一、CarbonData简介
CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。
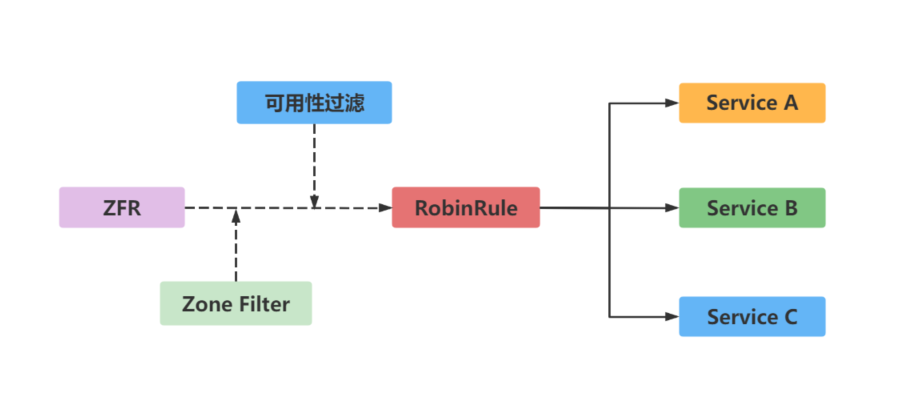
基础架构图

使用CarbonData的目的是对大数据即席查询提供超快速响应。从根本上说,CarbonData是一个OLAP引擎,采用类似于RDBMS中的表来存储数据。用户可将大量(10TB以上)的数据导入以CarbonData格式创建的表中,CarbonData将以压缩的多维索引列格式自动组织和存储数据。数据被加载到CarbonData后,就可以执行即席查询,CarbonData将对数据查询提供秒级响应。
CarbonData将数据源集成到Spark生态系统,用户可使用Spark SQL执行数据查询和分析。也可以使用Spark提供的第三方工具JDBCServer连接到Spark SQL。
二、CarbonData结构
CarbonData作为Spark内部数据源运行,不需要额外启动集群节点中的其他进程,CarbonData Engine在Spark Executor进程之中运行。CarbonData结构如下图所示:
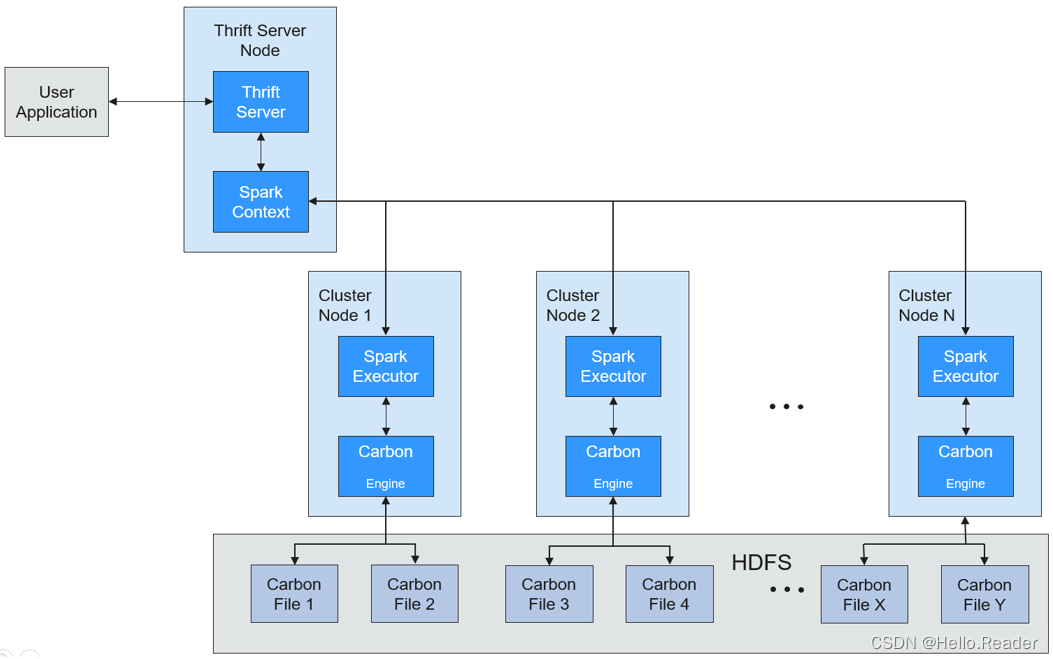
存储在CarbonData Table中的数据被分成若干个CarbonData数据文件,每一次数据查询时,CarbonData Engine模块负责执行数据集的读取、过滤等实际任务。CarbonData Engine作为Spark Executor进程的一部分运行,负责处理数据文件块的一个子集。
Table数据集数据存储在HDFS中。同一Spark集群内的节点可以作为HDFS的数据节点。
三、CarbonData特性
- SQL功能:CarbonData与Spark SQL完全兼容,支持所有可以直接在Spark SQL上运行的SQL查询操作。
- 简单的Table数据集定义:CarbonData支持易于使用的DDL(数据定义语言)语句来定义和创建数据集。CarbonData DDL十分灵活、易于使用,并且足够强大,可以定义复杂类型的Table。
- 便捷的数据管理:CarbonData为数据加载和维护提供多种数据管理功能。CarbonData支持加载历史数据以及增量加载新数据。加载的数据可以基于加载时间进行删除,也可以撤销特定的数据加载操作。
- CarbonData文件格式是HDFS中的列式存储格式。该格式具有许多新型列存储文件的特性,例如,分割表,数据压缩等。CarbonData具有以下独有的特点:
- 伴随索引的数据存储:由于在查询中设置了过滤器,可以显著加快查询性能,减少I/O扫描次数和CPU资源占用。CarbonData索引由多个级别的索引组成,处理框架可以利用这个索引来减少需要安排和处理的任务,也可以通过在任务扫描中以更精细的单元(称为blocklet)进行skip扫描来代替对整个文件的扫描。
- 可选择的数据编码:通过支持高效的数据压缩和全局编码方案,可基于压缩/编码数据进行查询,在将结果返回给用户之前,才将编码转化为实际数据,这被称为“延迟物化”。
- 支持一种数据格式应用于多种用例场景:例如,交互式OLAP-style查询,顺序访问(big scan),随机访问(narrow scan)。
CarbonData关键技术和优势
- 快速查询响应:高性能查询是CarbonData关键技术的优势之一。CarbonData查询速度大约是Spark SQL查询的10倍。CarbonData使用的专用数据格式围绕高性能查询进行设计,其中包括多种索引技术、全局字典编码和多次的Push down优化,从而对TB级数据查询进行最快响应。
- 高效率数据压缩:CarbonData使用轻量级压缩和重量级压缩的组合压缩算法压缩数据,可以减少60%~80%数据存储空间,很大程度上节省硬件存储成本。
CarbonData索引缓存服务器
为了解决日益增长的数据量给driver带来的压力与出现的各种问题,现引入单独的索引缓存服务器,将索引从Carbon查询的Spark应用侧剥离。所有的索引内容全部由索引缓存服务器管理,Spark应用通过RPC方式获取需要的索引数据。这样,释放了大量的业务侧的内存,使得业务不会受集群规模影响而性能或者功能出现问题。
四、跨源复杂数据的SQL查询优化
出于管理和信息收集的需要,企业内部会存储海量数据,包括数目众多的各种数据库、数据仓库等,此时会面临以下困境:数据源种类繁多,数据集结构化混合,相关数据存放分散等,这就导致了跨源复杂查询因传输效率低,耗时长。
