示进程的名字和 PID;
- [006] 表示 CPU 编号;
- d… 表示一系列的选项;
- 2348.114455 表示时间戳;
- bpf_trace_printk 表示函数名;
- 最后的 “Hello, World!” 就是调用 bpf_trace_printk() 传入的字符串。
到了这里,恭喜你已经成功开发并运行了第一个 eBPF 程序!不过,短暂的兴奋之后,你会发现这个程序还有不少的缺点,比如:
- 既然跟踪的是打开文件的系统调用,除了调用这个接口进程的名字之外,被打开的文件名也应该在输出中;
- bpf_trace_printk() 的输出格式不够灵活,像是 CPU 编号、bpf_trace_printk 函数名等内容没必要输出;……
实际上,我并不推荐通过内核调试文件系统输出日志的方式。一方面,它会带来很大的性能问题;另一方面,所有的 eBPF 程序都会把内容输出到同一个位置,很难根据 eBPF 程序去区分日志的来源。
那么,怎么来解决这些问题呢?接下来,我们就试着一起改进这个程序。
三、改进第一个 eBPF 程序?
为了简化 BPF 映射的交互,BCC 定义了一系列的库函数和辅助宏定义。比如,你可以使用 BPF_PERF_OUTPUT 来定义一个 Perf 事件类型的 BPF 映射,代码如下:
// 包含头文件
#include <uapi/linux/openat2.h>
#include <linux/sched.h>// 定义数据结构
struct data_t {u32 pid;u64 ts;char comm[TASK_COMM_LEN];char fname[NAME_MAX];
};// 定义性能事件映射
BPF_PERF_OUTPUT(events);// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename, struct open_how *how)
{struct data_t data = { };// 获取PID和时间data.pid = bpf_get_current_pid_tgid();data.ts = bpf_ktime_get_ns();// 获取进程名if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0){bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);}// 提交性能事件events.perf_submit(ctx, &data, sizeof(data));return 0;
}
其中,以 bpf 开头的函数都是 eBPF 提供的辅助函数,比如:
- bpf_get_current_pid_tgid 用于获取进程的 TGID 和 PID。因为这儿定义的 data.pid 数据类型为 u32,所以高 32 位舍弃掉后就是进程的 PID;
- bpf_ktime_get_ns 用于获取系统自启动以来的时间,单位是纳秒;
- bpf_get_current_comm 用于获取进程名,并把进程名复制到预定义的缓冲区中;
- bpf_probe_read 用于从指定指针处读取固定大小的数据,这里则用于读取进程打开的文件名。
有了 BPF 映射之后,前面我们调用的 bpf_trace_printk() 其实就不再需要了,因为用户态进程可以直接从 BPF 映射中读取内核 eBPF 程序的运行状态。
这其实也就是上面提到的第二个待解决问题。那么,怎样从用户态读取 BPF 映射内容并输出到标准输出(stdout)呢?在 BCC 中,与 eBPF 程序中 BPF_PERF_OUTPUT 相对应的用户态辅助函数是 open_perf_buffer() 。它需要传入一个回调函数,用于处理从 Perf 事件类型的 BPF 映射中读取到的数据。具体的使用方法如下所示:
from bcc import BPF# 1) load BPF program
b = BPF(src_file="trace-open.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")# 2) print header
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))# 3) define the callback for perf event
start = 0
def print_event(cpu, data, size):global startevent = b["events"].event(data)if start == 0:start = event.tstime_s = (float(event.ts - start)) / 1000000000print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))# 4) loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while 1:try:b.perf_buffer_poll()except KeyboardInterrupt:exit()
让我们来看看每一处的具体含义:
- 第 1) 处跟前面的 Hello World 一样,加载 eBPF 程序并挂载到内核探针上;
- 第 2) 处则是输出一行 Header 字符串表示数据的格式;
- 第 3) 处的 print_event 定义一个数据处理的回调函数,打印进程的名字、PID 以及它调用 openat 时打开的文件;
- 第 4) 处的 open_perf_buffer 定义了名为 “events” 的 Perf 事件映射,而后通过一个循环调用 perf_buffer_poll 读取映射的内容,并执行回调函数输出进程信息。
将前面的 eBPF 程序保存到 trace-open.c ,然后再把上述的 Python 程序保存到 trace-open.py 之后(你可以在 GitHub ebpf-apps 上找到完整的代码),就能以 root 用户来运行了:
sudo python3 trace-open.py
稍等一会,你会看到类似下面的输出:
TIME(s) COMM PID FILE
2.384485400 b'irqbalance' 991 b'/proc/interrupts'
2.384750400 b'irqbalance' 991 b'/proc/stat'
2.384838400 b'irqbalance' 991 b'/proc/irq/0/smp_affinity'