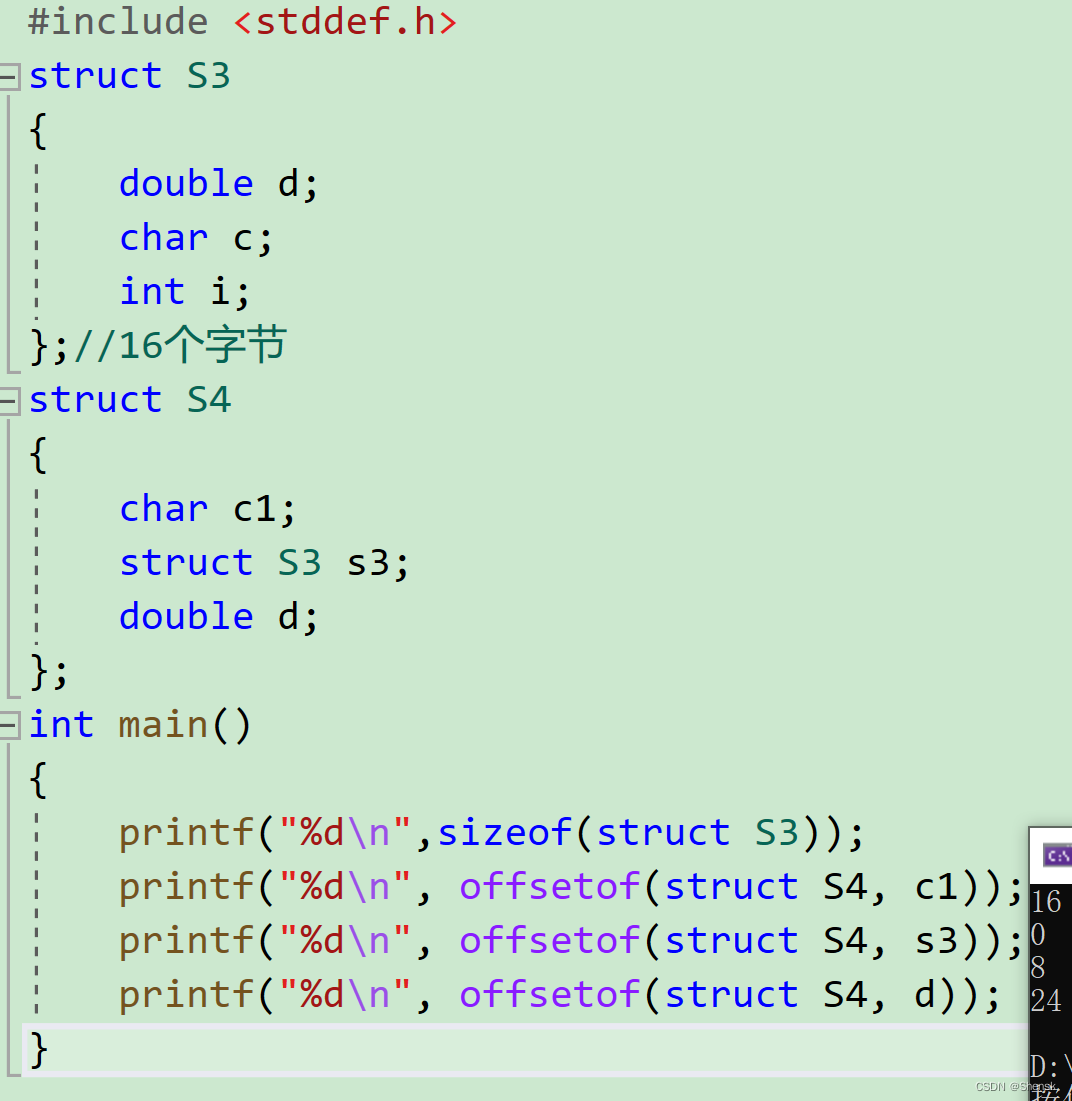
在日常工作中我们经常收到一些诸如此类需求:“用户给点击了开屏广告,给用户下发私信”、“用户进入了推荐线,但在60秒内没有任何点击操作,弹框引导用户选择感兴趣的内容”、“用户点赞了某位作者的两篇以上的内容,但并没有关注过此作者,则弹框引导用户关注作者”、“用户点击了活动入口,进入了活动页、发生了点赞、收藏等交互操作,引导用户进入活动下一流程”。这些需求大致可以分为如下三大类:
- 完成事件A,触发运营动作。
- 完成时间A多次,触发运营动作。
- 在固定时间内完成事件A,但未完成事件B,触发运营动作。
- 依次完成事件A,B,C,触发运营动作。
这些需求从开发角度来看,代码有很高的相似性,所以我们对这些需求进行了抽象,基于flink开发了一套行为规则引擎,并在规则引擎之上将常用的运营动作模块化,真正做到十分钟上线一个运营策略,相对之前天级别的交付时间,效率大幅提升。
先看下规则引擎整体的架构:
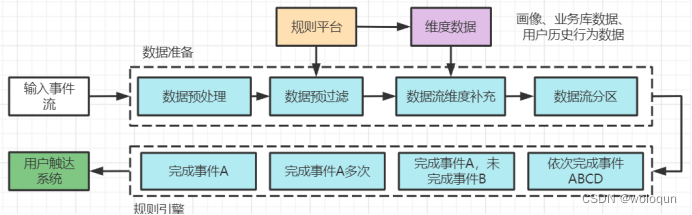
一个任务上线,从“数据流输入”到“用户触达”,整个任务流程分为6个阶段:输入事件流、数据准备、规则平台、维度数据、规则引擎、用户触达系统。
输入事件流
数据主要来自于行为日志,也就是用户通过sdk上报的埋点数据以及后端埋点数据。为了后规则引擎易于处理,通常会对一些嵌套数据进行扁平化操作。
数据准备