当前开源Spark在跨源查询时,只能对简单的filter进行下推,因此造成大量不必要的数据传输,影响SQL引擎性能。针对下推能力进行增强,当前对aggregate、复杂projection、复杂predicate均可以下推到数据源,尽量减少不必要数据的传输,提升查询性能。
目前仅支持JDBC数据源的查询下推,支持的下推模块有aggregate、projection、predicate、aggregate over inner join、aggregate over union all等。为应对不同应用场景的特殊需求,对所有下推模块设计开关功能,用户可以自行配置是否应用上述查询下推的增强。
跨源查询增加特性对比
| 模块 | 增强前 | 增强后 |
|---|---|---|
| aggregate | 不支持aggregate下推 | 1. 支持的聚合函数为:sum, avg, max, min, count 例如:select count(*) from table。 2. 支持聚合函数内部表达式 例如:select sum(a+b) from table 3. 支持聚合函数运算, 例如: select avg(a) + max(b) from table 4. 支持having下推 例如: select sum(a) from table where a>0 group by b having sum(a)>10 5. 支持部分函数下推 支持对abs()、month()、length()等数学、时间、字符串函数进行下推。并且,除了以上内置函数,用户还可以通过SET命令新增数据源支持的函数。 例如: select sum(abs(a)) from table 6. 支持aggregate之后的limit、order by下推(由于Oracle不支持limit,所以Oracle中limit、order by不会下推) 例如: select sum(a) from table where a>0 group by b order by sum(a) limit 5 |
| projection | 仅支持简单projection下推,例如:select a, b from table | 1. 支持复杂表达式下推。 例如:select (a+b)*c from table 2. 支持部分函数下推,详细参见表下方的说明。 例如:select length(a)+abs(b) from table 3. 支持projection之后的limit、order by下推。例如:select a, b+c from table order by a limit 3 |
| predicate | 仅支持运算符左边为列名右边为值的简单filter,例如 select * from table where a>0 or b in (“aaa”, “bbb”) | 1. 支持复杂表达数下推 例如:select * from table where a+b>c*d or a/c in (1, 2, 3) 2. 支持部分函数下推,详细参见表下方的说明。 例如:select * from table where length(a)>5 |
| aggregate over inner join | 需要将两个表中相关的数据全部加载到Spark,先进行join操作,再进行aggregate操作 | 支持以下几种: 1. 支持的聚合函数为:sum, avg, max, min,count 2.所有aggregate只能来自同一个表,group by可以来自一个表或者两个表,只支持inner join。 不支持的情形有: 1.不支持aggregate同时来自join左表和右表的下推。2.不支持aggregate内包含运算,如:sum(a+b)。3.不支持aggregate运算,如:sum(a)+min(b)。 |
| aggregate over union all | 需要将两个表中相关的数据全部加载到Spark,先进行union操作,再进行aggregate操作 | 支持情况: 支持的聚合函数为:sum, avg, max, min,count 不支持的情况: 1. 不支持aggregate内包含运算,如:sum(a+b)。 2.不支持aggregate运算,如:sum(a)+min(b)。 |
五、注意事项
- 外部数据源是Hive的场景,通过Spark建的外表无法进行查询。
- 数据源只支持MySQL和Mppdb。