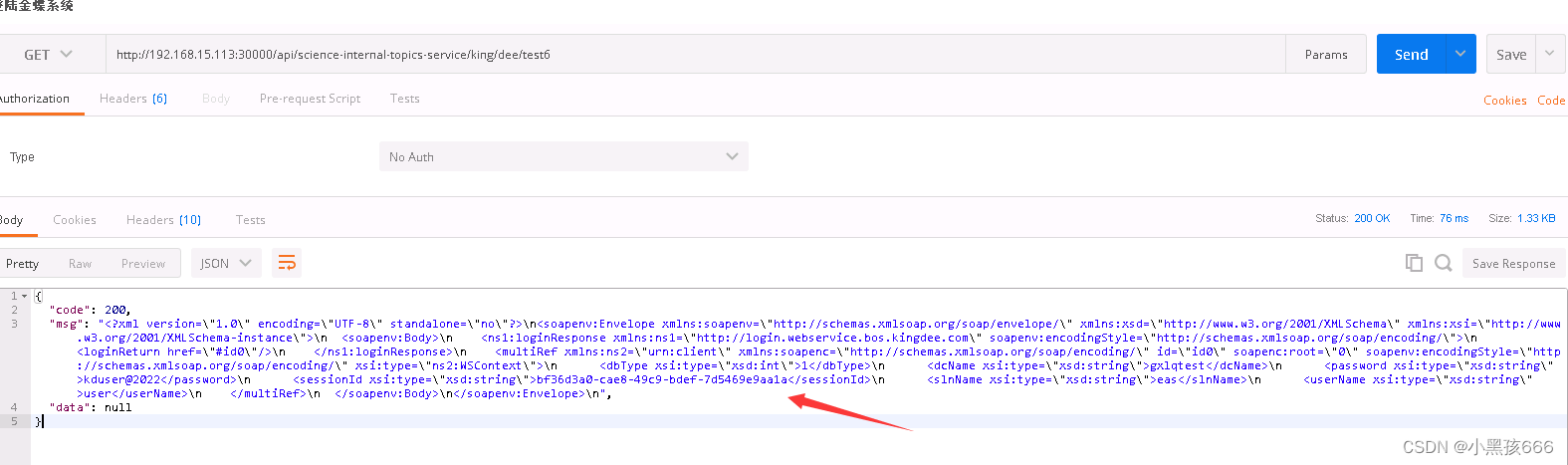
1、杰卡德相似度(Jaccard)
这个是衡量两个集合的相似度一种指标。 两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示

另一种表示的方法:

jaccard系数衡量维度相似性
jaccard系数很适合用来分析多个维度间的相似性,也多被用于推荐系统中用来给用户推荐相似的产品或业务。
举个例子,要计算某网站的两个用户的相似性,可以从性别、地区、年龄、浏览时间等等维度进行分析,我们把这些维度再进行细化:
男性、女性、小于18岁、18岁-40岁、40岁以上、浏览时间为早上、浏览时间为中午、浏览时间为下午
将以上维度作为一个集合,对两个用户A 和B ,将符合以上维度的指标值置为1,其他置为0。
假设用户A = [男性=1, 女性=0, 小于18岁=0, 18岁-40岁=1, 40岁以上=0, 浏览时间为早上=0, 浏览时间为中午=0, 浏览时间为下午=1]
假设用户B = [男性=1, 女性=0, 小于18岁=1, 18岁-40岁=0, 40岁以上=0, 浏览时间为早上=0, 浏览时间为中午=0, 浏览时间为下午=1]
即他们只有年龄不同,则根据计算公式,得到的jaccard系数值为:


jaccard系数衡量文本相似性
虽然jaccard主要是在维度分析这样的稀疏向量中作用比较大,但是在文本相似度计算时也可用jaccard。
用在文本相似度上,就是将字符串A, B分别进行分词,用交集中的词语数和并集中的词语数求比值。
A = [今天,天气,真好]
B = [今天,天气,不错]

转换为01向量

jaccard相似度在UserCF中应用示例
import numpy as np
import pandas as pd#构建用户购买记录数据集(1买了,0没买)
users = ["User1","User2","User3","User4","User5",]
items = ["ItemA","ItemB","ItemC","ItemD","ItemE"]
datasets = [[1,0,1,1,0],[1,0,0,1,1],[1,0,1,0,0],[0,1,0,1,1],[1,1,1,0,1]
]
df = pd.DataFrame(datasets,columns=items,index=users)df


# 计算所有数据两两之间的杰卡德相似系数from sklearn.metrics.pairwise import pairwise_distances# 计算用户的相似度 ( 相似度 = 1 - 杰卡德距离 )
user_similar = 1 - pairwise_distances(df.values,metric='jaccard')
user_similar = pd.DataFrame(user_similar,columns=users,index=users)
print("用户之间的相似度")
user_similar

#为每个用户找到最相似的K个用户(k=2)
topN_users = {}
for i in user_similar.index:_df = user_similar.loc[i].drop(i)#取出第i个用户的那一行,删除自身(自己与自己的相似度为1)_df_sorted = _df.sort_values(ascending = False) #降序排列top2 = list(_df_sorted.index[:2])#找到前两个topN_users[i] = top2print("每个用户最相似的两个用户")
topN_users

rs_users = {}
for user,sim_users in topN_users.items():rs_user = set()# 每个用户都有一个推荐结果for sim_user in sim_users:#和该用户相似的用户都买过什么,放在一起,set去重rs_user = rs_user.union(set(df.loc[sim_user].replace(0,np.nan).dropna().index))rs_user -= set(df.loc[user].replace(0,np.nan).dropna().index)#除去自己买了的rs_users[user] = rs_user
print("基于用户推荐")
rs_users

与传统相似性度量方法相比,杰卡德方法完善了余弦相似性只考虑用户评分而忽略了其他信息量的弊端,特别适合于应用到稀疏度过高的数据