这个阶段的主要工作就是为规则引擎准备输入数据,分为四个步骤:数据预处理、数据预过滤、数据流维度补充、数据流分区。
规则平台
规则平台面向的用户主要是运营。运营人员通过规则平台配置运营策略。规则平台会将这些规则分发给规则引擎,规则引擎将规则转换成处理逻辑。
维度数据
维度数据包含三部分:画像数据、业务库数据以及用户历史行为数据。这些数据在数据准备阶段会填充到数据流中,后续会介绍。
规则引擎
目前规则引擎支持四种规则类型,在实现上分别对应一个flink程序:
- 完成事件A
- 完成事件A多次
- 完成事件A、未完成事件B
- 依次完成事件A、B、C、D
接下来我们通过举例,从易到难的方式,介绍规则引擎的数据处理流程。
第一个例子:用户发生点赞行为(规则类型1)
输入数据流:
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110"
}
这条数据意思为:用户(uid:111)在时间(time:1672383110)对内容(oid:562asdf12)进行了点赞操作(action:like),这个场景再简单不过了。
我们需要通过规则平台告诉规则引擎如何处理这个需求,例如我们先定义了一个能满足当前需求的规则串
{"rule_id":"00001","rule_type":"1","conditions":{"action":"like"}
}
稍微解释字段含义
rule_id:规则id,规则唯一标识
rule_type:规则类型,当前规则为“完成事件A”,故该值为“1”.
conditions:规则引擎需要判定条件。
在这个例子中flink规则引擎只要判断数据流中的action的值是否为“like”。
第二个例子:用户触发点赞行为2次。(规则类型2)
和第一个例子不一样的地方在于这个例子出现计数场景。先看下规则串和之前的例子有什么不同
{"rule_id":"000012","rule_type":"2","pk":"rule_id::uid","conditions":{"action":"like","eventCount":"eq:2"}
}
rule_type:2,告诉规则引擎这是个”完成事件A多次“的任务,并且规则串新增属性pk、eventCount。‘pk’代表分区键,对应这flink程序中keyby中的字段,“eventCount”:"eq:2"在这个例子中代表:点赞次数等于2
第三个例子:用户给同一作者文章点赞超过2次(规则类型2)
在这个例子中需要用到作者信息,但是数据流中并没有。这就需要介绍下”数据预处理“部分。
”数据预处理“阶段会干两件事:补充数据主体、数据扁平化。
数据主体什么意思?对于一款UGC产品,最核心的主体包括:用户、内容、作者等。电商产品,主体包括:用户、商家、商品、品牌等。在我们的规则引擎里,数据主体通常作为关联数据的主键id,所以在数据预处理阶段,我们需要尽可能的将数据主体梳理全,并补充到数据中。在这个例子中我们可以通过oid,把作者id补充到数据中去。
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","author_id":12454
}
“数据扁平化”:为了让规则引擎更好的处理数据,我们会在数据预处理阶段把嵌套的数据进行扁平化操作。
回到例子,规则串可以如下描述
{"rule_id":"000012","rule_type":"2","pk":"rule_id::uid::author_id","conditions":{"action":"like","eventCount":"gt:2"}
}
和第二个例子中唯一不同的是,把author_id添加到分区键pk中,flink程序会按照"rule_id::uid::author_id"进行keyby操作,这样就可以进行计数操作了。
第四个例子:用户给同一作者文章点赞超过2次,但没有关注作者。
在此例子中涉及到了主体之间的关系,而“用户”和“作者”之间的关系存在数据库中,在数据处理过程中,这些数据是怎么使用的?这里就需要介绍下”维度数据“模块。”维度数据“主要包含3中类型数据:画像数据、业务库数据和用户历史行为数据。
画像数据:这个比较好理解,主要是用户相关的属性信息,例如:性别,城市,年龄等。
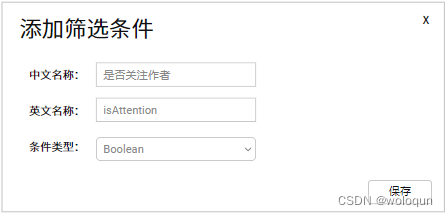
业务库数据:这种数据需要通过业务库获得,在这个例子中,用户是否关注了作者属于这个范畴。
历史行为数据:在有些规则场景中我们会需要用户的一些历史数据进行计算,例如:”用户在过去一周内访问过活动页,并且进行了内容生产“。通常我们会通过离线计算的方式,将数据导入到维度数据中。
”维度数据“通常使用键值数据库存储,例如:redis,hbase等。维度数据生成的方式有两种:通过规则平台从业务库中自动同步到键值数据库,或者直接通过代码的方式。
回到这个例子中,先看下规则串有什么不一样
{"rule_id":"000012","rule_type":"2","pk":"rule_id::uid::author_id","dimKey":{"isAttention":"uid,author_id"},"conditions":{"action":"like","isAttention":false,"eventCount":"gt:2"}
}
dimKey:这个字段中的”isAttention“代表要新增的维度数据,在这个例子中代表”没有关注作者“,这个字段在规则平台维护。"uid,author_id"意思是flink程序需要通过数据流中的uid和author_id去”维度数据“中获得isAttention的值。
在规则串里我们只是定义了isAttention的获取方式,那数据是填充的据流程是怎么样的?这里涉及到两个模块:“数据预过滤”和“数据流维度补充”。
数据预过滤:
在该阶段“数据准备”的flink程序会根据规则平台中的规则,对数据流进行过滤(将数据流中的“action”值与规则平台维护的规则中的”action“进行比对)数据过滤后,数据流中只包含规则相关的数据。
除此之外,flink程序还会把规则填充到数据流中。例如:规则平台维护了三条规则
{"rule_id":"00001","rule_type":"1","conditions":{"action":"like"}
}{"rule_id":"00002","rule_type":"1","conditions":{"action":"share"}
}{"rule_id":"00003","rule_type":"2","pk":"rule_id::uid::author_id","dimKey":{"isAttention":"uid,author_id"},"conditions":{"action":"like","isAttention":false,"eventCount":"gt:2"}
}
有三条数据进入到flink程序,
{"uid":111, "oid":"562asdf12","action":"like", "time":"1672383110","author_id":12454}
{"uid":111, "oid":"562asdf12","action":"share", "time":"1672383412","author_id":12454}
{"uid":113, "oid":"562asdf12","action":"comment", "time":"1672383412","author_id":12454}
经过数据预过滤后,数据输出如下
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","rule":{"rule_id":"00001","rule_type":"1","conditions":{"action":"like"}}}{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","rule":{"rule_id":"00003","rule_type":"2","action":"like","pk":"rule_id::uid::author_id","dimKey":{"isAttention":"uid,author_id"},"conditions":{"isAttention":false,"eventCount":"gt:2"}}}{"uid":111,"oid":"562asdf12","action":"share","time":"1672383412","rule":{"rule_id":"00002","rule_type":"1",,"conditions":{"action":"share"}}}
我们可以看到,输出了3条数据,但需要注意的是
{"uid":113,"oid":"562asdf12","action":"comment","time":"1672383412","author_id":12454
}
这条数据的action没有和任何一条规则中的action匹配,所以这条数据被抛弃了。而
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","author_id":12454
}
这条数数据的action和两条规则匹配成功,为了后续程序处理方便,我们对数据进行了冗余处理,数据预过滤后,输出了两条数据。
数据流维度补充
在这个步骤中,数据准备flink会按照数据中的规则,从”维度数据“中获取需要填充的维度数据。例如
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","author_id":12454,"rule":{"rule_id":"00003","rule_type":"2","pk":"rule_id::uid::author_id","dimKey":{"isAttention":"uid,author_id"},"conditions":{"action":"like","isAttention":false,"eventCount":"gt:2"}}
}
这条数据需要填充”isAttention“属性,填充”isAttention“需要用到”uid,author_id“两个字段。数据准备flink程序,使用”isAttention::uid::author_id“从”维度数据“中获得{“isAttention”:false},并填充到数据流中
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","author_id":12454,"isAttention":false,"rule":{"rule_id":"00003","rule_type":"2","pk":"rule_id::uid::author_id","dimKey":{"isAttention":"uid,author_id"},"conditions":{"action":"like","isAttention":false,"eventCount":"gt:2"}}
}
flink规则引擎就可以根据”conditions“中的条件,判断当前数据是否满足条件。
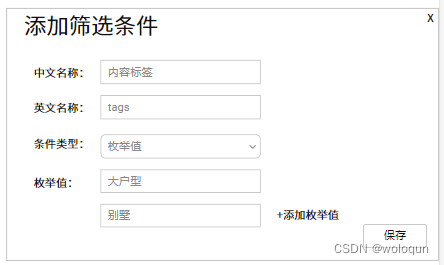
第五个例子:用户点赞文章,文章包含标签“大户型”或“别墅”
这个例子和第四个例子类似,都是需要从”维度数据“中补充业务库数据。我们看下数据处理流程
原始数据
{"uid":111, "oid":"562asdf12","action":"like","time":"1672383110","author_id":12454}
规则:
{"rule_id":"00003","rule_type":"1","pk":"rule_id::uid::oid","dimKey":{"tags":"oid"},"conditions":{"action":"like","tags":["大户型","别墅"]}
}
数据预过滤后
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","author_id":12454,"rule":{"rule_id":"00003","rule_type":"1","pk":"rule_id::uid::oid","dimKey":{"tags":"oid"},"conditions":{"action":"like","tags":["大户型","别墅"]}}
}
数据维度补充后
{"uid":111,"oid":"562asdf12","action":"like","time":"1672383110","author_id":12454,"tags":["大户型","别墅","大三居"],"rule":{"rule_id":"00003","rule_type":"1","pk":"rule_id::uid::oid","dimKey":{"tags":"oid"},"conditions":{"action":"like","tags":["大户型","别墅"]}}
}
flink规则引擎只需要数据中的tags和条件中的tags进行交集计算,就可以得到结果。
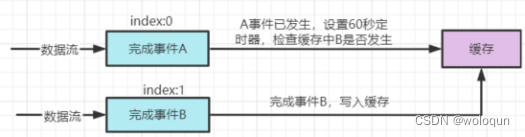
第六个例子:用户进入了推荐线,但在60秒内没有任何点击操作
这个例子属于“完成A时间但未完成B”类型,我们直接看规则串是什么样的
{"rule_id":"00004","rule_type":"3","pk":"rule_id::uid","index":0,"winthTime":60,"conditions":{"action":"recommend"}}
{"rule_id":"00004","rule_type":"3","pk":"rule_id::uid","index":1,"winthTime":60",conditions":{"action":"click"}}
这个规则串有两条数据,分别对应着“事件A”、“事件B”。“事件A”对应的index为0,“事件B”的index为1。winthTime的值对应“60秒内”。数据处理流程如下图。
第七个例子:用户点击了活动入口,进入了活动页、发生了点赞、分享等交互操作,引导用户进入活动下一流程。
先看下规则串
{"rule_id":"00007","rule_type":"4","pk":"rule_id::uid","index":0,"winthTime":60,"conditions":{"action":"activities-click"}
}
{"rule_id":"00007","rule_type":"4","pk":"rule_id::uid","index":1,"winthTime":60,"conditions":{"action":"activities-pv"}
}{"rule_id":"00007","rule_type":"4","pk":"rule_id::uid","index":2,"winthTime":60,"conditions":{"action":"click,share"}
}
这个规则串包含3条数据,分别对应“点击活动入口”、“进入活动页”、“点赞、分享”。
通常这种复杂的事件流匹配需要用到flink cep,但是使用CEP无法解决规则动态变更,并且每一个规则需要对应一个flink任务。基于这个背景,我们对事件顺序流匹配做了一个简单的实现,具体细节可以参照这篇文章:https://blog.csdn.net/woloqun/article/details/126254055。
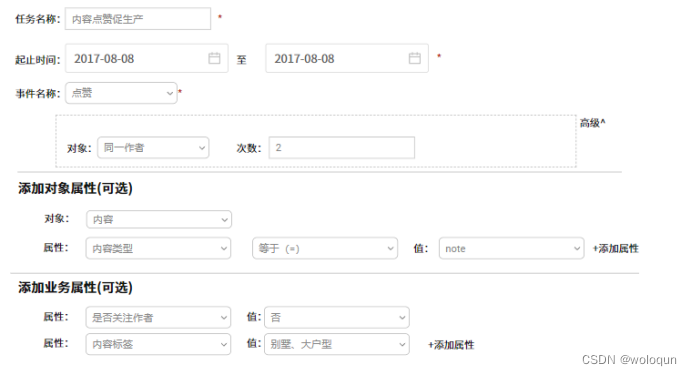
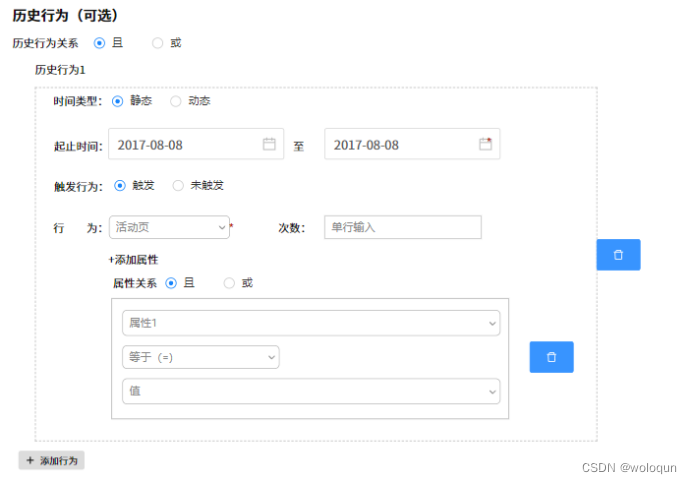
看到这里,你会发现,其实从技术角度没有特别复杂的逻辑。那难点是什么?难点是如何设计平台,生成规则串。最后贴几张草图,大家参考下

![【洛谷】P2345 [USACO04OPEN] MooFest G](/images/no-images.jpg)